


本文是對我們ECCV 2022被接收的文章LiDAR Distillation: Bridging the Beam-Induced Domain Gap for 3D Object Detection的介紹。在這個工作中,我們通過構建偽低線數點云,利用知識蒸餾方法,來減小由激光雷達線數域差異導致的模型性能下降問題。很榮幸地,我們的文章被ECCV 2022收錄,目前項目代碼已開源,歡迎大家試用。

arXiv:https://arxiv.org/abs/2203.14956
Code(已開源):
https://github.com/weiyithu/LiDAR-Distillation
概述
近年來隨著人工智能的發展,自動駕駛技術開始逐步落地,廣泛應用在無人機,清潔機器人,無人配送小車等無人系統中。而三維目標檢測是自動駕駛技術中的重要一環,是三維環境感知的基礎,其目的是檢測出三維空間中每個物體的三維緊致框。相較于基于圖像的純視覺算法,基于點云三維目標檢測方法精度更高,可以提供更加準確的三維位置,是現階段高階自動駕駛使用的方案。
激光雷達雖然可以提供準確的三維信息,但價格也是昂貴的,尤其是高線數激光雷達。因此在一些較低成本的產品中,例如清潔機器人和無人配送車,無法部署高線數雷達。然而現有公開數據集大部分都是用高線數雷達采集的,這中間存在著線數導致的域差異問題會使得我們無法很好地利用這些大型的公開數據集。除此之外,與RGB相機不同,激光雷達產品更新迭代較快,不同類型的激光雷達線數也會是不同的。對于每一代產品都去重新采集數據集是非常費時費力,不切合實際的。因此如何更好地利用之前采集的高線數數據集是個值得探究的問題。
同時,我們發現之前的一些算法大部分都是為了通用域適應問題設計的(例如ST3D),但面對訓練集是高線數點云,測試集是低線數點云的場景,這些算法不能很好地處理。為了解決這個問題,我們提出了LiDAR Distillation。我們方法的核心是對源域高線數數據進行下采樣得到偽低線數點云,與目標域線數對齊。以在高線數點云數據集上訓練得到的三維目標檢測器作為教師網絡,在偽低線數點云數據集上訓練得到的三維目標檢測器作為學生網絡,進行離線知識蒸餾算法,提升學生網絡精度。由于下采樣過程是逐步進行的,整個框架是迭代框架。在Waymo->nuScenes上的實驗結果表明,我們的方法超過了當前最好方法的性能,并且我們的方法可以很好地與其它通用域適應方法進行結合,在推理過程中不增加任何計算量。
方法
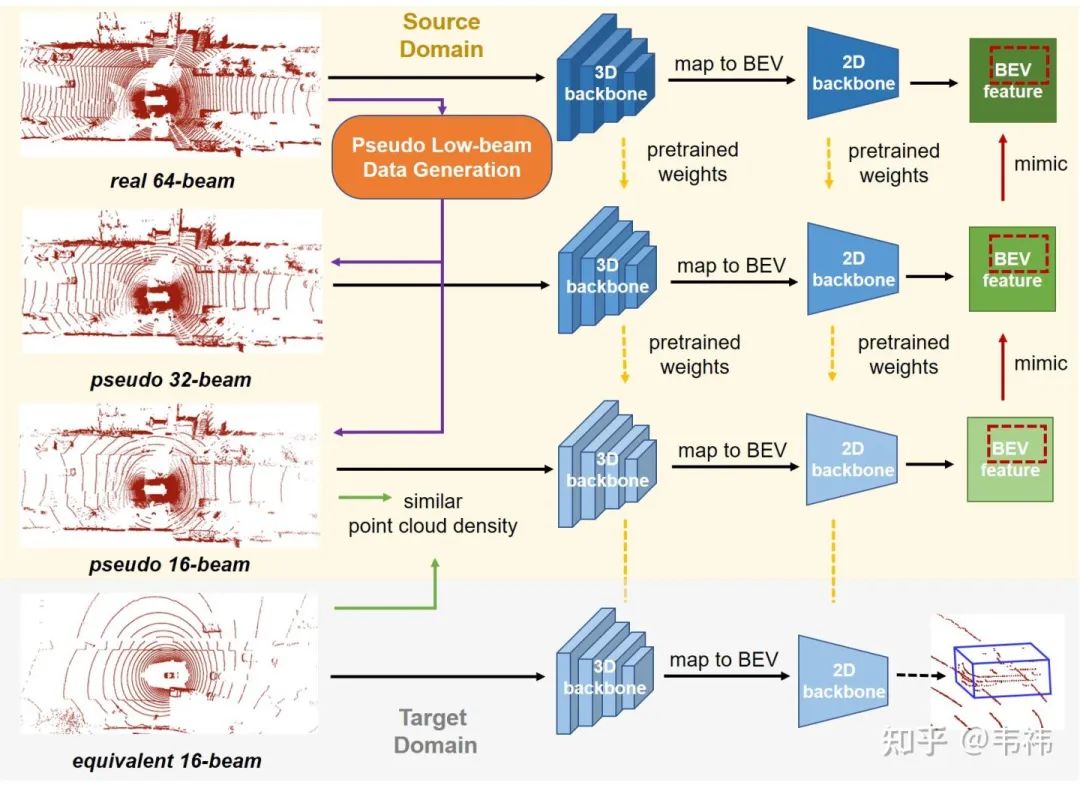
1)生成低線數偽點云數據
為了對齊源域和目標域的點云線數(假設源域和目標域線數分別為Bs和Bt),我們首先需要對源域的高線數數據進行下采樣。與一般的點云下采樣方法不同,我們不能對點云進行均勻的采樣,而是需要按照每條線進行采樣。因此,我們首先需要將一個場景的點云中的每個點歸類到每條線中。雖然有一些公開數據集中的數據有線束的標注,但很多激光雷達點云數據(例如KITTI)并沒有這個信息,我們需要自己設計算法分離出每條線上的點。我們將每個點的笛卡爾坐標轉換成球坐標:
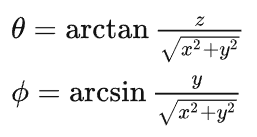

2)利用高線數點云數據進行知識蒸餾
知識蒸餾框架中包含兩個模型:教師網絡和學生網絡。一般而言,教師網絡擁有更多的參數量和更強的表示能力,可以達到更好的性能;而學生網絡模型更小,推理速度更快,能更好地用在存算資源受限的設備中。學生網絡通過模仿教師網絡的特征來提升自身的性能。與傳統知識蒸餾方法不同的是,在我們的方法中,教師網絡和學生網絡的結構相同,唯一區別在于教師網絡是在高線數數據上訓練得到的,而學生網絡是在低線數數據上訓練所得。因此我們利用知識蒸餾的目的是將高線數點云中的豐富信息量傳遞給學生網絡。
我們注意到大部分三維目標檢測框架都會將三維特征投影到二維鳥瞰圖(BEV)上,得到BEV特征。因此我們將BEV特征作為模仿目標。之前工作相關研究結果表明,由于特征圖維度非常高,直接回歸高維向量容易導致網絡不收斂。除此之外,特征圖存在很多低響應區域,這部分的特征往往是不重要的。為了解決這個問題,我們提取BEV特征圖中的感興趣區域(ROI)并在這些區域上執行模仿操作。整體目標函數如下:

3)漸進式知識蒸餾
我們發現當高線數數據和低線數數據之間的線數差異過大時(例如64線和16線),學生網絡無法很好地向教師網絡進行學習。我們提出漸進式知識蒸餾框架,逐步進行蒸餾學習。以64線數據到16線數據為例,我們首先生成偽32線數據,并在上面訓練得到學生模型。緊接著,我們生成偽16線數據,并以上一步得到的學生模型作為教師網絡。在偽16線數據上得到的學生網絡作為最終結果在目標域的16線數據上進行推理。
實驗結果
1) Waymo->nuScenes實驗
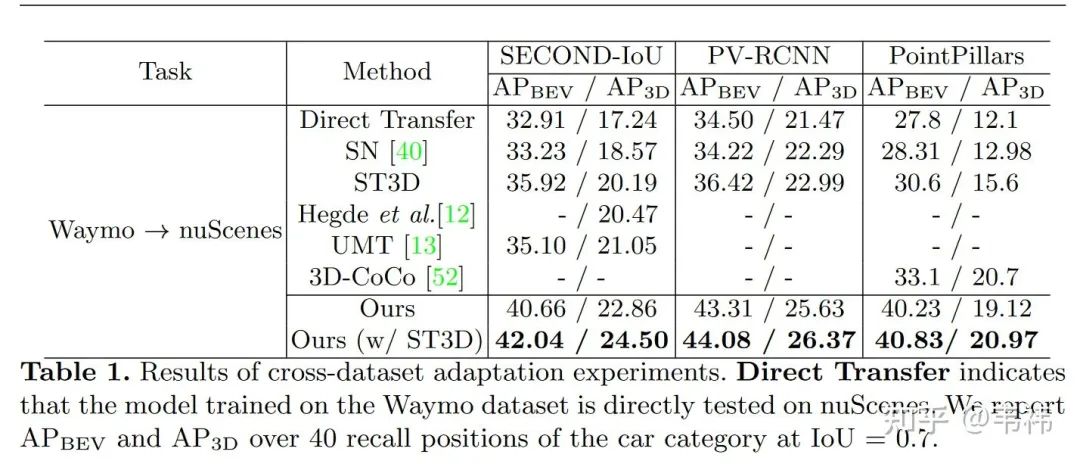
需要注意的是雖然Waymo數據集是64線數據,nuScenes是32線數據,但由于nuScene垂直視場角是Waymo的一半,因此其等效線數為16線。盡管我們的方法僅僅是為了由線數不同導致的域差異問題而設計的,沒有考慮其它域差異因素,我們的方法仍然達到了SOTA的性能。并且,由于我們的方法沒有用到目標域的訓練數據,我們的方法很容易與其它方法進行互補結合(例如ST3D),達到更好的效果。
2)KITTI實驗
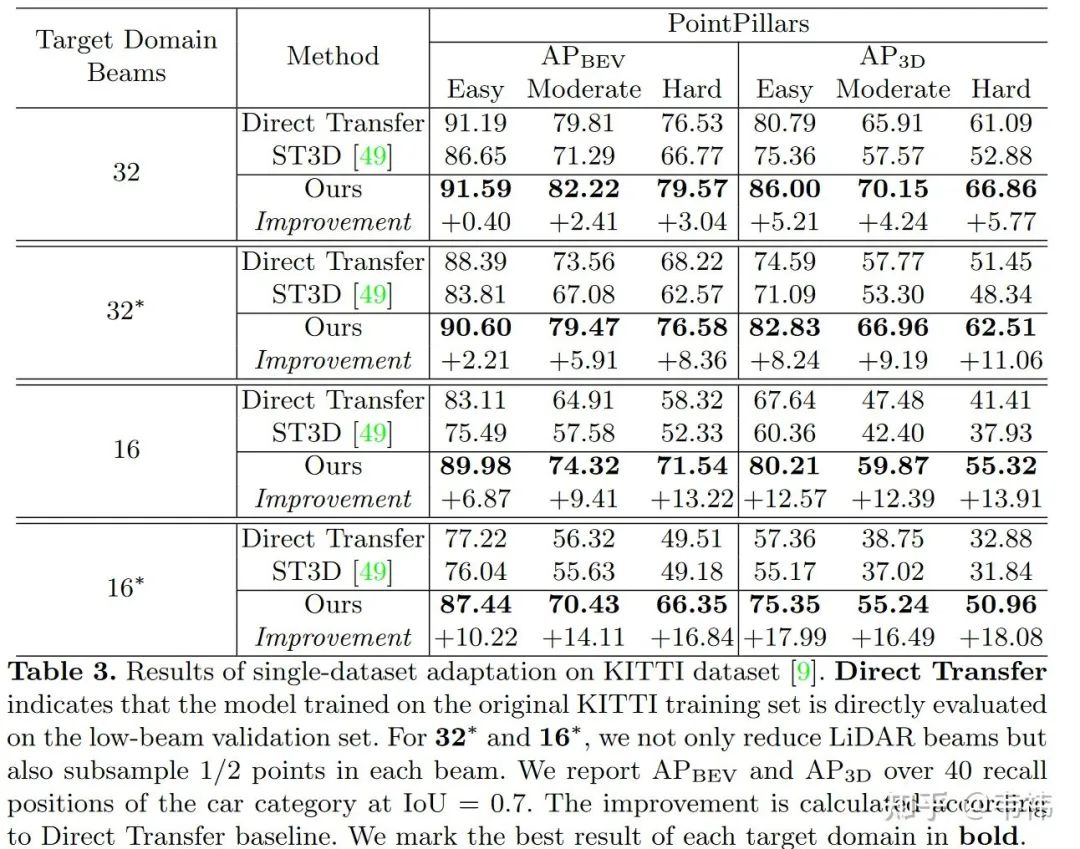
為了排除源域和目標域其它域差異因素的干擾,我們在KITTI上進行了實驗。在這個實驗中,點云線數不同是源域和目標域唯一的差別,其實這個設置更貼合真正的業界應用。換句話說,雖然產品更新導致了激光雷達線數變化,但使用場景并沒有改變。但很可惜的是,學界并沒有在同一場景用不同線數雷達采集的數據集。因此我們只能將64線KITTI數據分別下采樣到多種低線數作為目標域。
3)預訓練實驗
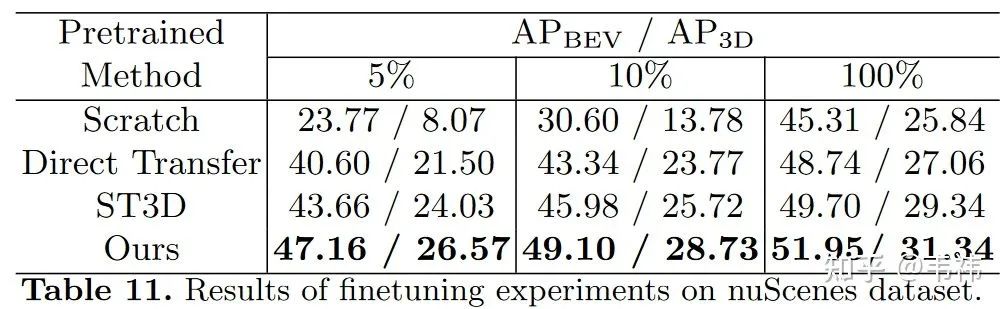
對于公司而言,他們愿意標一些源域的數據。因此我們也做了用我們方法在源域上進行預訓練,然后在目標域上進行微調的實驗。我們發現僅使用5%的目標域有標簽數據,我們方法得到的模型性能就可以超過沒有預訓練直接用100%目標域數據進行訓練得到模型的性能。
方法不足與未來展望
我們的方法是在BEV特征上進行知識蒸餾的,但很顯然這不是最優解,尤其是對于不是很依賴BEV特征的網絡而言,最近也出了不少三維目標檢測知識蒸餾的文章,這些方法值得借鑒。另一方面,現在的公開數據集基本上用的都是用機械式激光雷達采集的。而由于成本原因,現在越來越多的廠家選用固態或者混合固態的激光雷達,這些雷達中的線數概念與機械式的不同,因此如何在這些雷達中緩解域差異問題是一個不錯的未來方向。
審核編輯 :李倩
-
人工智能
+關注
關注
1809文章
49152瀏覽量
250688 -
激光雷達
+關注
關注
971文章
4245瀏覽量
193125 -
點云
+關注
關注
0文章
58瀏覽量
3974
原文標題:ECCV 2022 | LiDAR Distillation: 解決由激光雷達線數差異導致的三維目標檢測域適應問題
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
CES 2025激光雷達觀察:“千線”激光雷達亮相,頭部廠商布局具身智能

全固態激光雷達為什么遲遲未來?其技術難點是什么?
超酷的樹莓派激光雷達掃描儀!

愛普生高精度車規晶振助力激光雷達自動駕駛

激光雷達技術:自動駕駛的應用與發展趨勢

基于空譜特征優化選擇的高光譜激光雷達地物分類






 工商網監
工商網監

評論