


1 簡介
目前在大規模預訓練模型上進行finetune是NLP中一種高效的遷移方法,但是對于眾多的下游任務而言,finetune是一種低效的參數更新方式,對于每一個下游任務,都需要去更新語言模型的全部參數,這需要龐大的訓練資源。進而,人們會嘗試固定語言預訓練模型大部分網絡的參數,針對下游任務只更新一部分語言模型參數。大部分情況下都是只更新模型最后幾層的參數,但是我們知道語言模型的不同位置的網絡聚焦于不同的特征,針對具體任務中只更新高層網絡參數的方式在不少情形遭遇到精度的急劇下降。
在這個篇章介紹的Adapter會針對每個下游任務在語言模型的每層transformer中新增2個帶有少量參數的模塊,稱之為adapter,針對下游任務訓練時只更新adapter模塊參數,而凍結原有語言模型的參數,從而實現將強大的大規模語言模型的能力高效遷移到諸多下游任務中去,同時保證模型在下游任務的性能。
2 Adapter
Adapter的結構一目了然,transformer的每層網絡包含兩個主要的子模塊,一個attention多頭注意力層跟一個feedforward層,這兩個子模塊后續都緊隨一個projection操作,將特征大小映射回原本的輸入的維度,然后連同skip connection的結果一同輸入layer normalization層。而adapter直接應用到這兩個子模塊的輸出經過projection操作后,并在skip-connection操作之前,進而可以將adapter的輸入跟輸出保持同樣的維度,所以輸出結果直接傳遞到后續的網絡層,不需要做更多的修改。每層transformer都會被插入兩個adapter模塊。
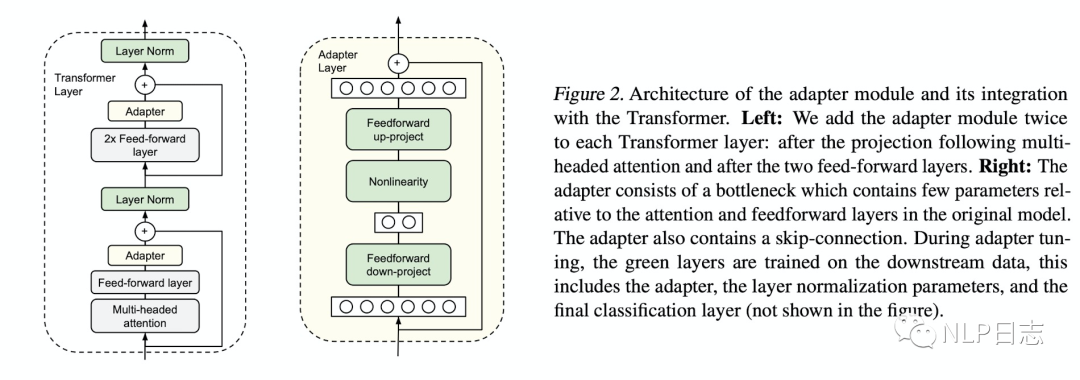
圖1: Adapter框架
下面我們來看看adapter的具體結構,首先通過一個feedforward down-project的矩陣乘法將特征維度降到一個更低的水平,然后通過一個非線形層,再利用一個feedforward up-project層將特征維度升到跟輸入一樣的水平,同時通過一個skip connection來將adpter的輸入重新加到最終的輸出中去,這樣可以保證保證即便adapter一開始的參數初始化接近0,adapter也有由于skip connection的設置而初始化接近于一個恒等映射,從而保證訓練的有效性。
至于adapter引進的模型參數,假設adapter的輸入的特征維度是d,而中間的特征維度是m,那么新增的模型參數有:down-project的參數d*m+m,up_project的參數m*d+d,總共2md+m+d,由于m遠小于d,所以真實情況下,一般新增的模型參數都只占語言模型全部參數量的0.5%~8%。同時要注意到,針對下游任務訓練需要更新的參數除了adapter引入的模型參數外,還有adapter層后面緊隨著的layer normalization層參數需要更新,每個layer normalization層只有均值跟方差需要更新,所以需要更新的參數是2d。(由于插入了具體任務的adapter模塊,所以輸入的均值跟方差發生了變化,就需要重新訓練)
通過實驗,可以發現只訓練少量參數的adapter方法的效果可以媲美finetune語言模型全部參數的傳統做法,這也驗證了adapter是一種高效的參數訓練方法,可以快速將語言模型的能力遷移到下游任務中去。同時,可以看到不同數據集上adapter最佳的中間層特征維度m不盡相同。
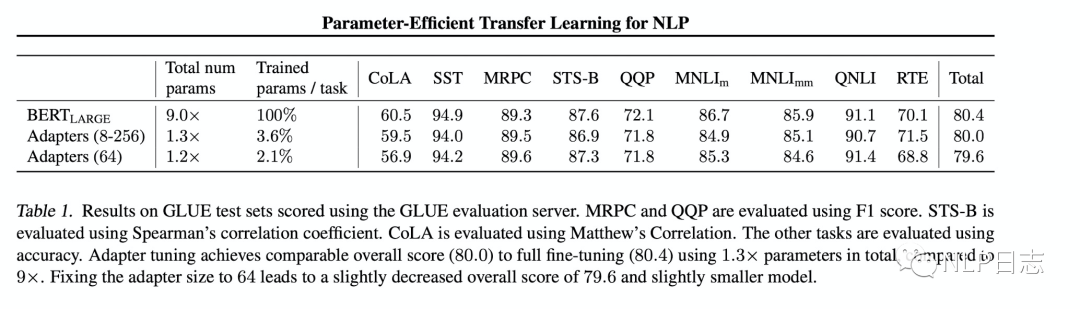
圖2: adapter跟finetune的效果對比
為了進一步探究adapter的參數效率跟模型性能的關系,論文做了進一步的實驗,同時比對了finetune的方式(只更新最后幾層的參數或者只更新layer normalization的參數),從結果可以看出adapter是一種更加高效的參數更新方式,同時效果也非常可觀,通過引入0.5%~5%的模型參數可以達到不落后先進模型1%的性能。
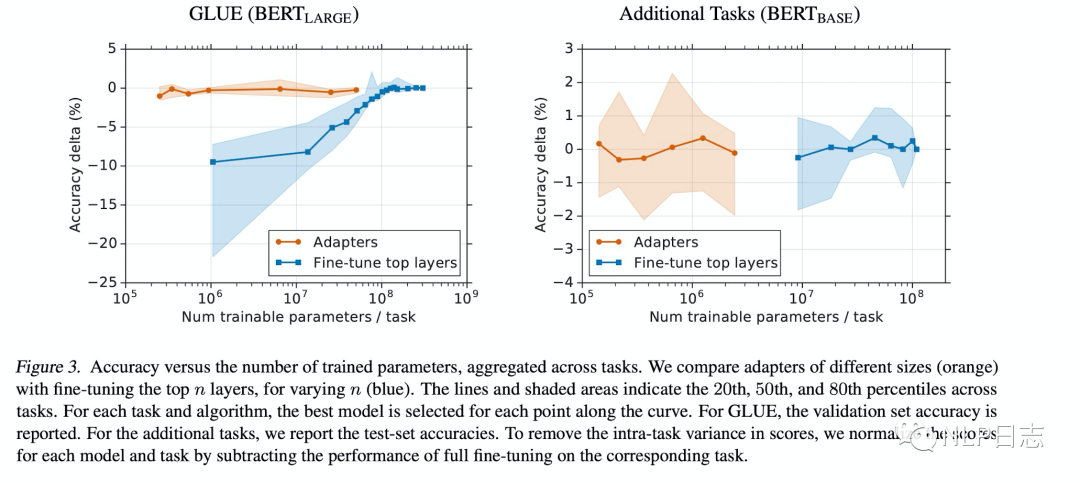
圖3:adapter跟finetune的效率對比
3Adapter fusion
這是一種融合多任務信息的adapter的變種,首先看下它的任務背景。假設C是N個分類任務的集合,這些分類任務的監督數據的大小跟損失函數不盡相同。C={(D1, L1), …, (DN, LN)},其中D是標注數據,L是損失函數,我們的任務是通過這N個任務加上某個任務m的數據跟損失函數(Dm, Lm)去提升這個特定任務m的效果。如圖所示,就是期望先從N個任務中學到一個模型參數(最右邊參數),然后利用該參數來學習特定任務m下的一個模型參數(最左邊參數)。
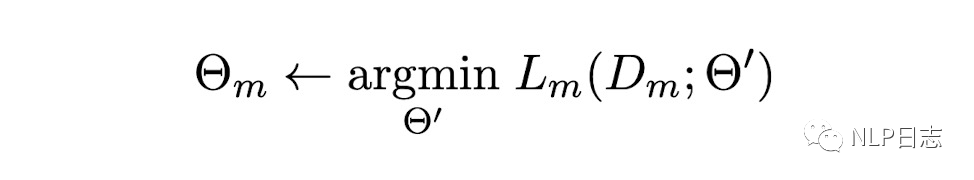
圖4:學習目標
為了實現這個目標,adapter fusion提出一個兩階段的學習策略,其中第一階段是knowledge extraction stage,在不同任務下引入各自的adapter模塊,用于學習特定任務的信息,而第二階段是knowledge composition step,用于學習聚合多個任務的adapter。
對于第一階段有兩種訓練方式,分別如下:
a)Single-Task Adapters(ST-A)
對于N個任務,模型都分別獨立進行優化,各個任務之間互不干擾,互不影響。對于其中第n個任務而言,相應的目標函數如下圖所示,其中最右邊兩個參數分別代表語言模型的模型參數跟特定任務需要引入的adapter參數。
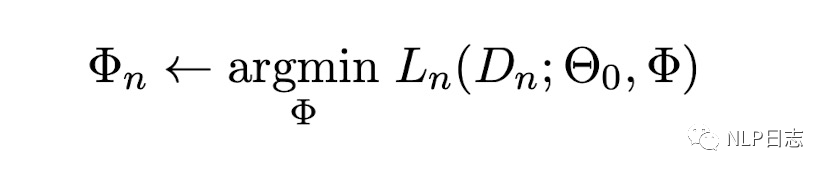
圖5:ST-A目標函數
b)Multi-Task Adapters(MT-A)
N個任務通過多任務學習的方式,進行聯合優化,相應的目標函數如下。
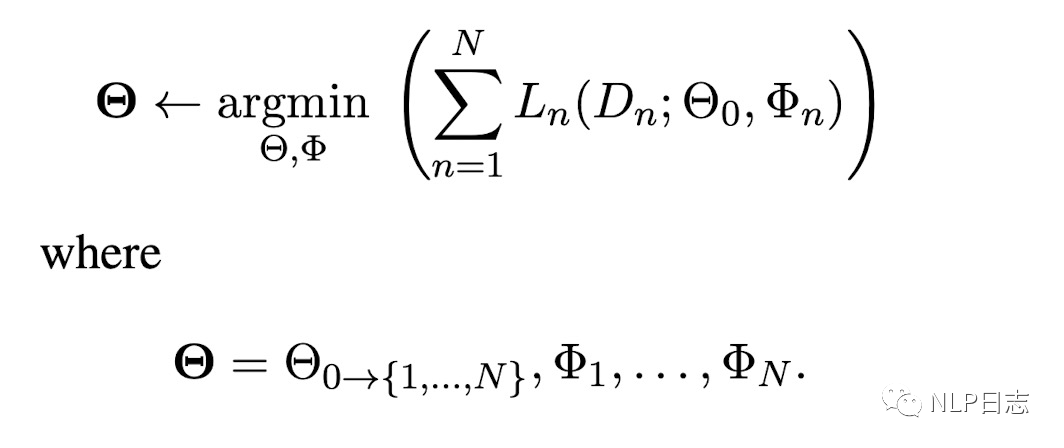
圖6:MT-A目標函數
對于第二階段,就是adapter fusion大展身手的時候了。為了避免通過引入特定任務參數而帶來的災難性遺忘問題,adapter fusion提出了一個共享多任務信息的結構。針對特定任務m,adapter fusion聯合了第一階段訓練的到的N個adapter信息。固定語言模型的參數跟N個adapter的參數,新引入adapter fusion的參數,目標函數也是學習針對特定任務m的adapter fusion的參數。
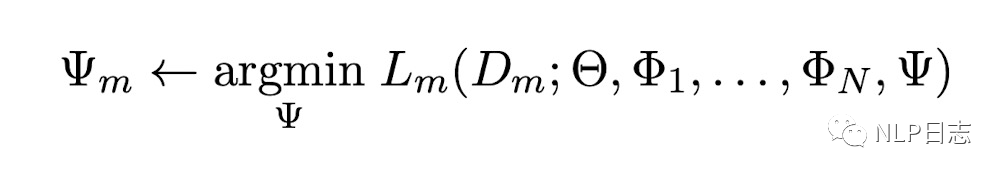
圖7:adapter fusion的目標函數
Adapter fusion的具體結構就是一個attention,它的參數包括query,key, value的矩陣參數,在transformer的每一層都存在,它的query是transformer每個子模塊的輸出結果,它的key跟value則是N個任務的adapter的輸出。通過adapter fusion,模型可以為不同的任務對應的adapter分配不同的權重,聚合N個任務的信息,從而為特定任務輸出更合適的結果。
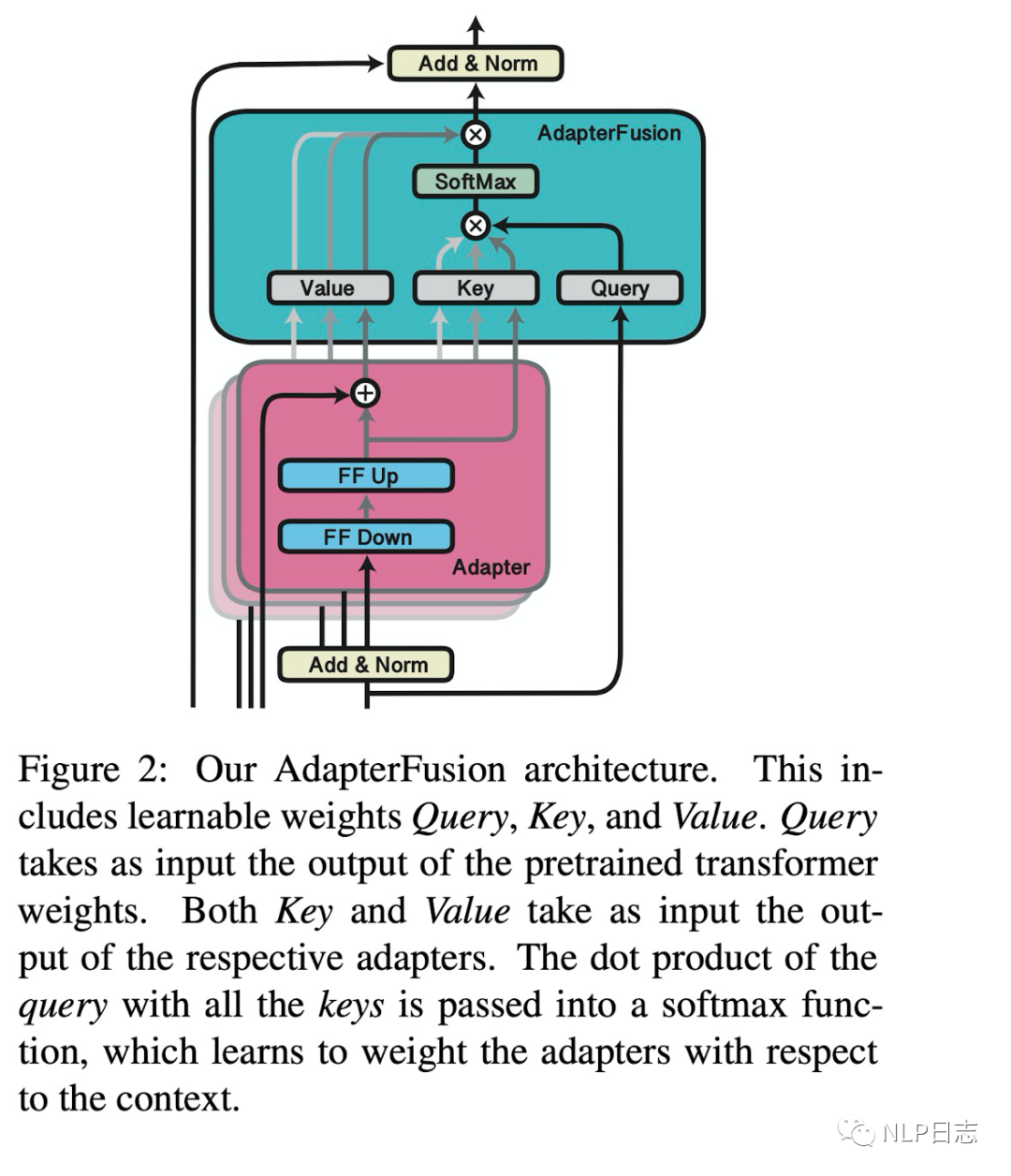
圖8:adapter fusion結構
通過實驗,可以看到第一階段采用ST-A+第二階段adapter fusion是最有效的方法,在多個數據集上的平均效果達到了最佳。關于MT-A+adapter fusion沒有取得最佳的效果,在于第一階段其實已經聯合了多個任務的信息了,所以adapter fusion的作用沒有那么明顯,同時MT-A這種多任務聯合訓練的方式需要投入較多的成本,并不算一種高效的參數更新方式。另外,ST-A的方法在多個任務上都有提升,但是MT-A的方法則不然,這也表明了MT-A雖然可以學習到一個通用的表征,但是由于不同任務的差異性,很難保證在所有任務上都取得最優的效果。
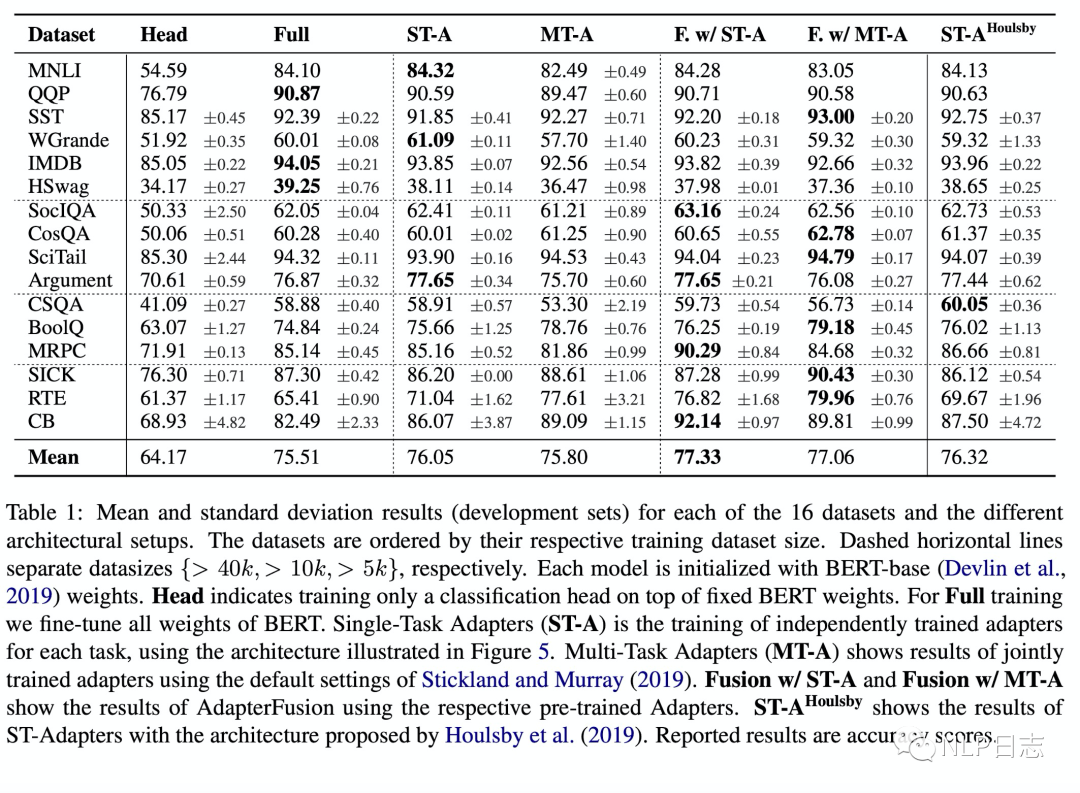
圖9:adapter fusion實驗結果
4 總結
Fusion是一種高效的參數更新方式,能在引入少量參數,只訓練少量參數的情況下達到媲美finetune全模型參數的效果,只訓練少量參數也意味著對訓練數據量更低的要求以及更快的訓練速度,是一種將大規模預訓練語言模型能力遷移到下游任務的高效方案,跟目前火熱的prompt learning有異曲同工之妙。而adapter fusion則跟MOE很像,可以聯合多個任務的信息,從而提升特定任務的性能。但相比于其他的parameter-efficient的方法,adapter是在原語言模型上加入了新的模塊,在推理時會進一步增加延遲。
-
函數
+關注
關注
3文章
4388瀏覽量
65286 -
Adapter
+關注
關注
0文章
16瀏覽量
7802 -
訓練模型
+關注
關注
1文章
37瀏覽量
3983
原文標題:Parameter-efficient transfer learning系列之Adapter
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
轎車參數化分析模型的構造研究及應用
Pytorch模型訓練實用PDF教程【中文】
adapter模式是如何去定義的
全志V853 在 NPU 轉換 YOLO V3 模型
不能同時使用lpuart_adapter和uart_adapter嗎?
TOOLSTICK DEBUG ADAPTER USER’S
什么是Host bus adapter
參數域邊界平直化的模型表面參數化方法






 工商網監
工商網監

評論