


前言 在本文中,作者提出了一種基于高斯感受野的標簽分配(RFLA)策略用于微小目標檢測。并提出了一種新的感受野距離(RFD)來直接測量高斯感受野和地面真值之間的相似性,而不是使用IoU或中心采樣策略分配樣本。
考慮到基于IoU閾值和中心采樣策略對大對象的傾斜,作者進一步設計了基于RFD的分層標簽分配(HLA)模塊,以實現小對象的平衡學習。在四個數據集上的大量實驗證明了所提方法的有效性。作者的方法在AI-TOD數據集上的AP點數為4.0,優于SOTA。
創新思路
微小物體的像素數量極為有限(小于AI-TOD[49]中定義的16×16像素),一直是計算機視覺領域的一個難題。微小目標檢測(TOD)是最具挑戰性的方法之一,一般的物體檢測器通常無法在TOD任務中提供令人滿意的結果,這是由于微小物體缺乏鑒別特征。
考慮到微小物體的特殊性,提出了幾種定制的TOD基準(如AI-TOD、TinyPerson和AI-TOT-v2),以促進一系列下游任務,包括駕駛輔助、交通管理和海上救援。最近,TOD逐漸成為一個受歡迎但具有挑戰性的方向,獨立于一般對象檢測。
在本文中,作者認為當前的先驗盒和點及其相應的測量策略對于微小物體是次優的,這將進一步阻礙標簽分配過程。具體來說,作者以單個先驗盒和點為例,從分布的角度重新思考它們。
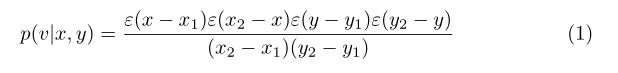
不同先驗的示意圖如圖1的第二行所示,現有先驗信息與其相應的測量策略相結合,對于微小物體存在以下問題。

圖1.不同標簽分配方案的檢測結果之間的比較
第一:當特定ground truth與特定先驗不重疊時,它們的位置關系無法通過IoU或中心度解決。對于微小對象,通常情況下,真實框與幾乎所有的錨框都沒有重疊(即IoU=0)或不包含任何錨定點,導致微小對象缺少正樣本。
為此,采用啟發式方法來保證微小對象的更多正樣本。然而,賦值器通常無法基于零值IoU或中心度補償微小對象的正樣本。因此,網絡將減少對微小對象學習的關注。
第二,當前先驗區域主要遵循均勻分布,并同等對待先驗區域內的每個位置。然而,基本上利用先驗信息來輔助標簽分配或特征點分配過程。
當將特征點的感受野重新映射回輸入圖像時,有效感受野實際上是高斯分布的。均勻分布先驗和高斯分布感受野之間的間隙將導致ground truth和分配給它的特征點的感受野之間不匹配。
為了緩解上述問題,作者引入了一種新的基于高斯分布的先驗知識,并建立了一種基于高斯感受野的標簽分配(RFLA)策略,該策略更有利于微小對象。
本文的主要貢獻
(1)實驗表明,當前基于錨和無錨的檢測器在微小目標標簽分配中存在尺度樣本不平衡問題。
(2) 為了緩解上述問題,引入了一種簡單但有效的基于感受野的標簽分配(RFLA)策略。RFLA很容易取代主流檢測器中的標準盒和基于點的標簽分配策略,提高了它們在TOD上的性能。
(3) 在四個數據集上的大量實驗驗證了提出的方法的性能優越性。在具有挑戰性的AI-TOD數據集上,引入的方法在推理階段沒有額外成本的情況下顯著優于最先進的競爭對手。
方法
感受野建模
基于錨的檢測器在FPN的不同層上平鋪不同尺度的先驗框,以輔助標簽分配,因此在FPN不同層上檢測不同尺度的對象。對于無錨探測器,它們將不同比例范圍內的對象分組到不同水平的FPN上進行檢測。盡管標簽分配策略各不相同,但基于錨和無錨檢測器的一個共同點是將適當感受野的特征點分配給不同尺度的對象。
因此,在不設計啟發式錨框預設或規模分組的情況下,感受野可以直接用作標簽分配的有根據和有說服力的先驗。
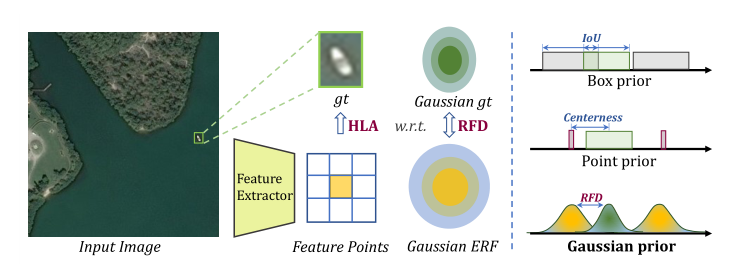
圖2.RFLA的過程
在本文中,作者直接測量有效感受野(ERF)和ground truth區域之間的匹配度,以進行標記分配,從而消除使TOD惡化的盒或點先驗。在這項工作中,將每個特征點的ERF建模為高斯分布,先通過以下公式推導出標準卷積神經網絡上第n層的理論感受野(TRF),即trn:
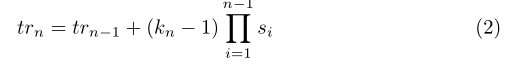
感受野距離
獲得高斯ERF,關鍵步驟是測量特征點的ERF與某個ground truth之間的匹配度。階躍變化的均勻分布不利于ground truth體,還需要將真實值建模為另一個分布。
觀察到物體的主體聚集在邊界框的中心,作者還將ground truth框(xg、yg、wg、hg)建模為標準的二維高斯分布Ng(μg,∑g),其中每個帶注釋框的中心點用作高斯的平均向量,半邊長的平方用作協方差矩陣,即,
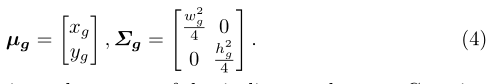
在本文中,作者研究了高斯分布之間的三種典型距離作為感受野距離候選(RFDC)。這些距離測量包括Wasserstein距離、K-L散度和J-S散度。高斯分布之間的J-S散度沒有閉式解,在近似其解時將引入大量計算,因此,不使用J-S散度。
Wasserstein距離
Wasserstein距離來自最優運輸理論。Wasserstein距離的主要優點是它可以測量兩個非重疊分布。通常情況下,ground truth框與大多數在先框和點沒有重疊,并且賦值器無法將這些候選ground truth級排序到某個真實值。
因此,可以很容易地說,Wasserstein距離的特性有利于TOD,TOD可以一致地反映所有特征點與某個ground truth盒之間的匹配程度,使賦值器能夠根據合理的優先級對微小對象補償更多的正樣本。然而,Wasserstein距離不是尺度不變的,當數據集包含大尺度方差的對象時,它可能是次優的。
Kullback-Leibler散度
Kullback-Leibler散度(KLD)是一種經典的統計距離,用于衡量一種概率分布與另一種概率的差異。KLD在兩個二維高斯分布之間具有尺度不變性,并且尺度不變性對檢測至關重要。而KLD的主要缺點是,當兩個分布的重疊可以忽略時,它不能一致地反映兩個分布之間的距離。
因此,本文選擇ERF和ground truth之間的KLD作為另一個RFDC。
然后,作者將非線性變換應用于RFDC,并得到歸一化值范圍在(0,1)之間的RFD,如下所示:

分層標簽分配
作者通過分數排序將標簽分層分配給微小對象。為了保證任何特征點和任何ground truth之間的位置關系都可以求解,所提出的分層標簽分配(HLA)策略建立在所提出的RFD之上。在分配之前,基于ground truth計算特征點和真實值之間的RFD ground truth。
在第一階段,作者使用特定的真實值對每個特征點的RFD得分進行排序。然后,將ground truth配給具有最高k個RFD分數的特征點,并具有一定的ground truth。最后,得到分配結果r1和已分配特征的對應掩碼m。
在第二階段,為了提高整體召回率并緩解異常值,通過乘以階段因子β來略微衰減有效半徑ern,然后重復上述排序策略,并向每個ground truth補充一個正樣本,得到分配結果r2。通過以下規則獲得最終分配結果r:

探測器的應用
所提出的RFLA策略可以應用于基于錨和無錨的框架。為了更快的R-CNN,RFLA可以用來代替標準的錨平鋪和MaxIoU錨分配過程。對于FCOS,消除了限制ground truth框內特征點的限制,因為小框只覆蓋非常有限的區域,通常比大對象包含的特征點少得多。
用RFLA代替基于點的分配,實現平衡學習。
作者將中心度損失修改為以下公式,以避免梯度爆炸:
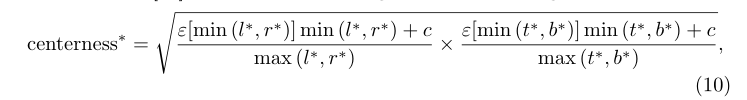
實驗
如表1所示,可以看出,GIoU不如RFD,因為它無法區分相互包容的盒子的位置,而WD和KLD的性能相當。
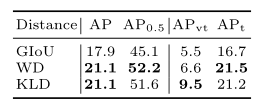
表1.不同感受野距離測量方法的比較
作者逐步將RFD和HLA應用到更快的RCNN中。結果列于表2,AP逐步改善,從而驗證了個體有效性。
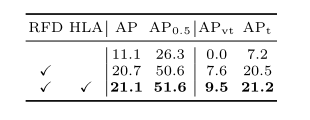
表2.不同設計的影響
在HLA中,作者為ERF設計了階段因子β,以緩解異常值效應。在表3中,作者保持所有其他參數不變,實驗表明0.9是最佳選擇。將β設置為較低的值將引入太多的低質量樣本。
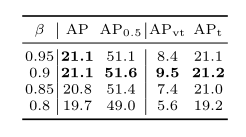
表3.分級標記賦值器(HLA)中階段因子β的影響
作者將錨直接建模為高斯分布,計算ground truth之間的RFD得分,然后使用HLA分配標簽。結果如表4所示。結果表明高斯先驗及其與HLA的結合具有很大的優勢。
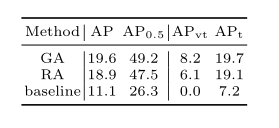
表4.高斯錨和接受錨
作者將作者的方法與AI-TOD基準上的其他最先進檢測器進行了比較。如表5所示,帶RFLA的探測器達到24.8 AP,比最先進的競爭對手高出4.0 AP。
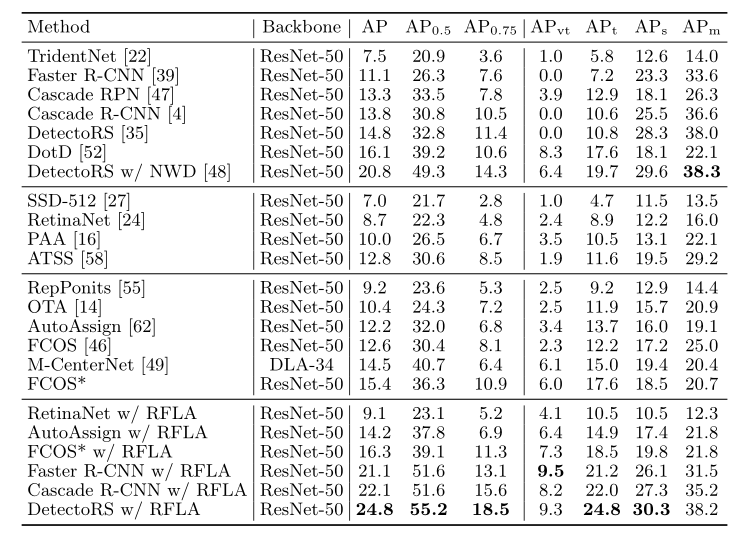
表5.AI-TOD的主要結果
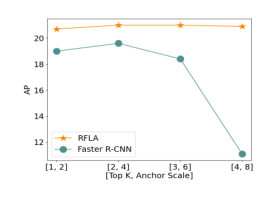
圖3.快速R-CNN w/HLA中的top k與快速R-CNN基線中的錨定微調之間的比較
作者將標度范圍劃分為16個區間,如圖4所示,并計算分配給不同標度范圍中每個ground truth的正樣本的平均數量。圖4中的觀察結果表明現有檢測器存在嚴重的標度樣本不平衡問題。
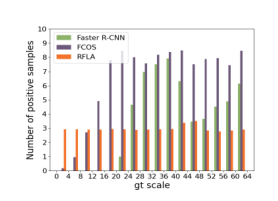
圖4.不同檢測器的比例樣本不平衡問題
AI-TOD數據集的可視化結果如圖5所示。當將RFLA應用于更快的R-CNN時,可以大大消除FN預測。

圖5.AI-TOD的可視化結果
結論
在本文中,作者指出框和點先驗對于TOD不起作用,導致在分配標簽時出現比例樣本不平衡問題。為此,作者引入了一種新的高斯感受野先驗。
然后,作者進一步設計了一種新的感受野距離(RFD),它度量了ERF和ground truth之間的相似性,以克服TOD上IoU和中心性的不足。RFD與HLA策略一起工作,為微小對象獲得平衡學習。
在四個數據集上的實驗表明了RFLA的優越性和魯棒性。
-
檢測器
+關注
關注
1文章
896瀏覽量
48753 -
數據集
+關注
關注
4文章
1224瀏覽量
25486 -
RFD
+關注
關注
0文章
2瀏覽量
3277
原文標題:ECCV 2022 | 武大&華為提出RFLA:用于小目標檢測的基于高斯感受野的標簽分配
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

娛樂版HLA分型網頁升級了 精選資料分享
基于HLA和Agent的電子對抗仿真系統構建
基于HLA的導彈攻防仿真系統的設計與實現
基于HLA的導彈攻防仿真系統的設計與實現
基于HLA的物資保障仿真系統研究
基于HLA和網絡服務的協同仿真環境
基于DDS和HLA聯合仿真系統
基于IPv6的DiffServ流標簽分配機制
RFD3190混合功率倍增放大器模塊的詳細數據手冊免費下載






 工商網監
工商網監

評論