


2. 介紹
參考一篇綜述,首先介紹兩個概念:
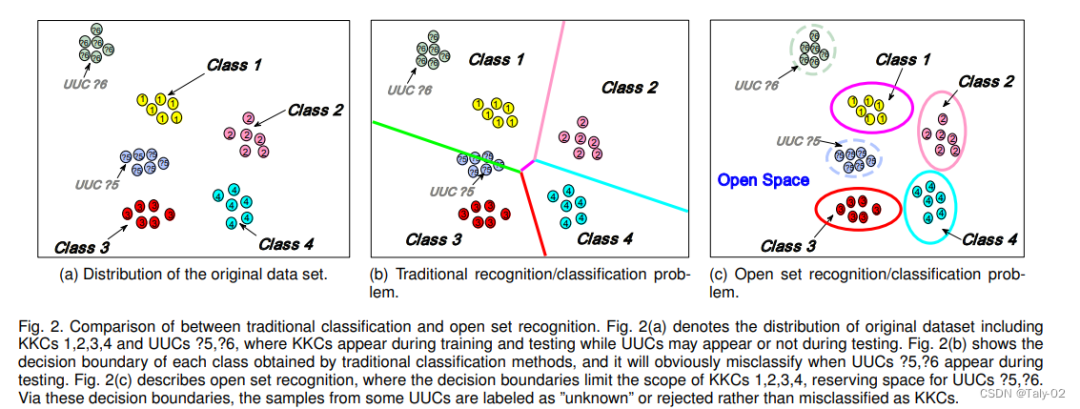
Close Set Recognition,閉集識別:指 訓練集中的類別和測試集中的類別是一致的,例如最常用最經典的ImageNet-1k。所有在測試集中的圖像的類別都在訓練集中出現過,沒有未知種類的圖像。從AlexNet到VGG,再到ResNet,以及最近大火的Visual Transformer,都能夠比較好的處理這一類別的任務。
Open Set Recognition,開集識別:指對一個在訓練集上訓練好的模型,當利用一個測試集(該測試集的中包含訓練集中沒有的類別)進行測試時,如果輸入已知類別數據,輸出具體的類別,如果輸入的是未知類別的數據,則進行合適的處理(識別為unknown或者out-of-distribution)。例如在利用一個數據集訓練好了一個模型可以對狗和人進行分類,而輸入一張狗的圖像,由于softmax這種方式的設定,模型可能會告訴你80%的概率為人,但顯然這是不合理的,限制了模型泛化性能提升。而我們想要的結果,是當輸入不為貓和人的圖像(比如狗)時,模型輸出為未知類別,輸入人或貓圖像,模型輸出對應具體的類別。
由于現實場景中更多的是開放和非靜態的環境,所以在模型部署中,經常會出現一些沒有見過的情況,所以這種考慮開集檢測的因素,對模型的部署十分有必要。那么模型在Close set和在Open set的表現是否存在一定的相關性呢?下面我們來了解一份ICLR 2021的工作來嘗試理解和探索兩者之間的關系。
在本文中,作者重新評估一些open set識別的方法,通過探索是否訓練良好的閉集的分類器通過分析baseline的數據集,可以像最近的算法一樣執行。要做到這一點,我們首先研究了分類器的閉集和開集性能之間的關系。
雖然人們可能期望更強的close set分類器過度擬合到train set出現的類別,因此在OSR中表現較差。其實最簡單的方法也非常直觀,就是‘maximum softmax probability (MSP) baseline,即經過softmax輸出的最大的概率值。而該論文展示了在close set和open set上開放集的表現是高度相關的,這一點是非常關鍵的。而且展這種趨勢在不同的數據集、目標以及模型架構中都是成立的。并在ImageNet-1k這個量級上的數據集進行評估,更能說明該方法的有效性。
但僅僅觀察到這種現象,這種contribution雖然有意義,但可能也不足以支撐一篇頂會oral,所以自然要基于這一現象展開一些方法上的設計,來提升開集檢測的表現。根據這一觀察,論文提出一種通過改善close set性能的方式來進一步提升open set上的表現。
具體來說,我們引入了更多的增強、更好的學習率調度和標簽平滑等策略,這些策略顯著提高了MSP基線的close set和open set性能。我們還建議使用maximum logit score(MLS),而不是MSP來作為開放集指標。通過這些調整,可以在不改變模型結構的情況下,非常有效的提升模型open set狀態下的識別性能。
3. 方法
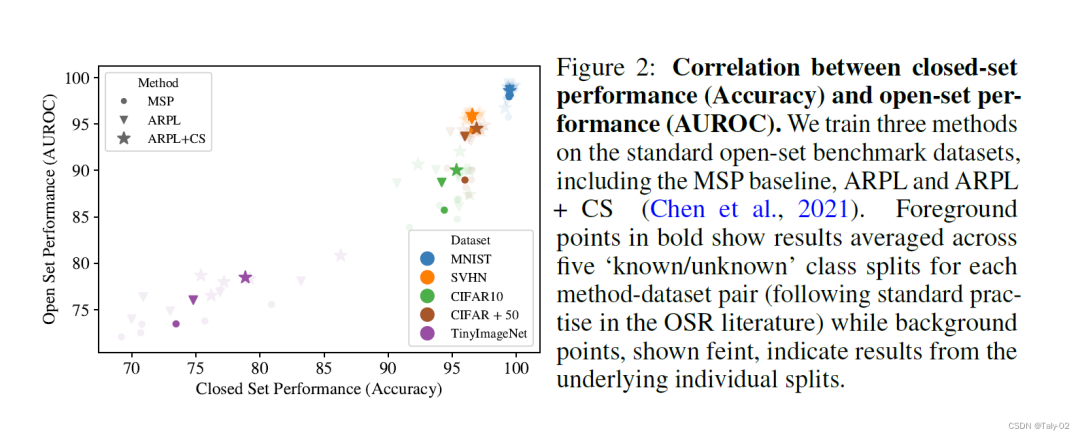
首先就是一張非常直觀的圖,在不用的數據集上,對OSR和CSR兩個任務的表現進行比較。論文首先利用標準基準數據集上,選取三種有代表性的開放集識別方法,包括MSP,ARPL以及ARPL+CS。然后利用一個類似于VGG形態的的輕量級模型,在不同的分類數據集上進行檢測。可以看到OSR和CSR兩個任務的表現是呈現出高度的正相關的。
對于理論上的證明,論文選取了模型校準的角度來解讀。直觀地說,模型校準的目的是量化模型是否具有感知對象類別的能力,即是否可以把低置信度的預測與高錯誤率相關聯。也就是說如果給了很低的置信度,而錯誤率又是很高的,那么就可以定義為模型沒有被很好地校準。反之,則說明模型被很好地校準了。
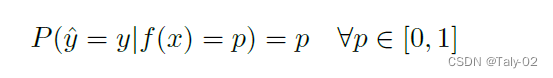
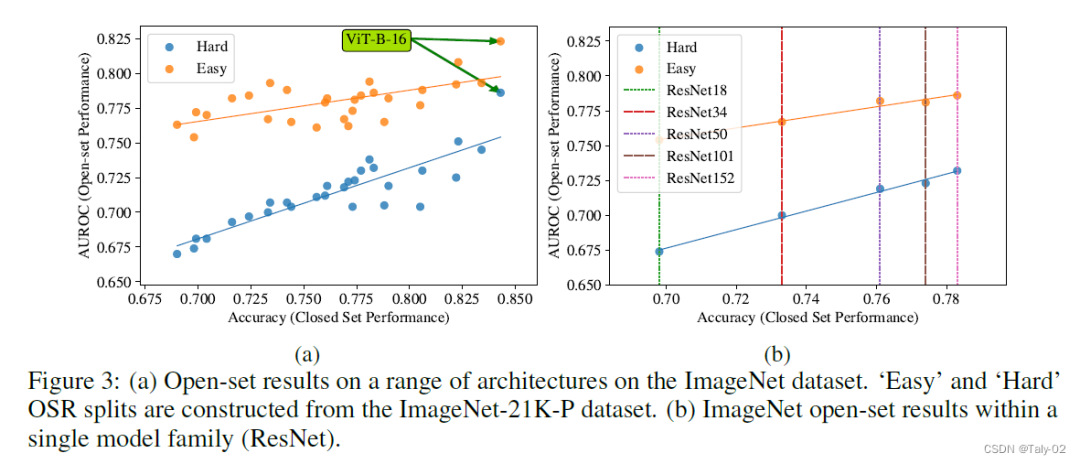
到目前為止,論文已經證明了在單一、輕量級架構和小規模數據集上封閉集和開放集性能之間的相關性——盡管我們強調它們是OSR文獻中現有的標準基準。如上圖,論文又在在大規模數據集(ImageNet-1k)上試驗了一系列架構。和在CIFAR-10等小數據集一致,該數據集也存在上述的現象。
至于,獲得更好的open set recognition上的表現,也就非常直接了。就是通過各種優化方式、訓練策略的設計,讓模型可以能夠在close set上具有更好的性能。完整的細節和用于提高封閉集性能的方法的表格明細可以在論文,以及附錄中更好地了解。
論文還提出一種新的評估close set性能的方式。以前的工作指出,開放集的例子往往比封閉集的例子具有更低的norm。因此,我們建議在開放集評分規則中使用最大對數,而不是softmax概率。Logits是深度分類器中最后一個線性層的原始輸出,而softmax操作涉及到一個歸一化,從而使輸出可以被解釋為一個概率向量的和為1。由于softmax操作將logits中存在的大部分特征幅度信息歸一化,作者發現logits能帶來更好的開放集檢測結果。
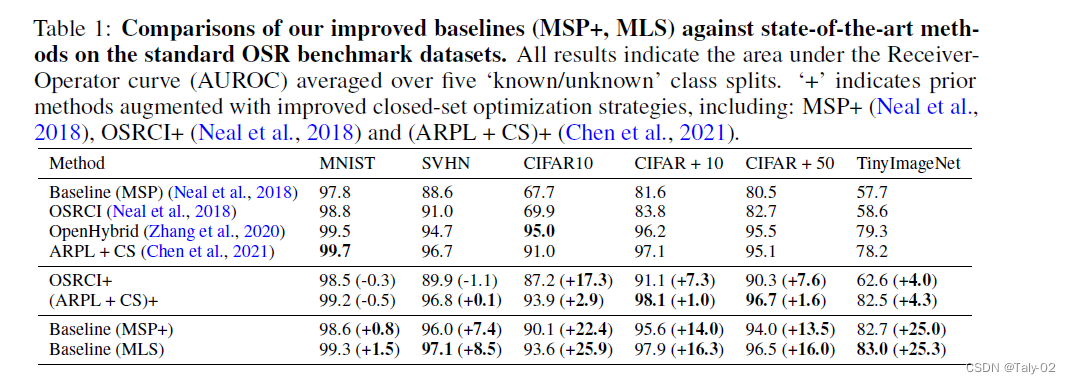
這種新的方式,改善了在所有數據集上的性能,并大大縮小了與最先進方法的差距,各數據集的AUROC平均絕對值增加了13.9%。如果以報告的baseline和當前最先進的方法之間的差異比例來計算,這意味著平均差異減少了87.2%。MLS方法還在TinyImageNet上取得了新的領先優勢,比OpenHybrid高出3.3%。
另外,作者指出,目前的標準OSRbaseline評價方式有兩個缺點:
它們都只涉及小規模的數據集;
它們缺乏對構成 "語義類 "的明確定義。
后者對于將開放集領域與其他研究問題,如out-of-distribution以及outlier的檢測,進行區分非常重要。OSR旨在識別測試圖像是否與訓練類有語義上的不同,而不是諸如模型對其預測不確定或是否出現了低層次的distribution shift。所以作者基于這兩個缺點,提出來了新的baseline用于評估open set的性能。具體關于數據集的細節,可以參考原文
4. 結論
在這篇文章中,作者給出了模型的閉集準確率與開集識別能力正相關的觀點,同時通過實驗驗證了加強模型的閉集性能能夠幫助我們獲得更強的開集能力。對于 Open-Set Recognition 具有啟發意義。
審核編輯:劉清
-
msp
+關注
關注
0文章
164瀏覽量
35788 -
分類器
+關注
關注
0文章
153瀏覽量
13482
發布評論請先 登錄
請問WICED CYW20735B1是否支持發送hci命令 set connection encryption?
大模型在半導體行業的應用可行性分析
WPP Media發布業內首個「大營銷模型」Open Intelligence





 工商網監
工商網監

評論