 淺談一下對未來的CAM發展或者是未來可解釋深度模型的發展
淺談一下對未來的CAM發展或者是未來可解釋深度模型的發展
導讀
本文從CVPR2022中三篇不同領域的文章中CAM的表現出發,淺談一下對未來的CAM發展或者是未來可解釋深度模型的發展。
卷首語

這個問題起源于我的對于現階段CAM解釋網絡特征變化的未來發展的一些不確定。我自己在20年開始寫文章就沉迷上使用了CAM去解釋自己的添加的網絡結構模塊了。我對于CAM的接觸時間還蠻長的,從開始的熱戀期到現在的倦怠期,我越來越不覺得CAM的圖能給我帶來眼前一亮的感覺了。加上現在一些文章的濫用,在一堆圖片中選擇出效果最好的幾張進行所謂的CAM的解釋,這樣的工作會逐漸讓我覺得這個東西的無用和雞肋。
所以今晚就想和大家聊聊,在CVPR2022中三篇不同領域的文章中CAM的表現,對未來的CAM發展或者是未來可解釋深度模型的發展希望得到一些啟發!
先簡單快速的回顧一遍CAM
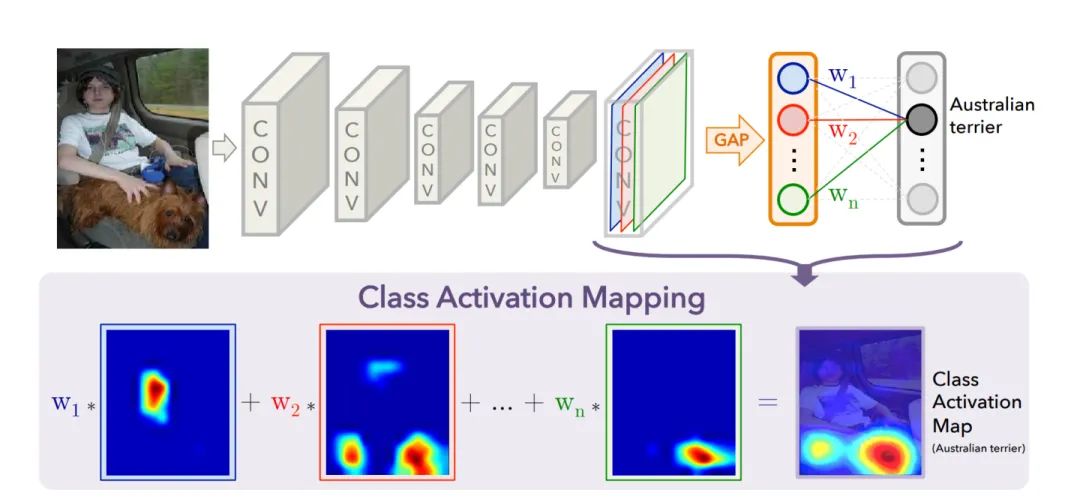
首先CAM是什么?
CAM全稱Class Activation Mapping,既類別激活映射圖,也被稱為類熱力圖、顯著性圖等。我們可以簡單的理解為是圖像中信息對于預測結果的貢獻排名,分數越高(顏色越熱)的地方表示在輸入圖片中這塊區域對網絡的響應越高、貢獻越大,也就是吸引網絡注意力的地方!
如何生成CAM
CNN的操作可以看做是濾波器對圖片進行特征提取,我們可以大膽直接的得出結論,被一層層卷積核提取后,基本就是卷積核判斷是重要的信息,其值越大,特征越明顯,得到卷積的關注度就越高。
一個深層的卷積神經網絡,通過層層卷積操作,提取出語義信息和空間信息,我們一直都很希望可以打破深度神經網絡的黑盒,可以溯源特征提取的過程,甚至可以知道特征所代表的語義內容, 通常每一層的特征圖還會有很多的層,我們一般用channel表示,這些不同層(通道)特征圖,我們可以認為理解為存放著卷積提取到不同的特征。隨著卷積的逐層深入,該特征已經失去了原有的空間信息和特征信息,被進一步的集成壓縮為具有高度抽象性的特征圖。這些特征圖所代表的語義信息我們不得而知,但是這些特征圖的重要性我們卻可以通過計算得出。所以我們的CAM主要作用就是根據不同通道的貢獻情況,融合出一張CAM圖,那么我們就可以更直觀的了解到在圖像中那些部分是在CNN中是高響應的重要信息,哪些信息是無關緊要的無聊信息。
CAM獲取的步驟如下:
step1:選擇可視化的特征層,例如尺寸為 16?16?1024 的特征圖
step2:獲取該特征的每個channel的權重,即長度為1024的向量;
step3:通過線性融合的方式,把不同channel的權重賦回原特征圖中,在依次的將各個通道的特征圖線性相加
獲取尺寸為16*16的新特征圖;
step4:對該新特征圖進行歸一化,并通過插值的方式還原到原圖尺寸;
Partial Class Activation Attention for Semantic Segmentation

文章任務背景
場景分割的工作其實大致上可以主要可以分為兩個任務,在局部視野下聚合同一類的像素和在全局視野下區分不同類別的像素。說得簡單,但是在實際場景中,由于紋理、光照和位置的不同,屬于同一類別的像素在特征響應也可能會有很大的差異 ,這樣就會產生像素之間的粘連,邊界區分不明顯的問題。(不同類別內的粘連問題,如下圖e,CAM所展示的效果)。對于這種問題,之前的工作會選擇使用像金字塔、空洞卷積還有自注意力機制這些結構,通過融合不同的感受野下的特征信息,不同的分辨率下的空間信息,以及深度挖掘不同類別下的特征信息,來幫助網絡解決不同物體之間邊界區分,以及同一物體的像素聚合。
為了消除局部上下文方差引起的類內不一致,在原有的基于圖像級分類的局部定位算法基礎上,局部類激活注意(Partial Class Activation Attention, PCAA)算法,該算法將定位任務細分為區域級預測任務,獲得了較好的定位性能。比如我們大致的鎖定物體出現的區域(局部中心位置),然后計算局部中心與其他像素的相關程度再對區域內的物體進行更一步的局部聚合。它同時利用局部和全局的信息進行特征聚合,
本文提出了Partial CAM,它將CAM的功能從整體預測擴展到區域級別的物體預測,并實現了非常不錯的定位性能。到底有多不錯呢?我們可以看看下圖的效果比較,會發現使用了Partial CAM的結構后的整體激活效果會更加的重視目標對象的分割邊緣,在同一物體中激活效果會更加聚集,非同一物體的會激活像素點會更加遠離。
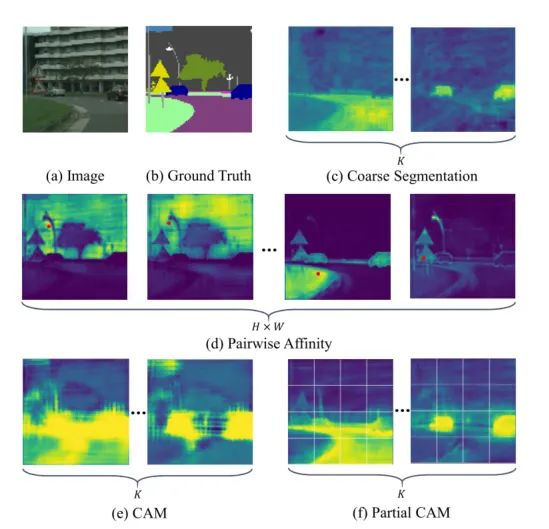
這里是展示的是不同的方法同一場景下的類激活效果
文章的工作內容
文章希望有一種方法可以打破以往的在局部視野下聚合同一類的像素和在全局視野下區分不同類別的像素的建模思路,使用一個局部延申到全局的建模思路,完成場景分割。本文將輸入的圖像分割成不重疊的patch塊,一個patch塊相當于一個小分割區域,通過對這樣的小區域進行像素的激活工作,不斷的堆疊,我們可以從局部逐步的細化整目標的分割精度。具體來說,它首先根據局部CAM收集到的局部信息,并計算每個patch內部像素到類的相似度映射。對于每個類,所有的區域信息會被聚合到一起,聚合在全局中心周邊。PCAA還通過計算區域之間像素之間的方差距離來考慮區域內容上下文的連貫性,更好的區分物體與物體之間的聯系,解決邊界黏連的問題完成分割任務。
一個小提示, 其實因為CAM其實原本設計并不是實現在語義分割任務上的,在空間上信息并關注,所以我們需要一點本土化的改進。這樣文章提出的像素級別特征聚集和激活目前只能使用在語義分割場景中,因為語義分割場景會提供像素級別的GT標注,像目標檢測和分類任務就暫時不能支持了。
我們提出了區域類激活注意(PCAA)。與以往的簡單使用像素特征或全局中心相比,PCAA同時使用局部和全局表示。與傳統的定位算法相比,局部定位算法使網絡學習到更多的空間信息,能夠提供更可靠的定位結果。而且它在有效的保留了全局特性之外,也考慮到了局部特殊性,更加的適配語義分割、圖像超分辨率這類型的需要更加細致的細節信息的像素級別任務。
文章方法的介紹
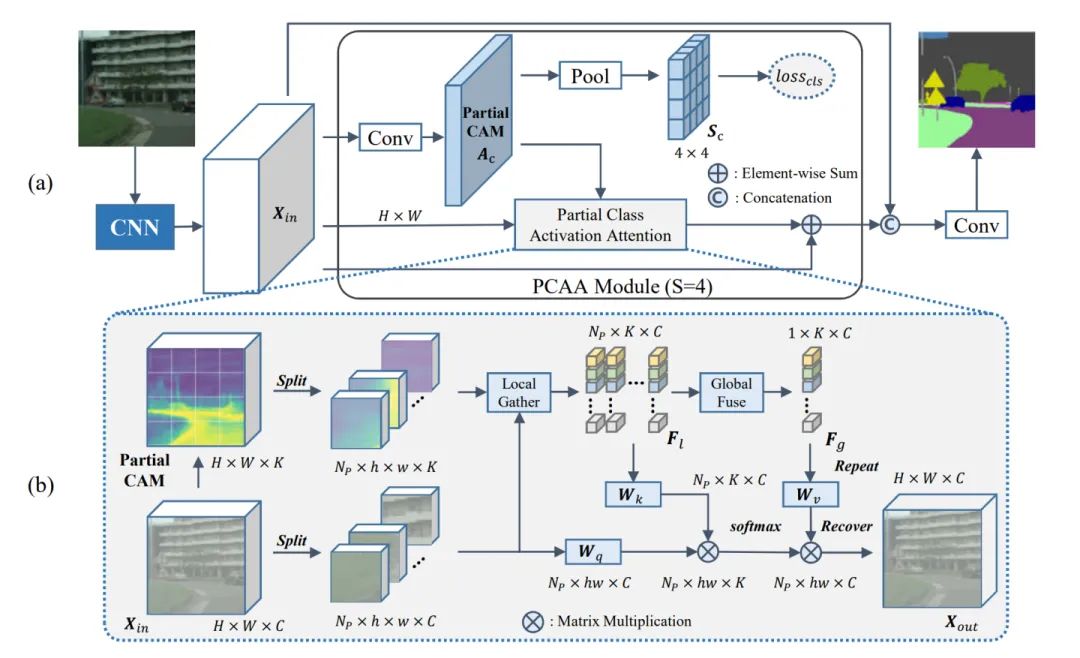
文章的模型設計圖
從模型的結構看,主要可以分為大整體和小局部的兩個模塊
Partial CAM(PCAM)
圖像經過CNN進行特征提取后,得到特征圖xin ,特征經過一個1x1的卷積之后,經過一個SxS的全局平均池化層希望在每個patch的區域中都能生成CAM,區域的面積就是SxS。之后我們將label轉換為獨熱向量,然后我們把轉化為獨熱向量后的Label通過maxpool生成每個patch的標簽。
Sc=Sigmoid(AvgPoolxS×S(Ac))
?Lc=MaxPoolS×S(Lc)
通過這樣的方式就可以讓PCAM的生成的局部激活圖得到有效的監督。與分類級標簽相比,像素級別的標簽對網絡空間信息進行更細粒度的監督,因此,PCAM比普通的CAM具有更精確的定位性能,通過這樣的方式我們就可以得到有效精確的PCAM圖了。
PCAA
PCAA獨特地采用了部分CAM來建模像素關系,在兩步注意力加權計算 (局部和全局) 中利用了不同類型的類中心。與整個圖像相比,屬于同一類的特征在每個部分內的方差往往更小。通過計算不同局部類中心的相似度圖來緩解局部特異性的影響。同時,采用全局表示進行特征聚合,保證了最終輸出的類內一致性。
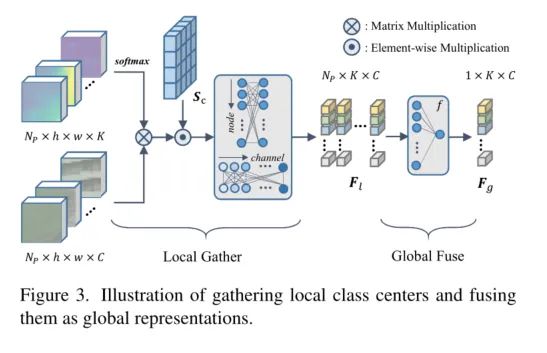
PCAA中具體分為以下幾個結構
我們把得到的特征圖分成大小為SxS的小Patch,我們把PCAM圖用SoftMax轉化為類別概率對各個特征圖進行加權處理
1、Local Class Center
在得到每個部分的精準PCAM圖后,我們把激活圖進行SoftMax的歸一化之后得到一個概率得分,然后將這組概率得分加權到各個patch上,對每組的patch進行整體的激活。之后再利用 Sc 激活每個patch的局部中心點。
Local Class Center
采用圖卷積的單元來建模每個Patch局部中心之間的相互作用以及特征之間的相互聯系,尋找相關連的單元節點,然后將節點們聚合更新出一版新的節點。
2、Global Class Representation
由于局部中心點是在每個區域內計算的,同一類的目標物體表示也有敏感的特征不是一致的(比如部分對顏色敏感,部分對紋路敏感)但是這些特征都是聚合成完整物體不可缺失的特征信息。為了提高整個圖像的類間的特征一致性,我們需要所有區域中心通過加權聚合的方式進行融合,將同一類物體的敏感的特征們進行聚合。
3、Feature Aggregation
我們將local的權重以及global的權重加權到特征圖中進行線性的加權融合得到了最后的特征圖輸出。
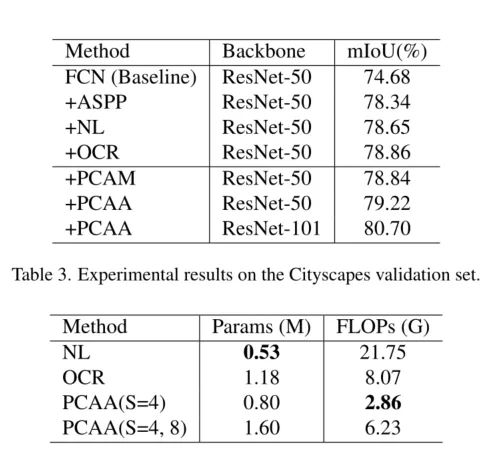
實驗結果
文章的貢獻
1、提出部分類激活映射(Partial Class Activation Map)作為一種表示像素關系的新策略。通過將圖像級分類任務細分為區域級預測,改進了CAM的生成。
2、設計了部分類激活注意(Partial Class Activation Attention)來增強特征表示。它同時考慮了局部特異性和全局一致性。
3、通過大量實驗驗證了所提方法的有效性。具體來說,方法在cityscape上實現了82.3%,在Pascal Context上實現了55.6%,在ADE20K上實現了46.74%。
看完后對于CAM的感受
本文首次探討了利用類激活映射 (Class Activation Map, CAM) 建模像素關系的方法。PCAM是一種可以用于語義分割的具有空間特性的類激活映射建模方法。CAM方法可以從分類模型定位對象。這對于弱監督任務至關重要,但完全會忽略了空間關系。對于一個全監督的分割任務,像素級別的注釋使我們能夠引入空間信息,以更精確地生成CAM。
這次的CAM其實并沒有像以往的工作一樣,只是單純的作為一個可視化的工具,而是挖掘了CAM的作為一個區域指導先驗的這樣一個可能性。通過有效的監督類激活的信息,讓CAM再一次切實的參與到模型的建設當中。我覺得以CAM作為構建一個即插即用的藍本模型,我認為是一個很可行的方向!
C-CAM: Causal CAM for Weakly Supervised Semantic Segmentation on Medical Image

文章任務背景介紹
第二篇文章的故事發生在醫療圖像分割case中。近年來,CAM的弱監督語義分割((Weakly supervised semantic segmentation以下簡稱WSSS)研究成果被提出,用于醫療影像上作品卻不多。現在階段的醫療圖像分割任務中存在著兩個問題,第一個是目標前景和背景的邊界不清晰,第二個是在訓練階段中, 共現的現象非常嚴重。(共現現象是指在訓練階段中同一張圖像中出現不同的器官)共現的主要問題是,同一環境下A器官出現次數比B器官多,可能效果會向A傾斜,對于需要識別出的B,比較難識別出。
我感覺共現這個情況我需要單獨拿出來說一下,再解釋一下
共現,字面意思一樣是共同出現,舉個例子比如說腹部MRI圖像中不同器官總是同時出現,會給AI造成了一定的干擾,可能會把這種共現作為特征信息學習進去了。然而,這種同現現象在自然圖像中并沒有那么嚴重。例如,“人”并不總是和“馬”一起出現,反之亦然。因此當人騎著馬出現的時候,CAM模型可以知道圖像的哪一部分是“人”,但遺憾的是,CAM模型很難在共現場景中正確激活有效的識別對象。

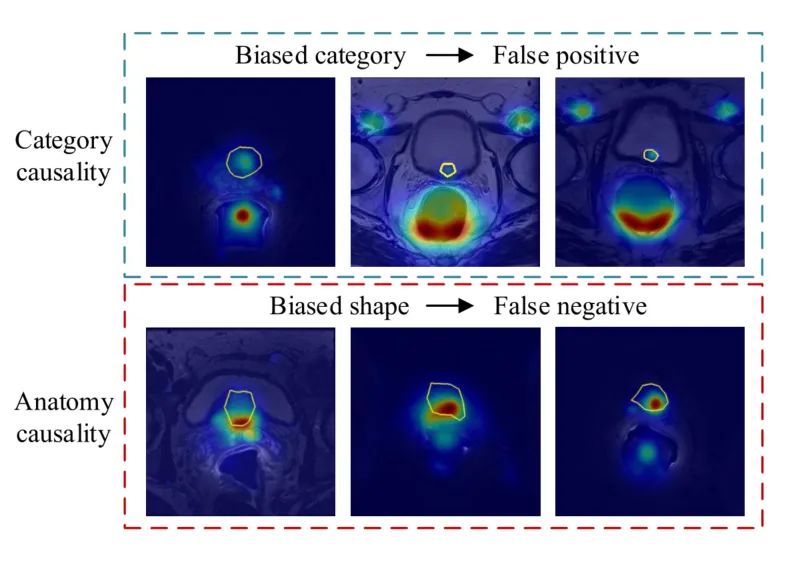
左邊圖為前景與背景的邊界,右邊圖為共現
在醫療圖像的熱力圖中我們可以更加清晰的發現這兩個問題的存在。第一行中可以發現由于共現問題中導致的激活錯誤(黃框表示為正確的激活部分)。第二行中也可以通過類激活圖發現分割過程中出現了前景和背景的黏連問題,邊界分割不清。由于醫療圖像與自然圖像不同,圖像中的區分不同器官區域與傳統的自然圖像中學習到的先驗知識(比如亮度變化、形狀、顏色)不相同,如果是分類任務識別會更加的精準,但是這種精準卻無法體現在醫療圖像分割的任務中。因為在分類任務中并不需要考慮空間相關性的要素,比如當在統計意義上高度相關的要素可以區分類別,但是無法區分區域。比如說我可以說雨傘和下雨在統計學意義是高度相關的,如果是場景分類的時候我們看見有人打傘,那么我們就可以認為這個場景在下雨。如果是分類的情況,激活雨傘也是合理的。但是如果我要把雨水的區域分開,如果激活雨傘就顯得毫無作用了,也顯得模型的毫無邏輯可以言。
文章的方法
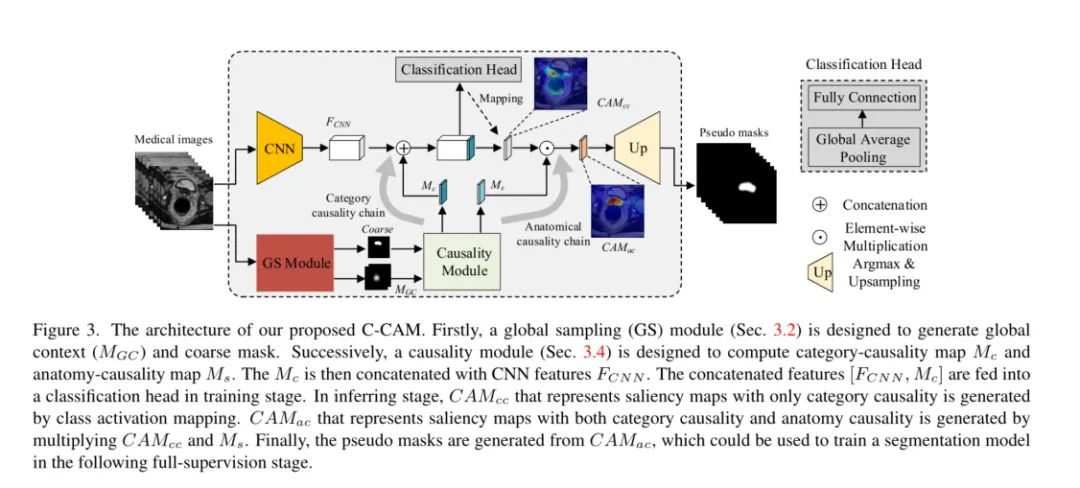
總的來說文章借助CAM以及通過因果推理鏈將因果關系引入了醫療圖像弱監督的方向上。從圖中可以發現,文章用了CAM的粗分割,結合細節調整+粗糙的區域劃分(粗掩碼),以及在分類頭的作用下解決了上面提到的兩個問題。
Global Sampling Module
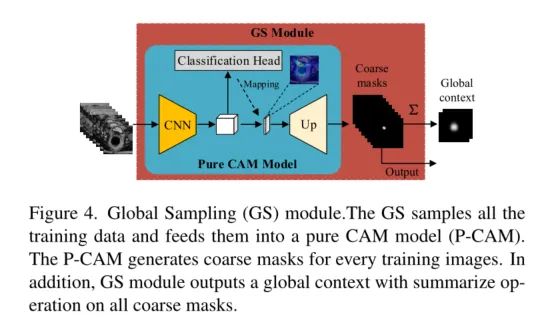
CAM雖然在分割任務中不夠準確。但是,它可以為醫學圖像提供與分類和解剖高度相關的有價值的信息。因此,我們設計了一個全局采樣(GS)模塊來利用這些有價值的信息。
GS模塊如圖下所示。訓練圖像直接輸入Pure CAM (P-CAM)模型,得到粗糙的偽掩模。
P-CAM是一個類似CAM的模型,它由一個CNN主干、一個分類頭、一個映射操作和一個上采樣操作組成。
在訓練階段, 只使用CNN主干和分類頭
在推斷階段, 通過映射操作和上采樣操作生成粗糙的偽掩碼,以及具有全局上下文聯系的特征圖。
Causality in medical image WSSS
在半監督的任務中關鍵是生成一個具有精確的偽掩膜,在C-CAM中我們通過因果鏈來進行邏輯上的細化決策。第一個鏈是分類任務中的因果關系控制,X→Y。說明圖像內容X(原因)在具有全局上下文聯系的特征圖的C的影響下影響最后的分類任務進行優化。第二條因果鏈是分析因果Z→S,通過分析結構信息進而監督分割時形狀(位置內容)的形成。最后,偽掩模由類別特征Y和形狀特征S共同確定。

值的一提的是文章中出現了一個比較好玩的東西,就是上圖的因果關系圖。在醫療圖像中利用因果關系,加強弱監督方向的工作,這篇工作是第一次。通過采用分類頭+CAM的方式去控制模型的學習方向,去做這兩個問題的解決方法,這是有趣的,也是令人信服的。
我們把上面的因果鏈路抽象為可以輸入到模型中的模塊,整理得到了下面的結構。
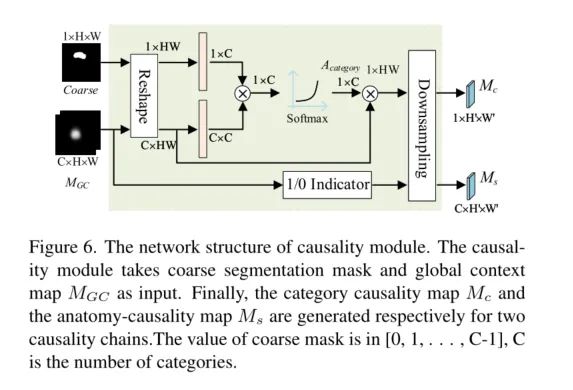
Category-Causality Chain.
通過 MGC 對粗分割標簽圖進行監督和細化,生成出更精細的類別標簽。同時也會細分割標簽圖進行進一步的監督優化,努力的保證控制上下文聯系的特征能夠有效的得到關注,被順利激活。
Anatomy-Causality Chain.
可以很好地捕捉目標的形狀和邊界,但不能完全確定語義,然后通過解剖結構信息來解決語義問題。特別是對于一些多器官影像,如腹部掃描,因為共現的情況,CAMcc無法區分左腎和右腎。為此,文章設計了一個分析因果鏈來解決這個問題。在分析-因果關系鏈中,文章設計了1/0指標來表示醫學圖像的位置信息。最后,按如下公式計算分析-因果關系圖Ms,得到各類別的可能位置:
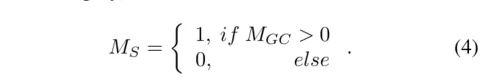
即對特征信息圖進行決策,當MGC被有效激活的時候就將特征進行保留,當MGC無法為有效激活的時候就置為0,通過這種篩選的方式,弱化共現產生的影響,當共現的特征消失的時候,與共現相關的特征通道會被置為0,再出現時是因為特征值被置為0,所以無法順利的激活與共現相關的特征信息。
CAM對于文章的作用
我對于CAM出現在醫療圖像上的事情是很支持的。因為醫療圖像于自然圖像的信息出入還是很大的,其實如果不細說,我們根本沒有辦法判斷出整體效果如何,所以在CAM的加持下,我覺得醫療圖像的工作會更具有說服力。但是在這篇文章中CAM有更重要的角色,就是參加弱監督模型做出粗掩碼,與上文的監督作用相類似,CAM的技術在文章中也是相當于一個信息提取以及監督優化的角色。因為CAM一開始被設計出來的其實主要一個期待點是希望可以強化半監督的工作效果的,所以再次回歸半監督何嘗不是一種不忘初心。
CLIMS: Cross Language Image Matching for Weakly Supervised Semantic Segmentation

文章背景
眾所周知,CAM(類激活圖)通常只激活有區別的對象區域,并且錯誤地包含許多與對象相關的背景。眾所周知,CAM (Class Activation Map)通常只激活目標對象所在的區域,不可避免的將大量與物體無關的背景信息激活了出來。由于WSSS(弱監督語義分割)模型只有固定的圖像級別的標簽,因此很難抑制激活目標對象會激活出的不同背景區域。
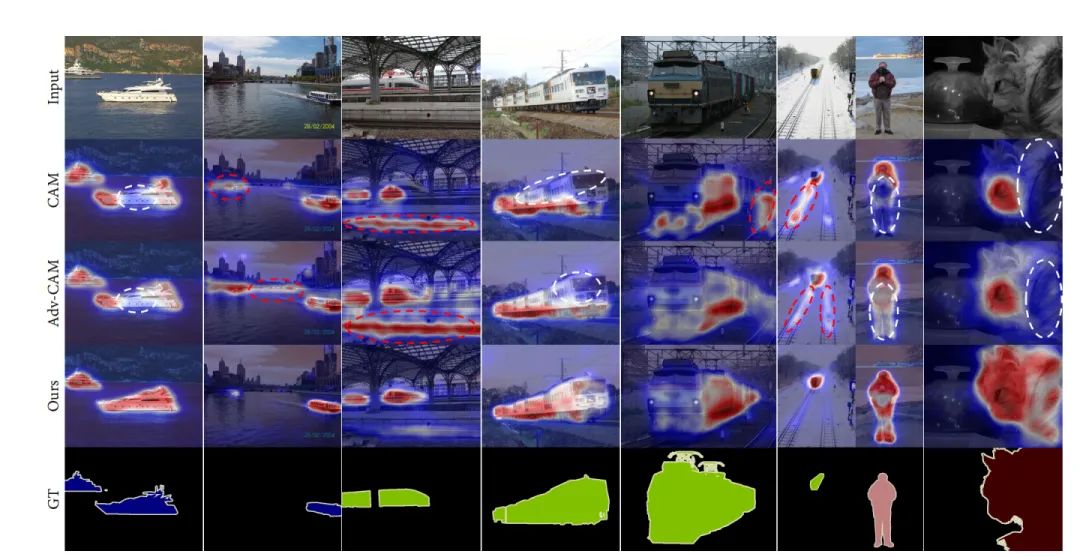
文章工作內容
在本文中,提出了一種用于WSSS場景中的跨語言圖像匹配(CLIMS)框架,基于最近引入的對比語言圖像預訓練(CLIP)模型。框架的核心思想是引入自然語言監督,激活更完整的對象區域,抑制密切相關的背景區域。
特別地,文章中還對目標對象、背景區域和文本標簽專門設計了損失函數對模型進行指導,對每一類CAM激發更合理的對象區域。
文章基于最近引入的對比學習的預訓練模型(CLIP),提出了一種新的跨模態的匹配網絡。框架的核心思想是引入自然語言的信息,來輔助圖像激活出更完整的目標識別區域,并抑制相關的背景區域的干擾。下圖展示的圖像是通過引入自然語言信息,協助圖像激活的效果展示,相信大家從CAM和ADV-CAM中都不難可以看到,跨模態信息交互提升圖像識別準確度方法的效果確實非常的不錯。
文章的方法
一個問題是,我們如何把文本內容和圖像內容進行整合,利用相互的信息監督優化。
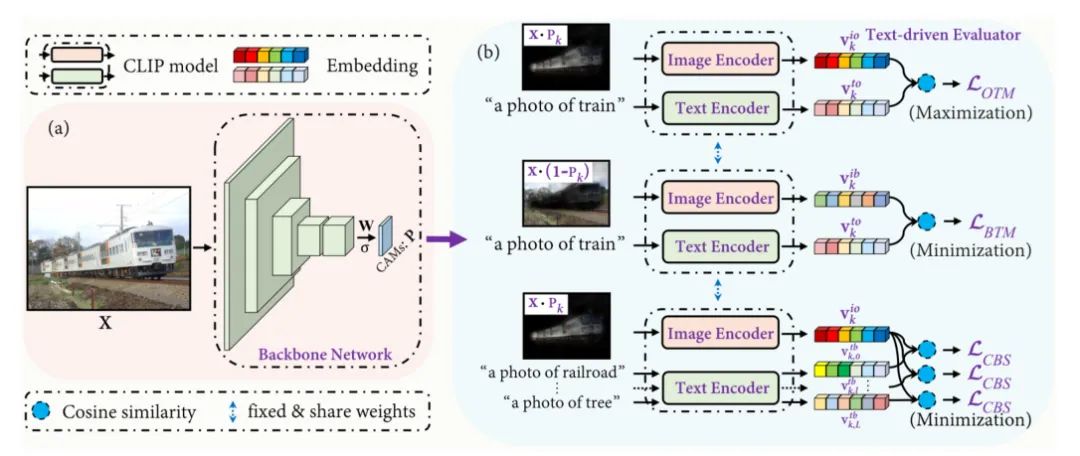
Cross Language Image Matching Framework
傳統的WSSS方法只使用一組預先設計好的固定對象進行監督,但是文章中基于CLIP模型的文本+圖像的模型放棄了這思路,基于Zero-shot的特性,自由探索對象與對象之間的關系。文章通過CAM提取出激活的權重,x表示激活前景的權重,(1-x)表示背景的激活權重。我們把權重賦值進原圖中,就可以初步的將目標對象,以及背景進行分離,然后通過CLIP將提取出的目標對象信息以及背景信息與文本信息進行交互,相互監督。
Object region and Text label Matching
監督的過程其實不難,主要還是CLIP的余弦相似度的計算,之后再經過loss控制優化。生成的初始CAM會在 LOTM 的監督下逐漸接近目標對象。然而,單獨的LOTM并不區分背景和前景的區域,也不能抑制CAM對于背景區域的激活。
Background region and Text label Matching
為了提高被激活對象區域的完整性,設計了背景區域和文本標簽匹配損失 LBTM ,以包含更多的目標對象內容。
Co-occurring Background Suppression
前面提到的兩個損失函數只保證激活圖完全覆蓋目標對象,沒有考慮到與目標對象出現的相關背景的錯誤激活。共現可能會顯著降低生成的偽掩模的質量。但是,要想對這些背景進行像素級標記是非常耗時和昂貴的,而且WSSS的場景中也不會進行這樣的操作。由于背景的種類比前景的種類要更復雜,使用ImageNet訓練的分類網絡,很有可能沒有覆蓋背景對象中出現的類,這樣就沒有辦法對目標對象有清晰的認知了。然而,如果加入了文本信息的監督,以及預訓練的CLIP就可以很好的避開這個缺陷。同時為了解決這一問題,我們設計了以下同時發生的背景抑制損失 LCBS ,在訓練過程中,骨干網絡會逐漸抑制背景區域的錯誤激活,使LCBS最小化。
Area Regularization
其實上文的損失函數的把控下,基本可以消除很大部分的錯誤激活,但是我們依舊也可以使用一個全局化的方式。就是對激活圖中激活目標的區域面積大小進行約束,就可以,更進一步精細化激活區域。因此,設計了一個像素級的區域正則化項 LREG 來約束激活圖的大小,以確保激活圖中不包含無關背景。
最后通過對loss函數的加權組合,就能得到我們想要的結果了。
文章的貢獻
提出了一個文本驅動的學習框架CLIMS,為WSSS引入基于圖像-文本匹配模型的監督。
設計了三個損失函數和一個區域面積的約束。目標對象、背景區域和與文本標簽的匹配損失保證了初始CAM的正確性和完整性。同時背景損失函數對背景抑制損失可以進一步大大降低類相關背景的影響。區域面積的正則化可以約束激活區域的大小
在PASCAL VOC2012數據集上的大量實驗表明,提出的CLIMS顯著優于以前最先進的方法。
CAM在CLIMS中的作用
這是一篇非常有趣的工作,是對于CLIP的一次拓展,文章妙就妙在了,串聯起來了很多意想不到的東西,用CLIP生成CAM圖。在文章中,CAM其實很大程度也和上文一樣,參與到了網絡中的選擇當中。其實看完這么多文章還是發現原來CAM在半監督的任務上參與度是最高的,其實除了CAM的可視化之外,CAM其實也具有選擇控制的作用。可能是CAM的解釋性的可視化更加的通用,以至于蓋過了它在無監督上的光芒吧。但沒事文章可以將CAM的生成和CLIP對比學習進行聯動,這真的是一種新的嘗試,打開了CAM的在半監督領域的更多可能性,其實也將可視化帶到了一個信息高度。
結尾
我遇到了很多朋友,他們都在問我CAM的圖到底要怎么畫才好。是不是用了CAM,就可以提高我實驗效果的說服力。我這里的回答也還是那句,CAM可能確實是目前可視化模型最直觀的手段,CAM的工作其實有對模型得出的過程進行溯源,這就是很多其他類型的可視化做不到的點了。但是我覺得我們不該濫用這類的可視化以及這類的控制結構,我們需要明白自己為啥用,我能不能用這樣的可視化說明一些合乎邏輯的發現,真正發揮解釋作用,而不是一味的可視化,卻忽略了分析,連一開始自己要優化的目標都忘記得一干二凈了。CAM它的功能不只有可視化模型,它還能參與模型的的任務當中,還能做弱監督,還能結合多模態的任務,真的不僅僅只有可視化這一個特點而已。所以我們應該繼續發散思維,去找尋CAM更多的可能性,更多相關的內容其實很建議大家可以后續去研究!
結尾++
其實我也嘗試在MMSegmentation的一些網絡中加入了CAM,實現了部分網絡的一些可視化內容,我晚點會整代碼,然后在MMSegmentation上面提一個pr,大家可以留意一下在MMSegmentation,如果覺得好用的話可以給MMSegmentation點一個大大的star。
審核編輯:劉清
-
PCAA
+關注
關注
0文章
3瀏覽量
6070 -
卷積神經網絡
+關注
關注
4文章
367瀏覽量
11863
原文標題:CNN可視化!從CVPR 2022出發,聊聊CAM是如何激活我們文章的熱度!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
未來物流發展趨勢與TMS的關系
未來AI大模型的發展趨勢
變阻器的未來發展趨勢和前景如何?是否有替代品出現?
FPGA做深度學習能走多遠?
嵌入式系統的未來趨勢有哪些?

數字孿生場景構建的未來發展







 工商網監
工商網監
評論