 Vision Transformers比基于CNN的模型更具有潛力
Vision Transformers比基于CNN的模型更具有潛力
Vision Transformer (ViT)自發布以來獲得了巨大的人氣,并顯示出了比基于CNN的模型(如ResNet)更大的潛力。但是為什么Vision Transformer比CNN的模型更好呢?最近發表的一篇文章“Do Vision Transformers See Like Convolutional Neural Networks?”指出,ViT的優勢來自以下幾個方面:
ViT不同層的特征更加均勻,而CNN模型不同層的特征呈網格狀
ViT的低層的注意力包含全局信息,而CNN的性質在低層只關注局部
在ViT的較高層中,跳躍連接在信息傳播中發揮突出作用,而ResNet/CNN跳躍連接在較高層中傳遞的信息較少
此外,數據的規模和全局平均池化的使用都會對ViT的表示產生很大的影響。
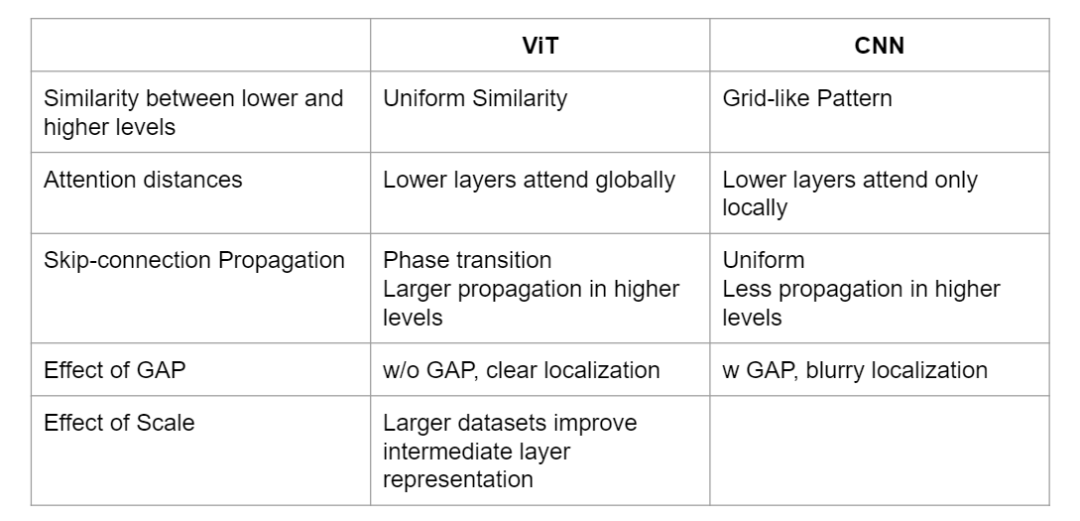
ViT和CNN的主要區別
首先,讓我們看看下面的兩個架構,ViT和一個典型的CNN模型ResNet50。ResNet50接收整個狗圖像,并進行2D卷積,內核大小為7×7,用殘差塊疊加50層,最后附加一個全局平均池化和一個dense層,將圖像分類為“狗”。ViT首先將狗圖像分解為16*16個patch,將每個patch視為一個“token”,然后將整個token序列送入transformer編碼器,該編碼器由多頭自注意力塊組成,編碼器特征隨后被發送到MLP層,用于分類“狗”類。
上: ResNet50; 下: ViT
對于兩個長度不同的特征向量,很難衡量它們的相似性。因此,作者提出了一種特殊的度量,中心核對齊(CKA),整個論文中都在使用這個。假設X和Y是m個不同樣本的特征矩陣,K=XX^T^, L=YY^T^,則利用Hilbert-Schmidt獨立準則(HSIC)的定義,定義CKA如下:
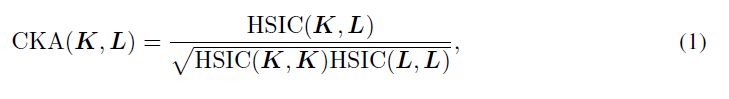
X和Y越相似,CKA值越高。更多的定義細節可以在論文的第3節中找到。
有了CKA的定義,一個自然的問題出現了:ViT和CNN的不同層的特征有多相似?作者表明,模式是相當不同的, ViT在所有層上有一個更統一的特征表示,而CNN/ResNet50在較低和較高的層上有一個網格狀的模式。這意味著ResNet50在它的低層和高層之間學習不同的信息。
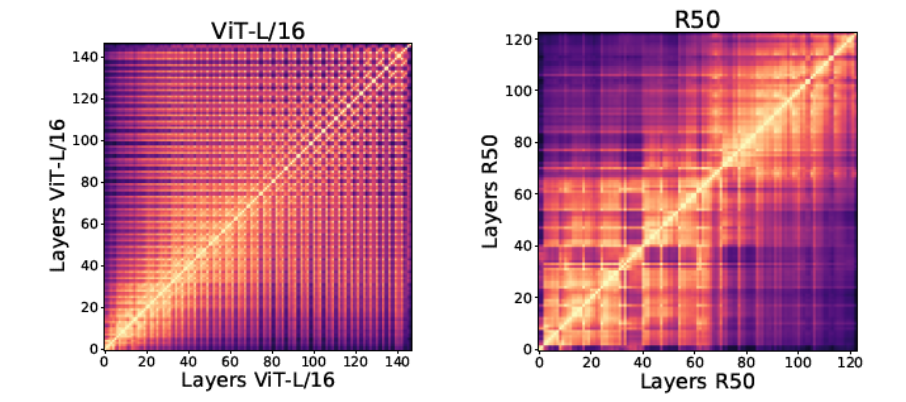
左:ViT各層特征對之間的CKA值,右:ResNet50所有層的特性對之間的CKA值。
但是ResNet在其較低層次和較高層次學習的“不同信息”是什么呢?我們知道對于CNN模型,由于卷積核的性質,在較低的層只學習局部信息,在較高的層學習全局信息。所以在不同的層之間有一個網格狀的模式就不足為奇了。那么我們不禁要問,ViT怎么??ViT是否也在其底層學習局部信息?
如果我們進一步觀察自注意力頭,我們知道每個token會關注所有其他token。每個被關注的token都是一個查詢patch,并被分配一個注意力權重。由于兩個“token”代表兩個圖像patch,我們可以計算它們之間的像素距離。通過將像素距離和注意力權重相乘,定義了一個“注意力距離”。較大的注意力距離意味著大多數“遠處的patch”具有較大的注意權重——換句話說,大多數注意力是“全局的”。相反,小的注意距離意味著注意力是局部的。
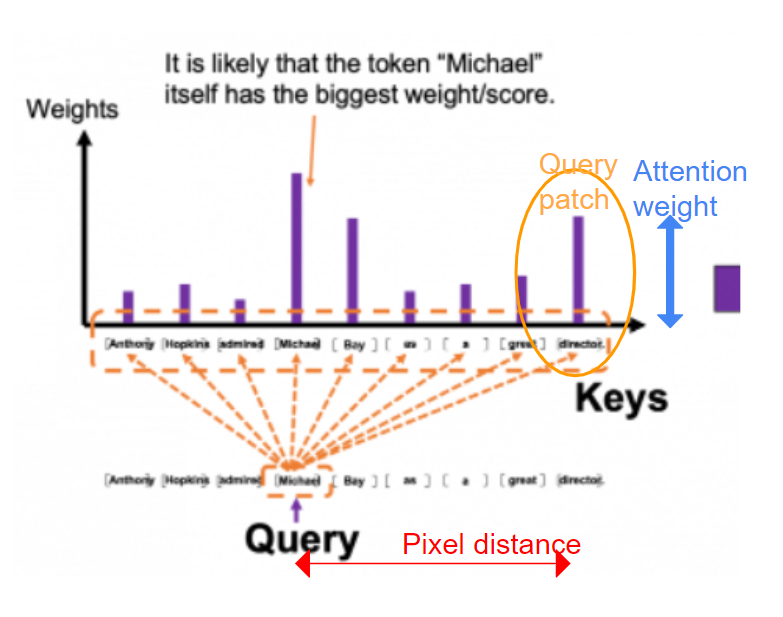
注意力距離的計算
作者進一步研究了ViT中的注意力距離。從下面的結果中,我們可以看到,雖然從較高層(block 22/23,紅色高亮顯示)的注意力距離主要包含全局信息,但是,即使是較低層(block 0/1,紅色高亮顯示)仍然包含全局信息。這和CNN的模型完全不同。
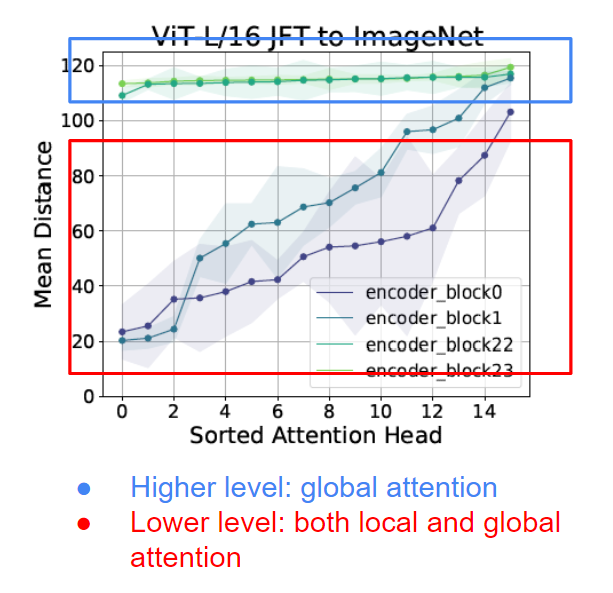
現在我們知道ViT甚至在它的底層也學習全局表示,下一個要問的問題是,這些全局表示會忠實地傳播到它的上層嗎?如果是這樣,是怎么實現的?
作者認為關鍵是ViT的跳躍連接。對于每個block,在自注意力頭和MLP頭上都存在跳躍連接。通過將跳躍連接的特征的范數除以通過長分支的特征的范數,作者進一步定義了一個度量:歸一化比率(Ratio of norm, RoN)。他們發現了驚人的相變現象,在較低的層次上,分類(CLS)token的RoN值很高,而在較高的層次上則低得多。這種模式與空間token相反,其中RoN在較低的層中較低。
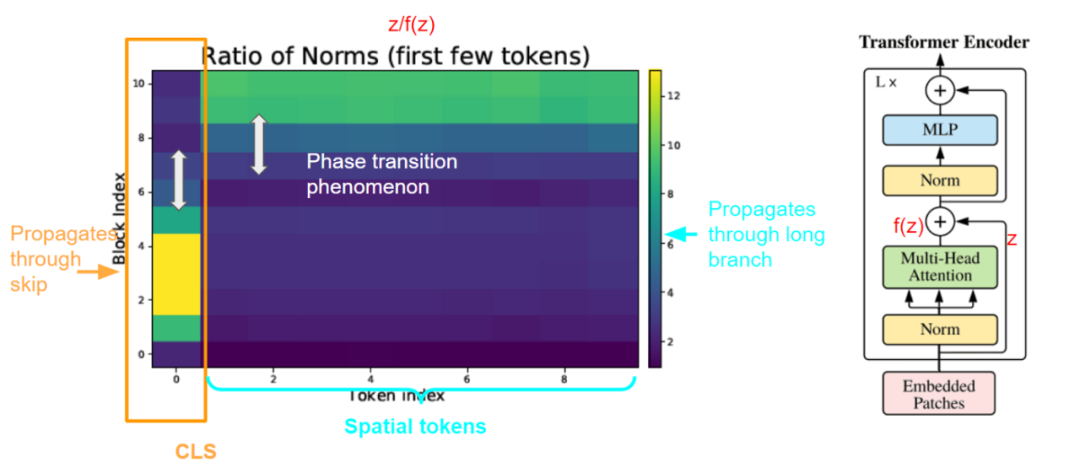
歸一化比率:|z|/|f(z)|。其中z是通過跳躍連接的特特征。F (z)是經過長分支的特征。
如果他們進一步刪除ViT不同層的跳躍連接,那么CKA映射將如下所示。這意味著跳躍連接是使ViT不同層之間的信息流成為可能的主要(如果不是全部的話)機制之一。
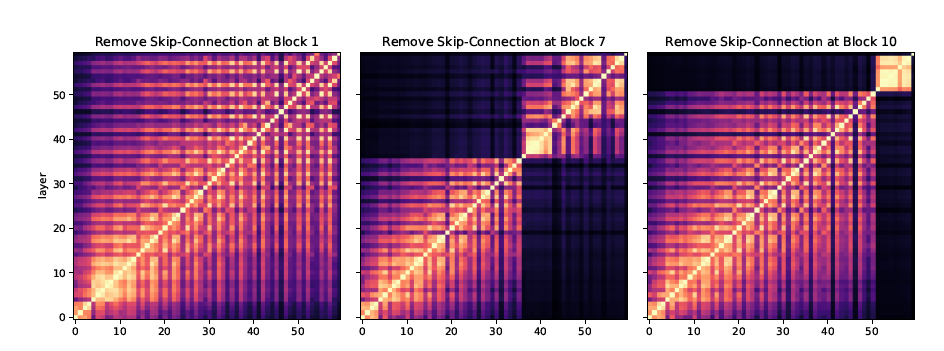
除了強大的跳躍連接機制和在較低層次學習全局特征的能力外,作者還進一步研究了ViT在較高層次學習精確位置表示的能力。這種行為與ResNet非常不同,因為全局平均池化可能會模糊位置信息。
此外,作者指出,有限的數據集可能會阻礙ViT在較低層次學習局部表示的能力。相反,更大的數據集特別有助于ViT學習高質量的中間層表示。
-
編碼器
+關注
關注
45文章
3638瀏覽量
134428 -
模型
+關注
關注
1文章
3226瀏覽量
48809 -
cnn
+關注
關注
3文章
352瀏覽量
22203
原文標題:Vision Transformers看到的東西是和卷積神經網絡一樣的嗎?
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于數字CNN與生物視覺的仿生眼設計
Github開源的數字手勢識別CNN模型簡析
如何將DS_CNN_S.pb轉換為ds_cnn_s.tflite?
為什么三相電機比單相電機更具優勢?
在線研討會 | 釋放 Vision Transformers、NVIDIA TAO 和最新一代 NVIDIA GPU 的潛力

2D Transformer 可以幫助3D表示學習嗎?
cnn卷積神經網絡模型 卷積神經網絡預測模型 生成卷積神經網絡模型
cnn卷積神經網絡算法 cnn卷積神經網絡模型
Transformers的功能概述





 工商網監
工商網監
評論