 汽車領域還未出現Chiplet設計
汽車領域還未出現Chiplet設計
Chiplet有翻譯成小芯片或小晶粒,也有叫MCM(Multi-Chip-Module,可以看做初級版Chiplet),與之對應的則是Monolithic。目前為止,汽車領域還未出現Chiplet設計。
Chiplet的出現有三個驅動力,一個是AI運算中的內存墻,一個是高性能運算,最后是靈活性和復用率。
AI運算中存儲瓶頸非常明顯,AI運算有大量的內存讀寫問題,內存讀取速度遠遠低于計算單元的速度,大部分時間計算單元都在等待內存讀取,有時候效率會下降90%,最有效解決內存墻問題的辦法就是縮短運算單元與存儲器之間的物理距離,在每秒萬億次計算時,幾微米的距離縮短都足以影響芯片性能。除了緩解內存瓶頸外,還能降低功耗減少發熱。
各種技術存儲器的性能對比
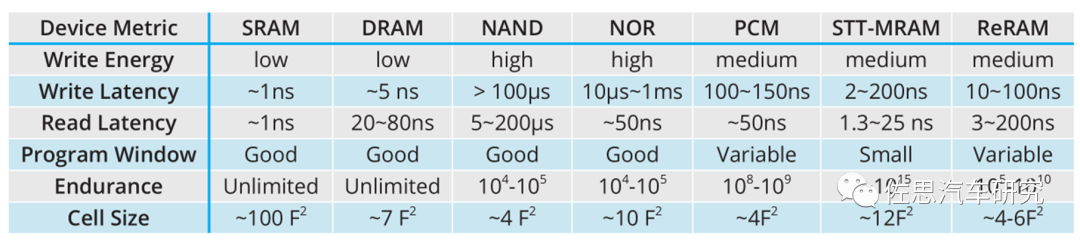
來源:互聯網
上表很明顯,SRAM性能最優,但Cell Size最大,這意味著成本也最高,是NAND的20倍以上。因此一級緩存多SRAM,并且容量很小。PCMMRAMReRAM這三種新興存儲器目前還不成熟,性能與SRAM也有明顯差距。這也是為什么處理器都是三級緩存設計,最靠近運算單元的都是SRAM,但由于成本高,所以容量有限。離運算單元遠的就可以是DRAM。
為解決這個問題,臺積電提出了CoWoS封裝,將大容量的DRAM與運算單元距離拉得最近,而成本又在可接受的范圍內,這就是最早的Chiplet。
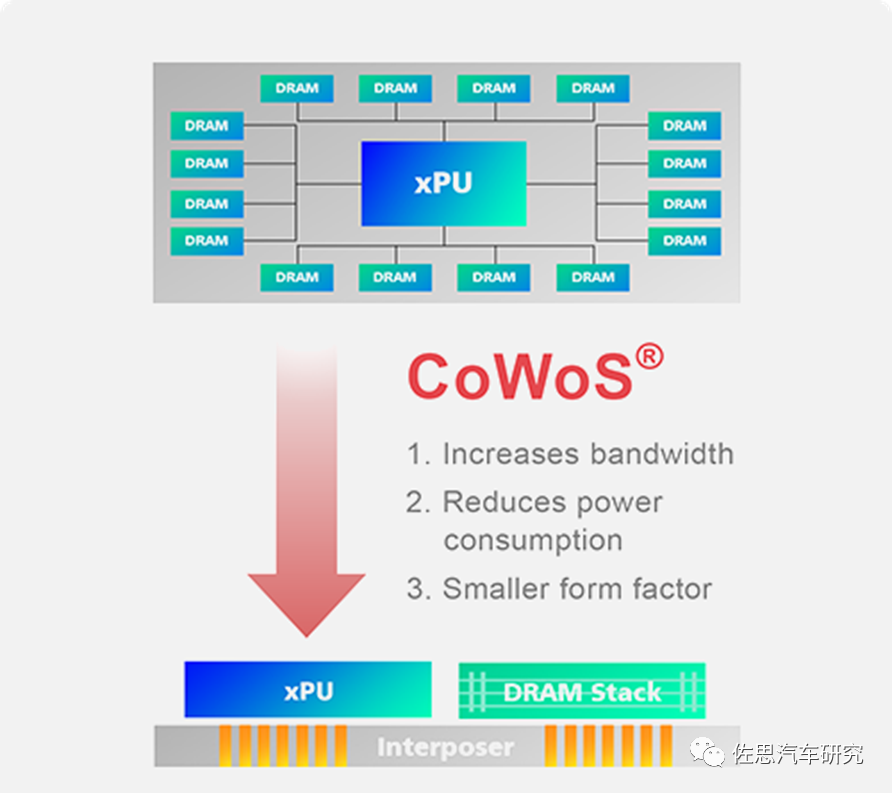
圖片來源:互聯網
CoWoS簡單說就是用硅中介層將邏輯運算器件與DRAM(HBM)合成一個大芯片,CoWoS缺點就是中介層價格太高,對價格敏感的手機和汽車市場都不合適,不過服務器和數據中心市場非常合適,因此臺積電幾乎壟斷高性能AI芯片市場。
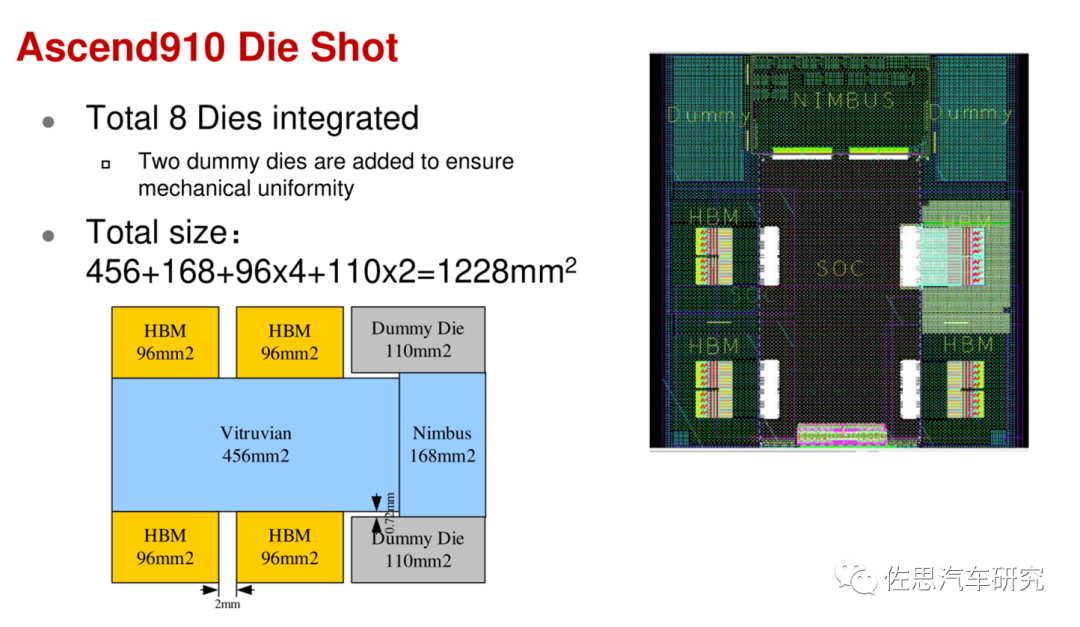
圖片來源:互聯網
華為昇騰910的裸晶面積高達1228平方毫米,兩個假Die只是為了增加機械一致性,是空的,這也是臺積電CoWoS工藝的缺點,如果是英特爾的EMIB,這兩個假Die可以不要。
華為昇騰910的外觀

圖片來源:互聯網
第二個驅動力是高性能運算,無論是AI運算還是常規標量運算,增加核心數都是最有效最可行的方法,但是芯片面積不能無限增大,芯片面積越大意味著良率越低,成本越高。半導體業內有一條不成文的共識,單一芯片的裸晶面積不超過800平方毫米,超過800平方毫米,成本會飛速增加,不具備實用性。這也是為何英偉達的芯片都那么貴的原因。
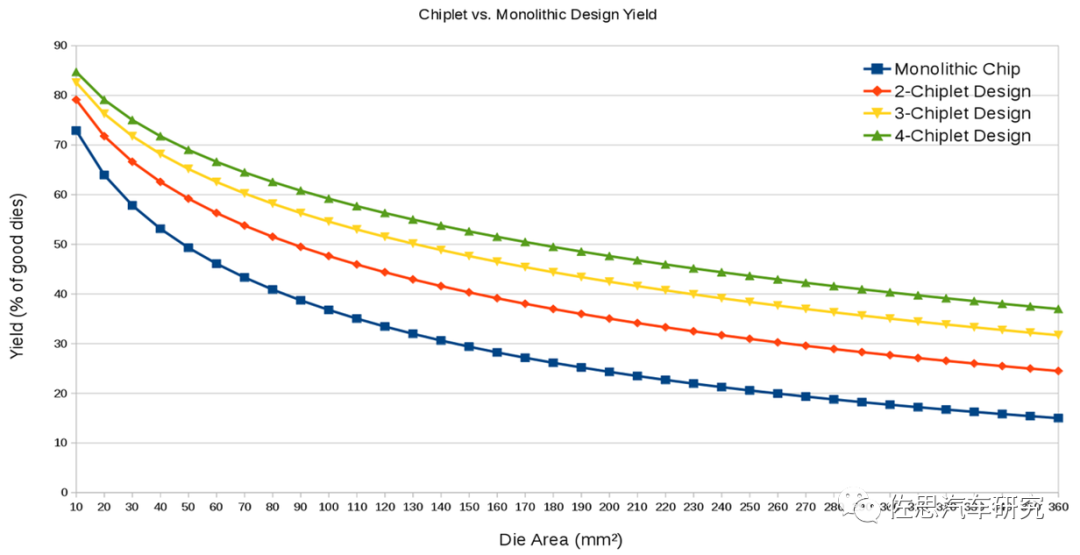
圖片來源:互聯網
上圖可以看出,單一芯片的面積越大,其良率就越低,成本就越高。

圖片來源:互聯網
典型的是AMD的32核(應該是32核小芯片)EPYC,這種方式最大優點是成本低,如果將32核封裝到一塊芯片中成本是1,那它們的MCM(Chiplet)方式只有0.59,換言之,節省了41%的成本。
通常16核是個分水嶺,16核以上的采用Chiplet才更有優勢。16核以下,Monolithic更占優勢。
GPU方面,英偉達下一代GPU會使用初級版的Chiplet即MCM。而AMD在2022年8月底就會推出第三代RNDA GPU,采用Chiplet技術,性價比會遠高于英偉達的GPU,英偉達明顯落后AMD,AMD市值超越英特爾主要原因并非CPU,而是AMD足以挑戰英偉達在GPU領域的統治地位。
基本上4096核心(流處理器,英偉達叫SM或CUDA核)是個分水嶺,4096以下Monolithic更占優勢,4096核以上Chiplet優勢明顯。
第三是靈活性和IP復用率。
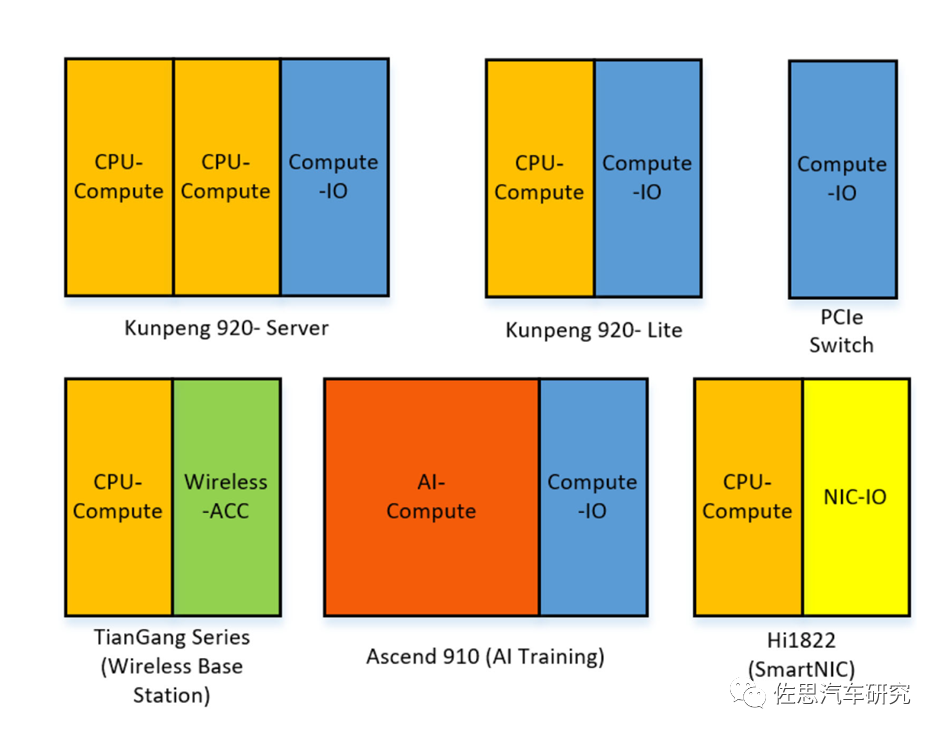
圖片來源:互聯網
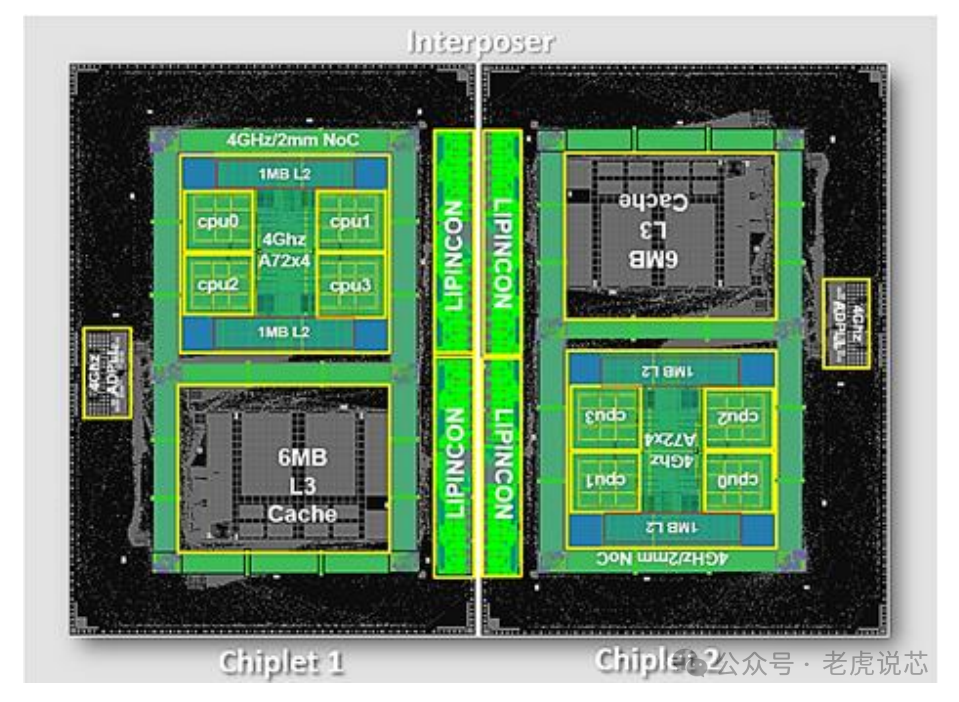
上圖是華為的Chiplet搭配,就像積木自由搭配,降低開發成本,減少開發周期,提高IP復用率。
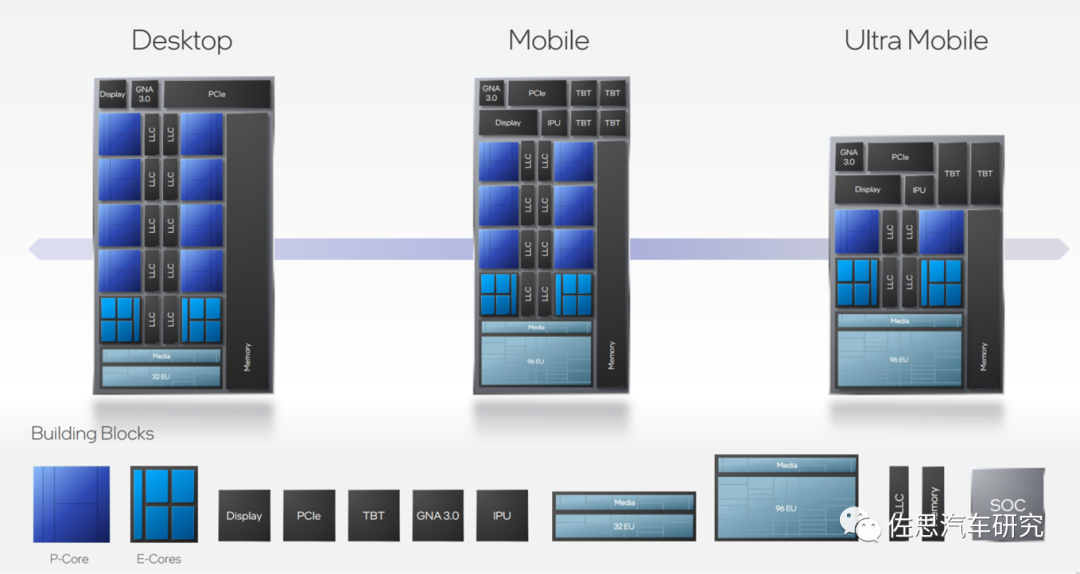
圖片來源:互聯網
英特爾的CPU設計,性能核P核,效率核E核,可以靈活調整其數量,一個設計可以針對無數種市場需求。這里不僅是設計上IP復用率,實際物理die也可以,只需要生產標準的die,產品由這些die物理拼湊膠合而成,大大節約了成本,便于生產管理和庫存管理。
Chiplet有沒有可能用在汽車領域?顯然除了自動駕駛或座艙SoC外,Chiplet絕無容身之地。自動駕駛或座艙SoC領域目前只有三家即英偉達、高通和英特爾(Mobileye),或許還可以加上三星。英偉達明確不會使用Chiplet,只不過下一代GPU可能使用MCM。高通的核心是手機市場,車載和筆記本電腦都是手機的延伸,手機領域是絕無可能用Chiplet的,因為Chiplet的封裝基板面積巨大,根本塞不進手機。英特爾旗下的Mobileye倒是有這個可能。不過鑒于Mobileye獨立性很強,這個可能性不高。
Chiplet對中國廠家友好度很低,能做Chiplet的基本只有英特爾和臺積電,三星能做最初級的封裝HBM的芯片,再進一步的Chiplet完全不能勝任。今年3月,以下科技巨頭成立了UCIe聯盟,包括中國臺灣日月光(全球第一大芯片封裝廠家)、中國臺灣臺積電、微軟、谷歌云、Meta、高通、三星、AMD、ARM、英特爾,此外,英偉達和阿里巴巴也剛加入。

圖片來源:互聯網
鑒于美國剛剛通過的芯片方案,這12大廠家除阿里外都是受益者,特別是三星、臺積電和英特爾。
實際這個UCIe是英特爾主導的,就是CXL的翻版,Chiplet最難的部分是緩存一致性問題。圍繞緩存一致性出現了多個標準,有以IBM牽頭的OpenCAPI,ARM為代表支持的CCIX,英特爾為代表的CXL,AMD為代表的Gen-Z。CCIX(Cache Coherent Interconnect for Accelerators,針對加速器的緩存一致性互聯)聯盟是由AMD、ARM、Mellanox、華為、賽靈思、高通六家巨頭公司成立的標準化組織。
Compute Express Link簡稱CXL,2019年3月由英特爾牽頭成立。
CXL的頂級會員包括AMD、阿里、ARM、思科、戴爾、谷歌、惠普、華為、IBM、英特爾、Meta、微軟、英偉達、Rambus、Xilinx。CXL協議包括三個子協議:CXL. io 是IO類型,與傳統PCIe類似,CXL.cache 允許設備訪問主存和cache,CXL.memory 允許CPU訪問設備的內存。
UCIe分層
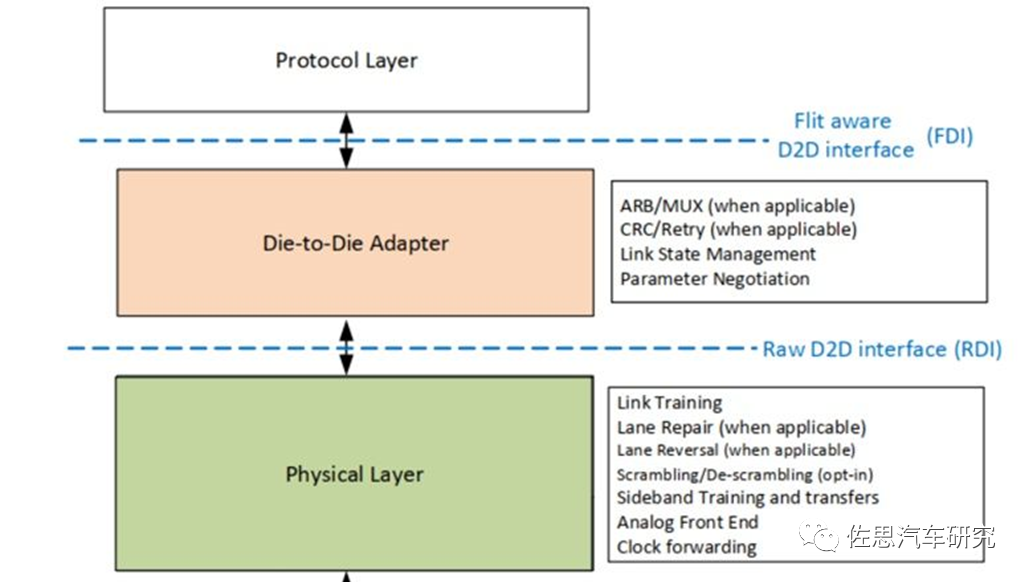
圖片來源:互聯網
UCIe主要包括協議層(Protocol Layer)、適配層(Adapter Layer)和物理層(Physical Layer)。
UCIe協議層支持已經廣泛使用的協議PCIe6.0、CXL2.0、CXL3.0,還支持用戶自定義的Streaming 協議來映射其他傳輸協議,協議層把數據轉換成Flit包進行傳輸。用戶通過用UCIe的適配層和PHY來替換PCIe/CXL的PHY和Link重傳功能,就可以實現更低功耗和性能更優的Die-to-Die互連接口。
適配層在協議層和物理層中間,當協議層有多個協議同時工作時,ARB/MUX用來在多個協議之間進行選擇和仲裁。協議層提供CRC和Retry機制以獲得更好的BER(BitError Rate)指標。同時負責Link狀態的管理,與對端UCIe Link進行協議相關參數的交換。
物理層主要用來解析Flit包在UCIe Data Lane上進行傳輸,主要包括Link Training、LaneRepair、Lane Reversal、Scrambling/De-scrambling、Sideband Training等。
UCIe支持兩種封裝,Standard Package (2D) 和Advanced Package (2.5D)。StandardPackage主要用于低成本、長距離(10mm到25mm)互連,Bump間距要求為100μm到130μm,互連線在有機襯底上進行布局布線即可實現Die間數據傳輸。基本上先進封裝被臺積電和英特爾壟斷。UCIe表面上是開放的,實際是臺積電和英特爾操控的。
短期內恐怕看不到Chiplet在汽車領域的應用,如果有的話,AMD或許是第一個。
審核編輯 :李倩
-
芯片
+關注
關注
456文章
50892瀏覽量
424324 -
存儲器
+關注
關注
38文章
7502瀏覽量
163936 -
chiplet
+關注
關注
6文章
434瀏覽量
12604
原文標題:Chiplet會用在汽車芯片上嗎?
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
解鎖Chiplet潛力:封裝技術是關鍵

Chiplet技術革命:解鎖半導體行業的未來之門

Chiplet技術有哪些優勢
ADS1299初始化配置完成后,發送START和RDATAC命令,spi總線Miso上未出現轉換數據,為什么?
IMEC組建汽車Chiplet聯盟

imec主導汽車Chiplet計劃,多家巨頭企業加入
突破與解耦:Chiplet技術讓AMD實現高性能計算與服務器領域復興

使用OPA548T器件來放大PWM電流,在還未給輸入時便出現6.2V輸出電壓,為什么?
北極雄芯獲云暉資本投資,加速Chiplet研發與產品化
Chiplet是否也走上了集成競賽的道路?
什么是Chiplet技術?
Chiplet技術對英特爾和臺積電有哪些影響呢?

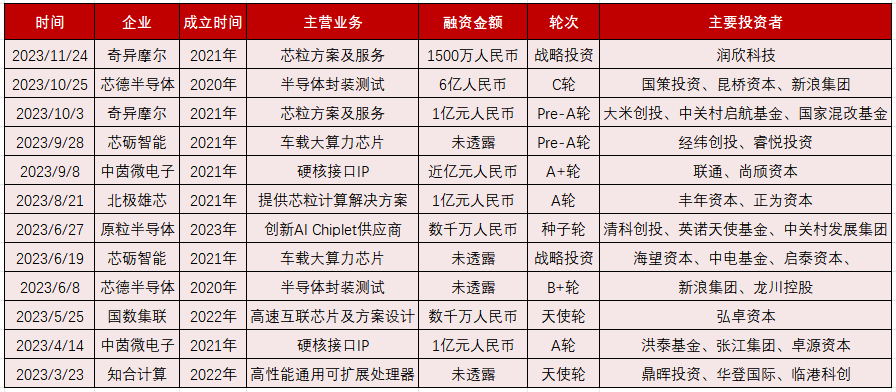
2023年Chiplet發展進入新階段,半導體封測、IP企業多次融資





 工商網監
工商網監
評論