

日志,對于一個程序的重要程度不言而喻。無論是作為排查問題的手段,記錄關鍵節點信息,或者是預警,配置監控大盤等等,都扮演著至關重要的角色。是每一類,甚至每一個應用程序都需要記錄和查看的重要內容。而在云原生時代,日志采集無論是在采集方案,還是在采集架構上,都會和傳統的日志采集有一些差異。我們匯總了一下在日志的采集過程中,經常會遇到一些實際的通用問題,例如:
部署在 K8s 的應用,磁盤大小會遠遠低于物理機,無法把所有日志長期存儲,又有查詢歷史數據的訴求
日志數據非常關鍵,不允許丟失,即使是在應用重啟實例重建后
希望對日志做一些關鍵字等信息的報警,以及監控大盤
權限管控非常嚴格,不能使用或者查詢例如 SLS 等日志系統,需要導入到自己的日志采集系統
JAVA,PHP 等應用的異常堆棧會產生換行,把堆棧異常打印成多行,如何匯總查看呢?
那么在實際生產環境中,用戶是如何使用日志功能采集的呢?而面對不同的業務場景,不同的業務訴求時,采用哪種采集方案更佳呢?Serverless 應用引擎 SAE(Serverless App Engine)作為一個全托管、免運維、高彈性的通用 PaaS 平臺,提供了 SLS 采集、掛載 NAS 采集、Kafka 采集等多種采集方式,供用戶在不同的場景下使用。本文將著重介紹各種日志采集方式的特點,最佳使用場景,幫助大家來設計合適的采集架構,并規避一些常見的問題。
SAE 的日志采集方式
Cloud Native
SLS 采集架構
SLS 采集日志是 SAE 推薦的日志采集方案。一站式提供數據采集、加工、查詢與分析、可視化、告警、消費與投遞等能力。
SAE 內置集成了 SLS 的采集,可以很方便的將業務日志,容器標準輸出采集到 SLS 。SAE 集成 SLS 的架構圖如下圖所示: 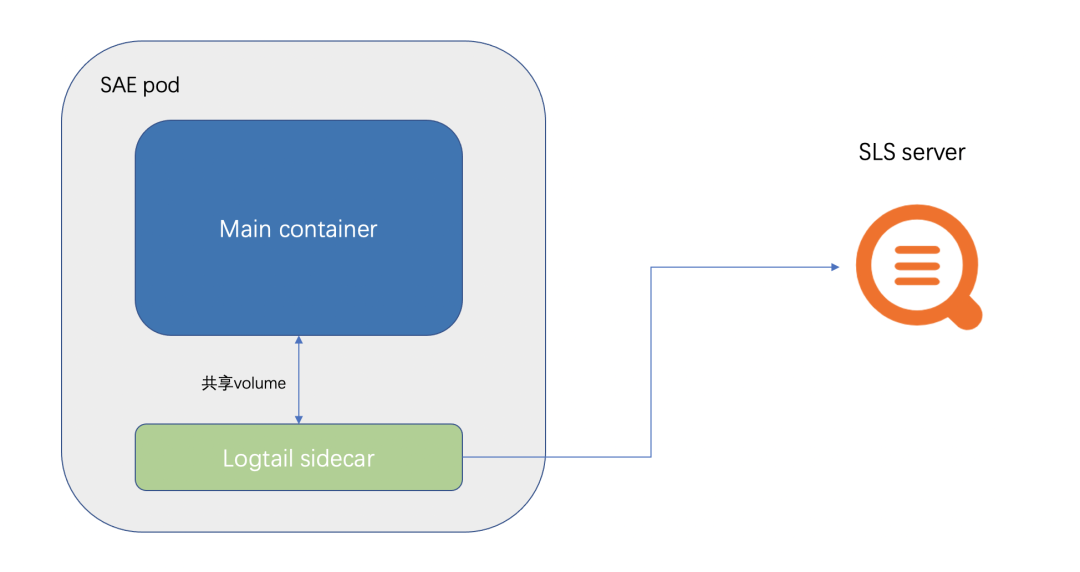
SAE 會在 pod 中,掛載一個 logtail (SLS 的采集器)的 Sidecar。
然后將客戶配置的,需要采集的文件或者路徑,用 volume 的形式,給業務 Container 和 logtail Sidecar 共享。這也是 SAE 日志采集不能配置/home/admin 的原因。因為服務的啟動容器是放在/home/admin 中,掛載 volume 會覆蓋掉啟動容器。
同時 logtail 的數據上報,是通過 SLS 內網地址去上報,因此無需開通外網。
SLS 的 Sidecar 采集,為了不影響業務 Container 的運行,會設置資源的限制,例如 CPU 限制在 0.25C ,內存限制在 100M。
SLS 適合大部分的業務場景,并且支持配置告警和監控圖。絕大多數適合直接選擇 SLS 就可以了。
NAS 采集架構
NAS 是一種可共享訪問、彈性擴展、高可靠以及高性能的分布式文件系統。本身提供高吞吐和高 IOPS 的同時支持文件的隨機讀寫和在線修改。比較適合日志場景。如果想把比較多或比較大的日志在本地留存,可以通過掛載 NAS,然后將日志文件的保存路徑指向 NAS 的掛載目錄即可。NAS 掛載到 SAE 不牽扯到太多技術點和架構,這里就略過不做過多的介紹了。
NAS 作為日志采集時,可以看作是一塊本地盤,即使實例崩潰重建等等各種以外情況,也都不會出現日志丟失的情況,對于非常重要,不允許丟失數據的場景,可以考慮此方案。
Kafka 采集架構
用戶本身也可以將日志文件的內容采集到 Kafka,然后通過消費 Kafka 的數據,來實現日志的采集。后續用戶可以結合自身的需求,將 Kafka 中的日志導入到 ElasticSearch ,或者程序去消費 Kafka 數據做處理等。
日志采集到 Kafka本身有多種方式,例如最常見的 logstach,比較輕量級的采集組建 filebeat,vector 等等。SAE 使用的采集組件是 vector,SAE 集成 vector 的架構圖如下圖所示: 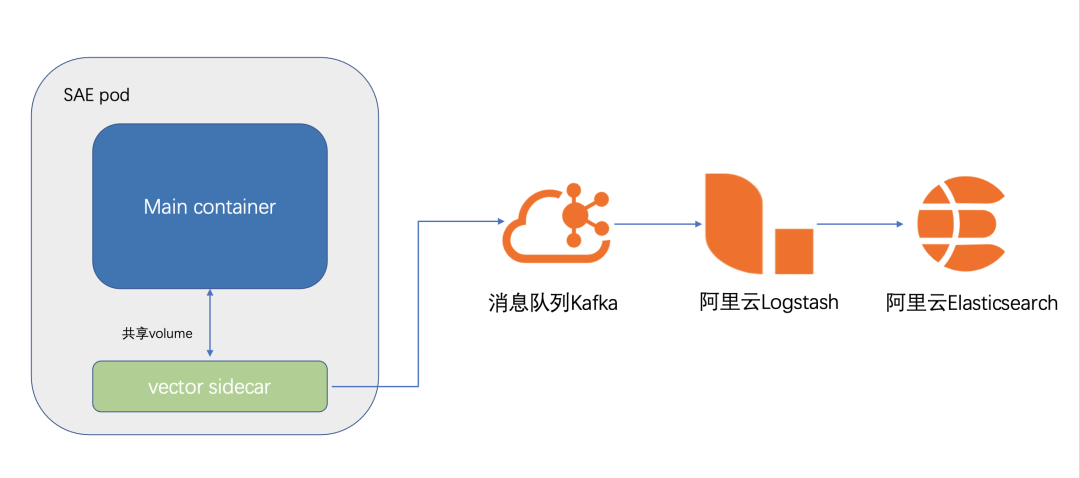
SAE 會在 pod 中,掛載一個 logtail(vector 采集器)的 Sidecar。
然后將客戶配置的,需要采集的文件或者路徑,用 volume 的形式,給業務 Container 和 vector Sidecar 共享
vector 會將采集到的日志數據定時發送到 Kafka。vector 本身有比較豐富的參數設置,可以設置采集數據壓縮,數據發送間隔,采集指標等等。
Kafka 采集算是對 SLS 采集的一種補充完善。實際生產環境下,有些客戶對權限的控制非常嚴格,可能只有 SAE 的權限,卻沒有 SLS 的權限,因此需要把日志采集到 Kafka 做后續的查看,或者本身有需求對日志做二次處理加工等場景,也可以選擇 Kafka 日志采集方案。 下面是一份基礎的 vector.toml 配置:
data_dir = "/etc/vector"
[sinks.sae_logs_to_kafka]
type = "kafka"
bootstrap_servers = "kafka_endpoint"
encoding.codec = "json"
encoding.except_fields = ["source_type","timestamp"]
inputs = ["add_tags_0"]
topic = "{{ topic }}"
[sources.sae_logs_0]
type = "file"
read_from = "end"
max_line_bytes = 1048576
max_read_bytes = 1048576
multiline.start_pattern = '^[^\s]'
multiline.mode = "continue_through"
multiline.condition_pattern = '(?m)^[\s|\W].*$|(?m)^(Caused|java|org|com|net).+$|(?m)^\}.*$'
multiline.timeout_ms = 1000
include = ["/sae-stdlog/kafka-select/0.log"]
[transforms.add_tags_0]
type = "remap"
inputs = ["sae_logs_0"]
source = '.topic = "test1"'
[sources.internal_metrics]
scrape_interval_secs = 15
type = "internal_metrics_ext"
[sources.internal_metrics.tags]
host_key = "host"
pid_key = "pid"
[transforms.internal_metrics_filter]
type = "filter"
inputs = [ "internal_metrics"]
condition = '.tags.component_type == "file" || .tags.component_type == "kafka" || starts_with!(.name, "vector")'
[sinks.internal_metrics_to_prom]
type = "prometheus_remote_write"
inputs = [ "internal_metrics_filter"]
endpoint = "prometheus_endpoint"
重要的參數解析:
multiline.start_pattern 是當檢測到符合這個正則的行時,會當作一條新的數據處
multiline.condition_pattern 是檢測到符合這個正則的行時,會和上一行做行合并,當作一條處理
sinks.internal_metrics_to_prom 配置了之后,會將配置一些 vector 的采集元數據上報到 prometheus
下面是配置了 vector 采集的元數據到 Prometheus,在 Grafana 的監控大盤處配置了 vector 的元數據的一些采集監控圖: 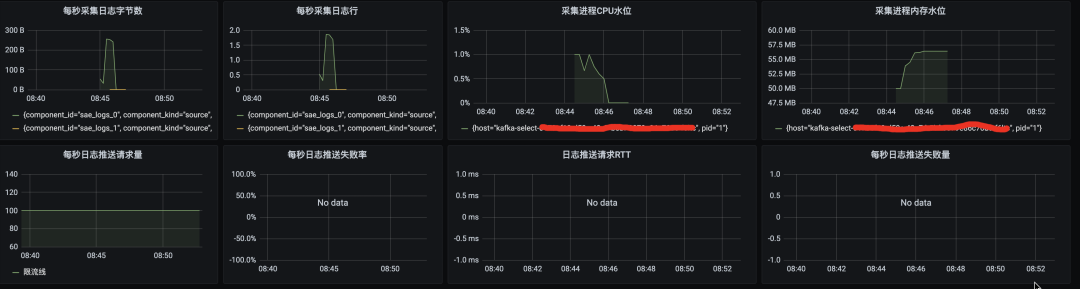
最佳實踐
Cloud Native
在實際使用中,可以根據自身的業務訴求選擇不同的日志采集方式。本身 logback 的日志采集策略,需要對文件大小和文件數量做一下限制,不然比較容易把 pod 的磁盤打滿。以 JAVA 為例,下面這段配置,會保留最大 7 個文件,每個文件大小最大 100M。
這段 log4j 的配置,是一種比較常見的日志輪轉配置。 常見的日志輪轉方式有兩種,一種是 create 模式,一種是 copytruncate 模式。而不同的日志采集組件,對兩者的支持程度會存在一些區別。 create 模式是重命名原日志文件,創建新的日志文件替換。log4j 使用的就是這種模式,詳細步驟如下圖所示: 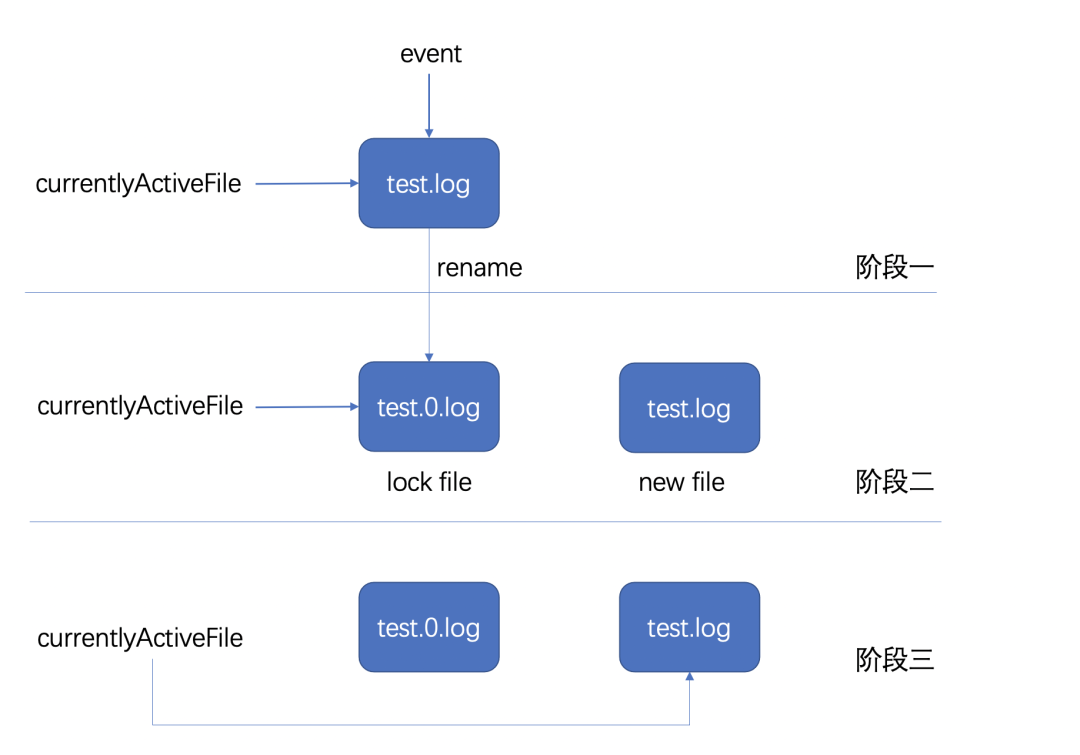
當日志的 event log 寫入前會判斷是否達到文件設置最大容量,如果沒達到,則完成寫入,如果達到了,則會進入階段二
首先關閉當前 currentlyActiveFile 指向的文件,之后對原文件進行重命名,并新建一個文件,這個文件的名字和之前 currentlyActiveFile 指向的名字一致
把 currentlyActiveFile 指向的文件變為階段二新創建的文件
copytruncate 模式的思路是把正在輸出的日志拷(copy)一份出來,再清空(trucate)原來的日志。 目前主流組件的支持程度如下:

實際案例演示
Cloud Native
下面介紹一下客戶實際生產環境中的一些真實場景。
某客戶 A 通過日志輪轉設置程序的日志,并將日志采集到 SLS。并通過關鍵字配置相關報警,監控大盤等。 首先通過 log4j 的配置,使日志文件最多保持 10 個,每個大小 200M,保持磁盤的監控,日志文件保存在/home/admin/logs 路徑下。這里不進行過多介紹了,可以最佳實踐場景介紹的配置。 隨后通過 SAE 的 SLS 日志采集功能,把日志采集到 SLS 中。 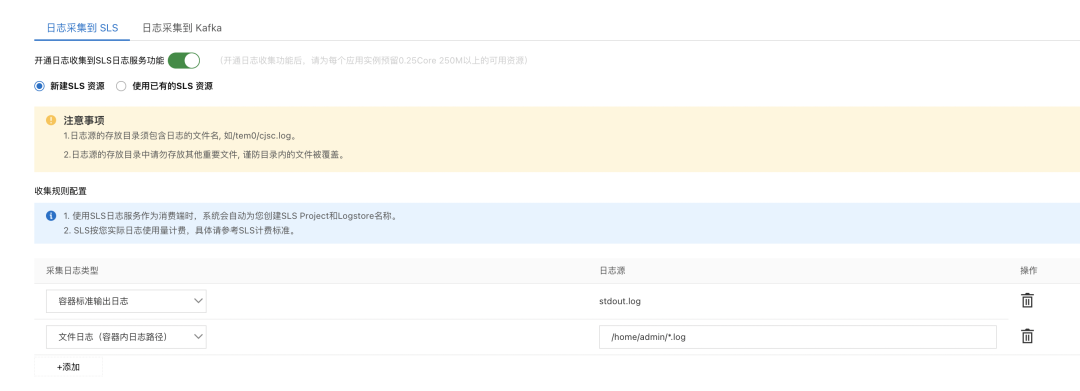
最后,通過程序中日志的一些關鍵字,或者一些其他規則,例如 200 狀態碼比例等進行了報警配置。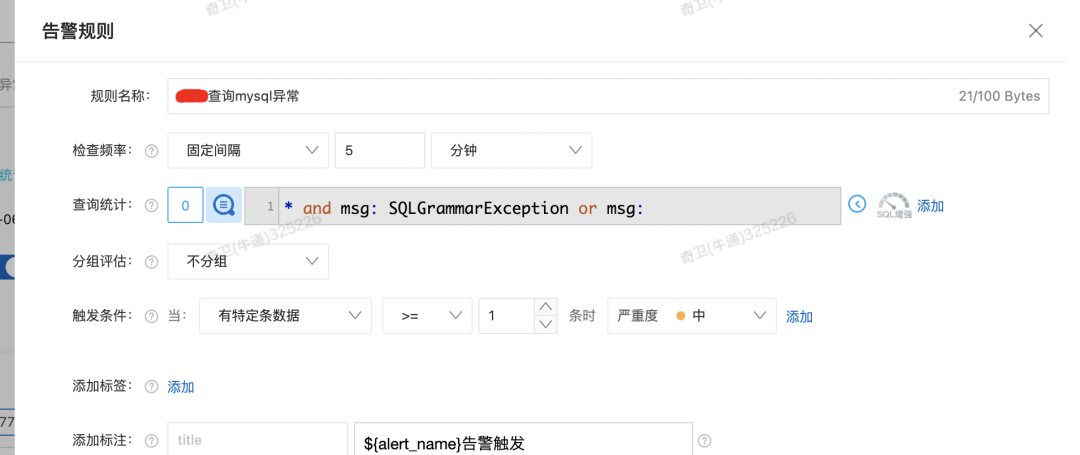
通過 Nginx 的日志完成監控大盤的配置。 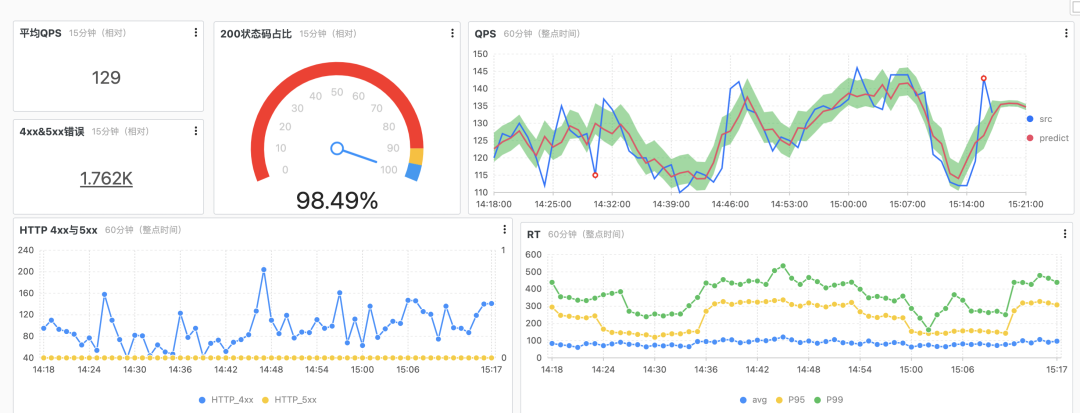
常見問題
Cloud Native
日志合并介紹
很多時候,我們需要采集日志,并不是單純的一行一行采集,而是需要把多行日志合并成一行進行采集,例如 JAVA 的異常日志等。這個時候就需要用到日志合并功能了。
在 SLS 中,有多行模式的采集模式,這個模式需要用戶設置一個正則表達式,用來做多行合并。 vector 采集也有類似的參數,multiline.start_pattern 用于設置新行的正則,符合此正則會被認為是一個新行。可以結合 multiline.mode 參數一起使用。更多參數請參看vector官網。
日志采集丟失分析
無論是 SLS 采集和 vector 采集到 Kafka 為了保證采集日志不丟失。都會將采集的點位(CheckPoint)信息保存到本地,如果遇到服務器意外關閉、進程崩潰等異常情況時,會從上一次記錄的位置開始采集數據,盡量保證數據不會丟失。
但是這并不能保證日志一定不會丟失。在一些極端場景下,是有可能造成日志采集丟失的,例如: 1. K8s pod 進程崩潰,liveness 連續失敗等異常導致 pod 重建 2. 日志輪轉速度極快,例如1秒輪轉1次。 3. 日志采集速度長期無法達到日志產生速度。 針對場景 2,3,需要去檢查自身的應用程序,是否打印了過多不必要的日志,或者日志輪轉設置是否異常。因為正常情況下,這些情況不應該出現。針對場景 1,如果對日志要求非常嚴格,在 pod 重建后也不能丟失的話,可以將掛載的 NAS 作為日志保存路徑,這樣即使在 pod 重建后,日志也不會丟失。
總結
Cloud Native
本文著重介紹了 SAE 提供了多種日志采集方案,以及相關的架構,場景使用特點。總結起來三點:
1、SLS 采集適配性強,實用大多數場景
2、NAS 采集任何場景下都不會丟失,適合對日志要求非常嚴格的場景
3、Kafka 采集是對 SLS 采集的一種補充,有對日志需要二次加工處理,或者因為權限等原因無法使用 SLS 的場景,可以選擇將日志采集到 Kafka 自己做搜集處理。
審核編輯:劉清
-
JAVA
+關注
關注
20文章
2989瀏覽量
110355 -
PHP
+關注
關注
0文章
454瀏覽量
27583 -
采集器
+關注
關注
0文章
203瀏覽量
18846 -
SLS
+關注
關注
0文章
15瀏覽量
9096
原文標題:一文搞懂SAE日志采集架構
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
頻域示波器的技術原理和應用場景
數據記錄儀的計數原理和應用場景

敏捷合成器的技術原理和應用場景
LoRaWAN的特點和應用場景
脈沖信號分析儀?的原理和應用場景
多蹤示波器的原理和應用場景
低電平靈敏專用儀器的技術原理和應用場景
便攜式示波器的技術原理和應用場景

智能IC卡測試設備的技術原理和應用場景
國產光耦繼電器的性能特點及應用場景






 工商網監
工商網監

評論