

命名實(shí)體識(shí)別是NLP領(lǐng)域中的一項(xiàng)基礎(chǔ)任務(wù),在文本搜索、文本推薦、知識(shí)圖譜構(gòu)建等領(lǐng)域都起著至關(guān)重要的作用,一直是熱點(diǎn)研究方向之一。多模態(tài)命名實(shí)體識(shí)別在傳統(tǒng)的命名實(shí)體識(shí)別基礎(chǔ)上額外引入了圖像,可以為文本補(bǔ)充語(yǔ)義信息來(lái)進(jìn)行消岐,近些年來(lái)受到人們廣泛的關(guān)注。
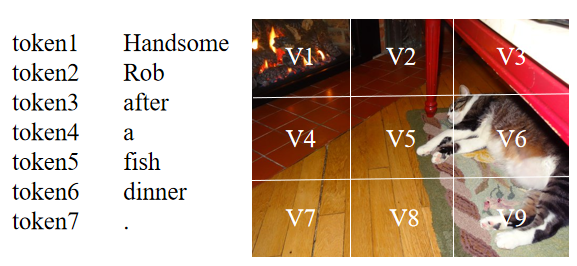
盡管當(dāng)前的多模態(tài)命名實(shí)體識(shí)別方法取得了成功,但仍然存在著兩個(gè)問(wèn)題:(1)當(dāng)前大部分方法基于注意力機(jī)制來(lái)進(jìn)行文本和圖像間的交互,但由于不同模態(tài)的表示來(lái)自于不同的編碼器,想要捕捉文本中token和圖像中區(qū)域之間的關(guān)系是困難的。如下圖所示,句子中的‘Rob’應(yīng)該和圖像中存在貓的區(qū)域(V5,V6,V9等)有著較高的相似度,但由于文本和圖像的表示并不一致,在通過(guò)點(diǎn)積等形式計(jì)算相似度時(shí),‘Rob’可能會(huì)和其它區(qū)域有著較高的相似度得分。因此,表示的不一致會(huì)導(dǎo)致模態(tài)之間難以建立起較好的關(guān)系。
(2)當(dāng)前的方法認(rèn)為文本與其隨附的圖像是匹配的,并且可以幫助識(shí)別文本中的命名實(shí)體。然而,并不是所有的文本和圖像都是匹配的,模型考慮這種不匹配的圖像將會(huì)做出錯(cuò)誤的預(yù)測(cè)。如下圖所示,圖片中沒(méi)有任何與命名實(shí)體“Siri”相關(guān)的信息,如果模型考慮這張不匹配的圖像,便會(huì)受圖中“人物”的影響將“Siri”預(yù)測(cè)為PER(人)。而在只有文本的情況下,預(yù)訓(xùn)練模型(BERT等)通過(guò)預(yù)訓(xùn)練任務(wù)中學(xué)到的知識(shí)可以將“Siri”的類(lèi)型預(yù)測(cè)為MISC(雜項(xiàng))。
Text: Ask [Siri MISC] what 0 divided by 0 is and watch her put you in your place.
為了解決上述存在的問(wèn)題,本文提出了MAF,一種通用匹配對(duì)齊框架(General Matching and Alignment Framework),將文本和圖像的表示進(jìn)行對(duì)齊并通過(guò)圖文匹配的概率過(guò)濾圖像信息 。由于該框架中的模塊是插件式的,其可以很容易地被拓展到其它多模態(tài)任務(wù)上。
本文研究成果已被WSDM2022接收,文章和代碼鏈接如下:
論文鏈接:https://dl.acm.org/doi/pdf/10.1145/3488560.3498475
代碼:https://github.com/xubodhu/MAF

整體框架
本文框架如下圖所示,由5個(gè)主要部分組成:
Input Representations
將原始的文本輸入轉(zhuǎn)為token序列的表示以及文本整體的表示,將原始的圖像輸入轉(zhuǎn)為圖像區(qū)域的表示以及圖像整體的表示。
Cross-Modal Alignment Module
接收文本整體的表示和圖像整體的表示作為輸入,通過(guò)對(duì)比學(xué)習(xí)將文本和圖像的表示變得更為一致。
Cross-Modal Interaction Module
接收token序列的表示以及圖像區(qū)域的表示作為輸入,使用注意力機(jī)制建立起文本token和圖像區(qū)域之間的聯(lián)系得到文本增強(qiáng)后的圖像的表示。
Cross-Modal Matching Module
接收文本序列的表示和文本增強(qiáng)后的圖像的表示作為輸入,用于判斷文本和圖像匹配的概率,并用輸出的概率對(duì)圖像信息進(jìn)行過(guò)濾。
Cross-Modal Fusion Module
將文本token序列的表示和最終圖像的表示結(jié)合在一起輸入到CRF層進(jìn)行預(yù)測(cè)。
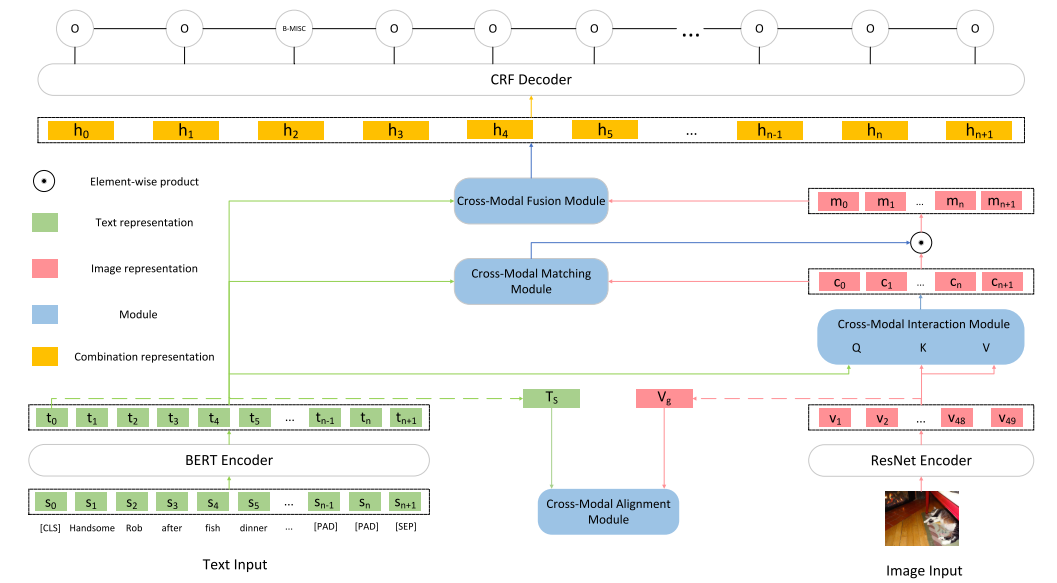
主要部分
Input Representations
本文使用BERT作為文本編碼器,當(dāng)文本輸入到BERT后,便可以得到token序列的表示,其中n為token的數(shù)量,為[CLS],為[SEP],,本文使用[CLS]的表示作為整個(gè)文本的表示。
本文使用ResNet作為圖像編碼器,當(dāng)圖像輸入到ResNet后,其最后一層卷積層的輸出被作為圖像區(qū)域的表示,其中為圖像區(qū)域的數(shù)量,即將整張圖像均分為49個(gè)區(qū)域。接著,使用大小為的平均池化層對(duì)進(jìn)行平均池化得到整個(gè)圖像的表示。由于后續(xù)和需要進(jìn)行交互,所以將通過(guò)一個(gè)全連接層將其投影到與相同的維度,其中。
Cross-Modal Alignment Module (CA)
該模塊遵循SimCLR[1]進(jìn)行對(duì)比學(xué)習(xí)的訓(xùn)練過(guò)程使得文本的表示和圖像的表示更趨于一致,接收以及作為輸入,通過(guò)對(duì)比學(xué)習(xí)來(lái)調(diào)整編碼器的參數(shù)。本文在構(gòu)造正負(fù)樣例階段中認(rèn)為原始的文本-圖像對(duì)為正樣例,除此之外的文本-圖像對(duì)均為負(fù)樣例,因此在大小為N的batch中,只有N個(gè)原始的文本-圖像對(duì)為正樣例,對(duì)于batch中的每個(gè)文本來(lái)說(shuō),除了其原始的image外,其余任意image與其都構(gòu)成負(fù)樣例,對(duì)于batch中的每個(gè)圖像來(lái)說(shuō)也是如此。如下圖所示,當(dāng)N為3時(shí),可以得到3個(gè)正樣例以及個(gè)負(fù)樣例。

接著,本文使用兩個(gè)不同的MLP作為投影層分別對(duì)和進(jìn)行投影得到以及。然后,通過(guò)最小化對(duì)比學(xué)習(xí)損失來(lái)最大化正樣例之間的相似度并且最小化負(fù)樣例之間的相似度來(lái)使得文本的表示和圖像的表示更加一致,image-to-text對(duì)比學(xué)習(xí)損失如下所示:
其中為余弦相似度,為溫度參數(shù)。text-to-image對(duì)比學(xué)習(xí)損失如下所示:
我們將上述兩個(gè)對(duì)比學(xué)習(xí)損失函數(shù)合并,得到最終的對(duì)比學(xué)習(xí)損失函數(shù):
其中為超參數(shù)。
補(bǔ)充:
Q:在“背景”部分提到的第(2)個(gè)問(wèn)題是圖文可能是不匹配的,為什么在CA中還是認(rèn)為來(lái)自同一文本-圖像對(duì)的數(shù)據(jù)為正樣例?
A:在EBR[2]中,作者通過(guò)類(lèi)似于對(duì)比學(xué)習(xí)的方式來(lái)訓(xùn)練一個(gè)向量召回模型(通過(guò)搜索文本來(lái)召回淘寶商品),并且認(rèn)為點(diǎn)擊和購(gòu)買(mǎi)的商品為正樣例,但這種點(diǎn)擊和購(gòu)買(mǎi)的信號(hào)除了和搜索內(nèi)容有關(guān)之外還受到商品價(jià)格、銷(xiāo)量、是否包郵等因素影響,類(lèi)似于本文中將原始的文本-圖像對(duì)看作正例,都是存在噪聲的。由于本身可以調(diào)節(jié)分布的特性,EBR作者通過(guò)增加的大小來(lái)減少數(shù)據(jù)噪聲的影響,并且通過(guò)實(shí)驗(yàn)證明將增大到一定數(shù)值(設(shè)置為3時(shí)達(dá)到最好)可以提高模型的表現(xiàn)。本文最終的也是一個(gè)相對(duì)較大的數(shù)字為0.1。而在其它數(shù)據(jù)噪聲相對(duì)較少的對(duì)比學(xué)習(xí)的工作中,如SimCSE[3],被設(shè)置為0.05,MoCo[4]中的被設(shè)置為0.07。
總的來(lái)說(shuō),CA中會(huì)存在一定數(shù)量的噪聲數(shù)據(jù),但可以通過(guò)提高的方式來(lái)顯著地降低其帶來(lái)的影響。
Cross-Modal Interaction Module (CI)
該模塊通過(guò)注意力機(jī)制建立起文本和圖像之間的關(guān)系,使用文本token序列表示作為Query,使用圖像的區(qū)域表示作為Key和Value,最終得到文本增強(qiáng)后的圖像表示。
Cross-Modal Matching Module (CM)
該模塊用于判斷圖文匹配的概率,并用概率調(diào)整圖像應(yīng)保留的信息。該模塊接受和作為輸入,輸出為和匹配的概率。由于缺少用于標(biāo)記圖文是否匹配的監(jiān)督數(shù)據(jù),本文使用一種自監(jiān)督的學(xué)習(xí)方式來(lái)訓(xùn)練該模塊。
首先,本文在大小為N的batch中構(gòu)造正負(fù)樣例,其中原始的文本-圖像對(duì)為正樣例,其余的為負(fù)樣例。本文通過(guò)隨機(jī)交換batch中前2k個(gè)樣例的來(lái)構(gòu)造負(fù)樣例,如下圖所示,在大小為3的batch中,交換前2*1個(gè)樣例的得到2個(gè)負(fù)樣例,而剩余的3-2=1個(gè)沒(méi)有被交換的樣例則為正樣例。
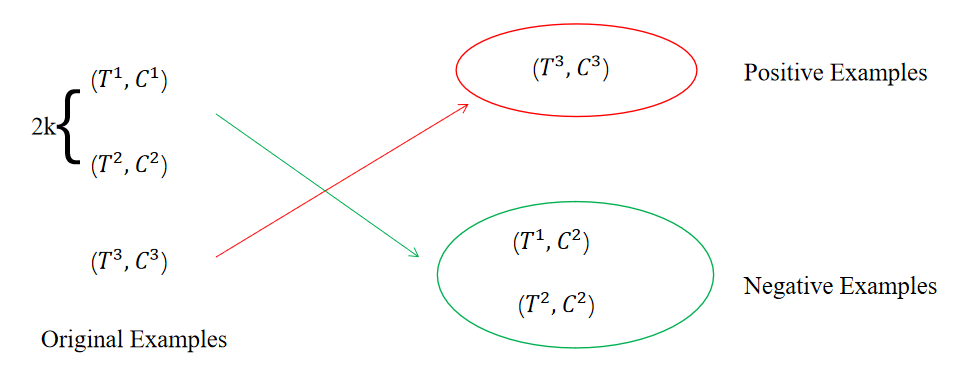
接著,將構(gòu)造好的每個(gè)樣例中的和拼接起來(lái)作為輸入到一個(gè)激活函數(shù)為sigmoid的全連接層中用于預(yù)測(cè)圖文匹配的概率。
判斷圖文是否匹配可以被看做是一個(gè)二分類(lèi)任務(wù),因此在獲取的正負(fù)樣例后,可以自然地獲得每個(gè)樣例的真實(shí)標(biāo)簽(正樣例為1,負(fù)樣例為0),再通過(guò)上述公式得到預(yù)測(cè)概率后,便可以使用二元交叉熵來(lái)訓(xùn)練該模塊。
最后,使用該模塊輸出的概率與進(jìn)行逐元素相乘來(lái)獲得圖像應(yīng)保留的信息(該模塊輸出的概率越大說(shuō)明圖文匹配的概率越高,則逐元素相乘圖像保留的信息越多)。
Cross-Modal Fusion Module (CF)
該模塊用于將文本token序列以及最終圖像的表示融合在一起。首先,本文使用門(mén)機(jī)制動(dòng)態(tài)地調(diào)整應(yīng)與文本結(jié)合的圖像表示:
最后將和拼接在一起得到,其中。將輸入到CRF層中,便可以得到每個(gè)token對(duì)應(yīng)的類(lèi)別。
訓(xùn)練時(shí),CA和CM中的損失會(huì)和命名實(shí)體識(shí)別的損失同步訓(xùn)練。
實(shí)驗(yàn)
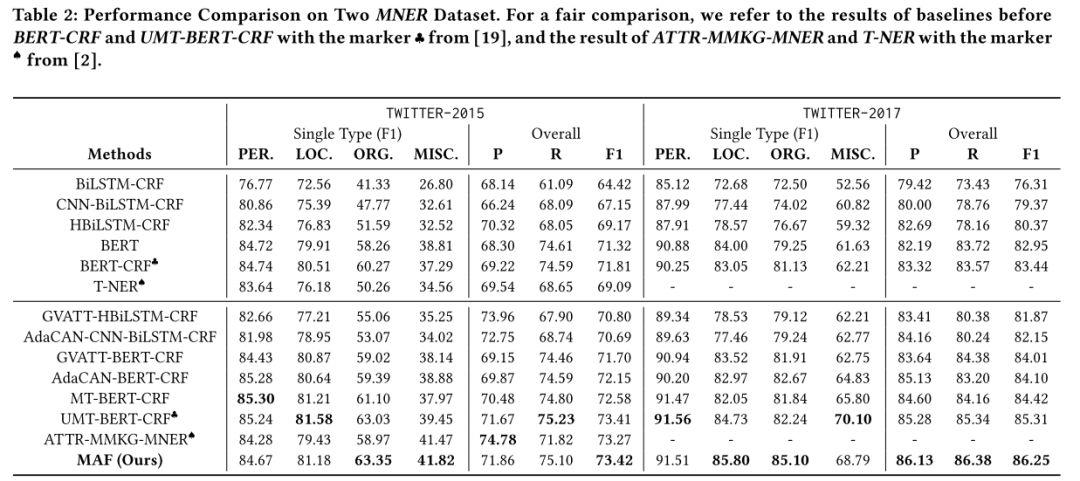
主要結(jié)果
本文的方法在Twitter-2015和Twitter-2017數(shù)據(jù)集上效果均優(yōu)于之前的方法。
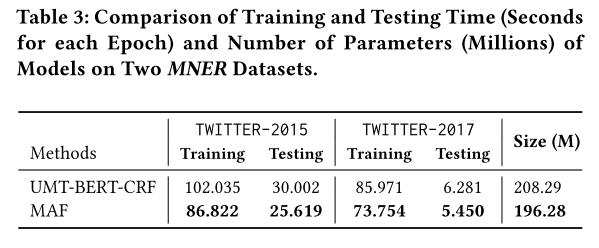
運(yùn)行時(shí)間
本文的方法相比于之前的方法除了有著模態(tài)之間交互的模塊(本文中為CI),還添加了對(duì)齊模態(tài)表示的CA以及判斷圖文是否匹配的CM,這可能會(huì)導(dǎo)致訓(xùn)練成本以及預(yù)測(cè)成本增加。但本文簡(jiǎn)化了模態(tài)之間交互的過(guò)程,因此整體訓(xùn)練和預(yù)測(cè)時(shí)間以及模型大小均由于之前的SOTA方法。
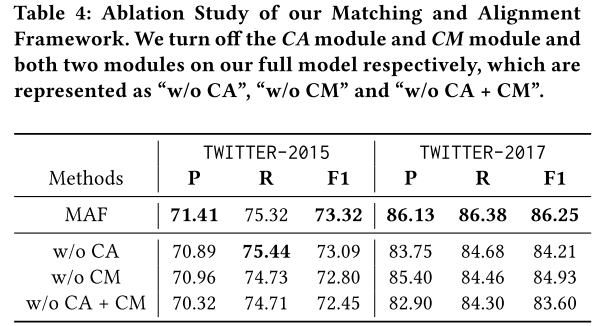
消融實(shí)驗(yàn)
本文進(jìn)行了消融實(shí)驗(yàn),驗(yàn)證了CA和CM的有效性。
樣例分析
本文還進(jìn)行了樣例分析來(lái)更加直觀地展示CA和CM的有效性。

參考資料
[1] A Simple Framework for Contrastive Learning of Visual Representations:http://proceedings.mlr.press/v119/chen20j/chen20j.pdf
[2] Embedding-based Product Retrieval in Taobao Search:https://arxiv.org/pdf/2106.09297.pdf?ref=https://githubhelp.com
[3] SimCSE: Simple Contrastive Learning of Sentence Embeddings:https://arxiv.org/pdf/2104.08821.pdf?ref=https://githubhelp.com
[4] Momentum Contrast for Unsupervised Visual Representation Learning:https://openaccess.thecvf.com/content_CVPR_2020/papers/He_Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning_CVPR_2020_paper.pdf
審核編輯 :李倩
-
圖像
+關(guān)注
關(guān)注
2文章
1094瀏覽量
41042 -
框架
+關(guān)注
關(guān)注
0文章
404瀏覽量
17797 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22497
發(fā)布評(píng)論請(qǐng)先 登錄
基于LockAI視覺(jué)識(shí)別模塊:C++多模板匹配
基于LockAI視覺(jué)識(shí)別模塊:C++多模板匹配

愛(ài)芯通元NPU適配Qwen2.5-VL-3B視覺(jué)多模態(tài)大模型

?多模態(tài)交互技術(shù)解析
海康威視發(fā)布多模態(tài)大模型文搜存儲(chǔ)系列產(chǎn)品
字節(jié)跳動(dòng)發(fā)布OmniHuman 多模態(tài)框架

商湯日日新多模態(tài)大模型權(quán)威評(píng)測(cè)第一
一文理解多模態(tài)大語(yǔ)言模型——下

利用OpenVINO部署Qwen2多模態(tài)模型
云知聲山海多模態(tài)大模型UniGPT-mMed登頂MMMU測(cè)評(píng)榜首

使用 TMP1826 嵌入式 EEPROM 替換用于模塊識(shí)別的外部存儲(chǔ)器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論