 基于OpenAI的GPT-2的語言模型ProtGPT2可生成新的蛋白質序列
基于OpenAI的GPT-2的語言模型ProtGPT2可生成新的蛋白質序列
人類語言與蛋白質有很多共同點,至少在計算建模方面。這使得研究團隊將自然語言處理(NLP)的新方法應用于蛋白質設計。其中,德國Bayreuth大學Birte H?cker的蛋白質設計實驗室,描述了基于OpenAI的GPT-2的語言模型ProtGPT2,以基于自然序列的原理生成新的蛋白質序列。
正如字母表中的字母組成單詞和句子一樣,天然氨基酸以不同的方式結合形成蛋白質。和自然語言一樣,蛋白質序列以極高的效率將結構和功能存儲在氨基酸序列中。
ProtGPT2是一個深度的、無監督的模型,它利用了變壓器架構的進步,而變壓器架構也導致了NLP技術的快速發展。該體系結構有兩個模塊,Noelia Ferruz解釋說,她是論文的合著者,也是培訓ProtGPT2的人:一個模塊理解輸入文本,另一個模塊處理或生成新文本。第二個是生成新文本的解碼器模塊,幫助了ProtGPT2的開發。
Researchers have used GPT-2 to train a model to learn the protein “language,” generate stable proteins, and explore “dark” regions of protein space.
“在我們創建這個模型的時候,還有許多其他人在使用第一個模塊,”Noelia Ferruz說,“例如ESM、ProtTrans和ProteinBERT。我們的是當時第一個公開發布的解碼器,這也是第一次有人直接應用GPT-2。”
Ferruz本人是GPT-2的忠實粉絲。“我發現有一個能寫英語的模型給我留下了深刻印象,”她說。這是一個著名的transformer模型,以無監督的方式對40千兆字節的英語互聯網文本進行預訓練,即使用沒有人類標記的原始文本生成句子中的下一個單詞。GPT-x系列已被證明能夠有效地生成長而連貫的文本,通常與人類書寫的文本無法區分,因此潛在的誤用是一個令人擔憂的問題。
鑒于GPT-2的能力,Bayreuth的研究人員對使用它訓練模型學習蛋白質語言、生成穩定的蛋白質以及探索蛋白質空間的“暗”區域持樂觀態度。Ferruz在整個蛋白質空間中約5000萬個無注釋序列的數據集上訓練了ProtGPT2。為了評估該模型,研究人員將由ProtGPT2生成的10000個序列的數據集與來自訓練數據集的10000個隨機序列集進行了比較。
他們發現該模型預測的序列在二級結構上與天然蛋白質相似。ProtGPT2可以預測穩定和功能性的蛋白質,不過,Ferruz說,這將在未來幾個月內通過對一組大約30種蛋白質的實驗室實驗來驗證。ProtGPT2還模擬了自然界中不存在的蛋白質,在蛋白質設計領域開辟了可能性。
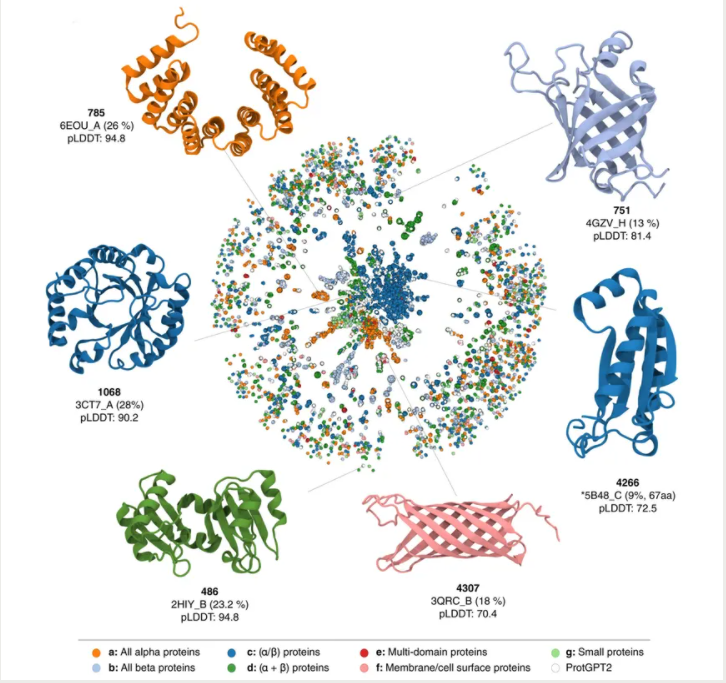
UNIVERSITY OF BAYREUTH/NATURE COMMUNICATIONS
Ferruz說,該模型可以在幾分鐘內產生數百萬種蛋白質。“如果沒有進一步的改進,人們可以采用免費提供的模型,并對一組序列進行微調,以在該區域產生更多的序列,例如抗生素或疫苗。”但是,她補充說,通過對訓練過程進行小的修改,“我們可以添加標簽,并有可能在未來開始生成具有特定功能的序列。”這反過來不僅在醫療和生物醫學領域,而且在環境科學等領域有潛在的應用。
Ferruz承認NLP領域的快速發展為ProtGPT2的成功做出了貢獻,但同時也指出,這是一個不斷變化的領域 —— “過去12個月發生的所有事情都太瘋狂了。”目前,她和她的同事已經在寫一篇關于他們工作的評論。“我在2021圣誕節訓練了這個模型,”她說,“當時,有另一個模型已經被描述過了……但它不可用。”不過她表示,到今年春天,其他模型已經發布。
ProtGPT2的預測序列跨越了新的、很少探索的蛋白質結構和功能區域。然而,幾周前,DeepMind發布了超過2億種蛋白質的結構。“所以我想我們已經沒有那么多的暗蛋白質組了,”Ferruz說,“但仍有一些地區……尚未被探索。”
不過,前面還有很多準備工作要做。“我想控制設計過程,”Ferruz補充道,“我們將需要獲取序列,預測結構,并可能預測功能(如果有的話)……這將是非常具有挑戰性的。”ProtGPT2是面向高效蛋白質設計和生成邁出的一大步,為探索設計蛋白質結構和功能的參數及其后續實際應用的實驗研究奠定了基礎。
-
解碼器
+關注
關注
9文章
1143瀏覽量
40718 -
語言模型
+關注
關注
0文章
520瀏覽量
10268 -
nlp
+關注
關注
1文章
488瀏覽量
22033 -
OpenAI
+關注
關注
9文章
1079瀏覽量
6481
原文標題:研究人員開發用于蛋白質設計的深度無監督語言模型ProtGPT2
文章出處:【微信號:IEEE_China,微信公眾號:IEEE電氣電子工程師】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
以色列面向生物傳感器和電路的蛋白質納米線
面向生物傳感器和電路的蛋白質納米線
蛋白質組學技術與藥物作用新靶點研究進展 精選資料分享
點成分享 | 蛋白質濃度測定之BCA法
基于PPI網絡與機器學習的蛋白質功能預測方法
OpenAI發布一款令人印象深刻的語言模型GPT-2
OpenAI宣布,發布了7.74億參數GPT-2語言模型
基于衰減系數的動態蛋白質預測網絡模型
食品蛋白質測定儀的特點及功能
蛋白質測定儀的特點、功能及參數
蛋白質快速檢測儀的特點及功能
蛋白質測定儀工作原理是怎樣的
使用AlphaFold2進行蛋白質結構預測





 工商網監
工商網監
評論