 關于JVM的調優知識
關于JVM的調優知識
最近很多小伙伴跟我說,自己學了不少JVM的調優知識,但是在實際工作中卻不知道何時對JVM進行調優。今天,我就為大家介紹幾種JVM調優的場景。
在閱讀本文時,假定大家已經了解了運行時的數據區域和常用的垃圾回收算法,也了解了Hotspot支持的垃圾回收器。
cpu占用過高
cpu占用過高要分情況討論,是不是業務上在搞活動,突然有大批的流量進來,而且活動結束后cpu占用率就下降了,如果是這種情況其實可以不用太關心,因為請求越多,需要處理的線程數越多,這是正常的現象。話說回來,如果你的服務器配置本身就差,cpu也只有一個核心,這種情況,稍微多一點流量就真的能夠把你的cpu資源耗盡,這時應該考慮先把配置提升吧。
第二種情況,cpu占用率長期過高 ,這種情況下可能是你的程序有那種循環次數超級多的代碼,甚至是出現死循環了。排查步驟如下:
(1)用top命令查看cpu占用情況
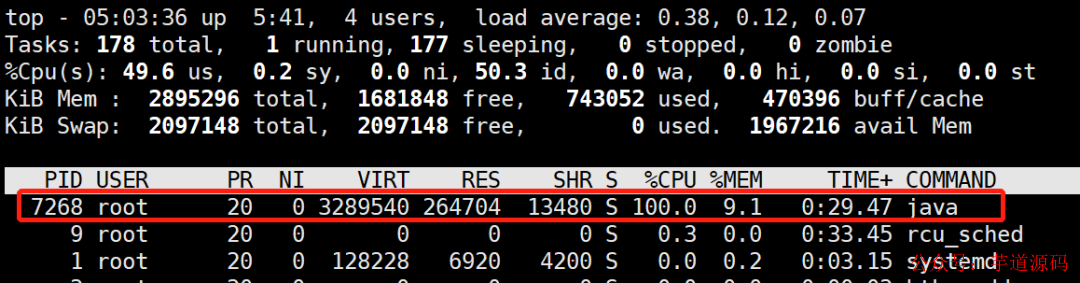
這樣就可以定位出cpu過高的進程。在linux下,top命令獲得的進程號和jps工具獲得的vmid是相同的:

(2)用top -Hp命令查看線程的情況
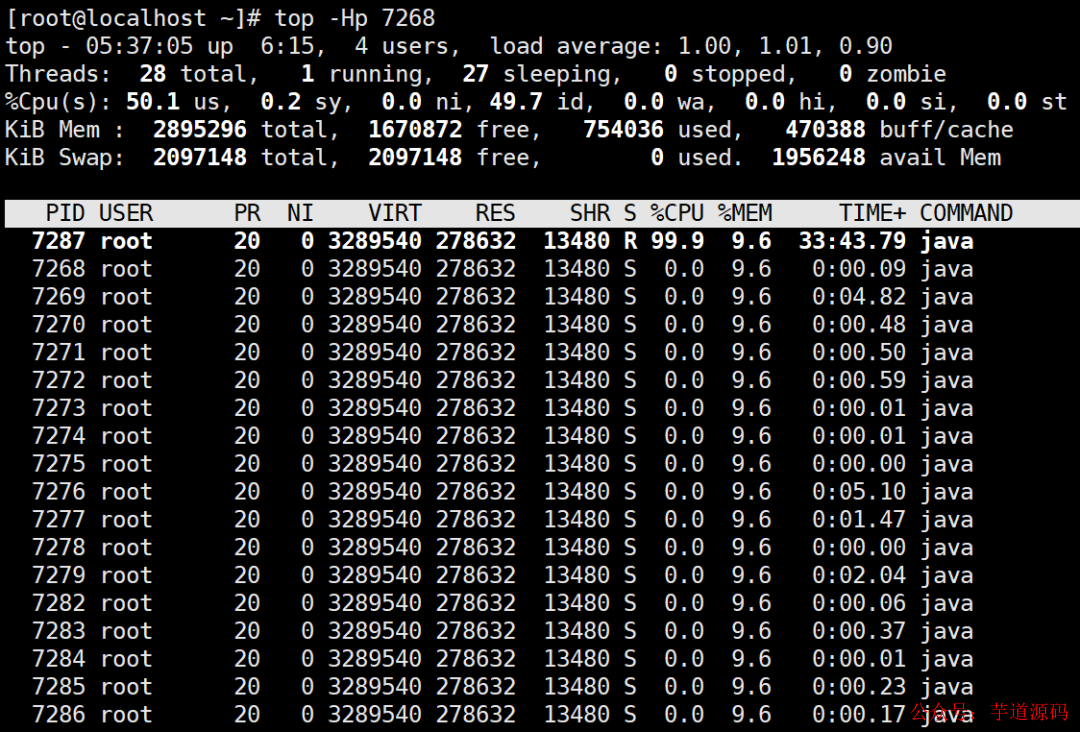
可以看到是線程id為7287這個線程一直在占用cpu
(3)把線程號轉換為16進制
[root@localhost~]#printf"%x"7287
1c77
記下這個16進制的數字,下面我們要用
(4)用jstack工具查看線程棧情況
[root@localhost~]#jstack7268|grep1c77-A10
"http-nio-8080-exec-2"#16daemonprio=5os_prio=0tid=0x00007fb66ce81000nid=0x1c77runnable[0x00007fb639ab9000]
java.lang.Thread.State:RUNNABLE
atcom.spareyaya.jvm.service.EndlessLoopService.service(EndlessLoopService.java:19)
atcom.spareyaya.jvm.controller.JVMController.endlessLoop(JVMController.java:30)
atsun.reflect.NativeMethodAccessorImpl.invoke0(NativeMethod)
atsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
atsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
atjava.lang.reflect.Method.invoke(Method.java:498)
atorg.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:190)
atorg.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:138)
atorg.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:105)
通過jstack工具輸出現在的線程棧,再通過grep命令結合上一步拿到的線程16進制的id定位到這個線程的運行情況,其中jstack后面的7268是第(1)步定位到的進程號,grep后面的是(2)、(3)步定位到的線程號。
從輸出結果可以看到這個線程處于運行狀態,在執行com.spareyaya.jvm.service.EndlessLoopService.service這個方法,代碼行號是19行,這樣就可以去到代碼的19行,找到其所在的代碼塊,看看是不是處于循環中,這樣就定位到了問題。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能。
項目地址:https://github.com/YunaiV/ruoyi-vue-pro
死鎖
死鎖并沒有第一種場景那么明顯,web應用肯定是多線程的程序,它服務于多個請求,程序發生死鎖后,死鎖的線程處于等待狀態(WAITING或TIMED_WAITING),等待狀態的線程不占用cpu,消耗的內存也很有限,而表現上可能是請求沒法進行,最后超時了。在死鎖情況不多的時候,這種情況不容易被發現。
可以使用jstack工具來查看
(1)jps查看java進程
[root@localhost~]#jps-l
8737sun.tools.jps.Jps
8682jvm-0.0.1-SNAPSHOT.jar
(2)jstack查看死鎖問題
由于web應用往往會有很多工作線程,特別是在高并發的情況下線程數更多,于是這個命令的輸出內容會十分多。jstack最大的好處就是會把產生死鎖的信息(包含是什么線程產生的)輸出到最后,所以我們只需要看最后的內容就行了
Javastackinformationforthethreadslistedabove:
===================================================
"Thread-4":
atcom.spareyaya.jvm.service.DeadLockService.service2(DeadLockService.java:35)
-waitingtolock<0x00000000f5035ae0>(ajava.lang.Object)
-locked<0x00000000f5035af0>(ajava.lang.Object)
atcom.spareyaya.jvm.controller.JVMController.lambda$deadLock$1(JVMController.java:41)
atcom.spareyaya.jvm.controller.JVMController$$Lambda$457/1776922136.run(UnknownSource)
atjava.lang.Thread.run(Thread.java:748)
"Thread-3":
atcom.spareyaya.jvm.service.DeadLockService.service1(DeadLockService.java:27)
-waitingtolock<0x00000000f5035af0>(ajava.lang.Object)
-locked<0x00000000f5035ae0>(ajava.lang.Object)
atcom.spareyaya.jvm.controller.JVMController.lambda$deadLock$0(JVMController.java:37)
atcom.spareyaya.jvm.controller.JVMController$$Lambda$456/474286897.run(UnknownSource)
atjava.lang.Thread.run(Thread.java:748)
Found1deadlock.
發現了一個死鎖,原因也一目了然。
基于微服務的思想,構建在 B2C 電商場景下的項目實戰。核心技術棧,是 Spring Boot + Dubbo 。未來,會重構成 Spring Cloud Alibaba 。
項目地址:https://github.com/YunaiV/onemall
內存泄漏
我們都知道,java和c++的最大區別是前者會自動收回不再使用的內存,后者需要程序員手動釋放。在c++中,如果我們忘記釋放內存就會發生內存泄漏。但是,不要以為jvm幫我們回收了內存就不會出現內存泄漏。
程序發生內存泄漏后,進程的可用內存會慢慢變少,最后的結果就是拋出OOM錯誤。發生OOM錯誤后可能會想到是內存不夠大,于是把-Xmx參數調大,然后重啟應用。這么做的結果就是,過了一段時間后,OOM依然會出現。最后無法再調大最大堆內存了,結果就是只能每隔一段時間重啟一下應用。
內存泄漏的另一個可能的表現是請求的響應時間變長了。這是因為頻繁發生的GC會暫停其它所有線程(Stop The World)造成的。
為了模擬這個場景,使用了以下的程序
importjava.util.concurrent.ExecutorService;
importjava.util.concurrent.Executors;
publicclassMain{
publicstaticvoidmain(String[]args){
Mainmain=newMain();
while(true){
try{
Thread.sleep(1);
}catch(InterruptedExceptione){
e.printStackTrace();
}
main.run();
}
}
privatevoidrun(){
ExecutorServiceexecutorService=Executors.newCachedThreadPool();
for(inti=0;i10;i++){
executorService.execute(()->{
//dosomething...
});
}
}
}
運行參數是-Xms20m -Xmx20m -XX:+PrintGC,把可用內存調小一點,并且在發生gc時輸出信息,運行結果如下
...
[GC(AllocationFailure)12776K->10840K(18432K),0.0309510secs]
[GC(AllocationFailure)13400K->11520K(18432K),0.0333385secs]
[GC(AllocationFailure)14080K->12168K(18432K),0.0332409secs]
[GC(AllocationFailure)14728K->12832K(18432K),0.0370435secs]
[FullGC(Ergonomics)12832K->12363K(18432K),0.1942141secs]
[FullGC(Ergonomics)14923K->12951K(18432K),0.1607221secs]
[FullGC(Ergonomics)15511K->13542K(18432K),0.1956311secs]
...
[FullGC(Ergonomics)16382K->16381K(18432K),0.1734902secs]
[FullGC(Ergonomics)16383K->16383K(18432K),0.1922607secs]
[FullGC(Ergonomics)16383K->16383K(18432K),0.1824278secs]
[FullGC(AllocationFailure)16383K->16383K(18432K),0.1710382secs]
[FullGC(Ergonomics)16383K->16382K(18432K),0.1829138secs]
[FullGC(Ergonomics)Exceptioninthread"main"16383K->16382K(18432K),0.1406222secs]
[FullGC(AllocationFailure)16382K->16382K(18432K),0.1392928secs]
[FullGC(Ergonomics)16383K->16382K(18432K),0.1546243secs]
[FullGC(Ergonomics)16383K->16382K(18432K),0.1755271secs]
[FullGC(Ergonomics)16383K->16382K(18432K),0.1699080secs]
[FullGC(AllocationFailure)16382K->16382K(18432K),0.1697982secs]
[FullGC(Ergonomics)16383K->16382K(18432K),0.1851136secs]
[FullGC(AllocationFailure)16382K->16382K(18432K),0.1655088secs]
java.lang.OutOfMemoryError:Javaheapspace
可以看到雖然一直在gc,占用的內存卻越來越多,說明程序有的對象無法被回收。但是上面的程序對象都是定義在方法內的,屬于局部變量,局部變量在方法運行結果后,所引用的對象在gc時應該被回收啊,但是這里明顯沒有。
為了找出到底是哪些對象沒能被回收,我們加上運行參數-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=heap.bin,意思是發生OOM時把堆內存信息dump出來。運行程序直至異常,于是得到heap.dump文件,然后我們借助eclipse的MAT插件來分析,如果沒有安裝需要先安裝。
然后File->Open Heap Dump... ,然后選擇剛才dump出來的文件,選擇Leak Suspects
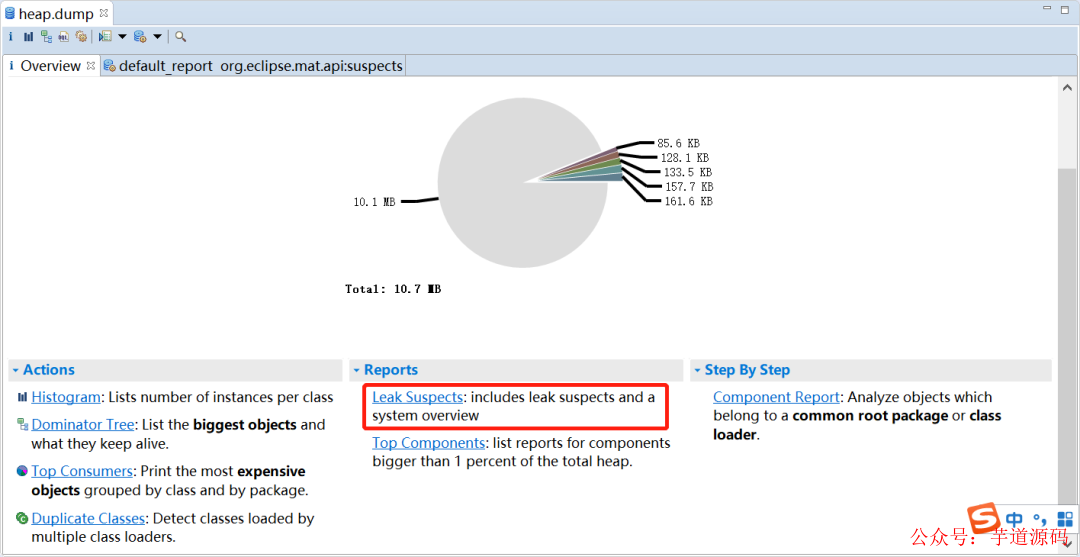
MAT會列出所有可能發生內存泄漏的對象
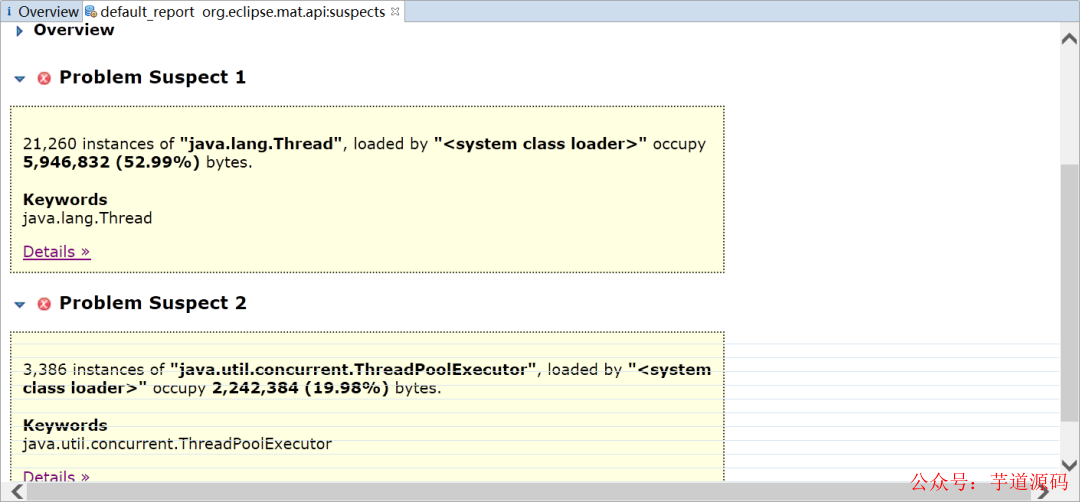
可以看到居然有21260個Thread對象,3386個ThreadPoolExecutor對象,如果你去看一下java.util.concurrent.ThreadPoolExecutor的源碼,可以發現線程池為了復用線程,會不斷地等待新的任務,線程也不會回收,需要調用其shutdown()方法才能讓線程池執行完任務后停止。
其實線程池定義成局部變量,好的做法是設置成單例。
上面只是其中一種處理方法
在線上的應用,內存往往會設置得很大,這樣發生OOM再把內存快照dump出來的文件就會很大,可能大到在本地的電腦中已經無法分析了(因為內存不足夠打開這個dump文件)。這里介紹另一種處理辦法:
(1)用jps定位到進程號
C:UsersspareyayaIdeaProjectsmaven-project argetclassesorgexample
et>jps-l
24836org.example.net.Main
62520org.jetbrains.jps.cmdline.Launcher
129980sun.tools.jps.Jps
136028org.jetbrains.jps.cmdline.Launcher
因為已經知道了是哪個應用發生了OOM,這樣可以直接用jps找到進程號135988
(2)用jstat分析gc活動情況
jstat是一個統計java進程內存使用情況和gc活動的工具,參數可以有很多,可以通過jstat -help查看所有參數以及含義
C:UsersspareyayaIdeaProjectsmaven-project argetclassesorgexample
et>jstat-gcutil-t-h8248361000
TimestampS0S1EOMCCSYGCYGCTFGCFGCTGCT
29.132.810.0023.4885.9292.8484.13140.33900.0000.339
30.132.810.0078.1285.9292.8484.13140.33900.0000.339
31.10.000.0022.7091.7492.7283.71150.38910.2330.622
上面是命令意思是輸出gc的情況,輸出時間,每8行輸出一個行頭信息,統計的進程號是24836,每1000毫秒輸出一次信息。
輸出信息是Timestamp是距離jvm啟動的時間,S0、S1、E是新生代的兩個Survivor和Eden,O是老年代區,M是Metaspace,CCS使用壓縮比例,YGC和YGCT分別是新生代gc的次數和時間,FGC和FGCT分別是老年代gc的次數和時間,GCT是gc的總時間。雖然發生了gc,但是老年代內存占用率根本沒下降,說明有的對象沒法被回收(當然也不排除這些對象真的是有用)。
(3)用jmap工具dump出內存快照
jmap可以把指定java進程的內存快照dump出來,效果和第一種處理辦法一樣,不同的是它不用等OOM就可以做到,而且dump出來的快照也會小很多。
jmap-dump:live,format=b,file=heap.bin24836
這時會得到heap.bin的內存快照文件,然后就可以用eclipse來分析了。
總結
以上三種嚴格地說還算不上jvm的調優,只是用了jvm工具把代碼中存在的問題找了出來。我們進行jvm的主要目的是盡量減少停頓時間,提高系統的吞吐量。
但是如果我們沒有對系統進行分析就盲目去設置其中的參數,可能會得到更壞的結果,jvm發展到今天,各種默認的參數可能是實驗室的人經過多次的測試來做平衡的,適用大多數的應用場景。
如果你認為你的jvm確實有調優的必要,也務必要取樣分析,最后還得慢慢多次調節,才有可能得到更優的效果。
-
cpu
+關注
關注
68文章
10854瀏覽量
211578 -
JVM
+關注
關注
0文章
158瀏覽量
12220
原文標題:幾種常見的JVM調優場景(建議收藏)
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Alluxio線程池結構與吞吐量調優
基于專家知識+AI算法的性能調優
JVM知識體系剖析
jvm調優參數
jvm參數的設置和jvm調優
jvm調優主要是調哪里
jvm調優常用命令
深度解析JVM調優實踐應用





 工商網監
工商網監
評論