 AMR圖譜在自然語言處理中的應用
AMR圖譜在自然語言處理中的應用
引言
TreeBank 作為自然語言語法的結構化表示可謂廣為人知,其實在語義層面也有一種類似的結構化方法——抽象語義表示(Abstract Meaning Representation,AMR)。它能記錄自然語言文本中最重要的語義信息,但并不限制實際表達時的語法結構。本次分享我們將向讀者介紹 ACL 2022 中與 AMR 有關的三篇論文,一窺 AMR 圖譜在自然語言處理中的應用。
文章概覽
Graph Pre-training for AMR Parsing and Generation
AMR 既不會自動從文本中展現出來,也無法自行表達一個句子。因此對于 AMR 而言,最重要的任務就是從文本中構建 AMR,以及根據 AMR 生成文本。目前的主流模型均以預訓練語言模型作為基礎,然而本文作者指出,傳統的預訓練方法面向文本,存在任務形式錯配的問題。因此,本文首次提出將直接針對 AMR 的圖預訓練任務應用至預訓練語言模型中,并取得了不錯的效果。
Variational Graph Autoencoding as Cheap Supervision for AMR Coreference Resolution
理論上我們可以利用 AMR 圖譜分析多個句子甚至一篇文章的語義,但必須通過指代消融將多個指代相同實體的節點合并。目前的模型一方面需要大量的圖譜數據用于訓練,另一方面卻對數據噪聲較為敏感。本文作者通過將變分圖自編碼器引入既有的 AMR 指代消融模型,成功將存在一定錯誤的自動標注 AMR 圖譜數據納入訓練數據中,使模型性能得到了顯著提高。
AMR-DA: Data Augmentation by Abstract Meaning Representation
AMR 圖譜可以助力多種自然語言處理任務,不過本文探討的卻是一個比較另類的應用——自然語言數據增強。面向文本的數據增強方法或者容易導致病句,或者難以提供足夠的數據多樣性;相反,面向 AMR 的數據增強可以在輕微改變甚至不改變語義的前提下,生成通順而多變的文本。基于上述觀察,本文在兩個主流任務上比較了傳統方法與 AMR 數據增強的效果,并分析了 AMR 方法的優勢所在。
論文細節
1

研究動機
人工標注 AMR 圖譜往往費時費力,因此設計能相互轉換文本與 AMR 的自動模型就顯得非常重要。其中,從文本構建 AMR 稱為 AMR 解析(parsing),而根據 AMR 生成文本則稱為 AMR 生成(generation)。目前主流的方法是將 AMR 圖譜按照一定的節點順序(如 DFS 序列)表示為一個字符串,然后應用序列到序列(seq2seq)模型;然而,通常的序列到序列模型是基于文本設計的,并不能很好地學習 AMR 特有的圖結構。
為了實現能更好地利用圖結構的模型,本文作者探究了以下三個問題:能否設計完全基于圖的預訓練任務(即圖到圖任務)作為文本預訓練的補充?怎樣有效結合這兩類形式不同的訓練任務?能否引入其它模型自動標注的 AMR(存在一定噪聲)?本文即沿著上述三個問題,分別在 AMR 解析與生成兩個任務上進行了實驗與分析。
圖訓練任務
為了與既有的模型結果對齊,本文依然沿用了基于文本的 BART 模型,輸入或輸出序列化的 AMR 圖譜。BART 的預訓練任務是文本去噪,即從添加了噪聲的文本中重建原始內容,其中噪聲包括語段的增刪、調換、掩碼(MASK)覆蓋等。顯然如果直接對序列化 AMR 圖譜應用這些操作,很可能會破壞圖譜表示,導致模型難以利用結構信息恢復原始圖譜。
為此,作者巧妙地設計了兩類能夠表示為文本去噪的圖預訓練任務——節點/邊重建和子圖重建。其中,節點/邊重建任務隨機選取原始 AMR 圖譜中部分節點和邊,并用掩碼標簽覆蓋,要求模型恢復這些節點和邊的原始標簽;子圖重建任務則進一步將一個完整的隨機子圖替換為掩碼節點,要求模型恢復整個子圖。這些基于圖譜的變換既可以分別應用于不同的輸入,也可以同時使用。
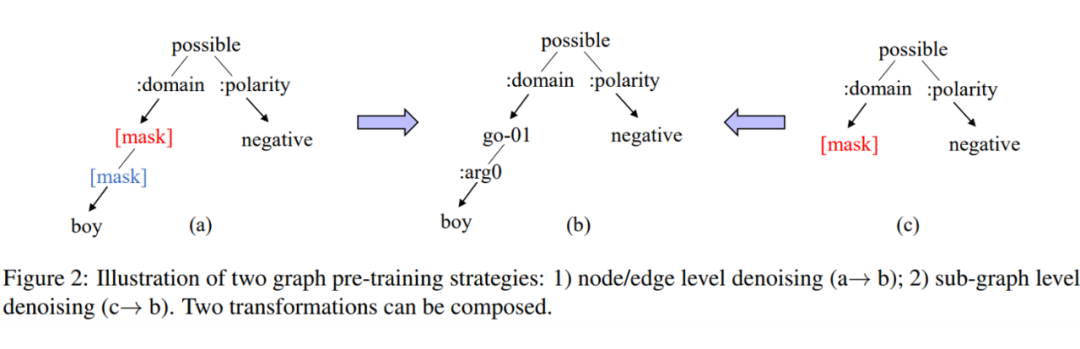
通過加入一些限制條件,上述兩個任務都能以文本掩碼、語段交換等形式套用既有的 BART 預訓練流程。這樣一方面可以在不改動既有模型架構的前提下進行圖訓練任務,另一方面可以增強模型對比結果的說服力。
聯合訓練框架
解決了任務設計的問題,還需要考慮如何統一圖訓練與文本訓練。本文作者注意到,這兩類預訓練任務和下游任務(AMR 解析與生成)都可以表示為如下形式:輸入一段文本或一個 AMR 圖譜,輸出另一段文本或另一個 AMR 圖譜;然而不難發現,預訓練任務的輸入與輸出有相同的形式,但下游任務卻并非如此——兩類任務的形式錯配了。
作者認為,這一錯配是目前序列到序列模型性能瓶頸的來源之一:模型在預訓練階段難以學習文本與圖譜信息交互的部分,然而無論是 AMR 解析還是生成任務都高度依賴這些交互信息。因此,他們進一步提出了文本-圖譜聯合預訓練框架,即模型同時輸入文本與圖譜信息,輸出期望的文本或圖譜。如此一來,上述各種任務無非是將其中一個輸入源置空而已。
在這樣一個統一的框架下,本文提出了將文本與圖譜結合起來的預訓練任務——其中一類是同時輸入文本與圖譜,但向其中某個輸入添加噪聲,并要求模型復原;另一類是同時向兩個輸入添加噪聲,并要求模型恢復其中一個。各個任務的損失函數與通常的去噪任務無異,均為交叉熵損失,且訓練期間可以同時加入所有任務,目標損失函數即為所有任務的損失函數之和。

與單純的文本或圖訓練任務相比,模型能同時利用文本與圖譜的信息,就有機會強化模型理解雙方交互的水平。此外,根據預訓練樣本量的不同,訓練樣本的噪聲水平會逐漸提高(即掩碼出現的頻率),使模型能漸進地學習。
實驗設計
利用以上提到的圖訓練與聯合訓練任務,本文選取 AMR 2.0 與 AMR 3.0 兩個人工標注數據集作為訓練集和主要測試集,并額外在 New3、小王子(LP)以及 Bio AMR 等小型數據集上測試模型的跨領域性能。此外為了回答第三個問題——能否利用自動標注數據,作者又從 Gigaword 語料庫(兩個主數據集的語料來源)隨機抽取部分句子,并采用 SPRING 模型生成自動標注的 AMR 圖譜,作為預訓練專用的附加數據集。
AMR 解析與 AMR 生成兩個任務均采用原版 BART 作為核心模型,并通過驗證集指標選取最優模型。AMR 解析任務采用目前主流的 Smatch 分數及其子項作為評價指標,AMR 生成任務則選取 BLEU、CHRF++ 和 METEOR 等文本生成評價指標。
結果及分析
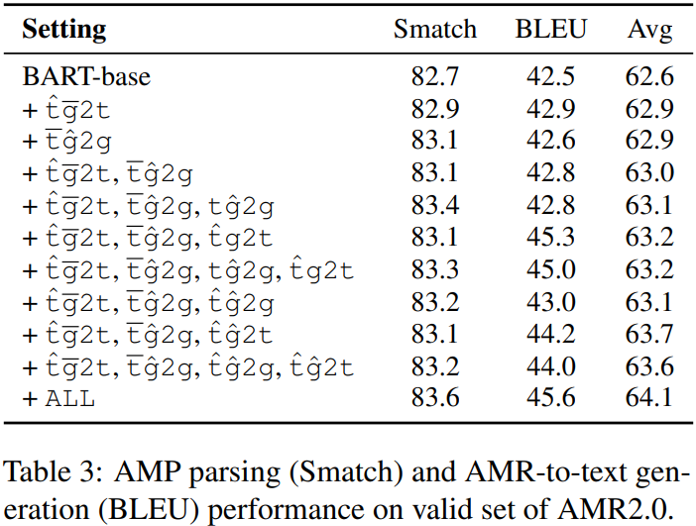
下圖展示了在驗證集上各種預訓練任務組合的效果,可見當模型是針對圖譜去噪預訓練時,解析任務的性能提升更明顯,生成任務的性能提升更明顯,且組合所有任務的效果是最好的。另外作者進一步發現,兩種圖預訓練形式都能提供一定程度的幫助,且子圖重建的貢獻更大一些。
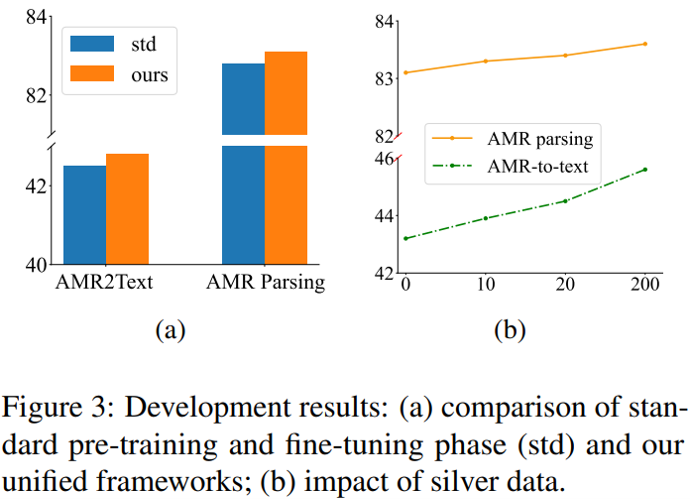
下圖列出了一些驗證集上的其它實驗結果。其中,左圖比較了兩種訓練范式下的模型性能,顯示通過聯合訓練框架預訓練的模型在兩個任務上都優于采用傳統任務預訓練的模型;右圖則統計了添加自帶噪聲的自動標注數據參加預訓練后的指標變化,表明在本文提出的訓練范式下,即使是自動標注數據也可以有效改善模型的性能。
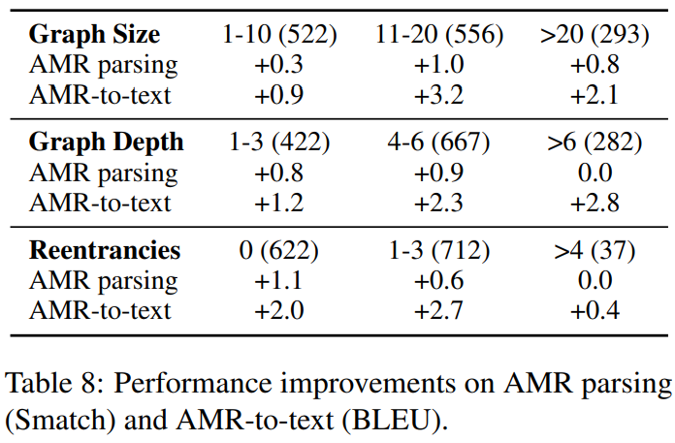
主數據集上的測試結果如下圖所示,包括 AMR 解析與 AMR 生成任務,可見本文提出的模型與其它主流模型相比,在各項指標上幾乎都實現了突破,甚至在生成任務上用較小的 bart-base 達到或超過了用 bart-large 作為核心的其它模型。值得注意的是,在這些模型中,本文提出的模型在利用自動標注數據時的表現是最好的——作者指出這是因為去噪預訓練任務可以更好地容忍一定的數據噪聲。此外,模型在跨領域數據集上的表性能也顯著優于參與比較的其它模型,顯示模型有更強的領域適應能力,作者認為是由于新的預訓練任務減輕了模型在精調階段的災難遺忘現象。
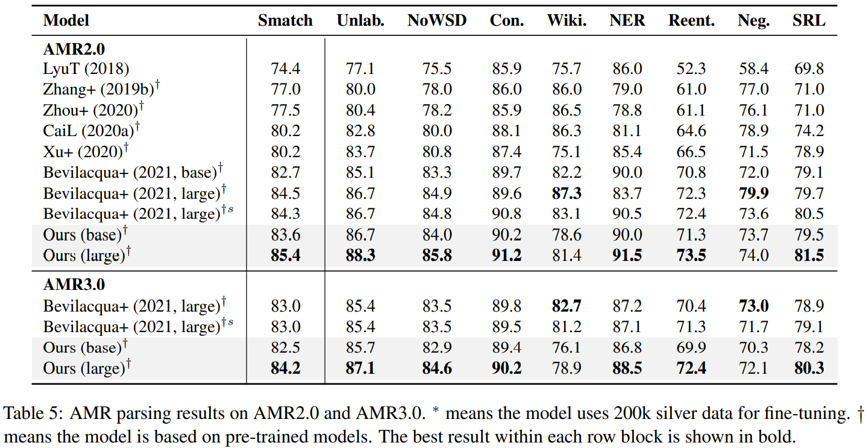
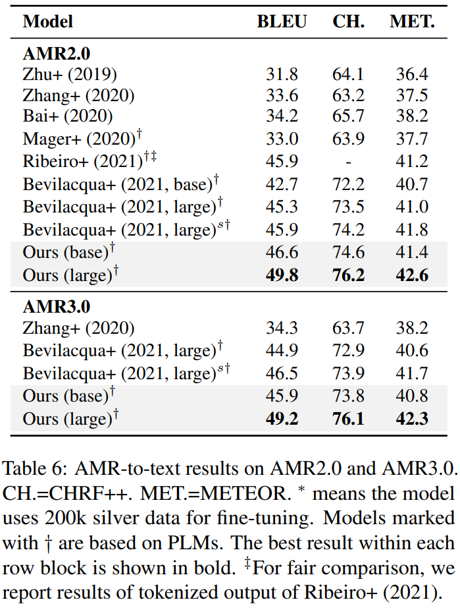
最后,本文作者還討論了應對復雜程度不同的 AMR 圖譜時,模型在兩個任務上的表現。從下圖的結果可以看到,模型的性能改進(特別是 AMR 生成)在更大、更深的圖上更加明顯,并且對有不同平均入度的圖也都有性能提升。
2

研究動機
雖然 AMR 是針對句子標注的,但從定義來看,它并不限制語義表達的規模,因此對一篇文章中每個句子生成 AMR 圖譜并整體處理是完全可行的。但在許多文章中,多個句子往往會涉及同一個實體,因此有必要將表達相同實體的 AMR 節點合并為一個聚類節點——這就是 AMR 上的指代消融任務。
早期的 AMR 指代消融主要有兩種方式,其一是人工設計匹配規則,其二是通過對齊 AMR 與文本,將面向文本的指代消融結果套用至 AMR 上。最近的研究開始聚焦于直接將基于神經網絡的文本指代消融模型改造為專用于 AMR 圖譜的模型,取得了不錯的成果;但正如上文所述,這類方法依然需要面對標注數據不足的困境。為了幫助模型走出這一困境,本文作者同樣試圖挖掘自動標注數據的潛力,使神經網絡模型也能很好地應用于 AMR 指代消融任務中。
模型結構
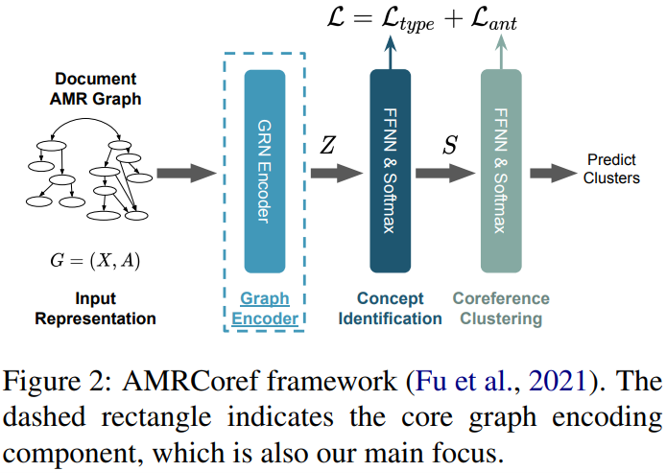
本文研究的基準模型稱為 AMRCoref,是一個直接在 AMR 圖譜上計算指代聚類的模型。整個模型由節點編碼、圖譜編碼、概念識別與指代聚類四個階段組成,其中概念識別需要確定 AMR 中各個節點的類別(功能詞、實體、動詞等),而指代聚類就專注于判斷節點之間有無指代關聯——模型正是基于后面這兩個階段的損失函數訓練的。
為了讓模型能學習帶有噪聲的自動標注數據,本文將 AMRCoref 中圖譜編碼采用的 GRN 替換為變分圖自編碼器(VGAE)。VGAE 由一個局部圖編碼器和一個局部圖解碼器組成,其中前者與 AMRCoref 的圖譜編碼階段作用相同,利用 GCN、GAT 或 GRN 將各個節點的編碼相互融合;后者則通過點積等運算試圖重建 AMR 的邊集——解碼器的目標正是要讓邊集重建損失以及變分限制懲罰之和最小。
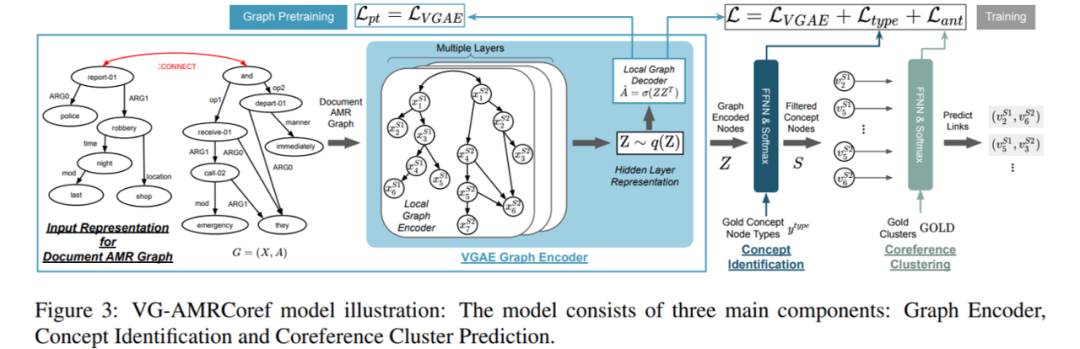
新的 VGAE-AMRCoref 模型有兩種訓練方式:直接訓練和圖編碼預訓練。直接訓練法與原始的 AMRCoref 基本相同,只是額外增加了 VGAE 的解碼器損失;圖編碼預訓練則只考慮解碼器損失,預訓練完畢后再針對下游任務精調。
實驗設計
本文選擇了 MS-AMR 基準測試作為訓練集和主測試集,并在小王子(LP)數據集上測試了跨領域性能;圖編碼預訓練采用 AMR 3.0(下文稱 AMR-gold)數據集。為了檢驗模型利用自動標注數據的能力,作者額外為 AMR-gold 的每個句子自動生成了 AMR 圖譜,組成同樣用于預訓練的 AMR-silver 數據集。指代消融的評測指標由 MUC、B3 和 CEAF-phi4 的 F-1 分數組成。
根據驗證集上的實驗結果,VGAE-AMRCoref 模型采用 GAT 作為圖編碼器。參與比較的模型包括一個基于節點字符串匹配的規則模型、一個結合文本指代消融與 AMR 對齊的模型和 AMRCoref;此外,AMRCoref 和 VGAE-AMRCoref 的節點編碼均考慮包含 BERT 編碼與不包含兩個版本。所有實驗結果均取 5 個隨機種子下的平均值。
結果及分析
下圖展示了各個模型在兩個不同的測試集上的指代消融性能。即使是未經過預訓練階段的 VGAE-AMRCoref,其性能也與 AMRCoref 相當;而加入預訓練任務后,模型性能得到了顯著提升,特別是在跨領域數據集上表現突出。另外,在節點編碼中引入 BERT 編碼可以讓模型略有改進,但并不明顯。
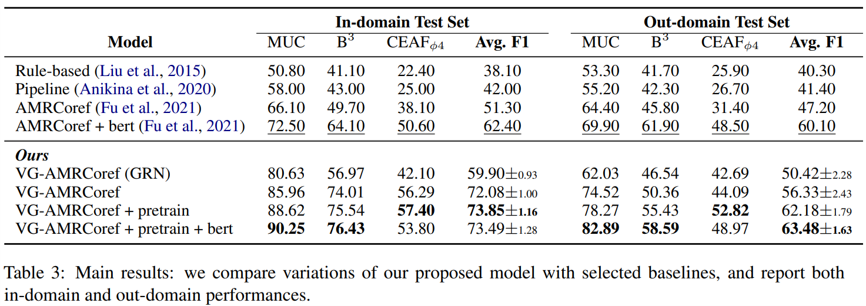
此外,本文作者還進行了若干消融實驗。下圖顯示了采用不同版本解碼器損失的實驗結果,可見無論是邊集重建損失亦或變分限制懲罰都能改進模型性能,且后者的效果更好一些。
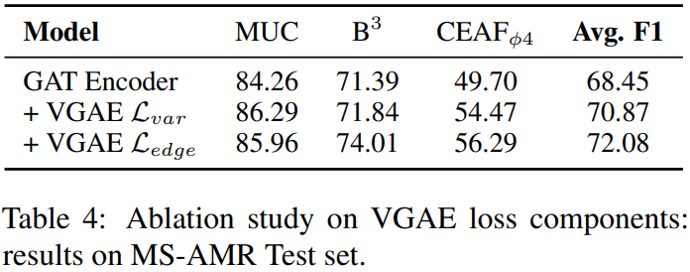
圖編碼器層數與模型性能的關系如下圖所示,不難發現圖神經網絡中常見的過平滑現象依然存在——當編碼器超過 3 層時,模型性能開始下降——這與 AMRCoref 的實驗結果一致。
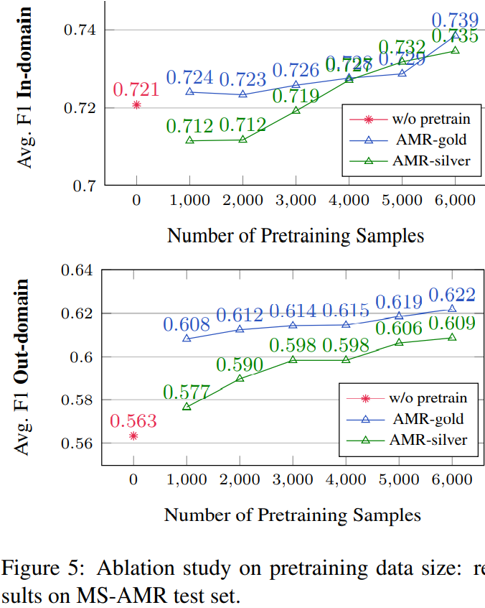
最后,下圖比較了將不同規模的 AMR-gold 與 AMR-silver 作為預訓練數據集時模型的效果。總體而言,越多的預訓練數據能帶來越高的分數,對兩個數據集而言都是如此。盡管自動標注的 AMR-silver 在小數據量時會稍微降低模型性能,但只要數據量達到一定水平,自動標注數據依然能帶來可觀的提升。作者在此也提出,如果能用更大規模的語料庫與更好的 AMR 解析模型,那么采用自動標注數據預訓練的 VGAE-AMRCoref 仍然存在提升空間。
3

研究動機
長期以來,數據增強技術(Data Augmentation,DA)在自然語言處理領域的應用都不算多。一方面,易于存儲的文本數據確實能以語料庫的形式提供大量樣本;但另一方面,目前的方法大部分難以在合理性與多樣性之間達到平衡——基于單詞的數據增強(如增刪調換)很容易造出病句或矛盾句,而基于句子的數據增強(如往復翻譯)則難以創造多變的句式,容易導致過擬合。
為了找到兼顧合理性與多樣性的數據增強方法,本文作者將目光轉向了 AMR。AMR 不限制語法的設定使得單個 AMR 圖譜能夠生成多種句式不同的句子,而且在一定范圍內修改 AMR 并不會顯著影響其語義。這些特性就使得 AMR 成為了自然語言數據增強的有力中介。
AMR 數據增強
AMR 數據增強(AMR-DA)包括三個階段:首先需要將文本語料解析為 AMR 圖譜,然后根據需求在 AMR 圖譜上作少量修改,最后從修改后的 AMR 圖譜生成新的文本。其中,AMR 解析模型選擇上文提到的 SPRING 模型,而 AMR 生成模型則采用了基于 T5 的預訓練文本生成模型。
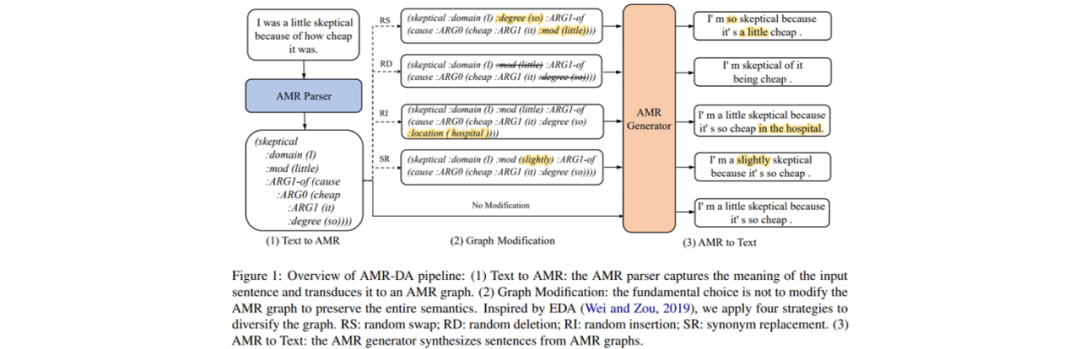
需要特別介紹的是 AMR 圖譜的修改操作,包括不修改(Ori)、隨機調換(RS)、隨機刪除(RD)、隨機插入(RI)和同義詞替換(SR)五種操作。
不修改操作即保持原有的 AMR 圖譜不變,單純利用生成模型實現文本改寫;
隨機調換每次將兩個概念節點連同其連邊交換,重復若干次;
隨機刪除每次刪除一個葉子節點及其連邊,重復若干次;
隨機插入每次從一個節點對庫中挑選一對連邊節點對插入,重復若干次,節點對庫是從 AMR 2.0 中提取并篩去不合適的連邊節點對組成的;
同義詞替換每次選擇一個概念節點,并用 PPDB 同義詞庫中的某個同義詞替換,重復若干次。
語義相似度實驗
本文作者首先在語義相似度(Semantic Textual Similarity,STS)任務上進行實驗。STS 要求計算句子對的語義相似度,在矛盾學習(一種無監督句級表示學習方法)中有重要應用;在這個任務中,自然語言數據增強可以提供相似度高的正例。為了檢驗各種數據增強方法在 STS 上的效果,本文選取了無監督的 ConSERT 和 SimCSE 兩個 STS 模型用于比較,并將原始模型采用的數據增強替換為 AMR-DA。所有模型都采用維基百科語料訓練,并在 7 個不同的 STS 基準數據集上測試。
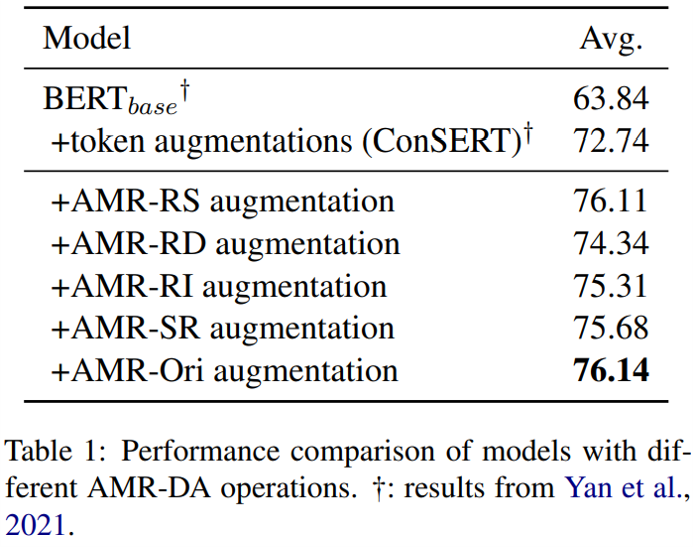
以下是各種修改操作的實驗結果,可見所有操作單獨應用時都能超過原版 ConSERT 采用的單詞級 DA。其中,不修改的提升效果最明顯,后續實驗表明這是由于這一操作可以生成相似度更高的句子對。值得留意的是,上述實驗顯示同義詞替換可以帶來最大的詞法多樣性,但這一方法同樣可以有效改進模型訓練。
下圖進一步比較了各種模型的測試性能,可以看到采用 AMR-DA 后,模型性能有了明顯提升,基本達到了領先水平。需要指出的是,ESimCSE 模型不僅有正例增強,還采用了負例增強,而 AMR-DA 雖然只能提供正例增強,但依然可以與之匹敵。

文本分類實驗
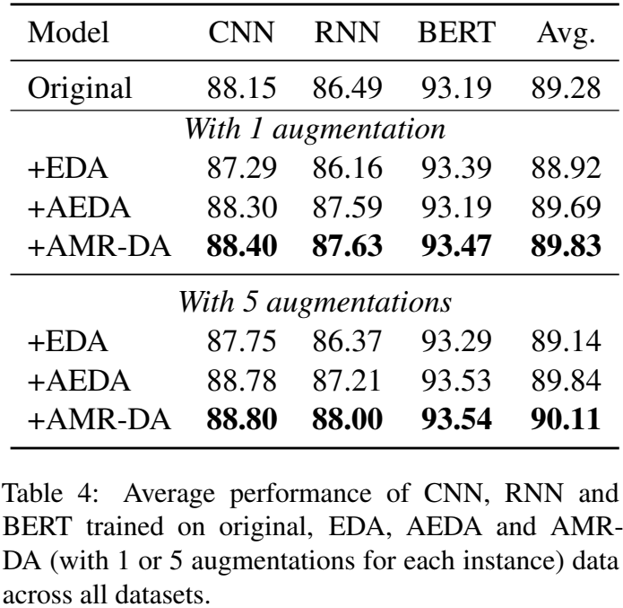
相比于語義相似度,文本分類(Text Classification,TC)的應用要廣泛得多,因此本文作者同樣在若干文本分類任務上測試了各種數據增強技術在 CNN、RNN、BERT 等神經網絡模型上的效果。針對同一種 DA 的所有實驗均采用相同的配置,且只應用于訓練集的一個子集上。此外,實驗分別測試了每個樣本應用一處和五處修改時模型的性能。
下圖展示了 TC 任務上的實驗結果,其中 EDA 直接在文本上應用類似 AMR-DA 的修改,而 AEDA 是 EDA 的一種改進版本。結果顯示,無論何種網絡、何種任務,AMR-DA 都取得了比其它 DA 更高的分數,并且同時采用五種修改方式的提升比單獨采用一種更大。
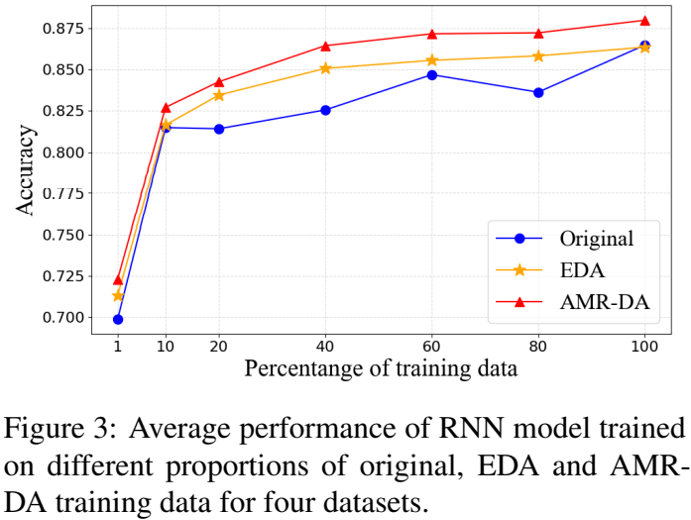
當限制模型訓練集大小時,模型性能的變化如下圖所示,可見 AMR-DA 在各種訓練集大小下都超過了 EDA,并且與原始訓練集相比有顯著改進。
機理分析
在上述兩個任務上實驗之后,本文作者嘗試從多個角度分析 AMR-DA 的優勢。下圖列出了不做任何 AMR 修改時 AMR-DA(以下稱為 AMR-Ori)的效果,即只考慮了 AMR 圖譜帶來的句式多樣性。可以看到,僅僅是通過解析-生成的方式改寫句子,AMR-Ori 就已經表現良好,并且不同生成模型對結果影響并不算大。

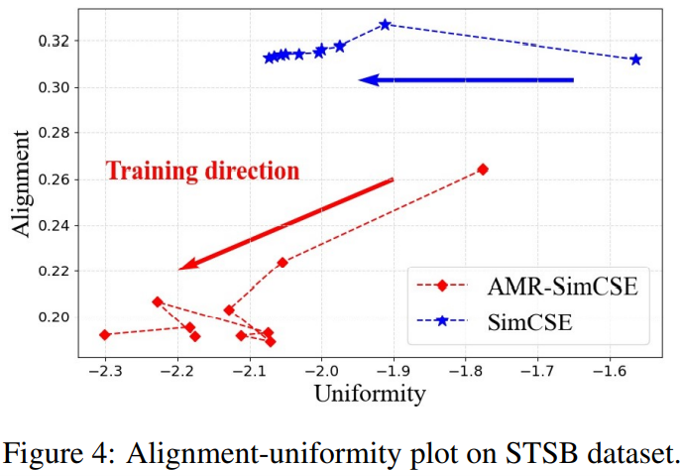
為了進一步考察 AMR-DA 帶來的變化,下圖展示了 STS 任務中 SimCSE 編碼在不斷學習的過程中對齊性(正例的相似程度)與統一性(隨機樣本的分散程度)的發展,其中兩個指標的值越低,編碼效果越好。對原版 SimCSE 而言,學習過程中雖然統一性指標確實在不斷下降,但對齊性指標未能進一步改進;而采用 AMR-DA 后,模型在兩個指標上都優于原版模型,且隨著新數據的學習均有下降。
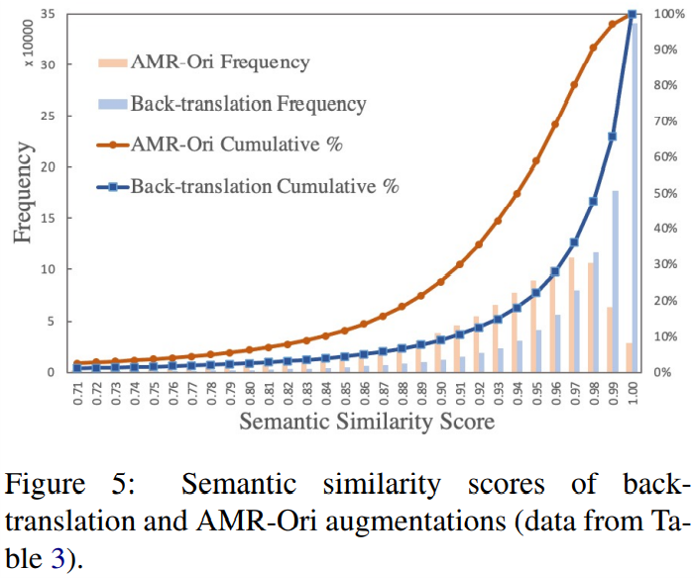
最后,下圖比較了 AMR-Ori 和往復翻譯生成句子對的相似度分布。兩種方法都可以視為對原文的改寫,但 AMR-Ori 的句子多樣性要顯著高于往復翻譯。這也解釋了為什么在 STS 任務中,往復翻譯效果糟糕,但 AMR-Ori 卻表現良好。
審核編輯 :李倩
-
AMR
+關注
關注
3文章
429瀏覽量
30243 -
自然語言
+關注
關注
1文章
288瀏覽量
13351
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論