") 一篇解決表示學(xué)習(xí)坍塌問(wèn)題的工作報(bào)告
一篇解決表示學(xué)習(xí)坍塌問(wèn)題的工作報(bào)告
1 表示學(xué)習(xí)中的坍塌問(wèn)題
在表示學(xué)習(xí)中,一種很常見(jiàn)的做法是利用孿生網(wǎng)絡(luò)的結(jié)構(gòu),讓同一個(gè)樣本的不同數(shù)據(jù)增強(qiáng)后的表示相似。比如對(duì)于一張圖像,使用翻轉(zhuǎn)、裁剪等方法生成另一個(gè)增強(qiáng)圖像,兩個(gè)圖像分別經(jīng)過(guò)兩個(gè)共享參數(shù)的編碼器,得到表示,模型的優(yōu)化目標(biāo)是讓這兩個(gè)表示的距離近。
這種方法一個(gè)比較大的挑戰(zhàn)在于,模型在訓(xùn)練過(guò)程中容易出現(xiàn)坍塌問(wèn)題。模型可以把所有樣本的表示都學(xué)成完全相同的常數(shù)向量(比如每個(gè)樣本模型的輸出都是全0向量),這樣就能滿足上述兩個(gè)表示距離近的要求了。
2 解決坍塌問(wèn)題的方法
業(yè)內(nèi)有很多解決坍塌問(wèn)題的方法,主要可以分為4種類型:
對(duì)比學(xué)習(xí)方法:在訓(xùn)練一對(duì)正樣本對(duì)時(shí),同時(shí)采樣大量的負(fù)樣本,讓正樣本之間離得近,負(fù)樣本之間離得遠(yuǎn),避免模型偷懶把所有樣本的表示都學(xué)成一樣的。
聚類方法:在訓(xùn)練過(guò)程中增加一個(gè)聚類過(guò)程,將樣本分配給不同的類簇,然后在類簇級(jí)別進(jìn)行對(duì)比學(xué)習(xí)。
基于蒸餾的方法:通過(guò)模型結(jié)構(gòu)的角度避免坍塌問(wèn)題,學(xué)習(xí)一個(gè)student network來(lái)預(yù)測(cè)teacher network的表示,teacher network是student network參數(shù)的滑動(dòng)平均,teacher network不通過(guò)反向傳播更新參數(shù)。
信息最大化方法:讓生成的embedding中每一維的向量相互正交,使其信息量最大化,這樣可以避免各個(gè)維度的值信息過(guò)于冗余,防止坍塌問(wèn)題。
目前常用的負(fù)樣本采樣方法,一個(gè)比較大的問(wèn)題是計(jì)算開(kāi)銷大,取得好的效果往往需要大量負(fù)樣本,因此有了MoCo等對(duì)比學(xué)習(xí)框架。本文提出的方法基于信息最大化的思路,能夠只使用正樣本對(duì)實(shí)現(xiàn)表示學(xué)習(xí)的同時(shí),防止坍現(xiàn)象的發(fā)生。關(guān)于對(duì)比學(xué)習(xí)的常用經(jīng)典方法,可以參考這篇文章:對(duì)比學(xué)習(xí)中的4種經(jīng)典訓(xùn)練模式。
3 信息最大化方法歷史工作
基于信息最大化的方法典型的工作有兩篇ICLM 2021的文章,分別是Whitening for Self-Supervised Representation Learning(ICML 2021,W-MSE)和Barlow twins: Self-supervised learning via redundancy reduction(ICML 2021)。下面介紹一下這兩篇文章的整體思路,F(xiàn)acebook的這篇論文也是基于這個(gè)思路設(shè)計(jì)的。
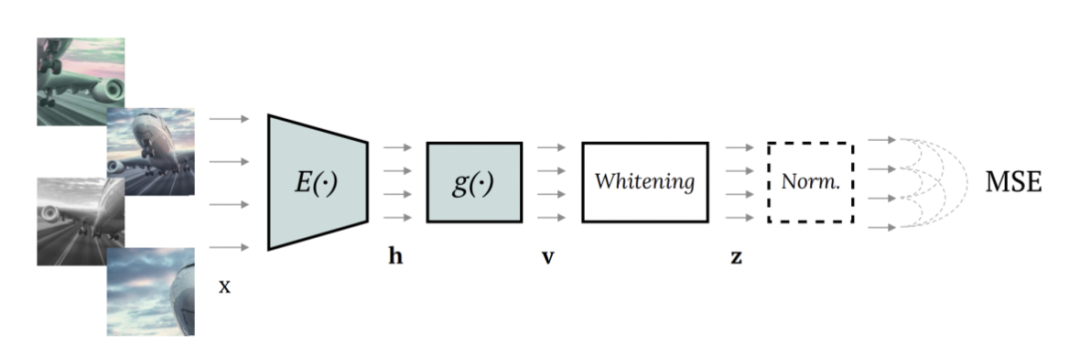
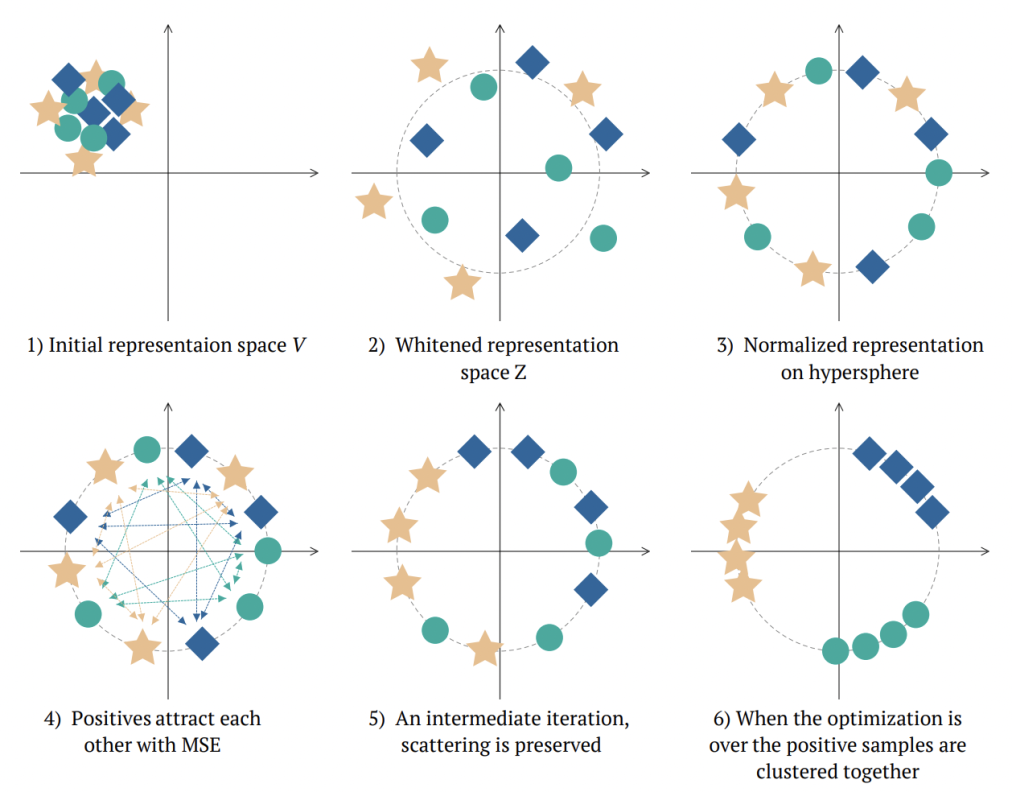
W-MSE的整體網(wǎng)絡(luò)結(jié)構(gòu)如上圖,模型中輸入一對(duì)互為正樣本的樣本對(duì)(例如一個(gè)圖像的不同增強(qiáng)形式),使用共享參數(shù)Encoder分別編碼后,增加一個(gè)whitening模塊,對(duì)每個(gè)batch內(nèi)的所有embedding進(jìn)行白化,讓embedding的各個(gè)維度變量線性無(wú)關(guān),后面再接norm處理。下圖形式化表明了W-MSE的用途,通過(guò)白化+norm讓樣本形成一個(gè)球形分布,正樣本之間距離近,每個(gè)樣本需要調(diào)整自己在圓周上的位置拉進(jìn)正樣本之間的距離,形成最終的簇。
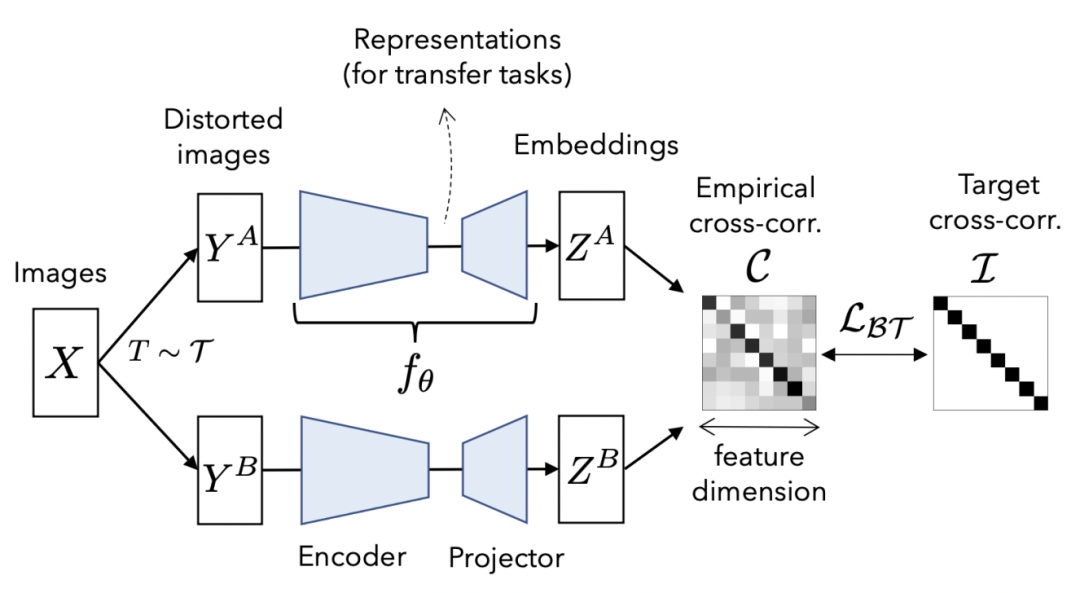
Barlow twins方法也是同樣的思路,只是做法不同。在得到一對(duì)正樣本的兩個(gè)embedding后,計(jì)算兩個(gè)向量各個(gè)變量之間的相關(guān)性矩陣,優(yōu)化這個(gè)矩陣接近對(duì)角矩陣,以此實(shí)現(xiàn)embedding中各個(gè)變量之間線性無(wú)關(guān)。
4 VICREG
Facebook團(tuán)隊(duì)提出的VICREG是上述基于信息最大化表示學(xué)習(xí)方法的一個(gè)擴(kuò)展,損失函數(shù)主要包括variance、invariance、covariance三個(gè)部分。模型的主體結(jié)構(gòu)如下,仍然是一個(gè)孿生網(wǎng)絡(luò)結(jié)構(gòu),輸入一個(gè)樣本的不同view互為正樣本。
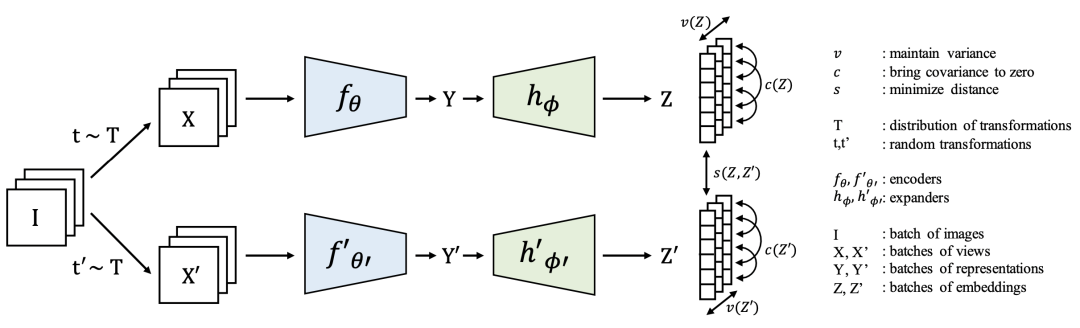
variance部分主要是讓batch內(nèi)每個(gè)樣本embedding向量的每一維變量之間的方差不小于一個(gè)值,這樣可以有效防止每個(gè)樣本的向量都對(duì)應(yīng)同一個(gè)點(diǎn)的情況,防止坍塌的發(fā)生。
invariance部分即讓正樣本對(duì)的表示embedding距離盡可能小,是正常的表示學(xué)習(xí)loss。
covariance借鑒了Barlow twins中的思路,讓batch內(nèi)的embedding非對(duì)角線元素盡可能為0,即讓表示向量各個(gè)維度變量線性無(wú)關(guān)。
最終的表示學(xué)習(xí)loss是由上述3個(gè)loss的加和:
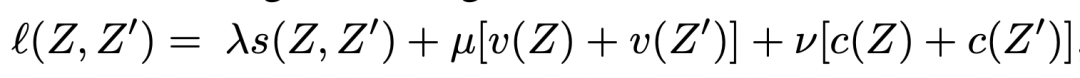
5 實(shí)驗(yàn)結(jié)果
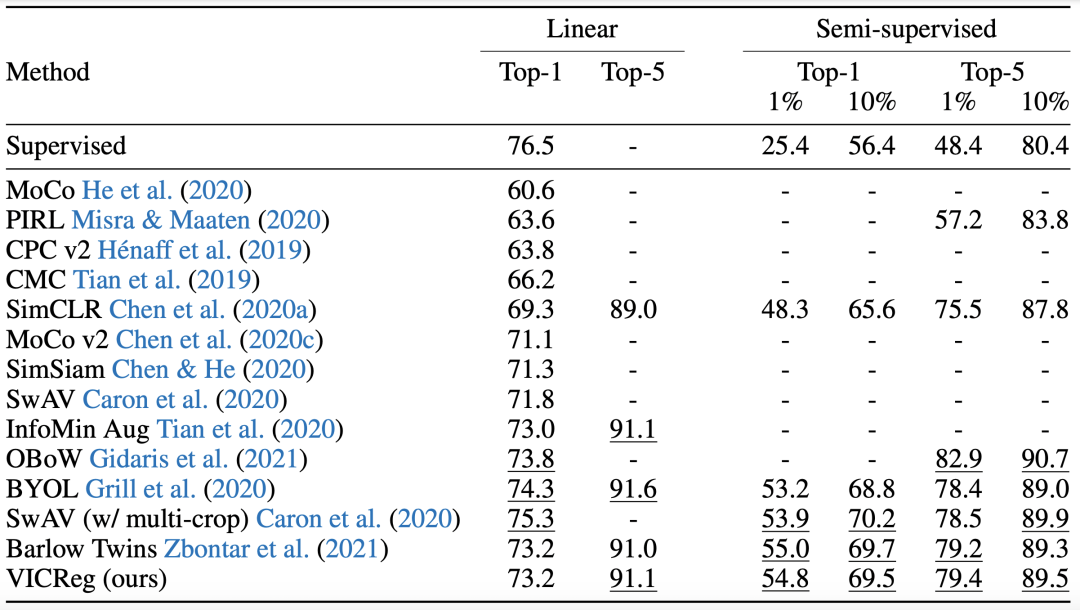
作者進(jìn)行了一些實(shí)驗(yàn)驗(yàn)證VICREG表示學(xué)習(xí)方法的效果。在ImageNet數(shù)據(jù)集上,使用不同方法預(yù)訓(xùn)練的表示接一個(gè)線性層進(jìn)行分類,或者基于預(yù)訓(xùn)練的表示使用部分?jǐn)?shù)據(jù)進(jìn)行finetune,對(duì)比圖像分類效果,實(shí)驗(yàn)結(jié)果如下:
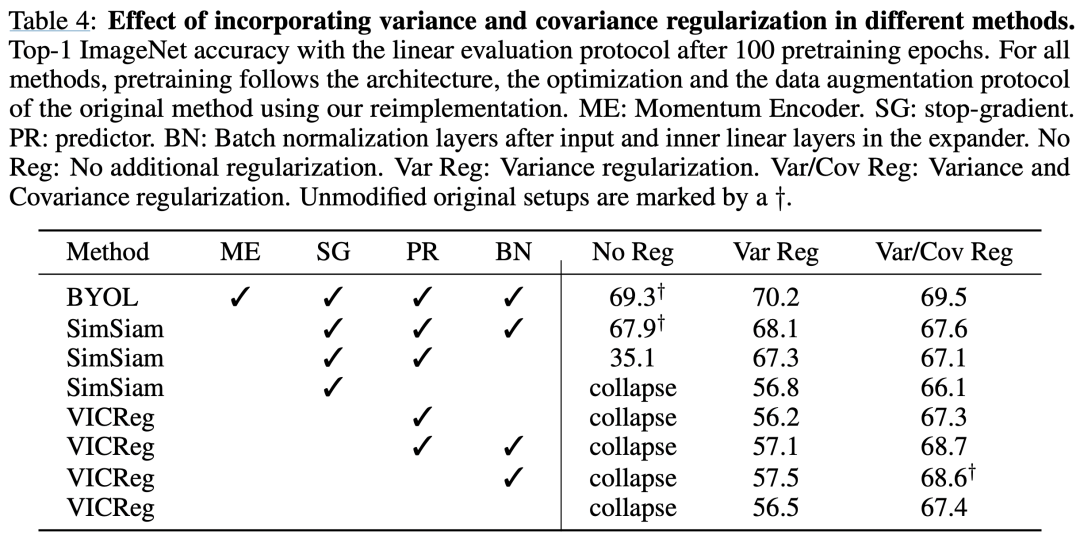
作者也對(duì)比了在不同方法上是否采用variance或covariance等loss的效果變化:
6 總結(jié)
本文介紹了Facebook AI團(tuán)隊(duì)在2022年ICLR的一篇解決表示學(xué)習(xí)坍塌問(wèn)題的工作,順帶介紹了基于信息最大化的防坍塌工作,有助于幫助我們更深層次理解表示學(xué)習(xí)的原理,以及如何解決實(shí)際應(yīng)用表示學(xué)習(xí)、對(duì)比學(xué)習(xí)時(shí)遇到的坍塌問(wèn)題。
審核編輯:劉清
-
矩陣
+關(guān)注
關(guān)注
0文章
423瀏覽量
34581 -
Network
+關(guān)注
關(guān)注
0文章
64瀏覽量
29644
原文標(biāo)題:ICLR2022 | Facebook AI提出解決表示學(xué)習(xí)坍塌問(wèn)題新方法
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
廣電計(jì)量新年首篇深度研究報(bào)告出爐
中國(guó)發(fā)展報(bào)告:我國(guó)是無(wú)人機(jī)第一大技術(shù)來(lái)源國(guó)
廣電計(jì)量助力第二屆低空科技發(fā)展大會(huì)區(qū)順利舉辦
維智科技入選中國(guó)數(shù)據(jù)要素X行業(yè)應(yīng)用圖譜
杰和科技攜新品受邀參加深圳計(jì)算機(jī)行業(yè)協(xié)會(huì)會(huì)員大會(huì)

羅德與施瓦茨發(fā)布城市空中交通eVTOL測(cè)試解決方案
AI入門之深度學(xué)習(xí):基本概念篇

深視智能參編《2024智能檢測(cè)裝備產(chǎn)業(yè)發(fā)展研究報(bào)告:機(jī)器視覺(jué)篇》

【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)篇
基于Python和深度學(xué)習(xí)的CNN原理詳解
兩會(huì)過(guò)后,來(lái)CMIMS 2024看新能源汽車產(chǎn)業(yè)穩(wěn)中提質(zhì)

中科曙光推出一種半實(shí)物實(shí)時(shí)仿真系統(tǒng)計(jì)算平臺(tái)及國(guó)產(chǎn)化方案
颯特紅外2023年售后服務(wù)工作報(bào)告

從政府工作報(bào)告看磁元件2024年機(jī)遇
快看!各地政府工作報(bào)告,重點(diǎn)提及這些MEMS傳感器及芯片項(xiàng)目!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論