") 如何用語言模型(LM)實現(xiàn)建模能力
如何用語言模型(LM)實現(xiàn)建模能力
前言
相信每個 NLPer 心中都有對 Reasoning 的一片期冀。
當初筆者進入 NLP 的大門,就是相信:由于語言強大的表達能力以及語言模型強大的建模能力,Reasoning 一定就在不久的將來!可惜實際情況卻是......
直到我看到了 Yoshua Bengio 最近反復強調的 System 2 的概念,又重新燃起了心中的希望!
System 2 主要針對深度學習系統(tǒng)的 Reasoning 能力以及系統(tǒng)泛化(Systematic Generalization)等等。其中一個很重要的點是:sparse factor graph in space of high-level semantic variables. 結合 QA 的例子以及我淺薄的理解,這里做一些簡單的解釋:
factor graph : 從 Q 到 A 的機理,往往不是 Q -> A 這么簡單,實際人類在建模 QA 的時候,會在這條路徑上增添很多很多的輔助狀態(tài)以及相應的運作機理,例如 Causal Inference 中常說的 SCM (Structural Causal Model)
sparse : from attention to conscious processing. 人類不會同時關注所有的狀態(tài)(變量),而只會關注其中一些比較重要的或者相關的狀態(tài)。通過這種主動的稀疏選擇,在面對 distribution change 的時候,能夠迅速更換另外的狀態(tài)和運作機理進行適應(adaptation).
high-level semantic variables : 這些狀態(tài)的表達,一般是一個高階的語義變量。
在今天這篇推文里,我們主要討論如何用語言模型(LM)實現(xiàn)這件事情。
那現(xiàn)在就以 Google Research 等的新文章 “Language Model Cascades” 開始,聊一聊 A Path Towards Universal Reasoning Systems.
總的來說,這篇文章是個 Proposal 性質的文章,核心論點是:利用概率編程語言,重復地提示(prompt)或調整單個或多個互相關聯(lián)的語言模型,以進行復雜的多步推理。
這樣,基于一個端到端的學習目標,就能夠使用一個通用過程進行系列模型的 inference, 參數(shù)調整或者 prompt 選擇。
還是用 QA 的例子,一般的 QA 是這樣的:
我們有兩種方式去做這件事情(假設數(shù)據(jù)集為 ):
few-shot prompting (aka. in-context learning) : ,即將小樣本集作為輸入的上下文拼接在輸入的前面,而不去調整模型參數(shù),常用于 GPT-3 等模型;
fine-tune : tuned on ,即使用訓練集調整模型參數(shù)。
然后,我們定義語言模型級聯(lián)(LM Cascades): 以從語言模型采樣出的字符串為隨機變量取值的一系列相互關聯(lián)的概率程序。
string-valued : 例如 P(A='老鼠'|Q='貓喜歡吃什么')
相互關聯(lián)的概率程序:可以簡單地理解為圖形式的模型鏈條,詳見下文。
成功的例子
Scratchpads & Chain of Thought
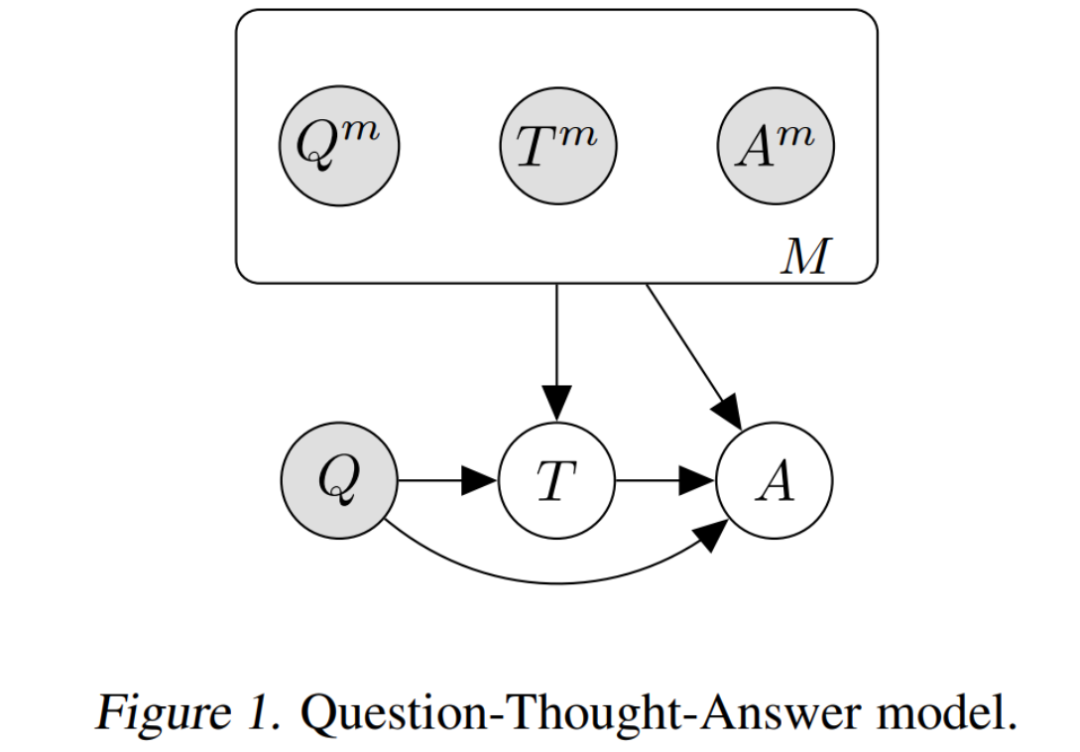
這類模型的 Cascades 如上圖所示,總的來說是一種 Question-Thought-Answer 的結構:
理想情況下的概率建模為:
但在實際場景下, 通常我們只有一個 small set 由完整的 三元組組成, 以及一個 large set 由 對組成。因為缺乏完全的監(jiān)督數(shù)據(jù),我們只能通過先驗預測分布 去建模:
Scratchpad[1] 和 Chain-of-Thought[2] 兩種模型所做的事情,本質上是建模這個先驗預測分布(prior predictive distribution):
scratchpad : 通過精調 (finetuning) 去做。
chain of thought : 將 作為 prompt, 即通過 few-shot prompting 去做。
多說一句:在全部的 上面進行求和顯然不現(xiàn)實,通常采用的方式是:使用 beam search 估計 ,然后在此之上進行求和。
Semi-Supervised Learning
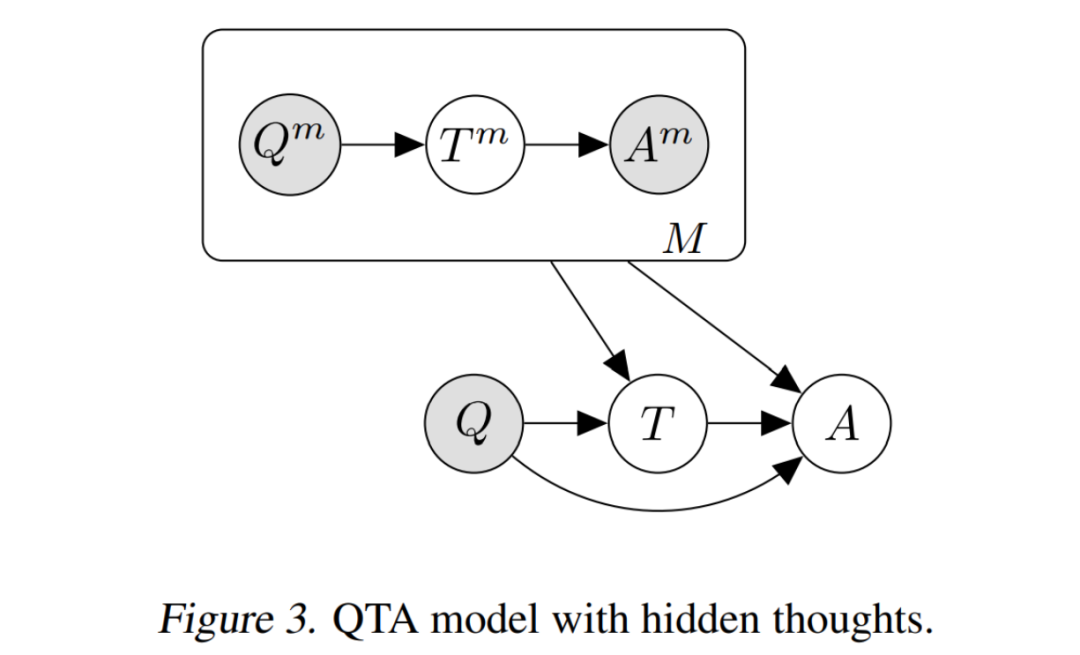
仍然是 Question-Thought-Answer 的結構,但在半監(jiān)督學習的設定下,我們是為 中的 Q-A 對新增一些未知隱變量 去解決。這樣就變成了一個比較典型的變分推斷問題。
這類方法比較典型的工作是:Self-Taught Reasoner (STaR) [3],該模型使用 EM 算法進行優(yōu)化:
-步: 首先在 上精調模型,然后對于 , 通過在 上的拒絕采樣估計未知量 . 直到找到能夠導致正確回答 的 . (如果找不到, 就從 采樣) (這種方式也稱為 :“rationale generation with rationalization”).
-步: 基于所估計的 上的 , 再次精調模型更新參數(shù)。
Selection-Inference
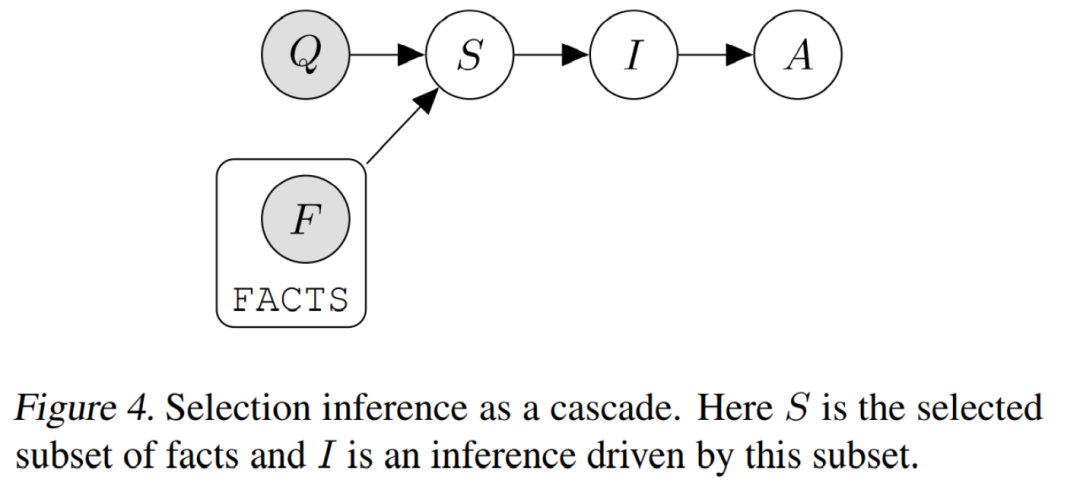
這類方法[4]將推理過程分為兩個部分:
選擇:給定問題 , 從事件集合 中選擇相關子集;
推斷:給定事件子集,推測新的事件集合。
Verifiers

這類方法[5]新增了一些驗證器 ,來判斷 Thought 或者 Answer 是否合理有效(valid):
where
Tool-use
上面這些方法僅僅是 Language Model 的控制流,沒有外部的反饋(external feedback).
在 Cascades 的框架下,我們可以非常方便的引入外部工具,以進行額外的知識補充,比如:
calculator : Training verifiers to solve math word problems (https://arxiv.org/abs/2110.14168).
web : WebGPT: Browser-assisted question-answering with human feedback (https://openai.com/blog/webgpt/).
simulation : The frontier of simulation-based inference (https://www.pnas.org/doi/10.1073/pnas.1912789117)
Twenty Questions
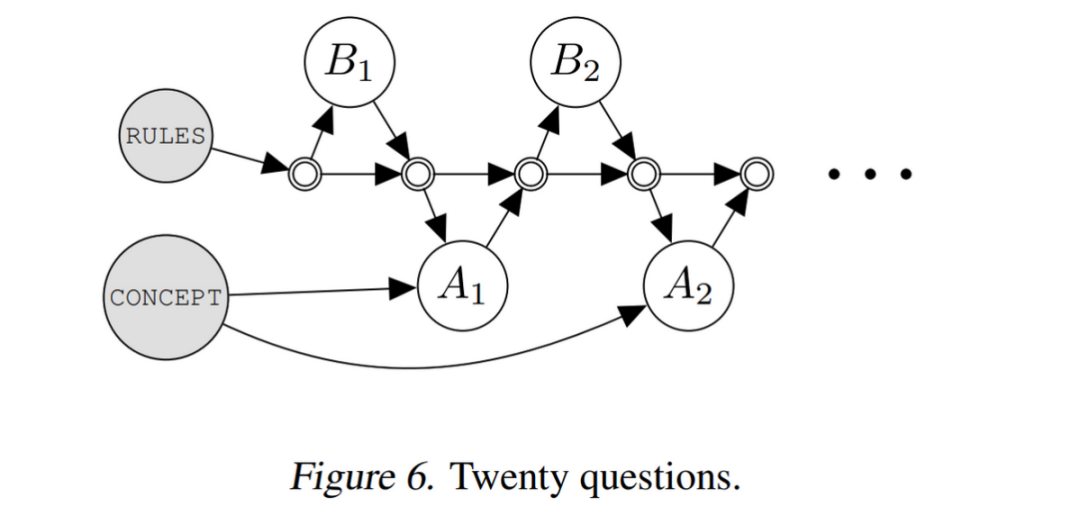
再舉一個交互式問答的例子,如上圖,是 Big-Bench [6] 中的一個任務:兩個 agent, 分別叫做 Alice (A) 和 Bob (B). 在給定的游戲規(guī)則下,兩個 agent 進行語言交流,A 描述一個概念,B 去猜,然后 A 回答是或不是,直到 B 猜出來。
這樣一個過程也能很容易地歸結到 Cascades 的框架中去。
未來
回到最初的問題,Sparse Factor Graph 以及 High-Level Semantic Variables. 我們可以先拋棄掉 Causal Mechanism 等復雜的問題,先只去考慮這種簡單的 Cascading Mechanism.
筆者一直覺得,只用一個模型 One-For-All 肯定是行不通的:雖然我們有 Gato [7] 等所謂的 Generalist Agent,我們也很難 claim 這些模型有 Human-level 的 Out-of-Distribution 的泛化能力,或者 Systematic Generalization. 這也符合 No-Free-Lunch Theorem 一直以來告訴我們的事情。這是第一點。
第二點是,對于 Universal Reasoning 而言,本質的問題并不是如何 encode 盡可能多的知識到單個模型當中,而是:How to re-use pieces of knowledge.
那么基于這兩點,就涉及到一個模塊化的問題:我們能不能定義一些模塊化的知識以及這些模塊之間的交互方式,來實現(xiàn)更加本質的 Reasoning (參考:Is a Modular Architecture Enough? [8])
LM Cascades 就是這個思想的一個很好的嘗試:不同的語言模型對應著不同功能的知識模塊,然后通過人為定義的交互 Graph 來執(zhí)行特定的任務。這么做的好處至少是:
端到端的模塊化:以一種端到端的方式,做到了不同語言模型,根據(jù)其所執(zhí)行的不同功能,進行專門的精調優(yōu)化(finetuning)或者提示優(yōu)化(prompting)。
sparse factor graph : 以一種人為定義的方式,指定了任務內在的知識結構,比如將 Q->A 分解為 Q->T->A 等。這也是近期各種 Chain-of-Thoughts 相關工作令人興奮的點,例如 AI Chains [9] 等。這種知識結構是稀疏的,因為我們人為定義了某個 LM 是基于哪個特定的 LM,而不是全部 LM.
high-level semantic variables : 語言的表達能力是極大的,因此,以 language 作為 variable value 的一個圖結構,具有非常強大的對于實際問題的建模能力。當然,language 只是一個選擇,high-layer hidden states 也是一個(可能更好的)選擇。
當然,不只有語言模型可以級聯(lián),多模態(tài)模型也能夠級聯(lián):比如同樣來自 Google 的 Socratic Models [10], 就級聯(lián)了三個模態(tài)(語言-視覺-音頻)的語言模型,達到了很好的零樣本多模態(tài)推理能力。

因此,筆者相信 LM Cascades 體現(xiàn)出了 Reasoning System 的未來:(1)模塊化、(2)稀疏化、(3)結構化。
這樣一個系統(tǒng),以語言為媒介,最好可以通過一種端到端的方式去進行優(yōu)化。從這個角度看,這個 Proposal 還有很多需要探索的點,例如:
既然“端到端+手工Cascading“可以同時做到這三點,那么有沒有什么辦法,把 Cascading 也納入到端到端的過程中呢(即以一種自動或者可微的方式進行),以找到一種稀疏的條件結構?
有沒有什么更好的模塊化機制?
推理速度...
等等。
-
建模
+關注
關注
1文章
304瀏覽量
60765 -
編程語言
+關注
關注
10文章
1942瀏覽量
34711 -
語言模型
+關注
關注
0文章
521瀏覽量
10268
原文標題:谷歌:級聯(lián)語言模型是通用推理系統(tǒng)的未來
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的應用
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
我們如何實現(xiàn)通用語言智能
實現(xiàn)通用語言智能我們還需要什么
應用語言模型技術創(chuàng)作人工智能音樂
語言模型的發(fā)展歷程 基于神經(jīng)網(wǎng)絡的語言模型解析

什么是系統(tǒng)建模語言SysML?
如何用python實現(xiàn)RFM建模






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論