


命名實體識別是NLP領域中的一項基礎任務,在文本搜索、文本推薦、知識圖譜構建等領域都起著至關重要的作用,一直是熱點研究方向之一。多模態命名實體識別在傳統的命名實體識別基礎上額外引入了圖像,可以為文本補充語義信息來進行消岐,近些年來受到人們廣泛的關注。
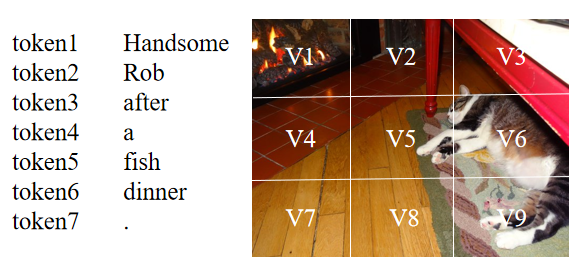
盡管當前的多模態命名實體識別方法取得了成功,但仍然存在著兩個問題:(1)當前大部分方法基于注意力機制來進行文本和圖像間的交互,但由于不同模態的表示來自于不同的編碼器,想要捕捉文本中token和圖像中區域之間的關系是困難的。如下圖所示,句子中的‘Rob’應該和圖像中存在貓的區域(V5,V6,V9等)有著較高的相似度,但由于文本和圖像的表示并不一致,在通過點積等形式計算相似度時,‘Rob’可能會和其它區域有著較高的相似度得分。因此,表示的不一致會導致模態之間難以建立起較好的關系。
(2)當前的方法認為文本與其隨附的圖像是匹配的,并且可以幫助識別文本中的命名實體。然而,并不是所有的文本和圖像都是匹配的,模型考慮這種不匹配的圖像將會做出錯誤的預測。如下圖所示,圖片中沒有任何與命名實體“Siri”相關的信息,如果模型考慮這張不匹配的圖像,便會受圖中“人物”的影響將“Siri”預測為PER(人)。而在只有文本的情況下,預訓練模型(BERT等)通過預訓練任務中學到的知識可以將“Siri”的類型預測為MISC(雜項)。
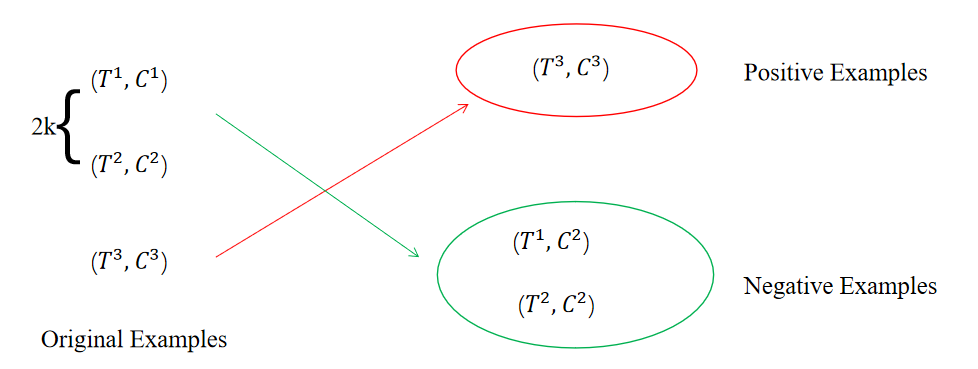
為了解決上述存在的問題,本文提出了MAF,一種通用匹配對齊框架(General Matching and Alignment Framework),將文本和圖像的表示進行對齊并通過圖文匹配的概率過濾圖像信息 。由于該框架中的模塊是插件式的,其可以很容易地被拓展到其它多模態任務上。
本文研究成果已被WSDM2022接收,


整體框架
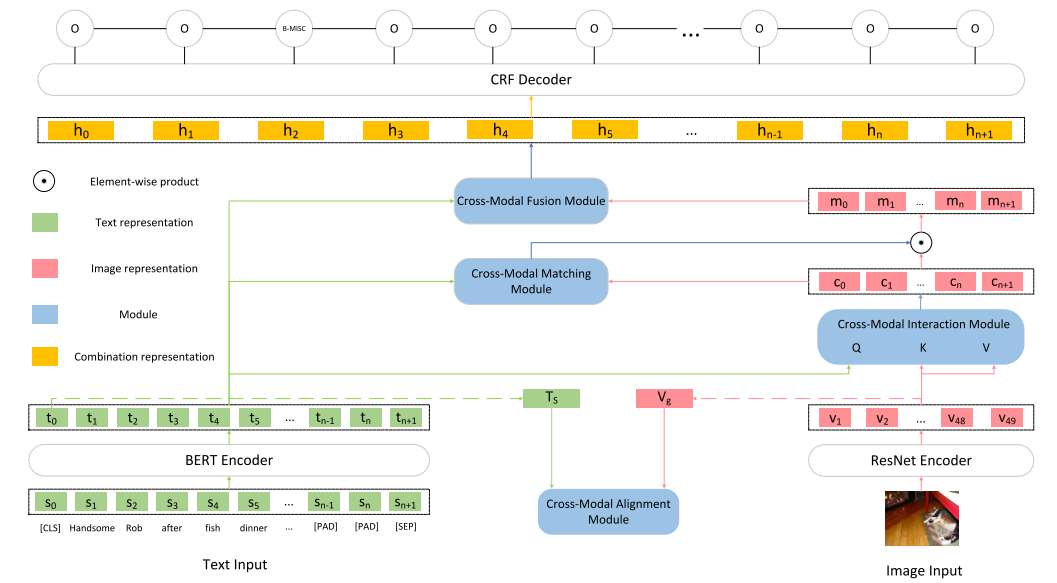
本文框架如下圖所示,由5個主要部分組成:
Input Representations
將原始的文本輸入轉為token序列的表示以及文本整體的表示,將原始的圖像輸入轉為圖像區域的表示以及圖像整體的表示。
Cross-Modal Alignment Module
接收文本整體的表示和圖像整體的表示作為輸入,通過對比學習將文本和圖像的表示變得更為一致。
Cross-Modal Interaction Module
接收token序列的表示以及圖像區域的表示作為輸入,使用注意力機制建立起文本token和圖像區域之間的聯系得到文本增強后的圖像的表示。
Cross-Modal Matching Module
接收文本序列的表示和文本增強后的圖像的表示作為輸入,用于判斷文本和圖像匹配的概率,并用輸出的概率對圖像信息進行過濾。
Cross-Modal Fusion Module
將文本token序列的表示和最終圖像的表示結合在一起輸入到CRF層進行預測。
主要部分
Input Representations





實驗
主要結果
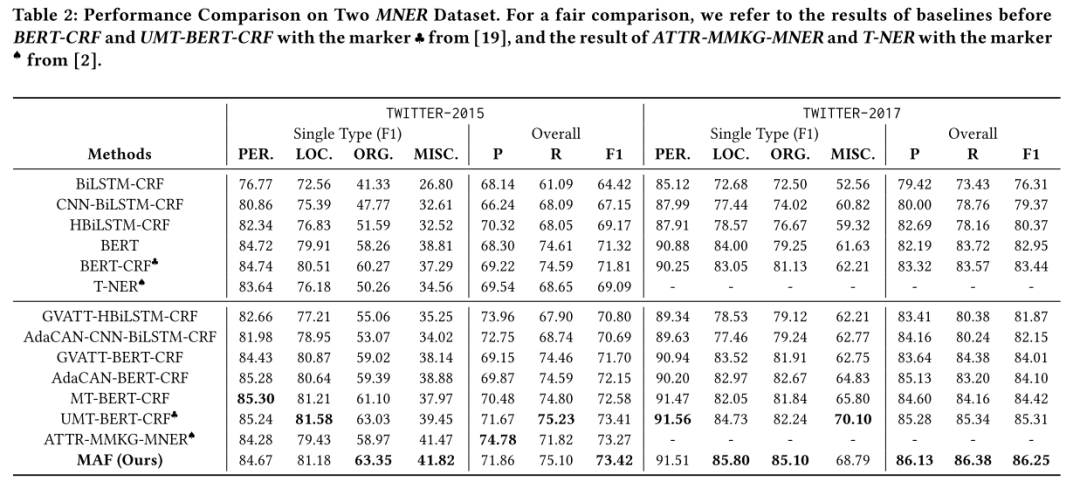
本文的方法在Twitter-2015和Twitter-2017數據集上效果均優于之前的方法。
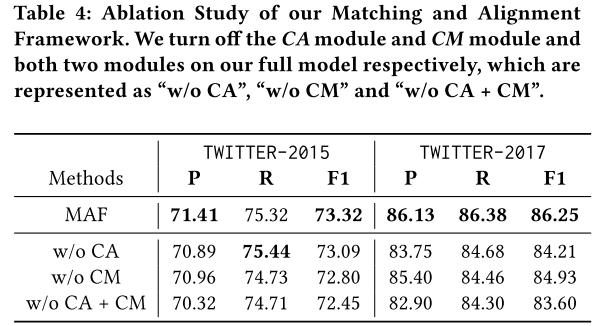
運行時間
本文的方法相比于之前的方法除了有著模態之間交互的模塊(本文中為CI),還添加了對齊模態表示的CA以及判斷圖文是否匹配的CM,這可能會導致訓練成本以及預測成本增加。但本文簡化了模態之間交互的過程,因此整體訓練和預測時間以及模型大小均由于之前的SOTA方法。
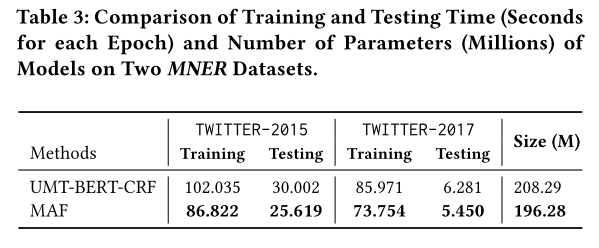
消融實驗
本文進行了消融實驗,驗證了CA和CM的有效性。
樣例分析
本文還進行了樣例分析來更加直觀地展示CA和CM的有效性。

審核編輯:劉清
-
編碼器
+關注
關注
45文章
3793瀏覽量
137973 -
MLP
+關注
關注
0文章
57瀏覽量
4606
原文標題:用于多模態命名實體識別的通用匹配對齊框架
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
dhkey chcks不匹配怎么解決?
Allegro Skill布局功能--器件絲印過孔對齊介紹與演示
一種新型激光雷達慣性視覺里程計系統介紹
一種實時多線程VSLAM框架vS-Graphs介紹
PCB布局太亂? Altium Designer這個快捷鍵幫你一秒對齊全場
一種多模態駕駛場景生成框架UMGen介紹
Orcad繪制原理圖的元器件對齊方法

AI開發框架集成介紹
一種降低VIO/VSLAM系統漂移的新方法
KiCad的對齊工具不好用?
一種使用LDO簡單電源電路解決方案
一種面向飛行試驗的數據融合框架






 工商網監
工商網監

評論