") 幾個經(jīng)典的立體匹配算法的評價指標和數(shù)據(jù)集
幾個經(jīng)典的立體匹配算法的評價指標和數(shù)據(jù)集
一. ADCensus背景介紹
到目前為止,我通過解讀Stefano Mattoccia教授的經(jīng)典講義,介紹了立體匹配算法的全貌。然后介紹了幾個經(jīng)典的立體匹配算法的評價指標和數(shù)據(jù)集。下一步我將介紹經(jīng)典的立體匹配算法,并展示它們在實際中的應(yīng)用。 先來看看你現(xiàn)在讀到哪里了吧:
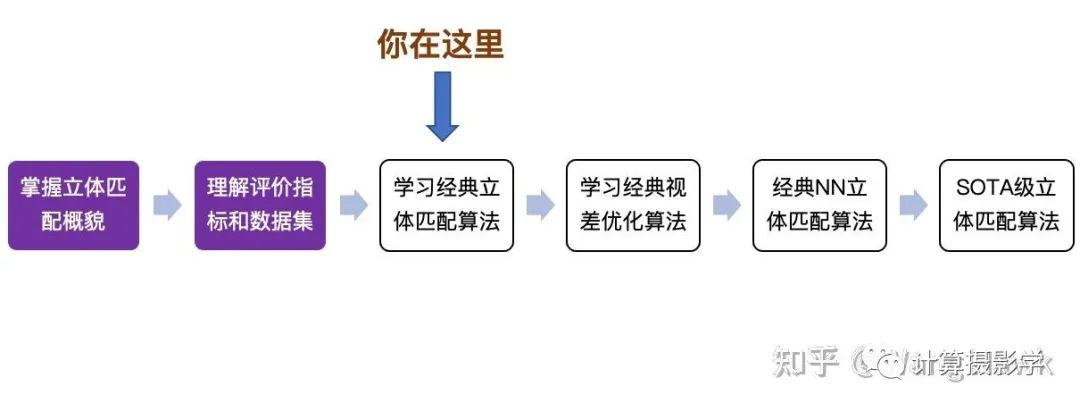
經(jīng)典立體匹配算法局部法和全局法的總體流程,如下圖所示:
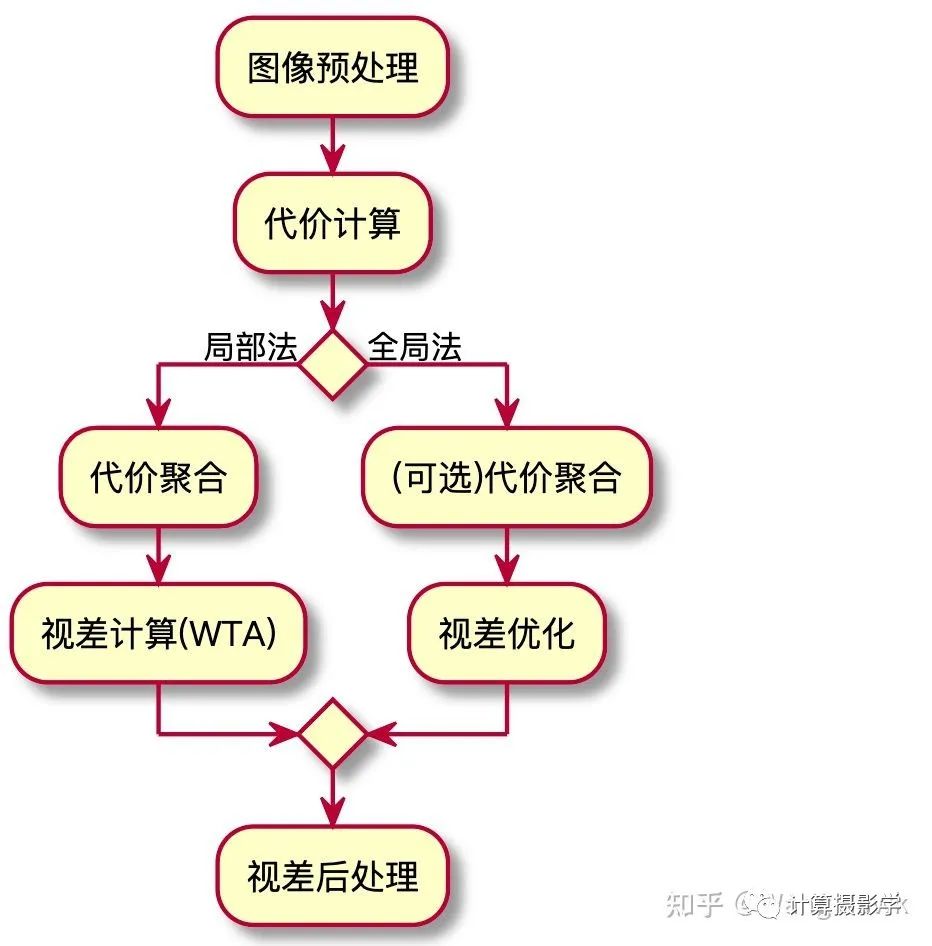
事實上,有一些算法的流程比較混合——比如今天我將介紹的一個經(jīng)典立體匹配算法,它總體來說是局部法的流程,但其中也有少量模塊在進行視差優(yōu)化的過程。 這個方法很多人簡稱為ADCensus,是三星先進技術(shù)研究院中國實驗室以及中科院自動化所的一群學(xué)者的成果,文章發(fā)表于2011年:

我用下圖總結(jié)這篇文章的完整流程,我們可以利用Stefano Mattoccia教授給出的流程來對比理解ADCensus。
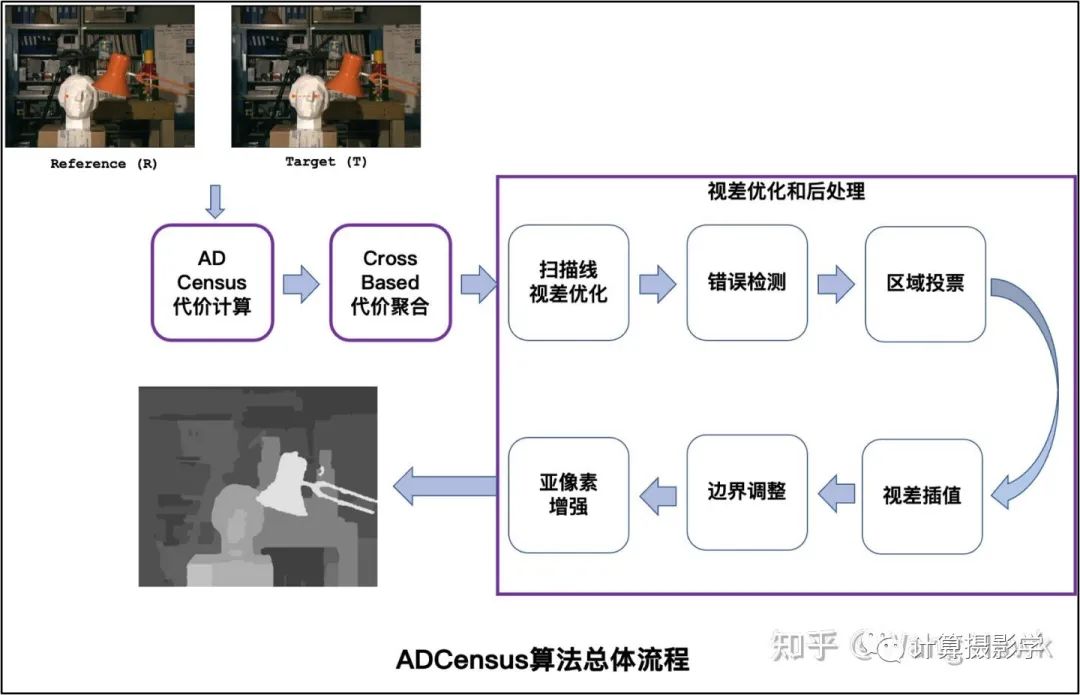
這個算法我個人非常喜歡,因為它的流程非常規(guī)范,而且易于理解。簡直就像學(xué)習(xí)了Stefano Mattoccia教授的講義后,將各個標準組件用當(dāng)時各種優(yōu)秀的算法實現(xiàn)并串聯(lián)起來的作品,可以說上面圖中每一個組件都有當(dāng)時已經(jīng)發(fā)表的論文做基礎(chǔ)。但作者也并非簡單的搞了一個縫合怪出來, 而是把許多組件都做了創(chuàng)造性的優(yōu)化。比如把AD和Census兩種特征融合在一起計算代價,并優(yōu)化了基于十字架的代價聚合算法,同時組合使用了一系列的視差優(yōu)化的后處理算法。而且,作者還在文章中描述了算法的CUDA實現(xiàn),使得這個算法可以高效的在硬件上運行。 每一年計算機視覺領(lǐng)域都有大量的研究成果,但其中能夠?qū)嵱没恼娴牟欢啵鳤DCensus就是其中之一。據(jù)我了解,很多硬件實現(xiàn)的立體匹配算法受到了ADCensus的啟發(fā)。比如OAK相機,這是一個由OpenCV基金會發(fā)起的成功的眾籌產(chǎn)品,可以實時計算深度圖,完成一系列復(fù)雜的功能。
它們推出了多款產(chǎn)品,我手上有下面這一款:

這個相機內(nèi)部集成的立體匹配算法,就是基于ADCensus的思想實現(xiàn)的,我們可以在這里查到相應(yīng)的介紹,如下圖所示,當(dāng)然這里為了效率在原始的算法上做了必要的裁剪和調(diào)整。
另外,Intel公司的著名產(chǎn)品Intel Realsense D400后的系列RGBD相機也借鑒了本文作者提出的立體匹配算法,特別是其中代價計算部分,在Census特征基礎(chǔ)上疊加AD這樣的特征,就是從ADCensus方法中借鑒的方法。 如果你查看2017年CVPR的下面這篇關(guān)于Intel RealSense的論文,你會看到對此的清晰描述

總之,一群中國學(xué)者,在2011年左右搞出了一種非常實用化的立體匹配算法,在很多領(lǐng)域都得到了應(yīng)用,非常值得欽佩!
二. 效果展示
我在github上找到了一個比較原汁原味的算法實現(xiàn):https://github.com/DLuensch/StereoVision-ADCensus,我們來看看效果吧。 先來看兩對MiddleBurry中的經(jīng)典圖像,左上和左下是校正后的圖像,右邊是算法默認參數(shù)生成的視差圖,看起來還不錯:

再看看這把椅子吧,看起來對這種復(fù)雜的場景稍微差點意思,需要仔細的調(diào)優(yōu)參數(shù)才行(我?guī)缀跤玫氖悄J參數(shù)):

來試試摩托車,盡管還遺留了一些空洞,整個畫面的深度圖還是被正確恢復(fù)出來了,總的來說,效果還是令人滿意的

再看看在MPI Sintel數(shù)據(jù)集上的效果,這個數(shù)據(jù)集的具體介紹請見76. 三維重建11-立體匹配7,解析合成數(shù)據(jù)集和工具,可以看到前景效果總體來說不錯,背景似乎都為0,看起來是因為太遠了的原因?

然后我們請出我的御用模特Sunny妹來試試,看起來默認參數(shù)在這種場景下有很多錯誤,需要仔細調(diào)參才能得到更好的結(jié)果。我們待會會仔細分析下ADCensu算法的各個步驟和相關(guān)參數(shù):

三. 原理簡介
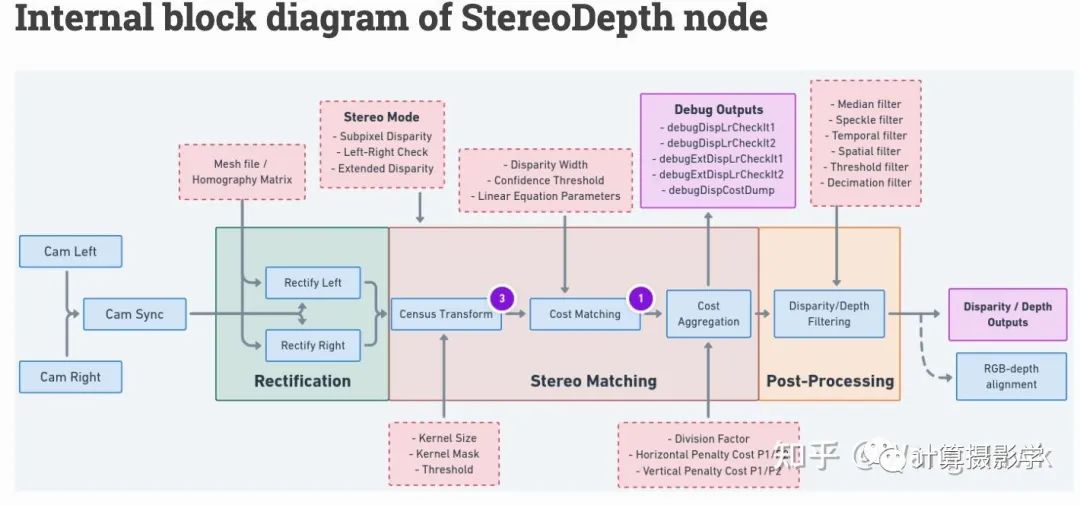
3.1 代價計算
立體匹配算法總體理解中說過代價計算的過程類似于連連看的過程:
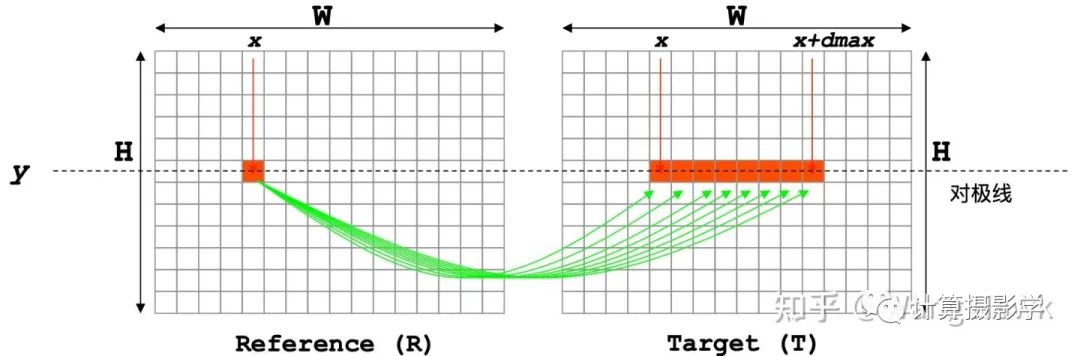
最簡單的代價就是左右圖中相應(yīng)像素的亮度絕對差,這種代價被稱為AD:
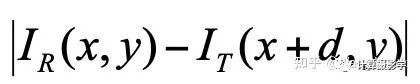
然而,這種代價在圖像中的平坦區(qū)域(亮度值都差不多)很顯然會得到錯誤的結(jié)果。此時顯然應(yīng)該使用別的特征來計算代價。Cencus就是一種很好的特征,它衡量了局部區(qū)域中像素亮度的排序,這是一種結(jié)構(gòu)信息。這就使得它很好的避免了左右圖像素亮度差異、噪聲、重復(fù)紋理等因素帶來的錯誤。 不過,僅使用Census特征的話,在圖像中重復(fù)結(jié)構(gòu)的區(qū)域,也會得到錯誤的結(jié)果。這時候顏色或亮度特征則可以加以輔助。所以ADCensus的作者創(chuàng)造了一種很不錯的融合亮度差異和結(jié)構(gòu)差異的方法,如下面公式所述。這里前一部分是基于Census的代價,后一部分是AD代價,所以這個算法才被很多人稱為ADCensus:
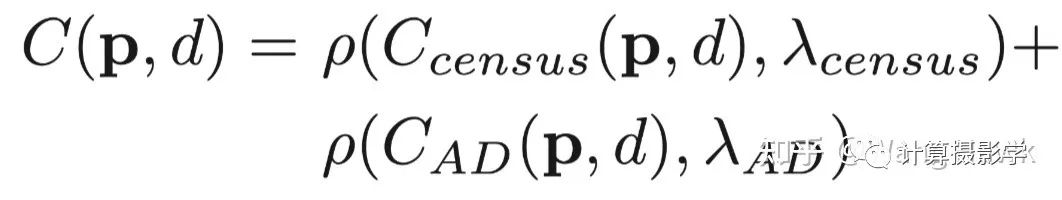
這里面,為了讓兩部分代價歸一化到[0,1]之間,作者采用了下面這個歸一化函數(shù),它能很方便的將輸入的原始代價轉(zhuǎn)換為[0,1]之間的值,而這里的λ則用于設(shè)置代價的權(quán)重:
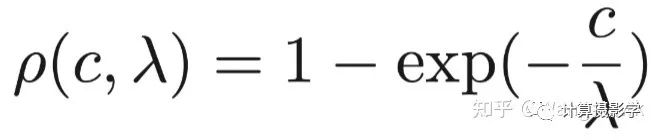
我們通過作者給出的下圖可以很容易的看到混合兩種代價帶來的好處:

這時候,直接利用AD-Census計算固定窗口的代價,然后用WTA得到視差圖,如下圖所示。我們可以看到這里有大量的噪聲和空洞區(qū)域。這是很容易理解的,所以才需要下一節(jié)所述的代價聚合過程:

3.2 代價聚合
ADCensus所用的代價聚合方法很有意思。在我的文章71. 三維重建6-立體匹配2,立體匹配中的代價聚合中,我提到了代價聚合的假設(shè):
空間上接近的像素,其視差值也是接近的,于是代價值也是接近的
像素值接近的像素,其視差值也是接近的,于是代價值也是接近的
左右兩張圖的相鄰像素,在關(guān)鍵信息上具有局部相似性
我們還看到了各種各樣的聚合方式,有一類方式就是用可變形狀的支持窗來進行聚合的——ADCensus的方法就屬于這種。當(dāng)要確定某個像素點p的支持窗時,它是通過尋找上下左右四個"臂",在這四個臂的包裹下構(gòu)成了其支持窗。確切說,首先找到p的上下臂,也就是在空間和像素值兩個維度上都盡可能接近p的兩端像素。這樣就構(gòu)成了一個包含在p內(nèi)的垂直的像素線段。在這條線段上的任何一個點q,我們都確定其左右臂,得到水平的遠端像素。這樣,所有q點的左右臂的遠端像素就形成了一個包絡(luò),其中就是p點的支持窗。
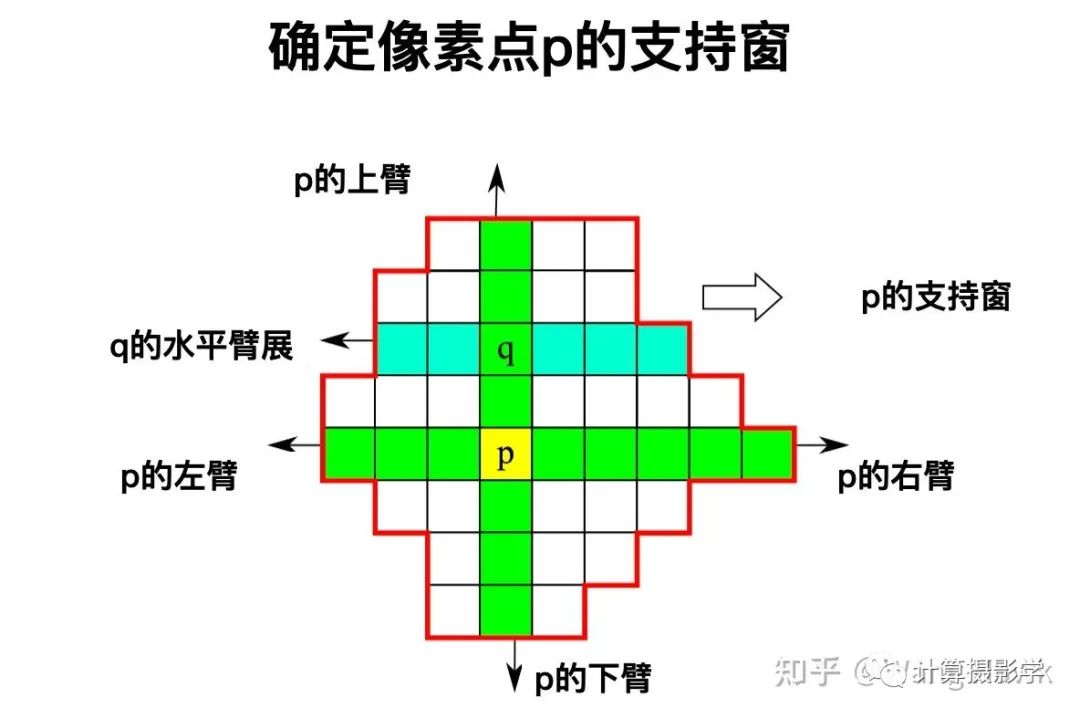
有了支持窗后,就比較容易聚合了,先在水平方向聚合,將水平方向的代價值加到一起。然后在垂直方向聚合,得到總的代價:
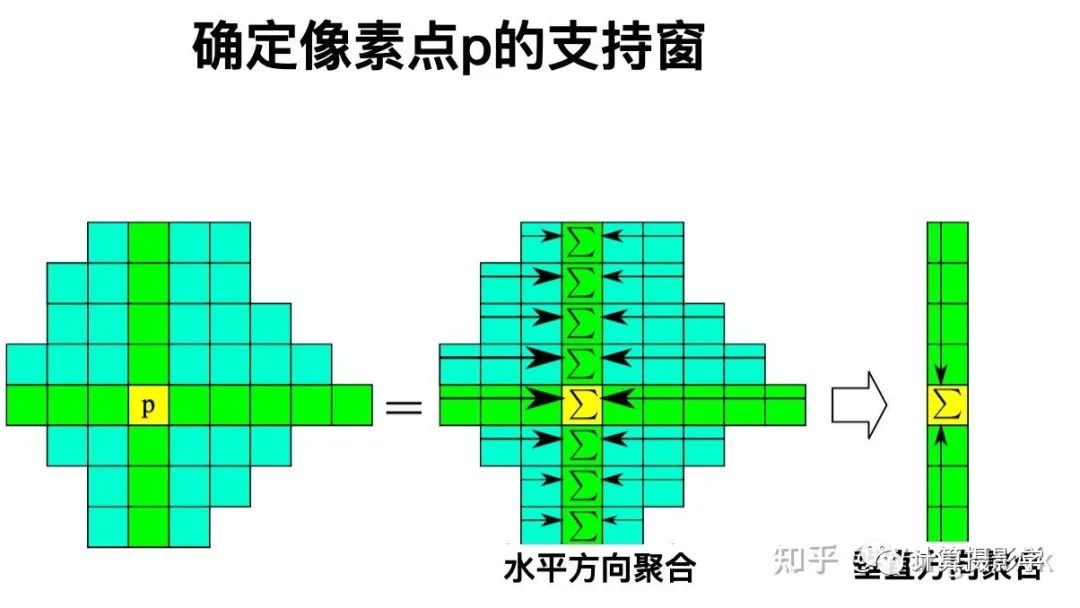
事實上,ADCensus中為了讓結(jié)果更好,進行了4次交替方向的聚合。即先水平再垂直,這是第1次。第二次相反,先垂直,再水平。然后再進行2次交替的聚合。最終四次的代價整合到一起,成為最后聚合后的代價值。 那么,如何得到上面所說的p點的四個臂呢?這似乎是得到支持窗的關(guān)鍵。我們以獲得p的左臂為例來說明:

所以很顯然,這里面的幾個參數(shù)L1, L2等參數(shù)τ2 都很重要。總之,通過這一步代價聚合后,我們能夠得到更加平滑的視差圖,如下圖所示:

3.3 掃描線優(yōu)化
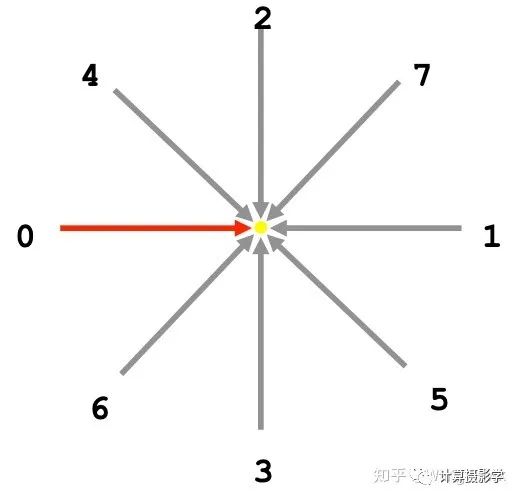
在文章72. 三維重建7-立體匹配3,立體匹配算法中的視差優(yōu)化中,我們看到了一種掃描線優(yōu)化的方法。ADCensus也采用了這種方法,通過聚合后的代價優(yōu)化得到視差圖。在這篇文章中我已經(jīng)詳細闡述了方法,這里只說說不同之處。在原始的掃描線優(yōu)化方法中,一共是8個方向。而ADCensus為了提高計算速度,只采用了其中的0、1、2、3這幾個水平和垂直的掃描線:
通過這一步,能得到更加準確的視差圖,如下圖所示。相比上面代價聚合后的結(jié)果,這里明顯噪聲小了很多:

3.4 視差后處理
接下來就是視差后處理了,這里是我覺得這個算法的可圈可點之處。作者幾乎把我在73. 三維重建8-立體匹配4,利用視差后處理完善結(jié)果中提到的視差后處理方法都用上了,形成了一個復(fù)雜的管線,如下圖所示。我會在后面對這種方式進行評價,但讓我們先跟著作者的脈絡(luò)往下學(xué)習(xí)吧。

3.4.1 錯誤檢測和區(qū)分
首先需要通過左右一致性檢查判斷哪些像素是錯誤的:
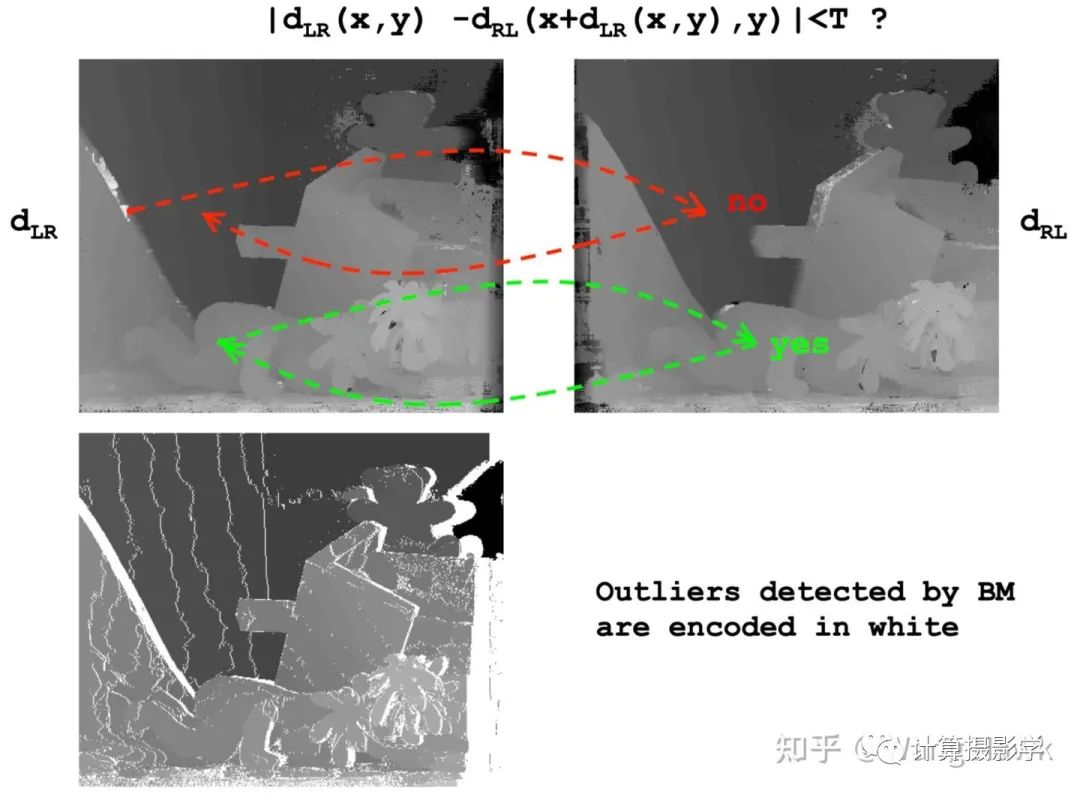
然后,通過一個簡單的法則來區(qū)分到底是因為遮擋導(dǎo)致的錯誤,還是因為錯誤匹配導(dǎo)致的錯誤。遮擋像素?zé)o論調(diào)整d為多少,都無法通過左右一致性檢測。而錯誤匹配則可以通過調(diào)整d,得到滿足左右一致性檢查的新視差值。
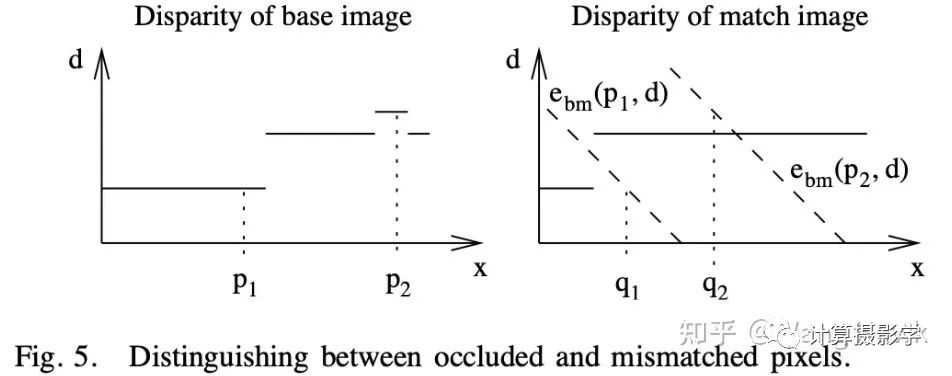

接下來,就可以分別對遮擋和錯誤匹配進行處理了。
3.4.2 區(qū)域投票
首先進行區(qū)域投票。在錯誤像素點p的支持窗內(nèi),對所有正確計算視差的像素(即通過了左右一致性檢測)的視差值建立一個直方圖。如果這個支持窗中穩(wěn)定視差值足夠多,并且直方圖中占比最大的視差值的占比大于某個閾值,我們就把p點的視差值更新為最大占比的視差值:
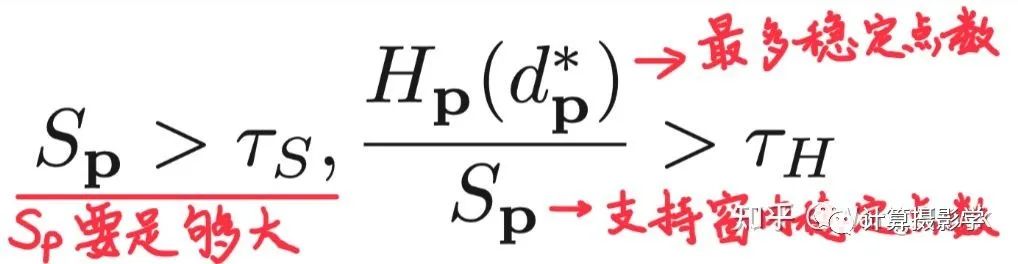
這里面,Sp代表支持窗中正確視差值的個數(shù),Hp(d*p)代表直方圖中占比最大的視差值的數(shù)量

3.4.3 分情況插值
前面我們區(qū)分了遮擋像素和錯誤匹配的像素,現(xiàn)在分情況進行插值。
首先對于錯誤像素,我們尋找16個方向上的最相似的正確匹配的像素。
接下來,如果當(dāng)前像素在3.4.1節(jié)中被劃分為了遮擋像素,那么就從這些正確像素中挑選最小的視差,用于填充當(dāng)前像素的視差值,也就是說假設(shè)遮擋像素屬于背景。
而如果當(dāng)前像素是錯誤匹配的像素,那么就從這些正確點中挑選與當(dāng)前像素顏色維度最相似的那一個,用其視差填充當(dāng)前像素。
現(xiàn)在再來看看結(jié)果,很明顯大量的錯誤像素被成功插值了。不過也可以看到,部分遮擋像素還是未填充視差值,這是因為在其16個方向都找不到滿足條件的正確像素,這里主要是因為用1個參數(shù)限制了在一個方向上的最大搜索像素。如果增加這個參數(shù)的值,應(yīng)該可以使得更多的像素得到填充。

3.4.4 修正邊緣處的視差值
考慮到物體邊緣的視差值不穩(wěn)定,容易出錯,因此作者還加入了一個步驟,對邊緣處的視差值進行微調(diào)。具體來說,先檢測到所有的邊緣,接著對邊緣上的像素p,我們判斷其在邊緣兩側(cè)的兩個相鄰像素p1或p2的代價是否小于p點的代價。如果確實如此,那么就用p1和p2中代價最小的那個像素的視差值來替換p點的視差值。 不過對于當(dāng)前這對圖像,似乎邊緣調(diào)整帶來的變化很小,肉眼幾乎分不出來。當(dāng)然,這是可以理解的,因為這只是“微調(diào)”

3.4.5 亞像素增強和濾波
調(diào)整完邊緣后,作者采用了我在文章73. 三維重建8-立體匹配4,利用視差后處理完善結(jié)果中提到的亞像素增強,將整數(shù)型的視差值插值為了浮點數(shù)型的視差值
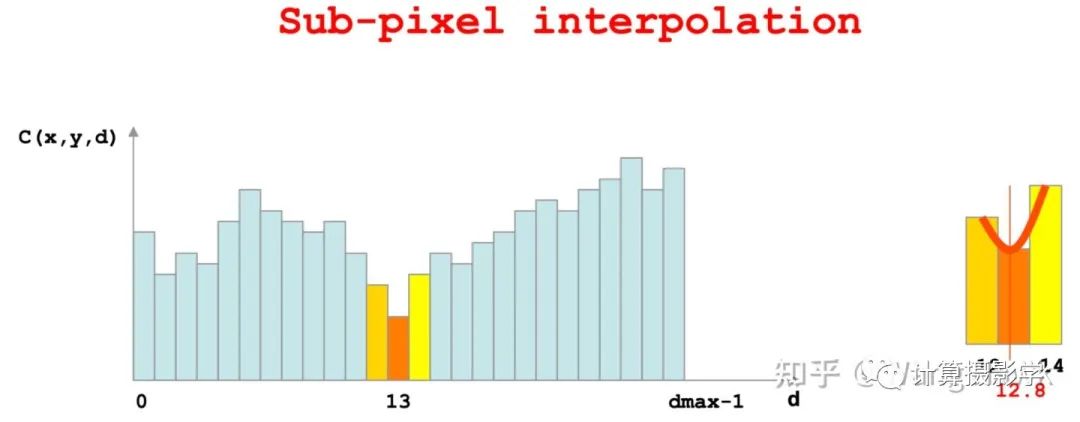
然后,對最后的視差圖做了1個3x3的中值濾波,去除微小的噪聲,這就得到了最終的視差圖:

我把整個過程做成一個視頻,可以看得更清楚些:
四. 算法討論
正如我在文章開篇所說,我挺喜歡ADCensus這個算法的。因為它是由一個又一個非常容易理解的子部件組合而成的。這種結(jié)構(gòu)也使得實現(xiàn)起來很容易,而且還可以根據(jù)工程需要刪除或者替換其中的子部件。 比如,在文章開篇我們看到的OAK Camera的流程,通過官方的流程圖可以看出跟原版ADCensus很相似,用了Census特征,掃描線優(yōu)化,左右一致性檢測后的插值,還增加了更多的濾波器。似乎裁減掉了區(qū)域投票、邊緣調(diào)整等步驟:
從效果上看,OAK Camera僅通過單通道的雙目圖像,就已經(jīng)能實時得到不錯的結(jié)果,這進一步證明了類ADCensus算法的有效性:


而且,作者還專門闡釋了在硬件上優(yōu)化實現(xiàn)的方案,包括代價計算,代價聚合,掃描線優(yōu)化等在內(nèi)的步驟都可以用硬件來并行計算。在作者的論文中,通過硬件加速,算法執(zhí)行速度提升了最高140倍!OAK Camera應(yīng)該也是借鑒了其中的思想,所以能實時計算得到視差圖。 然而,硬幣總有兩面,由多個子部件來構(gòu)成一個完整的算法管線,也會帶來新的問題。由于每個部件都有自己的參數(shù),這就導(dǎo)致要將算法調(diào)整到最佳狀態(tài)非常困難,因為參數(shù)數(shù)量太多了,而且各個部件之間有強相關(guān)關(guān)系,調(diào)整前一個步驟的參數(shù),可能會影響到后一個步驟,這就使得調(diào)整參數(shù)更加復(fù)雜。而且,在不同的數(shù)據(jù)集上,參數(shù)的值顯然不相同,所以導(dǎo)致這個算法的泛化性很成問題。 前面的開源實現(xiàn)https://github.com/DLuensch/StereoVision-ADCensus, 里面,就定義了眾多參數(shù):
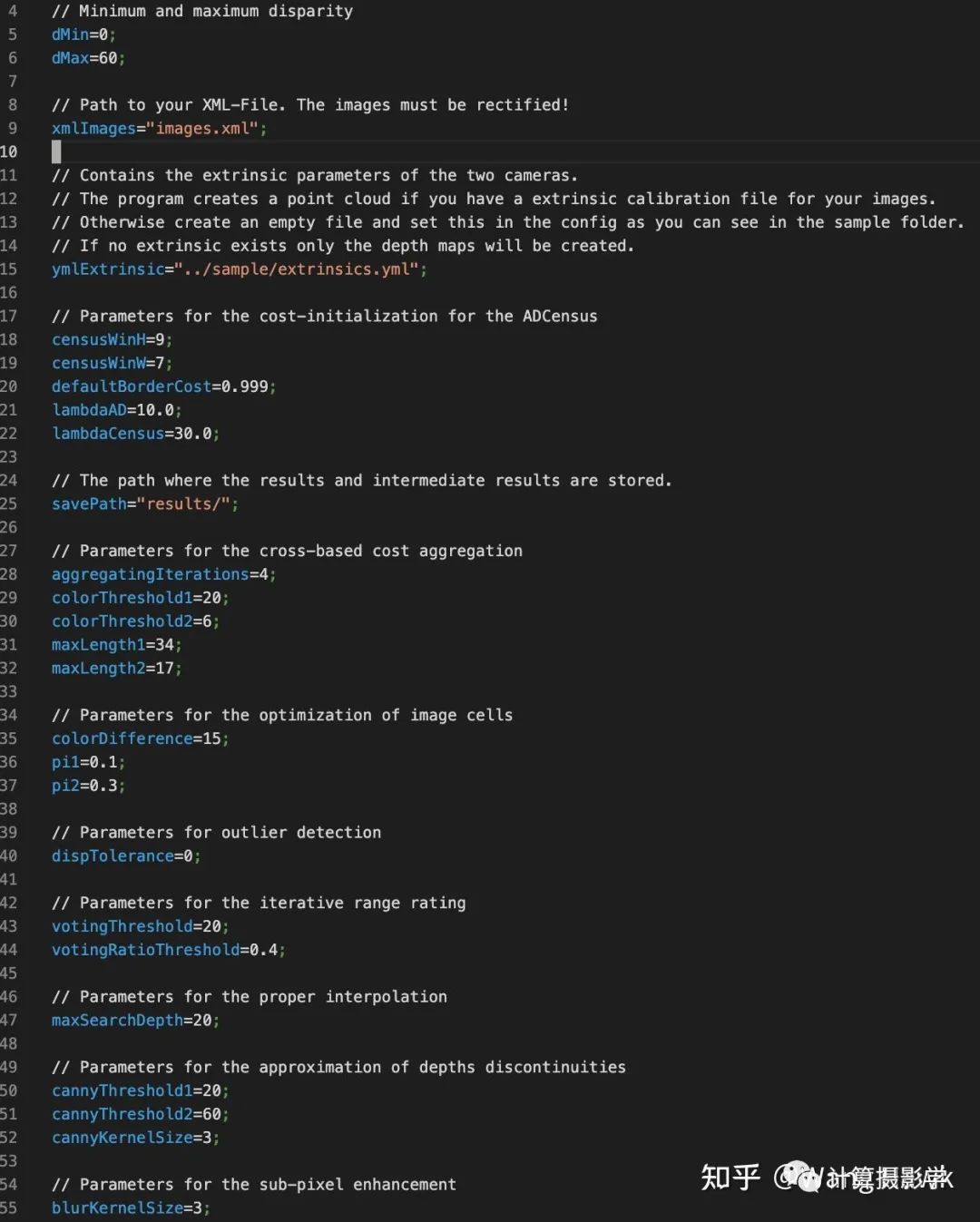
前面我們Sunny妹的圖片,采用MiddleBurry數(shù)據(jù)集上調(diào)出的默認參數(shù)時就存在很多區(qū)域的錯誤。很顯然,此時應(yīng)該在這種場景下對參數(shù)進行精調(diào)才行。
比如在OAK-Camera上調(diào)整參數(shù)后,可以得到這個結(jié)果,明顯的錯誤像素少了許多:

用多個子部件組成算法管線,還存在性能優(yōu)化的問題。因為你不得不優(yōu)化每一個部件的性能,才能得到一個高性能的算法——這對立體匹配通常非常重要。
五. 總結(jié)
今天,我為你介紹了一個經(jīng)典的立體匹配算法ADCensus,其流程非常規(guī)整。它很容易理解,很容易實現(xiàn),并且被許多知名的硬件設(shè)備所借鑒,比如OpenCV官方推出的OAK Camera,以及Intel Realsense。 它的作者是一群中國學(xué)者,嗯,好感度++ 它遵循的范式是用一堆容易理解的子模塊構(gòu)成整個算法,似乎咱普通人也能想得到這種思想:
ADCensus算法也有自己的缺點:參數(shù)眾多、難以調(diào)整、泛化性不夠高。模塊眾多,優(yōu)化復(fù)雜,很吃經(jīng)驗。 那么,有沒有更好的方式呢?這也是我后面的文章中會講述的,讓我們拭目以待吧。
六. 參考資料
1.X. Mei etc.,On building an accurate stereo matching system on graphics hardware2.OAK-Camera:https://store.opencv.ai/products/oak-d3.Leonid Keselman etc.Intel RealSense Stereoscopic Depth Cameras4.開源實現(xiàn):https://github.com/DLuensch/StereoVision-ADCensus
審核編輯 :李倩
-
模塊
+關(guān)注
關(guān)注
7文章
2695瀏覽量
47433 -
算法
+關(guān)注
關(guān)注
23文章
4608瀏覽量
92844 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24690
原文標題:立體匹配經(jīng)典算法:ADCensus
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
請問PCM4220數(shù)據(jù)手冊中給的群延時時間和數(shù)字濾波器延時時間是同一個概念嗎?
圖像識別算法的測試方法有哪些
PyTorch如何訓(xùn)練自己的數(shù)據(jù)集
機器學(xué)習(xí)的經(jīng)典算法與應(yīng)用

請問NanoEdge AI數(shù)據(jù)集該如何構(gòu)建?
振弦采集儀在巖土工程監(jiān)測中的性能評價及標準選擇

大數(shù)據(jù)時代的數(shù)據(jù)保護:分布式存儲系統(tǒng)的七大原則
評價放大電路的主要性能指標有哪些
arcgis空間參考與數(shù)據(jù)框不匹配如何解決
傳感器性能評價指標有哪些
基于NID-SLAM對神經(jīng)SLAM在動態(tài)環(huán)境下的性能提升

關(guān)于ADXL345加速度傳感器幾個指標的疑問
labview怎么記錄時間和數(shù)據(jù)
STM32控制中常見的PID算法總結(jié)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論