


前言
自BERT出現(xiàn)以來,nlp領(lǐng)域已經(jīng)進(jìn)入了大模型的時代,大模型雖然效果好,但是畢竟不是人人都有著豐富的GPU資源,在訓(xùn)練時往往就捉襟見肘,出現(xiàn)顯存out of memory的問題,或者訓(xùn)練時間非常非常的久,因此,這篇文章主要解決的問題就是如何在GPU資源受限的情況下訓(xùn)練transformers庫上面的大模型。
這篇文章源自Vadim Irtlach大佬在kaggle的開源notebook,感謝原作者的分享,本nlp小白覺得受益良多,因此搬運到知乎分享給大家,已取得作者授權(quán),大部分內(nèi)容是照搬翻譯過來的,小部分內(nèi)容結(jié)合自己的理解進(jìn)行了補充和修改,不對的地方請大家批評指正,正文開始!
盡管Huggingface開源的Transformers在自然語言處理(NLP)任務(wù)中取得了驚人的成功,但由于里面的模型參數(shù)數(shù)量龐大,即使是使用GPU進(jìn)行訓(xùn)練或者部署,也仍具有非常大的挑戰(zhàn)性,因為用如此大的模型進(jìn)行訓(xùn)練或推理,會很容易發(fā)生顯存不足(OOM)以及訓(xùn)練時間過長的問題。(這里想吐槽一句的是,kaggle上面的nlp比賽現(xiàn)在動不動就用五折debert-large-v3,沒幾塊V100根本玩不起這種比賽,所以這篇文章對我這種只能用colab的p100來跑實驗的窮學(xué)生來說真的是福音啊!)
然而,有很多方法可以避免顯存不足以及訓(xùn)練時間過長的方法,這篇文章的主要貢獻(xiàn)就是介紹了這些方法的原理以及如何實現(xiàn),具體包括以下幾種方法:
梯度累積(Gradient Accumulation)
凍結(jié)(Freezing)
自動混合精度(Automatic Mixed Precision)
8位優(yōu)化器(8-bit Optimizers)
梯度檢查點(Gradient Checkpointing)
快速分詞器(Fast Tokenizers)
動態(tài)填充(Dynamic Padding)
均勻動態(tài)填充(Uniform Dynamic Padding)
其中1-5是神經(jīng)網(wǎng)絡(luò)通用的方法,可以用在任何網(wǎng)絡(luò)的性能優(yōu)化上,6-8是針對nlp領(lǐng)域的性能優(yōu)化方法。
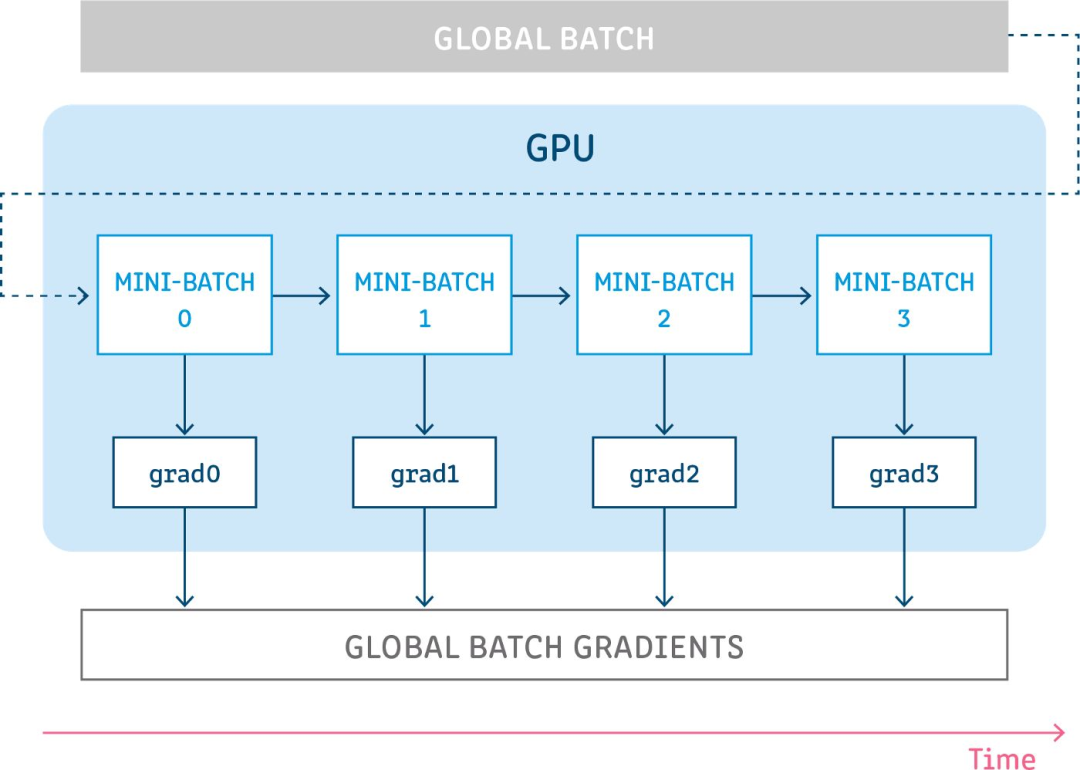
梯度累積
梯度累積背后的想法非常簡單,就是為了模擬更大的批量(batch)。有時,為了更好地收斂或提高性能,需要使用大批量進(jìn)行訓(xùn)練,但是,這通常需要更大的顯存。這個問題的一種可能的解決方案是使用較小的批量,但是,一方面,小批量訓(xùn)練會增加訓(xùn)練和推理時間,另一方面,梯度下降算法對批量大小的選擇非常敏感,小批量可能會導(dǎo)致不穩(wěn)定的收斂和性能降低。所以,我們可以先執(zhí)行幾次前向傳播和反向傳播,使得梯度進(jìn)行累積,當(dāng)我們有足夠的計算梯度時,再對參數(shù)進(jìn)行優(yōu)化,從而利用小顯存,模擬大批量的效果,并且訓(xùn)練時間也不會大幅增加。
代碼實現(xiàn)
steps=len(loader) ##performvalidationloopeach`validation_steps`trainingsteps! validation_steps=int(validation_steps*gradient_accumulation_steps) forstep,batchinenumerate(loader,1): #prepareinputsandtargetsforthemodelandlossfunctionrespectively. #forwardpass outputs=model(inputs) #computingloss loss=loss_fn(outputs,targets) #accumulatinggradientsoversteps ifgradient_accumulation_steps>1: loss=loss/gradient_accumulation_steps #backwardpass loss.backward() #performoptimizationstepaftercertainnumberofaccumulatingstepsandattheendofepoch ifstep%gradient_accumulation_steps==0orstep==steps: torch.nn.utils.clip_grad_norm_(model.parameters(),max_norm) optimizer.step() model.zero_grad() #performvalidationloop ifstep%validation_steps==0: validation_loop()
凍結(jié)
凍結(jié)是一種非常有效的方法,通過取消計算模型某些層中的梯度計算(如embedding層,bert的前幾層),可以大大加快訓(xùn)練速度并且降低了顯存占用,而且?guī)缀醪粫p失模型的性能。
深度學(xué)習(xí)中的一個眾所周知的事實是,網(wǎng)絡(luò)的底層學(xué)習(xí)輸入數(shù)據(jù)的通用特征,而網(wǎng)絡(luò)頂層學(xué)習(xí)目標(biāo)任務(wù)特定的高級特征,所以在對預(yù)訓(xùn)練模型進(jìn)行微調(diào)時,一般網(wǎng)絡(luò)底層的參數(shù)都不怎么需要變,這些都是通用的知識,需要學(xué)習(xí)的是頂層的那些參數(shù),當(dāng)使用某種優(yōu)化算法(如SGD、AdamW或RMSprop)執(zhí)行優(yōu)化步驟時,網(wǎng)絡(luò)的底層的梯度就都很小,因此參數(shù)幾乎保持不變,這也被稱為梯度消失,因此,與其花費大量的時間和算力來計算底層這些“無用”梯度,并對此類梯度很小的參數(shù)進(jìn)行優(yōu)化,不如直接凍結(jié)它們,直接不計算梯度也不進(jìn)行優(yōu)化。
PyTorch為關(guān)閉梯度計算提供了一個舒適的API,可以通過torch.Tensor的屬性requires_grad設(shè)置。
代碼實現(xiàn)
deffreeze(module): """ Freezesmodule'sparameters. """ forparameterinmodule.parameters(): parameter.requires_grad=False defget_freezed_parameters(module): """ Returnsnamesoffreezedparametersofthegivenmodule. """ freezed_parameters=[] forname,parameterinmodule.named_parameters(): ifnotparameter.requires_grad: freezed_parameters.append(name) returnfreezed_parameters
importtorch
fromtransformersimportAutoConfig,AutoModel
##initializingmodel
model_path="microsoft/deberta-v3-base"
config=AutoConfig.from_pretrained(model_path)
model=AutoModel.from_pretrained(model_path,config=config)
##freezingembeddingsandfirst2layersofencoder
freeze(model.embeddings)
freeze(model.encoder.layer[:2])
freezed_parameters=get_freezed_parameters(model)
print(f"Freezedparameters:{freezed_parameters}")
##selectingparameters,whichrequiresgradientsandinitializingoptimizer
model_parameters=filter(lambdaparameter:parameter.requires_grad,model.parameters())
optimizer=torch.optim.AdamW(params=model_parameters,lr=2e-5,weight_decay=0.0)
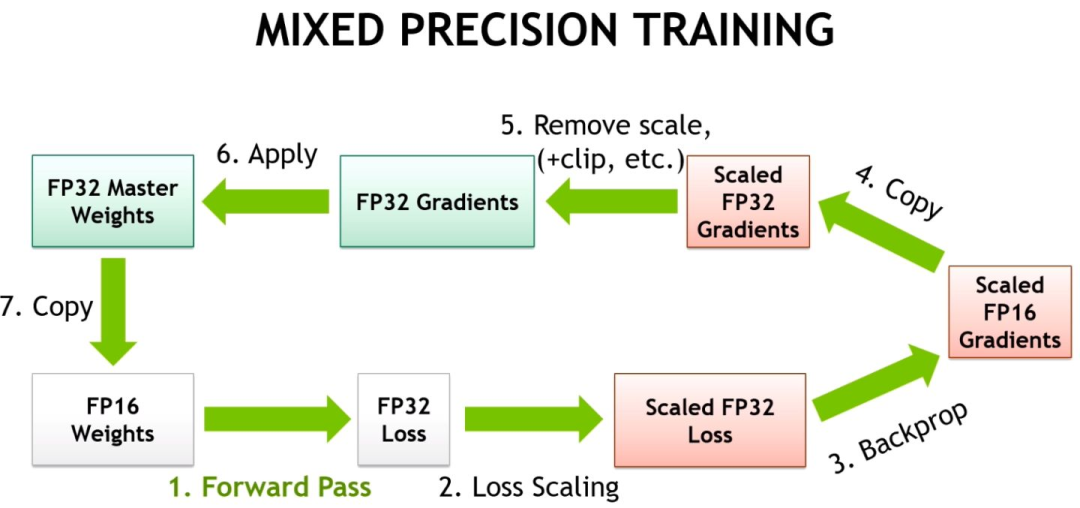
自動混合精度
自動混合精度(AMP)是另一種在不損失最終質(zhì)量的情況下減少顯存消耗和訓(xùn)練時間的方法,該方法由NVIDIA和百度研究人員在2017年的Mixed Precision Training論文中提出。該方法背后的關(guān)鍵思想是使用較低的精度將模型的梯度和參數(shù)保留在內(nèi)存中,即不使用全精度(float32),而是使用半精度(例如float16)將張量保存在內(nèi)存中。然而,當(dāng)以較低精度計算梯度時,某些值可能太小,以至于被視為零,這種現(xiàn)象被稱為“溢出”。為了防止“溢出”,原始論文的作者提出了一種梯度縮放方法。
PyTorch從1.6的版本開始提供了一個包:torch.cuda.amp,具有使用自動混合精度所需的功能(從降低精度到梯度縮放),自動混合精度作為上下文管理器實現(xiàn),因此可以隨時隨地的插入到訓(xùn)練和推理腳本中。
代碼實現(xiàn)
fromtorch.cuda.ampimportautocast,GradScaler scaler=GradScaler() forstep,batchinenumerate(loader,1): #prepareinputsandtargetsforthemodelandlossfunctionrespectively. #forwardpasswith`autocast`contextmanager withautocast(enabled=True): outputs=model(inputs) #computingloss loss=loss_fn(outputs,targets) #scalegradintandperformbackwardpass scaler.scale(loss).backward() #beforegradientclippingtheoptimizerparametersmustbeunscaled. scaler.unscale_(optimizer) #performoptimizationstep torch.nn.utils.clip_grad_norm_(model.parameters(),max_norm) scaler.step(optimizer) scaler.update()
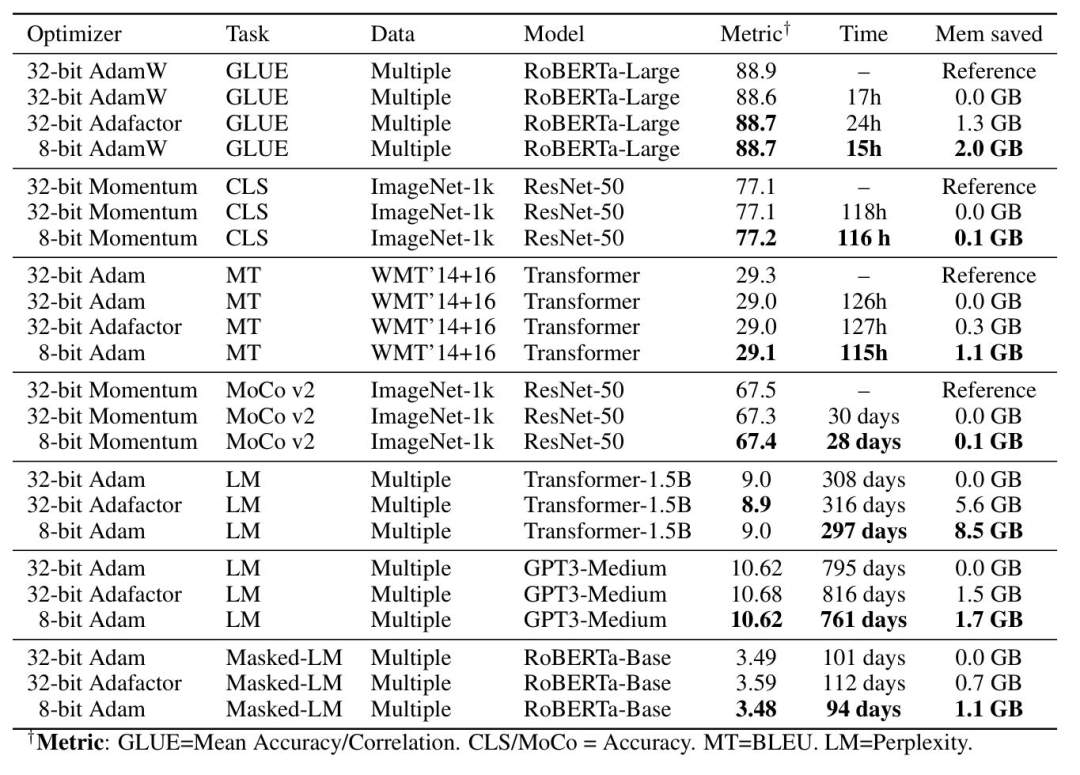
8位優(yōu)化器
8-bit Optimizers的思想類似于自動混合精度(模型的參數(shù)和梯度使用較低的精度保存),但8-bit Optimizers還讓優(yōu)化器的狀態(tài)使用低精度保存。作者(Meta Research)在最初的論文8-bit Optimizers via Block-wise Quantization中詳細(xì)介紹了8-bit Optimizers,表明8-bit Optimizers顯著降低了顯存占用,略微加快了訓(xùn)練速度。此外,作者研究了不同超參數(shù)設(shè)置的影響,表明8-bit Optimizers對不同的學(xué)習(xí)率、beta和權(quán)重衰減參數(shù)的效果是穩(wěn)定的,不會降低性能或影響收斂性。因此,作者為8位優(yōu)化器提供了一個高級庫,叫做bitsandbytes。
代碼實現(xiàn)
!pipinstall-qbitsandbytes-cuda110
defset_embedding_parameters_bits(embeddings_path,optim_bits=32):
"""
https://github.com/huggingface/transformers/issues/14819#issuecomment-1003427930
"""
embedding_types=("word","position","token_type")
forembedding_typeinembedding_types:
attr_name=f"{embedding_type}_embeddings"
ifhasattr(embeddings_path,attr_name):
bnb.optim.GlobalOptimManager.get_instance().register_module_override(
getattr(embeddings_path,attr_name),'weight',{'optim_bits':optim_bits}
)
importbitsandbytesasbnb
##selectingparameters,whichrequiresgradients
model_parameters=filter(lambdaparameter:parameter.requires_grad,model.parameters())
##initializingoptimizer
bnb_optimizer=bnb.optim.AdamW(params=model_parameters,lr=2e-5,weight_decay=0.0,optim_bits=8)
##bnb_optimizer=bnb.optim.AdamW8bit(params=model_parameters,lr=2e-5,weight_decay=0.0)#equivalenttotheaboveline
##settingembeddingsparameters
set_embedding_parameters_bits(embeddings_path=model.embeddings)
print(f"8-bitOptimizer:
{bnb_optimizer}")
梯度檢查點
有時候,即使用了上面的幾種方法,顯存可能還是不夠,尤其是在模型足夠大的情況下。那么梯度檢查點(Gradient Checkpointing)就是壓箱底的招數(shù)了,這個方法第一次在 Training Deep Nets With Sublinear Memory Cost ,作者表明梯度檢查點可以顯著降低顯存利用率,從降低到,其中n是模型的層數(shù)。這種方法允許在單個GPU上訓(xùn)練大型模型,或者提供更多內(nèi)存以增加批量大小,從而更好更快地收斂。梯度檢查點背后的思想是在小數(shù)據(jù)塊中計算梯度,同時在正向和反向傳播過程中從內(nèi)存中移除不必要的梯度,從而降低內(nèi)存利用率,但是這種方法需要更多的計算步驟來再現(xiàn)整個反向傳播圖,其實就是一種用時間來換空間的方法。
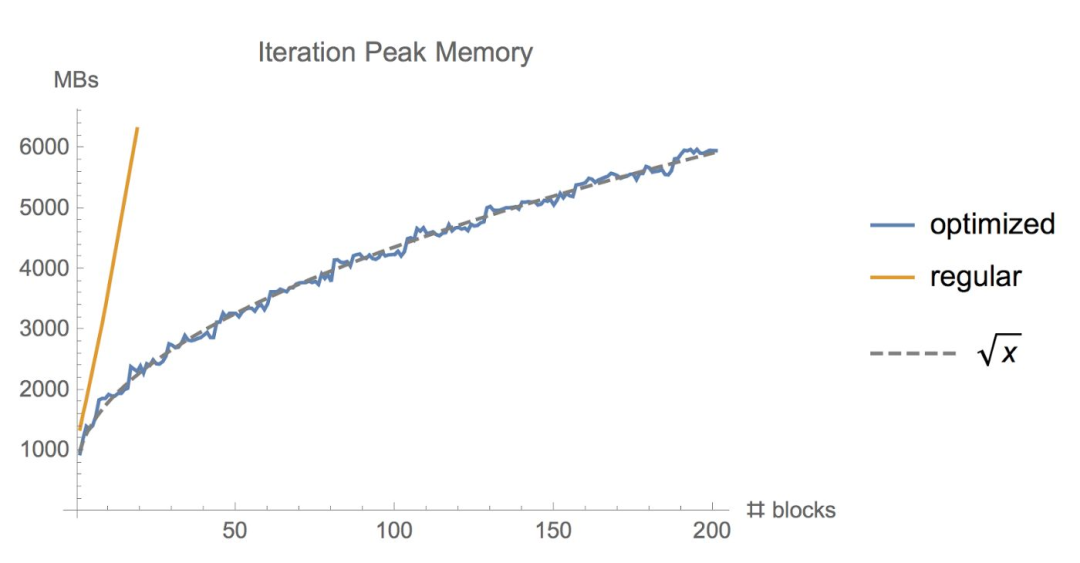
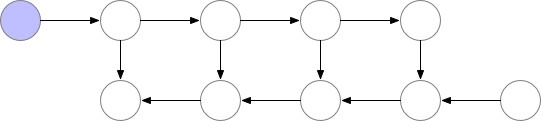 演示梯度檢查點如何在正向和反向傳播過程中工作
演示梯度檢查點如何在正向和反向傳播過程中工作
PyTorch框架里也有梯度檢查點的實現(xiàn),通過這兩個函數(shù):torch.utils.checkpoint.checkpoint和torch.utils.checkpoint.checkpoint_sequential
這邊引用一段torch官網(wǎng)對梯度檢查點的介紹:
梯度檢查點通過用計算換取內(nèi)存來工作。檢查點部分不是存儲整個計算圖的所有中間激活以進(jìn)行反向計算,而是不保存中間激活,而是在反向過程中重新計算它們。它可以應(yīng)用于模型的任何部分。
具體而言,在前向傳播中,該函數(shù)將以torch.no_grad()的方式運行,即不存儲中間激活。然而,前向傳播保存了輸入元組和函數(shù)參數(shù)。在反向傳播時,檢索保存的輸入和函數(shù),然后再次對函數(shù)進(jìn)行前向傳播,現(xiàn)在跟蹤中間激活,然后使用這些激活值計算梯度。
此外,HuggingFace Transformers也支持梯度檢查點。梯度檢查點可以通過PreTrainedModel實例的gradient_checkpointing_enable方法執(zhí)行,一行代碼直接搞定!
代碼實現(xiàn)
fromtransformersimportAutoConfig,AutoModel
##https://github.com/huggingface/transformers/issues/9919
fromtorch.utils.checkpointimportcheckpoint
##initializingmodel
model_path="microsoft/deberta-v3-base"
config=AutoConfig.from_pretrained(model_path)
model=AutoModel.from_pretrained(model_path,config=config)
##gradientcheckpointing
model.gradient_checkpointing_enable()
print(f"GradientCheckpointing:{model.is_gradient_checkpointing}")
快速分詞器
HuggingFace Transformers提供兩種類型的分詞器:基本分詞器和快速分詞器。它們之間的主要區(qū)別在于,快速分詞器是在Rust上編寫的,因為Python在循環(huán)中非常慢,但在分詞的時候又要用到循環(huán)。快速分詞器是一種非常簡單的方法,允許我們在分詞的時候獲得額外的加速。要使用快速分詞器也很簡單,只要把transformers.AutoTokenizer里面的from_pretrained方法的use_fast的值修改為True就可以了。

分詞器是如何工作的
代碼實現(xiàn)
fromtransformersimportAutoTokenizer
##initializingBaseversionofTokenizer
model_path="microsoft/deberta-v3-base"
tokenizer=AutoTokenizer.from_pretrained(model_path,use_fast=False)
print(f"BaseversionTokenizer:
{tokenizer}",end="
"*3)
##initializingFastversionofTokenizer
fast_tokenizer=AutoTokenizer.from_pretrained(model_path,use_fast=True)
print(f"FastversionTokenizer:
{fast_tokenizer}")
動態(tài)填充
通常來說,模型是用批量數(shù)據(jù)輸入訓(xùn)練的,批中的每個輸入必須具有固定大小,即一批量的數(shù)據(jù)必須是矩陣的表示,所有批量數(shù)據(jù)的尺寸都一樣。固定尺寸通常是根據(jù)數(shù)據(jù)集中的長度分布、特征數(shù)量和其他因素來選擇的。在NLP任務(wù)中,輸入大小稱為文本長度,或者最大長度(max length)。然而,不同的文本具有不同的長度,為了處理這種情況,研究人員提出了填充標(biāo)記和截斷。當(dāng)最大長度小于輸入文本的長度時,會使用截斷,因此會刪除一些標(biāo)記。當(dāng)輸入文本的長度小于最大長度時,會將填充標(biāo)記,比如[PAD],添加到輸入文本的末尾,值得注意的是,填充標(biāo)記不應(yīng)包含在某些任務(wù)的損失計算中(例如掩蔽語言建模或命名實體識別)
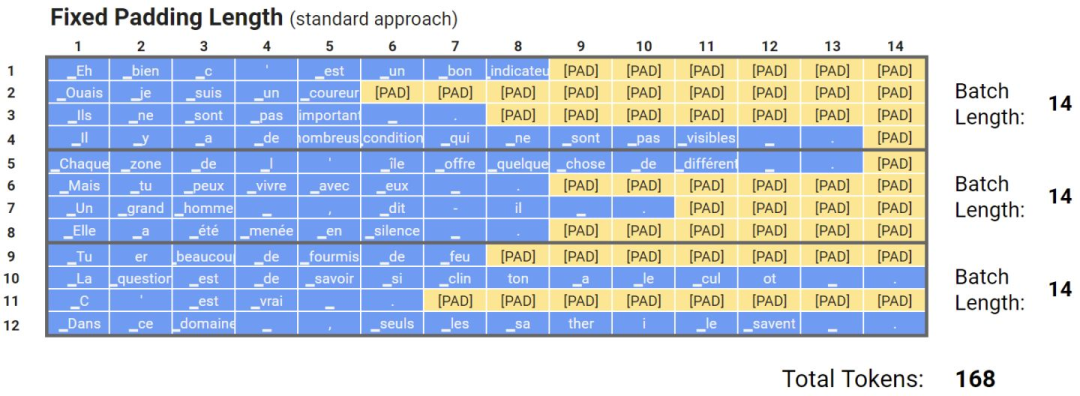
固定長度填充
然而,填充標(biāo)記有明顯的缺點。比如在輸入文本相對于選定的最大長度非常短的情況下,效率就很低,需要更多的額外內(nèi)存,比如我有一條文本長度512,然后其他文本長度都在10左右,那么如果將max seq設(shè)置為512,就會導(dǎo)致很多無效計算。為了防止額外的計算操作,研究人員提出了一種非常有效的方法,就是將批量的輸入填充到這一批量的最大輸入長度,如下圖所示,這種方法可以將訓(xùn)練速度提高35%甚至50%,當(dāng)然這種方法加速的效果取決于批量的大小以及文本長度的分布,批量越小,加速效果越明顯,文本長度分布越不均,加速效果也越好。
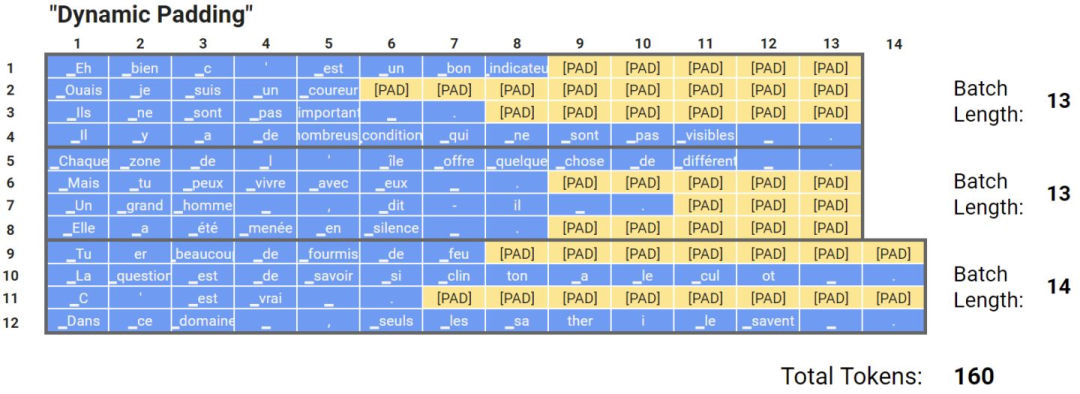
動態(tài)填充
均勻動態(tài)填充
還有一種基于動態(tài)填充的方法,叫做均勻動態(tài)填充。其思想是在分batch時,先按文本的長度對文本進(jìn)行排序,這樣同一個batch里面的文本長度就都差不多。這種方法非常有效,在訓(xùn)練或推理期間的計算量都比動態(tài)填充要來的少。但是,不建議在訓(xùn)練期間使用均勻動態(tài)填充,因為訓(xùn)練時數(shù)據(jù)最好是要shuffer的,但是推理時如果一次性要推理很多文本的話可以考慮這么做
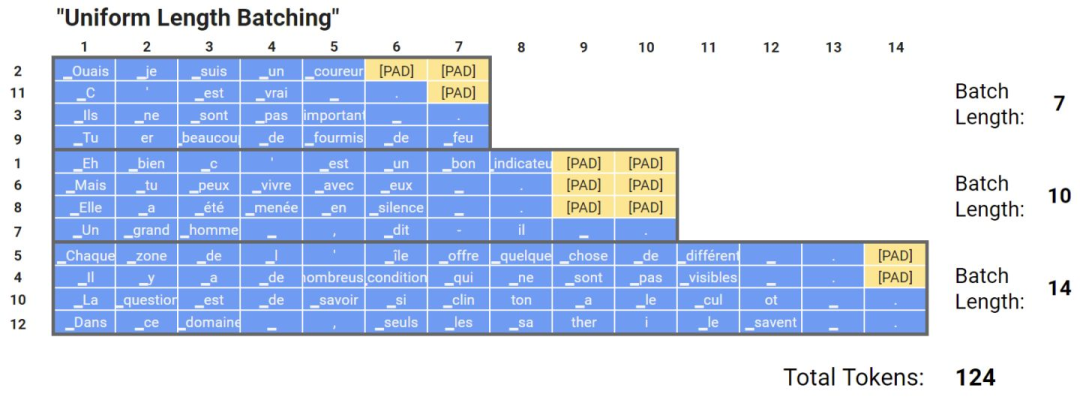
均勻動態(tài)填充
總結(jié)
即使在現(xiàn)代GPU上,優(yōu)化內(nèi)存和時間也是開發(fā)模型的必要步驟,因此,本文介紹了加速訓(xùn)練和減少transformers等大型模型內(nèi)存消耗的最強大、最流行的方法。
審核編輯:劉清
-
gpu
+關(guān)注
關(guān)注
28文章
4956瀏覽量
131427 -
自然語言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14178 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22639 -
大模型
+關(guān)注
關(guān)注
2文章
3162瀏覽量
4113
原文標(biāo)題:一文詳解Transformers的性能優(yōu)化的8種方法
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
提升AI訓(xùn)練性能:GPU資源優(yōu)化的12個實戰(zhàn)技巧

如何高效訓(xùn)練AI模型?這些常用工具你必須知道!
LPC1227FBD48如何在沒有SDK的情況下配置FreeRTOS?
請問如何在imx8mplus上部署和運行YOLOv5訓(xùn)練的模型?
摩爾線程GPU原生FP8計算助力AI訓(xùn)練






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論