 幽靈攻擊的消減方法
幽靈攻擊的消減方法
引言
現代處理器使用分支預測和推測執行來最大限度地提高性能。例如,如果分支的目標取決于正在讀取的內存值,CPU將嘗試猜測目標并嘗試提前執行。當內存值最終到達時,CPU要么丟棄,要么提交推測計算。投機邏輯在執行方式上是不可信的,可以訪問受害者的內存和寄存器,并可以執行具有可觀副作用的操作。幽靈攻擊包括誘使受害者投機性地執行在正確程序執行期間不會發生的操作,并通過側通道將受害者的機密信息泄露給攻擊者。
注:幽靈攻擊有很多變體,比如 Spectre Variant 1/2/3/3a/4、L1TF, Foreshadow (SGX)、MSBDS, Fallout、TAA, ZombieLoad V2等1, 這里只介紹 spectre v1, 其他幾個變體暫不涉及。
1、基本概念
亂序執行:又稱無序執行,它允許程序指令流下游的指令與先前指令并行執行,有時甚至在先前指令之前執行,從而提高了處理器組件的利用率。
投機性執行:通常,處理器不知道程序的未來指令流。例如,當無序執行到達條件分支指令時,就會發生這種情況,該指令的方向取決于先前指令執行情況。在這種情況下,處理器可以保留其當前寄存器狀態,預測程序將遵循的路徑,并推測地沿著路徑執行指令。如果預測結果是正確的,則提交(即保存)推測執行的結果,從而產生比等待期間CPU空轉的性能優勢。否則,當處理器確定它遵循了錯誤的路徑時,它通過恢復其寄存器狀態并沿著正確的路徑繼續,放棄 "推測執行" 的工作。
分支預測:在推測執行期間,處理器猜測分支指令的可能結果。更好的預測通過增加可以成功提交的推測性執行操作的數量來提高性能。
內存層次結構:為了彌合較快處理器和較慢內存之間的速度差距,處理器使用連續較小但較快的緩存的層次結構。緩存將內存劃分為固定大小的塊,稱為行,典型的行大小為64或128字節。當處理器需要內存中的數據時,它首先檢查層次結構頂部的L1緩存是否包含副本。在緩存命中的情況下,即在緩存中找到數據,從L1緩存中檢索并使用數據。否則,在緩存未命中的情況下,重復該過程,嘗試從下一個緩存級別檢索數據,最后從外部內存檢索數據。一旦讀取完成,數據通常存儲在緩存中(以前緩存的值被驅逐以騰出空間),以防在不久的將來再次需要數據。
微體系結構側信道攻擊:我們上面討論的所有微體系結構組件都通過預測未來的程序行為來提高處理器性能。為此,他們維護依賴于過去程序行為的狀態,并假設未來行為與過去行為相似或相關。當多個程序同時或通過分時在同一硬件上執行時,由一個程序的行為引起的微體系結構狀態的變化可能會影響其他程序。這反過來又可能導致意外信息從一個程序泄露到另一個程序。初始微體系結構側信道攻擊利用時序可變性和通過 L1 cache 的泄漏從密碼原語中提取密鑰。多年來,通道已經在多個微體系結構組件上得到了演示,包括指令緩存、低級緩存、BTB 和分支歷史。目標已經擴大到包括共址檢測、打破 ASLR、擊鍵監測、網站指紋識別和基因組處理。最近的結果包括跨核和跨CPU攻擊、基于云的攻擊、對可信執行環境的攻擊、來自移動代碼的攻擊以及新的攻擊技術。
2、攻擊舉例
思考下面這個程序,可否在不輸入正確密碼情況下通過驗證?(答案有很多,比如:24個1)
intmain(){
intret=0;
chardef_password[8]="1234567";
charsave_password[8]={0};
charpassword[8]={0};
while(true){
printf("pleaseinputpassword:");
scanf("%s",password);
memset(save_password,0,sizeof(save_password));
if(strcmp(password,def_password)){//比較是否和密碼一致
printf("incorrectpassword!
");
}else{
printf("Congratulation!Youhavepassedtheverification!
");
strcpy(save_password,password);
break;
}
}
returnret;
}
這里對數組的訪問沒有檢查下標是否合法,但是更進一步的思考下,加上長度檢查就一定安全了嗎?
實際上,軟件即使沒有漏洞,數組訪問時都加了下標有效性檢查,也是不一定是安全的。考慮一個例子,其中程序的控制流依賴于位于外部物理內存中的未緩存值。由于此內存比CPU慢得多,因此通常需要幾百個時鐘周期才能知道該值。這時候,CPU會通過投機執行把這段空閑時間利用起來,從安全的角度來看,投機性執行涉及以可能不正確的方式執行程序。然而,由于CPU的設計了通過將不正確的投機執行的結果恢復到其先前狀態來保持功能正確性,因此這些錯誤以前被認為是安全的。
具體的,比如下面的代碼片段(完整的在論文2最后):
if(x
假設變量 x 包含攻擊者控制的數據,為了確保對 array1 的內存訪問的有效性,上面的代碼包含了一個 if 語句,其目的是驗證x的值是否在合法范圍內。接下來我們將介紹一下攻擊者如何繞過此if語句,從而從進程的地址空間讀取潛在的秘密數據。
首先,在初始錯誤訓練階段,攻擊者使用有效輸入調用上述代碼,從而訓練分支預測器期望 if 為真。接下來,在漏洞攻擊階段,攻擊者在 array1 的邊界之外調用值 x 的代碼。CPU不會等待分支結果的確定,而是猜測邊界檢查將為真,并已經推測性地執行使用惡意x訪問array2[array1[x]*4096]的指令。
請注意,從 array2 讀取的數據使用惡意x將數據加載到依賴于 array1[x] 的地址的緩存中,并進行映射,以便訪問轉到不同的緩存行,并避免硬件預取效應。當邊界檢查的結果最終被確定時,CPU 會發現其錯誤,并將所做的任何更改恢復到其標稱微體系結構狀態(nominal microarchitectural state)。但是,對緩存狀態所做的更改不會恢復,因此攻擊者可以分析緩存內容,并找到從受害者內存讀取的越界中檢索到的潛在秘密字節的值。
3、攻擊的消減方法
攻擊的消減方法主要有以下幾個:
防止投機性執行: 幽靈攻擊需要投機執行。確保只有在確定導致指令的控制流時才能執行指令,將防止推測性執行,并防止幽靈攻擊。雖然作為一種對策有效,但防止投機執行將導致處理器性能的顯著下降。
防止訪問機密數據
防止數據進入隱蔽通道
限制從隱蔽通道提取數據
Preventing Branch Poisoning
關于使用編譯器(如畢昇編譯器)進行 spectre v1 的消減在LLVM社區4已有針對函數級別的方案,使用方法如下:
為單個函數添加屬性.
voidf1()__attribute__((speculative_load_hardening)){}
為代碼片段添加函數屬性.
#pragmaclangattributepush(__attribute__((speculative_load_hardening)),apply_to=function) voidf2(){}; #pragmaclangattributepop
添加編譯選項, 整體使能幽靈攻擊防護
-mllvm-antisca-spec-mitigations=true -mllvm-debug-only=aarch64-speculation-hardening#查看調試信息
下面簡單介紹一下編譯器(如畢昇編譯器)的消減原理3。
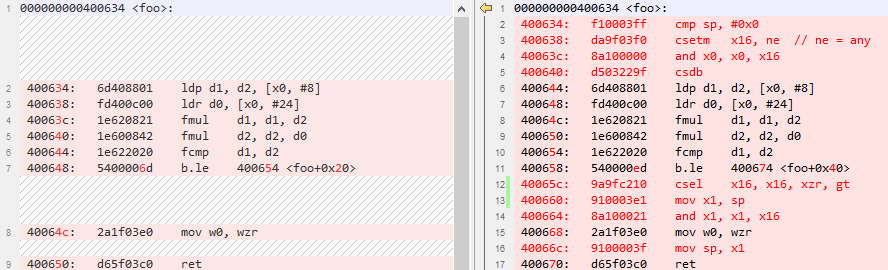
原始代碼:
if(untrusted_value
生成的匯編大概是這樣:
CMP untrusted_value, limit B.HS label LDRB val, [array, untrusted_value] label: // Use val to access other memory locations
消減后:
if(untrusted_value
生成的匯編大概是這樣:
CMP untrusted_value, limit B.HS label CSEL tmp, untrusted_value, WZr, LO CSDB LDRB val, [array, tmp] label: // Use val to access other memory locations
可以看到,我們主要使用CSEL+CSDB(Consume Speculative Data Barrier) 兩個指令組合進行消減,CSEL 指令引入一個臨時的變量,如果沒有投機執行,這個指令看起來是多余的,因為它還是會等于untrusted_value, 在投機執行且推測錯誤的情況下,臨時變量的值就變成了0,且 CSDB 確保 CSEL 的結果不是基于預測的。
附:編譯器防護前后反匯編對比
4.編譯器的實現
主要代碼在文件AArch64SpeculationHardening.cpp, 雖然 LLVM社區4有很多討論5,但代碼一共只有七百行左右,主要有三個步驟:
啟用自動插入投機安全值。
//對于可能讀寫內存的指令(不止是load),加固其相關的寄存器 MachineInstr&MI=*MBB.begin(); if(MI.mayLoad()) BuildMI(MBB,MBBI,MI.getDebugLoc(), TII->get(Is64Bit?AArch64::SpeculationSafeValueX :AArch64::SpeculationSafeValueW)) .addDef(Reg) .addUse(Reg);
其中:如果全是load到 GPR(通用寄存器),就對寄存器加固,否則對地址加固,因為 mask load 的值預計會導致更少的性能開銷,因為與 mask load 地址相比,load 仍然可以推測性地執行。但是,mask 只在 GPR寄存器上很容易有效地完成,因此對于load到非GPR寄存器中的負載(例如浮點load),mask load 的地址。
將消減代碼添加到函數入口和出口(初始化)。
for(autoEntry:EntryBlocks) insertSPToRegTaintPropagation( *Entry,Entry->SkipPHIsLabelsAndDebug(Entry->begin())); ... //CMPSP,#0===SUBSxzr,SP,#0 BuildMI(MBB,MBBI,DebugLoc(),TII->get(AArch64::SUBSXri)) .addDef(AArch64::XZR) .addUse(AArch64::SP) .addImm(0) .addImm(0);//noshift //CSETMx16,NE===CSINVx16,xzr,xzr,EQ BuildMI(MBB,MBBI,DebugLoc(),TII->get(AArch64::CSINVXr)) .addDef(MisspeculatingTaintReg) .addUse(AArch64::XZR) .addUse(AArch64::XZR) .addImm(AArch64CC::EQ);
將消減代碼添加到每個基本塊。
BuildMI(SplitEdgeBB,SplitEdgeBB.begin(),DL,TII->get(AArch64::CSELXr)) .addDef(MisspeculatingTaintReg) .addUse(MisspeculatingTaintReg) .addUse(AArch64::XZR) .addImm(CondCode); SplitEdgeBB.addLiveIn(AArch64::NZCV); ... BuildMI(MBB,MBBI,DL,TII->get(AArch64::HINT)).addImm(0x14);
其他說明,這個方案依賴于X16/W16寄存器(CSEL 要用到),如果已經被使用,則只能插入內存屏障指令:
BuildMI(MBB,MBBI,DL,TII->get(AArch64::DSB)).addImm(0xf); BuildMI(MBB,MBBI,DL,TII->get(AArch64::ISB)).addImm(0xf);
5. 總結2
支持軟件安全技術的一個基本假設是,處理器將忠實地執行程序指令,包括其安全檢查。本文介紹的幽靈攻擊,它利用了投機執行違反這一假設的事實。實際攻擊的示例不需要任何軟件漏洞,并允許攻擊者讀取私有內存并從其他進程和安全上下文注冊內容。軟件安全性從根本上取決于硬件和軟件開發人員之間對CPU實現允許(和不允許)從計算中暴露哪些信息有明確的共識。因此,雖然文中描述的對策可能有助于在短期內限制攻擊,但它們只是權宜之計,因為最好有正式的體系結構保證,以確定任何特定代碼構建在當今的處理器中是否安全。因此,長期解決方案將需要從根本上改變指令集體系結構。更廣泛地說,安全性和性能之間存在權衡。本文中的漏洞以及許多未介紹的漏洞都來自于技術行業長期以來對最大限度地提高性能的結果。這之后,處理器、編譯器、設備驅動程序、操作系統和許多其他關鍵組件已經進化出了復雜優化的復合層,從而引入了安全風險。隨著不安全成本的上升,這些設計需要選擇性修改。在許多情況下,需要改為安全性優化的替代實現。
審核編輯:彭靜
-
處理器
+關注
關注
68文章
19259瀏覽量
229651 -
cpu
+關注
關注
68文章
10854瀏覽量
211578 -
代碼
+關注
關注
30文章
4779瀏覽量
68521
原文標題:技術分享 | 幽靈攻擊與編譯器中的消減方法介紹
文章出處:【微信號:openEulercommunity,微信公眾號:openEuler】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
CC攻擊
網絡攻擊的相關資料分享
cc攻擊防御解決方法
技術分享 | 幽靈攻擊與編譯器中的消減方法介紹
KeeLoq密碼Courtois攻擊方法的分析和修正
基于柯西-高斯動態消減變異的果蠅優化算法研究
基于攻擊威脅監控的軟件保護方法
基于攻擊圖的風險評估方法
DDoS攻擊溯源優化方法

基于攻擊預測的安全態勢量化方法
噪聲消減方案
服務器遭到DDoS攻擊的應對方法
基于概率屬性網絡攻擊圖的攻擊路徑預測方法

針對Kaminsky攻擊的異常行為檢測方法






 工商網監
工商網監
評論