") Untether AI引領通用AI推理加速器市場
Untether AI引領通用AI推理加速器市場
憑借其獨特的at-memory計算架構,Untether AI希望引領通用AI推理加速器市場。這家初創(chuàng)公司能否取代主導AI訓練領域、并將觸角伸向AI推理領域的領先CPU和GPU供應商?這些令人印象深刻的展示足以讓這家公司成功嗎? Untether AI是一家總部位于多倫多的AI芯片初創(chuàng)公司,上周在Hot Chips 2022上發(fā)布了其最新的通用AI推理加速器,名為speedAI,基于該公司的“at-memory”計算架構。
SpeedAI旨在解決AI計算工作量的爆炸性增長,以及在廣泛的AI推理應用中對更高精度、更低延遲、更靈活和更優(yōu)能效日益增長的需求。
Untether AI專注于推理應用,正試圖模仿Nvidia在AI訓練方面的成功。
AI處理分為兩個階段。在訓練階段,開發(fā)人員向他們的模型提供一個經過策劃的數(shù)據(jù)集,這樣它就可以“學習”它將分析的數(shù)據(jù)類型所需的一切。然后,在推理階段,模型可以根據(jù)實時數(shù)據(jù)進行預測,產生可操作的結果。后者正是Untether AI所追求的細分市場。
Untether AI的目標是否過于雄心勃勃?也許。但基于其芯片前所未有的30 TFLOPS/W和2 PFLOPS的性能,Untether AI相信它有機會。該公司聲稱其最新的推理加速器“為能效和計算密度設定了新的標準”。
Yole Intelligence計算和軟件技術和市場分析師Adrien Sanchez稱speedAI的30FLOPS/W“令人印象深刻”。他補充說,這擊敗了Nvidia的A100,并與Nvidia的Hopper設備相媲美。Sanchez說:“誠然,將為訓練量身定制的硬件與以推理為重點的硬件進行比較是完全不同的,但這仍然令人印象深刻。”AI推理市場涵蓋了從自動駕駛汽車到智能城市/零售、自然語言處理和科學應用等方方面面。
處在十字路口的AI推理
在當今的通用AI處理器市場,Nvidia無疑是訓練領域的王者。盡管Nvidia的高功耗解決方案不太適合AI推理應用,但在現(xiàn)實中,許多Nvidia客戶最終也會使用Nvidia基于GPU的解決方案來滿足他們的推理需求。
然而,AI推理市場正處于十字路口。許多用戶很難在AI推理引擎中找到能效和靈活性之間的折中方案。
一方面,有廣泛使用的基于CPU和GPU的解決方案。另一方面,許多推理處理器通常專門作為視覺處理器。Untether AI公司產品副總裁Bob Beachler表示,Mobileye和Ambarella等公司“可以在它們的SoC上實現(xiàn)一些AI功能,其中一些已經成功實現(xiàn)了量產。”
在目前碎片化的AI推理市場中,缺少一種能夠處理各種應用中AI工作負載的推理引擎。
TechInsights的首席分析Linley Gwennap認為,“考慮到神經網絡的多樣性和變化”,即使是用于推理,最佳解決方案仍是通用AI處理器。另一種選擇是“一種更具體的處理器,例如,只在卷積網絡上工作”。
Gwennap說:“GPU更加通用,這就是為什么它如此普遍的原因。”Untether AI(在speedAI)增加了更多的靈活性,以滿足AI推理應用的這些更廣泛的需求。
可擴展的產品系列
Beachler表示,Untether AI將把speedAI變成一個可擴展的系列。上周發(fā)布的SpeedAI 240被是最大的設備,而一些列的縮小版(在不同的功率節(jié)點上有更少的memory bank)正在開發(fā)中。這些加速器的功率范圍從10W到5W甚至是亞瓦,Beachler說,因此“我們的芯片可以成為任何嵌入式SoC的協(xié)處理器,這取決于你可能需要多少AI計算。”
SpeedAI 240計劃在2023年初出樣。按比例縮小的推理加速器計劃在明年晚些時候推出。
At-memory計算
Untether AI之所以出名,是因為它自己發(fā)明了一種“at-memory”計算架構。
這家初創(chuàng)公司設計了at-memory計算,將其AI推理加速器從CPU和GPU馮·諾伊曼架構固有的低能效中解放出來。這是因為在馮·諾伊曼架構下,數(shù)據(jù)從DRAM傳輸?shù)奖镜鼐彺妫缓筮M入處理元素的距離要遠得多。
Untether AI的at-memory方案在數(shù)據(jù)駐留的地方處理,專用SRAM使用短而寬的總線。這種memory bank架構允許AI計算所需的效率和帶寬,同時支持計算的大規(guī)模并行直接連接。
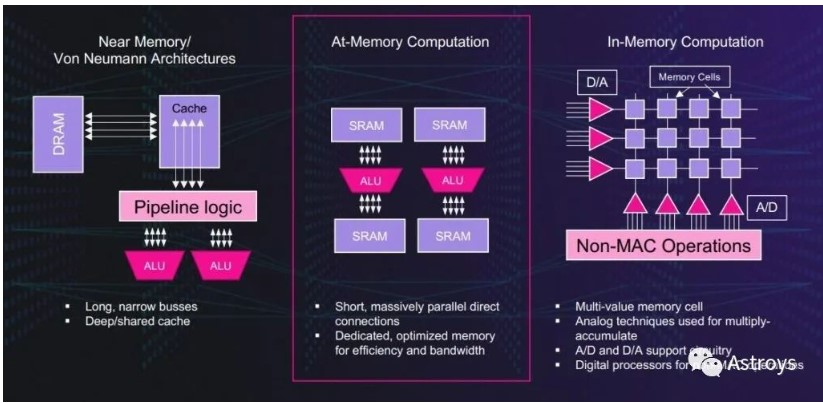
Untether AI使用At-Memory Computation進行AI加速。
這并不是UntetherAI的at-memory計算架構的第一次展示。該公司首先通過其最初的AI推理加速器runAI展示了其方法的優(yōu)勢。runAI于2020年秋季宣布將于本季度投產。
對于新的speedAI架構,Untether AI在能效、準確性和吞吐量方面增加了許多改進。它們包括第二代at-memory計算架構,超過1400個經過優(yōu)化的RISC-V處理器與定制指令,并采用浮點數(shù)據(jù)類型FP8,用于增強推理加速。這些指標標志著runAI的原始性能(Integer數(shù)據(jù)類型為8個TOPS/W)提高到30TFLOPS/W(浮點計算)。
near-memory/馮·諾伊曼架構帶來的吞吐量和能效不足等局限性是眾所周知的。像Mythics這樣的芯片設計公司一直在推廣所謂的“in-memory計算”。
然而,at-memory計算是不同的。Beachler:“人們試圖用內存單元來做乘積。”他解釋說,問題是“你試圖使用模擬技術,這導致了模擬效應,意味著你需要在它周圍安裝很多補償電路。”他補充說,額外的電路并不能使in-memory計算設備更高效。
相比之下,在Untether AI,“我們將處理元素直接附加到標準SRAM單元上。”SpeedAI是數(shù)字化的,采用了TSMC 7nm CMOS技術。Beachler補充道:“我們圍繞SRAM做所有的事情,最大限度地降低功耗。我們不做緩存,每個算術邏輯單元都有自己的內存。”
RISC-V處理器
Untether AI第二代at-memory計算架構的獨特之處在于使用了RISC-V處理器。
兩年半前,當Beachler加入Untether AI時,他曾問團隊:“我知道你們?yōu)槭裁床皇褂?a target="_blank">Arm,但你們?yōu)槭裁床皇褂肦ISC-V處理器呢?”
對于runAI,Untether AI必須設計一個定制的RISC處理器。Beachler說,RISC-V的生態(tài)系統(tǒng)“還沒有完全形成”。
對于speedAI,團隊“添加了一堆擴展指令,我們稱之為自定義指令,超過20多個”。Beachler解釋道:“這是特定于我們正在進行的計算類型的,包括神經網絡計算,以及我們的at-memory計算架構。”
Beachler指出,這種定制化是Untether AI即使在今天的Arm處理器上也無法做到的,因為Arm不開放其指令集。相反,“RISC-V允許這種情況發(fā)生。我們能夠用我們自己的指令設計自己的定制處理器,但我們仍然使用RISC-V指令集架構。”
MemoryBank
Untether AI的第二代memory bank將使用RISC-V處理器,用于靈活、高效的AI加速。
據(jù)Untether AI稱,speedAI架構中的每個memory bank都有512個處理元素,直接連接到專用SRAM。這些處理元素支持INT4、FP8、INT8和BF16數(shù)據(jù)類型,以及用于節(jié)能的零檢測電路,并支持2:1結構稀疏性。
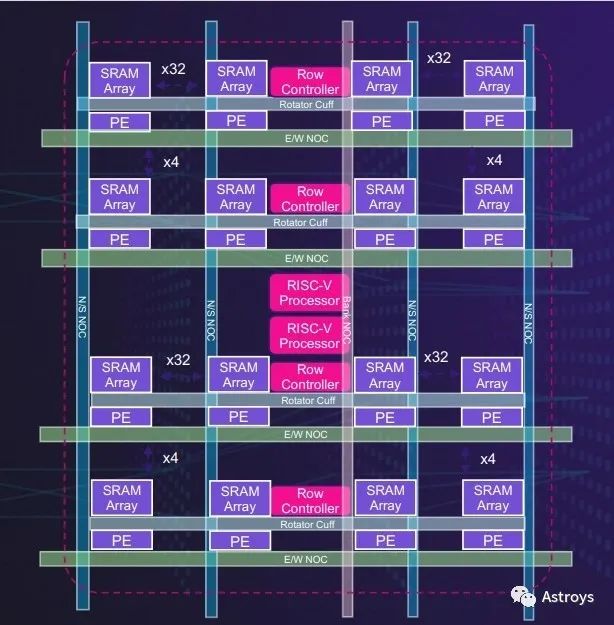
SpeedAI加速器使用雙多線程RISC-V來提高memory bank的編程靈活性。
以8行64個處理元素排列,每一行有自己的專用行控制器和硬接線減少功能,以允許編程的靈活性和變壓器網絡功能的高效計算。
兩個RISC-V處理器(每個處理器都有20多條用于推理加速的定制指令)管理各行。該公司表示,這種靈活的memory bank可以適應許多不同的神經網絡架構,包括卷積、transformer和推薦網絡以及線性代數(shù)模型。
精度問題
除了能效,UntetherAI團隊還專注于提高其高速AI芯片的AI精度。Beachler說:“AI推理芯片的用戶發(fā)現(xiàn),當他們進行量化步驟時,有時會出現(xiàn)不可接受的準確性損失。對于某些應用來說,這沒問題,但當AI推理加速器用于推薦引擎和自動駕駛汽車時就不行了。”
Beachler解釋說,在AI推薦引擎中,“如果你的準確率僅下降0.1%,就可能會損失5000萬至1億美元的廣告收入,因為你向消費者提供了錯誤的廣告或推薦。準確性很重要的另一個領域是自動駕駛汽車,因為車廠在準確性上不會妥協(xié)。”
今年早些時候,當Nvidia宣布其Hopper架構時,這家GPU巨頭談到了一種新的8位浮點(FP8)數(shù)據(jù)類型。與標準的FP16訓練相比,F(xiàn)P8格式的吞吐量增加了一倍。
SpeedAI也在使用FP8。經過自己的研究,該團隊得出結論,兩種不同的FP8格式為AI推理提供了精度、范圍和效率的最佳組合。該公司解釋說,將4-尾數(shù)(FP8p用于精度)和3-尾數(shù)(FP8r用于范圍)相結合,為跨各種不同網絡的推理提供了最佳的精度和吞吐量。”
對于卷積網絡,Untether AI聲稱,使用FP8“與使用BF16數(shù)據(jù)類型相比,精度損失不到1%的十分之一,吞吐量和能效提高了四倍”。
不是“一刀切”
為什么市場需要一個通用的AI推理加速器?首先,因為AI推理加速應用的出現(xiàn)。
Beachler指出,除了中央計算系統(tǒng)必須處理越來越多感知數(shù)據(jù)的自動駕駛汽車之外,智能城市還部署著廣泛的監(jiān)控市場。“他們需要聚集數(shù)百個攝像頭來生成實時可操作的情報。”這同樣適用于軍事AI應用,例如對抗無人機。“他們試圖用不同的傳感器掃描天空,以對抗無人機。或者他們會尋找雷達信號,以了解空域內的情況。”其他的AI推理應用包括自然語言處理加速,Untether AI將其加入到speedAI中。
Yole Intelligence的Sanchez表示,通用AI推理的其他應用包括實時分類的智能零售、金融領域的語音到文本、企業(yè)數(shù)據(jù)中心和高性能計算領域的氣候建模。
其次,神經網絡以及客戶在執(zhí)行AI時使用它們的方式有無數(shù)種變化。Beachler說:“我們已經分析了50多個不同的客戶神經網絡。每個都是不同的。他們可能從基本的開始,但隨后他們會做出“適合他們數(shù)據(jù)集和訓練”的偏差。
綜上所述,你需要的是具有擴展性和靈活性的AI推理加速器架構。
然而,目前許多AI應用都依賴于現(xiàn)有的通用CPU和GPU。對于服務器中的AI應用,Sanchez說:“我們看到大部分的推理都是由CPU完成的。這是因為對推理任務的需求是零星的。對于客戶來說,使用幾個Xeon或Epyc內核進行快速推理比使用整個硬件池更方便。”
Untether AI面臨的一大挑戰(zhàn)是識別需要專用推理硬件的細分市場。Sanchez說:“超擴展性和服務器分離可能會增加推理專用硬件應對挑戰(zhàn)的機會。”
軟件陷阱
曾在Altera工作過的Beachler(就像Untether AI執(zhí)行團隊的許多成員一樣)很清楚軟件和工具流的重要性。就像FPGA客戶遇到了軟件編譯問題或擬議硬件架構的利用率很差一樣,一些AI芯片客戶也遇到了類似的問題,“你不能編程,或者它太難編程。”
Beachler說:“正如我們在Altera學到的,我們確保我們的工具永遠是行業(yè)中最好的,我們在Untether AI也在努力做同樣的事,對軟件進行過度投資。”
然而,Untether AI還沒有提交給MLPerf對其AI芯片進行基準測試。Beachler說,公司的工程團隊被50個客戶拉去做50個不同的神經網絡,這家初創(chuàng)公司的首要任務是“確保軟件能夠運行所有這些不同的神經網絡”。
他說,這些都是“任何AI初創(chuàng)公司都會遇到的成長的痛苦”。但UntetherAI的首個AI加速器runAI已經投入使用,并為客戶運行網絡。
與大量現(xiàn)成的特定應用AI推理引擎不同,Untether AI的AI推理加速器被設計為通用設備。然而,這家初創(chuàng)公司似乎被拉向了多個方向,以滿足客戶的不同需求。Untether AI成功的關鍵在于它的軟件和編程工具,讓客戶在使用Untether AI的加速器時能夠獨立地做出自己的偏差和修改。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19349瀏覽量
230293 -
cpu
+關注
關注
68文章
10882瀏覽量
212224 -
加速器
+關注
關注
2文章
802瀏覽量
37936 -
gpu
+關注
關注
28文章
4754瀏覽量
129071
發(fā)布評論請先 登錄
相關推薦
Untether發(fā)布人工智能(AI)芯片
NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案

SiFive發(fā)布MX系列高性能AI加速器IP
AMD助力HyperAccel開發(fā)全新AI推理服務器

下一代高功能新一代AI加速器(DRP-AI3):10x在高級AI系統(tǒng)高級AI中更快的嵌入處理

西門子推出Catapult AI NN軟件,賦能神經網絡加速器設計
美國限制向中東AI加速器出口,審查國家安全
Arm發(fā)布新一代Ethos-U AI加速器 Arm旨在瞄準國產CPU市場
Arm推動生成式AI落地邊緣!全新Ethos-U85 AI加速器支持Transformer 架構,性能提升四倍






 工商網監(jiān)
工商網監(jiān)
評論