 同一個CPU核訪問不同的內存條延時一樣嗎?
同一個CPU核訪問不同的內存條延時一樣嗎?
現在的服務器物理機一般都是多個CPU,核數也是十幾甚至幾十核。內存幾十GB甚至是上百G,也是由許多條組成的。那么我這里思考一下,這么多的CPU和內存它們之間是怎么互相連接的?同一個CPU核訪問不同的內存條延時一樣嗎?
在《內存隨機訪問也比順序慢,帶你深入理解內存IO過程》中我們了解了內存訪問時芯片內部的執行過程,在《實際測試內存在順序IO和隨機IO時的訪問延時差異》中我們又進行了實際的代碼測試。不過這兩文中我們都把精力聚焦在內存內部機制,而回避了上面的問題,那就是CPU和內存的連接方式,也就是總線架構。
1 回顧CPU與內存的簡單連接:FSB時代
我們先來回顧下在歷史上CPU、內存數量比較少的年代里的總線方案-FSB。FSB的全稱是Front Side Bus,因此也叫前端總線。CPU通過FSB總線連接到北橋芯片,然后再連接到內存。內存控制器是集成在北橋里的,Cpu和內存之間的通信全部都要通過這一條FSB總線來進行。
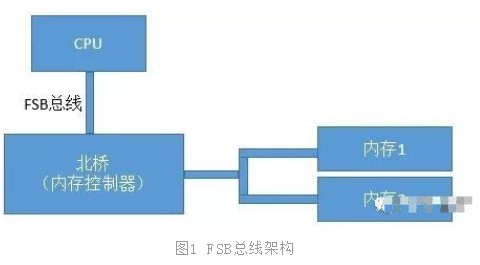
在這個年代里,當時提高計算機系統整體性能的方式就是不斷地提高CPU、FSB總線、內存條的數據傳輸頻率。
2 如今多CPU多內存復雜互聯:NUMA時代
當CPU的主頻提升到了3GHz每秒以后,硬件制造商們發現單個CPU的已經到了物理極限了。所以就改變了性能改進的方法,改成為向多核、甚至是多CPU的方向來發展。在這種情況下,如果仍然采用FSB總線,會導致所有的CPU和內存通信都經過總線,這樣總線就成為了瓶頸,無法充分發揮多核的優勢與性能。所以CPU制造商們把內存控制器從北橋搬到了CPU內部,這樣CPU便可以直接和自己的內存進行通信了。那么,如果CPU想要訪問不和自己直連的內存條怎么辦呢?所以就誕生了新的總線類型,它就叫QPI總線。
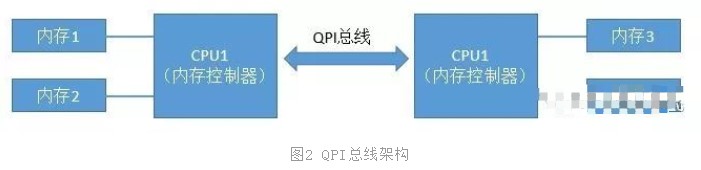
圖2中CPU1如果想要訪問內存3的話,就需要經過QPS總線才可以。
3 動手查看Linux下的NUMA架構
我們先通過dmidecode命令查看一下內存插槽,單條大小等信息。大家可以試著在linux上執行以下該命令。輸出結果很長,大家可以有空仔細研究。我這里不全部介紹,這里只挑選一些和內存相關的:
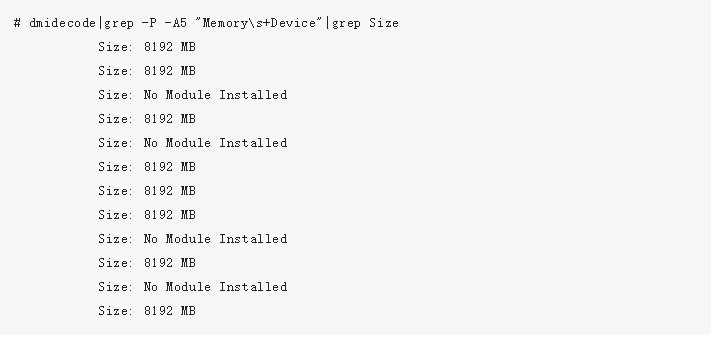
可以看出,我當前使用的機器上共有16個內存插槽,共插了8條8G的內存。所以總共是64GB。如我們前面所述,在NUMA架構里,每一個物理CPU都有不同的內存組,通過numactl命令可以查看這個分組情況。

通過上述命令可以看到,每一組CPU核分配了32GB(4條)的內存。node distance是一個二維矩陣,描述node訪問所有內存條的延時情況。node 0里的CPU訪問node 0里的內存相對距離是10,因為這時訪問的內存都是和該CPU直連的。而node 0如果想訪問node 1節點下的內存的話,就需要走QPI總線了,這時該相對距離就變成了21。
所以、在NUMA架構下,CPU訪問自己同一個node里的內存要比其它內存要快!
4 動手測試NUMA架構內存延遲差異
numactl命令有--cpubind和--membind的選項,通過它們我們可以指定我們要用的node節點。還沿用《實際測試內存在順序IO和隨機IO時的訪問延時差異》里的測試代碼
1、讓內存和CPU處于同一個Node
下面代碼可能需要左右滑動
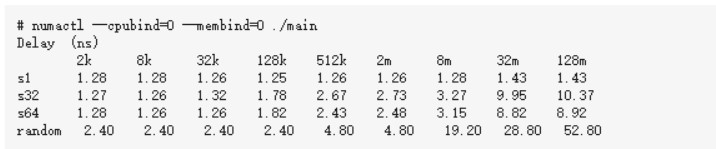
2、讓內存和CPU處于不同Node
下面代碼可能需要左右滑動
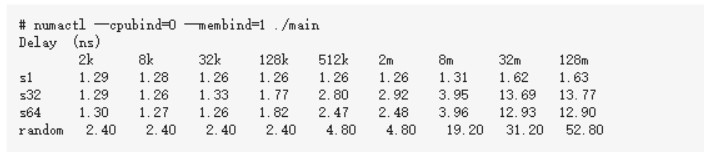
5 結論
通過上面的各個小節我們可以看到,現代的服務器里,CPU和內存條都有多個,它們之前目前主要采用的是復雜的NUMA架構進行互聯,NUMA把服務器里的CPU和內存分組劃分成了不同的node。從上述實驗結果來看,拿8M數組,循環步長為64的case來說,同node耗時3.15納秒,跨node為3.96納秒。所以屬于同一個node里的CPU和內存之間訪問速度會比較快。而如果跨node的話,則需要經過QPI總線,總體來說,速度會略慢一些。
審核編輯:劉清
-
cpu
+關注
關注
68文章
10855瀏覽量
211602 -
服務器
+關注
關注
12文章
9129瀏覽量
85338 -
總線
+關注
關注
10文章
2878瀏覽量
88055 -
FSB
+關注
關注
0文章
7瀏覽量
9393
發布評論請先 登錄
相關推薦

FPGA對DDRSDRAM內存條的控制
內存條買單條跟雙條的區別解析
加內存條需要注意什么
內存條的什么屬性重要應該如何選擇
如何選擇合適的內存條?內存條的什么屬性最重要
怎么區分內存條的單面和雙面
內存條壞了會出現什么狀況_內存條壞了如何解決
內存條起著什么樣的作用
如何讓RTOS多任務訪問同一個UART?
兩個網絡IP地址是否在同一個段中的判斷方法





 工商網監
工商網監
評論