") 圖像分類任務(wù)的各種tricks
圖像分類任務(wù)的各種tricks
導(dǎo)讀
計(jì)算機(jī)視覺(jué)主要問(wèn)題有圖像分類、目標(biāo)檢測(cè)和圖像分割等。針對(duì)圖像分類任務(wù),提升準(zhǔn)確率的方法路線有兩條,一個(gè)是模型的修改,另一個(gè)是各種數(shù)據(jù)處理和訓(xùn)練的tricks。圖像分類中的各種技巧對(duì)于目標(biāo)檢測(cè)、圖像分割等任務(wù)也有很好的作用。本文在精讀論文的基礎(chǔ)上,總結(jié)了圖像分類任務(wù)的各種tricks。
目錄:
Warmup
Label-smoothing
Random image cropping and patching
Knowledge Distillation
Cutout
Random erasing
Cosine learning rate decay
Mixup training
AdaBoud
AutoAugment
其他經(jīng)典的tricks
Warmup
學(xué)習(xí)率是神經(jīng)網(wǎng)絡(luò)訓(xùn)練中最重要的超參數(shù)之一,針對(duì)學(xué)習(xí)率的技巧有很多。Warm up是在ResNet論文[1]中提到的一種學(xué)習(xí)率預(yù)熱的方法。由于剛開(kāi)始訓(xùn)練時(shí)模型的權(quán)重(weights)是隨機(jī)初始化的(全部置為0是一個(gè)坑,原因見(jiàn)[2]),此時(shí)選擇一個(gè)較大的學(xué)習(xí)率,可能會(huì)帶來(lái)模型的不穩(wěn)定。學(xué)習(xí)率預(yù)熱就是在剛開(kāi)始訓(xùn)練的時(shí)候先使用一個(gè)較小的學(xué)習(xí)率,訓(xùn)練一些epoches或iterations,等模型穩(wěn)定時(shí)再修改為預(yù)先設(shè)置的學(xué)習(xí)率進(jìn)行訓(xùn)練。論文[1]中使用一個(gè)110層的ResNet在cifar10上訓(xùn)練時(shí),先用0.01的學(xué)習(xí)率訓(xùn)練直到訓(xùn)練誤差低于80%(大概訓(xùn)練了400個(gè)iterations),然后使用0.1的學(xué)習(xí)率進(jìn)行訓(xùn)練。
上述的方法是constant warmup,18年Facebook又針對(duì)上面的warmup進(jìn)行了改進(jìn)[3],因?yàn)閺囊粋€(gè)很小的學(xué)習(xí)率一下變?yōu)楸容^大的學(xué)習(xí)率可能會(huì)導(dǎo)致訓(xùn)練誤差突然增大。論文[3]提出了gradual warmup來(lái)解決這個(gè)問(wèn)題,即從最開(kāi)始的小學(xué)習(xí)率開(kāi)始,每個(gè)iteration增大一點(diǎn),直到最初設(shè)置的比較大的學(xué)習(xí)率。
Gradual warmup代碼如下:
fromtorch.optim.lr_schedulerimport_LRScheduler classGradualWarmupScheduler(_LRScheduler): """ Args: optimizer(Optimizer):Wrappedoptimizer. multiplier:targetlearningrate=baselr*multiplier total_epoch:targetlearningrateisreachedattotal_epoch,gradually after_scheduler:aftertarget_epoch,usethisscheduler(eg.ReduceLROnPlateau) """ def__init__(self,optimizer,multiplier,total_epoch,after_scheduler=None): self.multiplier=multiplier ifself.multiplier<=??1.: ?????????????raise??ValueError('multiplier?should?be?greater?than?1.') ?????????self.total_epoch?=?total_epoch ?????????self.after_scheduler?=?after_scheduler ?????????self.finished?=??False ?????????super().__init__(optimizer) ????def?get_lr(self): ????????if?self.last_epoch?>self.total_epoch: ifself.after_scheduler: ifnotself.finished: self.after_scheduler.base_lrs=[base_lr*self.multiplierforbase_lrinself.base_lrs] self.finished=True returnself.after_scheduler.get_lr() return[base_lr*self.multiplierforbase_lrinself.base_lrs] return[base_lr*((self.multiplier-1.)*self.last_epoch/self.total_epoch+1.)forbase_lrinself.base_lrs] defstep(self,epoch=None): ifself.finishedandself.after_scheduler: returnself.after_scheduler.step(epoch) else: returnsuper(GradualWarmupScheduler,self).step(epoch)
Linear scaling learning rate
Linear scaling learning rate是在論文[3]中針對(duì)比較大的batch size而提出的一種方法。
在凸優(yōu)化問(wèn)題中,隨著批量的增加,收斂速度會(huì)降低,神經(jīng)網(wǎng)絡(luò)也有類似的實(shí)證結(jié)果。隨著batch size的增大,處理相同數(shù)據(jù)量的速度會(huì)越來(lái)越快,但是達(dá)到相同精度所需要的epoch數(shù)量越來(lái)越多。也就是說(shuō),使用相同的epoch時(shí),大batch size訓(xùn)練的模型與小batch size訓(xùn)練的模型相比,驗(yàn)證準(zhǔn)確率會(huì)減小。
上面提到的gradual warmup是解決此問(wèn)題的方法之一。另外,linear scaling learning rate也是一種有效的方法。在mini-batch SGD訓(xùn)練時(shí),梯度下降的值是隨機(jī)的,因?yàn)槊恳粋€(gè)batch的數(shù)據(jù)是隨機(jī)選擇的。增大batch size不會(huì)改變梯度的期望,但是會(huì)降低它的方差。也就是說(shuō),大batch size會(huì)降低梯度中的噪聲,所以我們可以增大學(xué)習(xí)率來(lái)加快收斂。
具體做法很簡(jiǎn)單,比如ResNet原論文[1]中,batch size為256時(shí)選擇的學(xué)習(xí)率是0.1,當(dāng)我們把batch size變?yōu)橐粋€(gè)較大的數(shù)b時(shí),學(xué)習(xí)率應(yīng)該變?yōu)?0.1 × b/256。
Label-smoothing
在分類問(wèn)題中,我們的最后一層一般是全連接層,然后對(duì)應(yīng)標(biāo)簽的one-hot編碼,即把對(duì)應(yīng)類別的值編碼為1,其他為0。這種編碼方式和通過(guò)降低交叉熵?fù)p失來(lái)調(diào)整參數(shù)的方式結(jié)合起來(lái),會(huì)有一些問(wèn)題。這種方式會(huì)鼓勵(lì)模型對(duì)不同類別的輸出分?jǐn)?shù)差異非常大,或者說(shuō),模型過(guò)分相信它的判斷。但是,對(duì)于一個(gè)由多人標(biāo)注的數(shù)據(jù)集,不同人標(biāo)注的準(zhǔn)則可能不同,每個(gè)人的標(biāo)注也可能會(huì)有一些錯(cuò)誤。模型對(duì)標(biāo)簽的過(guò)分相信會(huì)導(dǎo)致過(guò)擬合。
標(biāo)簽平滑(Label-smoothing regularization,LSR)是應(yīng)對(duì)該問(wèn)題的有效方法之一,它的具體思想是降低我們對(duì)于標(biāo)簽的信任,例如我們可以將損失的目標(biāo)值從1稍微降到0.9,或者將從0稍微升到0.1。標(biāo)簽平滑最早在inception-v2[4]中被提出,它將真實(shí)的概率改造為:
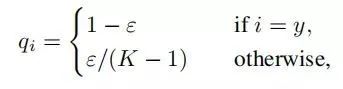
其中,ε是一個(gè)小的常數(shù),K是類別的數(shù)目,y是圖片的真正的標(biāo)簽,i代表第i個(gè)類別,是圖片為第i類的概率。
總的來(lái)說(shuō),LSR是一種通過(guò)在標(biāo)簽y中加入噪聲,實(shí)現(xiàn)對(duì)模型約束,降低模型過(guò)擬合程度的一種正則化方法。LSR代碼如下:
importtorch importtorch.nnasnn classLSR(nn.Module): def__init__(self,e=0.1,reduction='mean'): super().__init__() self.log_softmax=nn.LogSoftmax(dim=1) self.e=e self.reduction=reduction def_one_hot(self,labels,classes,value=1): """ Convertlabelstoonehotvectors Args: labels:torchtensorinformat[label1,label2,label3,...] classes:int,numberofclasses value:labelvalueinonehotvector,defaultto1 Returns: returnonehotformatlabelsinshape[batchsize,classes] """ one_hot=torch.zeros(labels.size(0),classes) #labelsandvalue_addedsizemustmatch labels=labels.view(labels.size(0),-1) value_added=torch.Tensor(labels.size(0),1).fill_(value) value_added=value_added.to(labels.device) one_hot=one_hot.to(labels.device) one_hot.scatter_add_(1,labels,value_added) returnone_hot def_smooth_label(self,target,length,smooth_factor): """converttargetstoone-hotformat,andsmooththem. Args: target:targetinformwith[label1,label2,label_batchsize] length:lengthofone-hotformat(numberofclasses) smooth_factor:smoothfactorforlabelsmooth Returns: smoothedlabelsinonehotformat """ one_hot=self._one_hot(target,length,value=1-smooth_factor) one_hot+=smooth_factor/length returnone_hot.to(target.device)
Random image cropping and patching
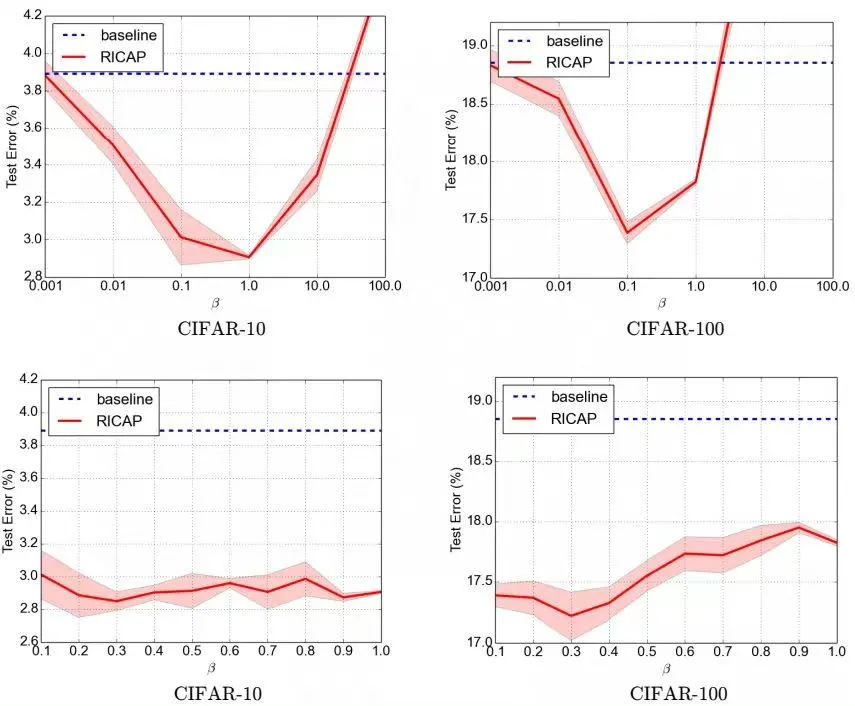
Random image cropping and patching (RICAP)[7]方法隨機(jī)裁剪四個(gè)圖片的中部分,然后把它們拼接為一個(gè)圖片,同時(shí)混合這四個(gè)圖片的標(biāo)簽。
RICAP在caifar10上達(dá)到了2.19%的錯(cuò)誤率。
如下圖所示,Ix, Iy是原始圖片的寬和高。w和h稱為boundary position,它決定了四個(gè)裁剪得到的小圖片的尺寸。w和h從beta分布Beta(β, β)中隨機(jī)生成,β也是RICAP的超參數(shù)。最終拼接的圖片尺寸和原圖片尺寸保持一致。
RICAP的代碼如下:
beta=0.3#hyperparameter for(images,targets)intrain_loader: #gettheimagesize I_x,I_y=images.size()[2:] #drawaboundryposition(w,h) w=int(np.round(I_x*np.random.beta(beta,beta))) h=int(np.round(I_y*np.random.beta(beta,beta))) w_=[w,I_x-w,w,I_x-w] h_=[h,h,I_y-h,I_y-h] #selectandcropfourimages cropped_images={} c_={} W_={} forkinrange(4): index=torch.randperm(images.size(0)) x_k=np.random.randint(0,I_x-w_[k]+1) y_k=np.random.randint(0,I_y-h_[k]+1) cropped_images[k]=images[index][:,:,x_k:x_k+w_[k],y_k:y_k+h_[k]] c_[k]=target[index].cuda() W_[k]=w_[k]*h_[k]/(I_x*I_y) #patchcroppedimages patched_images=torch.cat( (torch.cat((cropped_images[0],cropped_images[1]),2), torch.cat((cropped_images[2],cropped_images[3]),2)), 3) #patched_images=patched_images.cuda() #getoutput output=model(patched_images) #calculatelossandaccuracy loss=sum([W_[k]*criterion(output,c_[k])forkinrange(4)]) acc=sum([W_[k]*accuracy(output,c_[k])[0]forkinrange(4)])
Knowledge Distillation
提高幾乎所有機(jī)器學(xué)習(xí)算法性能的一種非常簡(jiǎn)單的方法是在相同的數(shù)據(jù)上訓(xùn)練許多不同的模型,然后對(duì)它們的預(yù)測(cè)進(jìn)行平均。但是使用所有的模型集成進(jìn)行預(yù)測(cè)是比較麻煩的,并且可能計(jì)算量太大而無(wú)法部署到大量用戶。Knowledge Distillation(知識(shí)蒸餾)[8]方法就是應(yīng)對(duì)這種問(wèn)題的有效方法之一。
在知識(shí)蒸餾方法中,我們使用一個(gè)教師模型來(lái)幫助當(dāng)前的模型(學(xué)生模型)訓(xùn)練。教師模型是一個(gè)較高準(zhǔn)確率的預(yù)訓(xùn)練模型,因此學(xué)生模型可以在保持模型復(fù)雜度不變的情況下提升準(zhǔn)確率。比如,可以使用ResNet-152作為教師模型來(lái)幫助學(xué)生模型ResNet-50訓(xùn)練。在訓(xùn)練過(guò)程中,我們會(huì)加一個(gè)蒸餾損失來(lái)懲罰學(xué)生模型和教師模型的輸出之間的差異。
給定輸入,假定p是真正的概率分布,z和r分別是學(xué)生模型和教師模型最后一個(gè)全連接層的輸出。之前我們會(huì)用交叉熵?fù)p失l(p,softmax(z))來(lái)度量p和z之間的差異,這里的蒸餾損失同樣用交叉熵。所以,使用知識(shí)蒸餾方法總的損失函數(shù)是
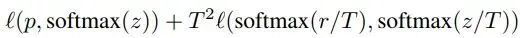
上式中,第一項(xiàng)還是原來(lái)的損失函數(shù),第二項(xiàng)是添加的用來(lái)懲罰學(xué)生模型和教師模型輸出差異的蒸餾損失。其中,T是一個(gè)溫度超參數(shù),用來(lái)使softmax的輸出更加平滑的。實(shí)驗(yàn)證明,用ResNet-152作為教師模型來(lái)訓(xùn)練ResNet-50,可以提高后者的準(zhǔn)確率。
Cutout
Cutout[9]是一種新的正則化方法。原理是在訓(xùn)練時(shí)隨機(jī)把圖片的一部分減掉,這樣能提高模型的魯棒性。它的來(lái)源是計(jì)算機(jī)視覺(jué)任務(wù)中經(jīng)常遇到的物體遮擋問(wèn)題。通過(guò)cutout生成一些類似被遮擋的物體,不僅可以讓模型在遇到遮擋問(wèn)題時(shí)表現(xiàn)更好,還能讓模型在做決定時(shí)更多地考慮環(huán)境(context)。
代碼如下:
importtorch importnumpyasnp classCutout(object): """Randomlymaskoutoneormorepatchesfromanimage. Args: n_holes(int):Numberofpatchestocutoutofeachimage. length(int):Thelength(inpixels)ofeachsquarepatch. """ def__init__(self,n_holes,length): self.n_holes=n_holes self.length=length def__call__(self,img): """ Args: img(Tensor):Tensorimageofsize(C,H,W). Returns: Tensor:Imagewithn_holesofdimensionlengthxlengthcutoutofit. """ h=img.size(1) w=img.size(2) mask=np.ones((h,w),np.float32) forninrange(self.n_holes): y=np.random.randint(h) x=np.random.randint(w) y1=np.clip(y-self.length//2,0,h) y2=np.clip(y+self.length//2,0,h) x1=np.clip(x-self.length//2,0,w) x2=np.clip(x+self.length//2,0,w) mask[y1:y2,x1:x2]=0. mask=torch.from_numpy(mask) mask=mask.expand_as(img) img=img*mask returnimg
效果如下圖,每個(gè)圖片的一小部分被cutout了。
Random erasing
Random erasing[6]其實(shí)和cutout非常類似,也是一種模擬物體遮擋情況的數(shù)據(jù)增強(qiáng)方法。區(qū)別在于,cutout是把圖片中隨機(jī)抽中的矩形區(qū)域的像素值置為0,相當(dāng)于裁剪掉,random erasing是用隨機(jī)數(shù)或者數(shù)據(jù)集中像素的平均值替換原來(lái)的像素值。而且,cutout每次裁剪掉的區(qū)域大小是固定的,Random erasing替換掉的區(qū)域大小是隨機(jī)的。
Random erasing代碼如下:
from__future__importabsolute_import fromtorchvision.transformsimport* fromPILimportImage importrandom importmath importnumpyasnp importtorch classRandomErasing(object): ''' probability:Theprobabilitythattheoperationwillbeperformed. sh:maxerasingarea r1:minaspectratio mean:erasingvalue ''' def__init__(self,probability=0.5,sl=0.02,sh=0.4,r1=0.3,mean=[0.4914,0.4822,0.4465]): self.probability=probability self.mean=mean self.sl=sl self.sh=sh self.r1=r1 def__call__(self,img): ifrandom.uniform(0,1)>self.probability: returnimg forattemptinrange(100): area=img.size()[1]*img.size()[2] target_area=random.uniform(self.sl,self.sh)*area aspect_ratio=random.uniform(self.r1,1/self.r1) h=int(round(math.sqrt(target_area*aspect_ratio))) w=int(round(math.sqrt(target_area/aspect_ratio))) ifw
Cosine learning rate decay
在warmup之后的訓(xùn)練過(guò)程中,學(xué)習(xí)率不斷衰減是一個(gè)提高精度的好方法。其中有step decay和cosine decay等,前者是隨著epoch增大學(xué)習(xí)率不斷減去一個(gè)小的數(shù),后者是讓學(xué)習(xí)率隨著訓(xùn)練過(guò)程曲線下降。
對(duì)于cosine decay,假設(shè)總共有T個(gè)batch(不考慮warmup階段),在第t個(gè)batch時(shí),學(xué)習(xí)率η_t為:
這里,η代表初始設(shè)置的學(xué)習(xí)率。這種學(xué)習(xí)率遞減的方式稱之為cosine decay。
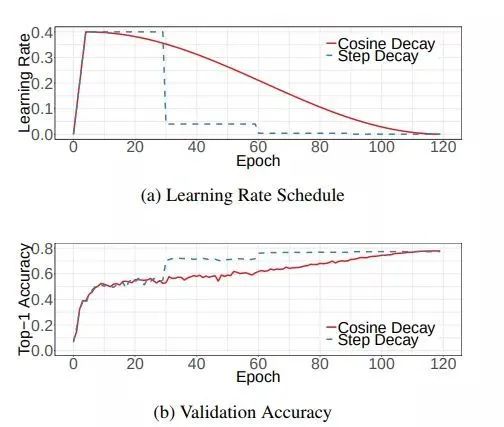
下面是帶有warmup的學(xué)習(xí)率衰減的可視化圖[4]。其中,圖(a)是學(xué)習(xí)率隨epoch增大而下降的圖,可以看出cosine decay比step decay更加平滑一點(diǎn)。圖(b)是準(zhǔn)確率隨epoch的變化圖,兩者最終的準(zhǔn)確率沒(méi)有太大差別,不過(guò)cosine decay的學(xué)習(xí)過(guò)程更加平滑。
在pytorch的torch.optim.lr_scheduler中有更多的學(xué)習(xí)率衰減的方法,至于哪個(gè)效果好,可能對(duì)于不同問(wèn)題答案是不一樣的。對(duì)于step decay,使用方法如下:
#Assumingoptimizeruseslr=0.05forallgroups #lr=0.05ifepoch
Mixup training
Mixup[10]是一種新的數(shù)據(jù)增強(qiáng)的方法。Mixup training,就是每次取出2張圖片,然后將它們線性組合,得到新的圖片,以此來(lái)作為新的訓(xùn)練樣本,進(jìn)行網(wǎng)絡(luò)的訓(xùn)練,如下公式,其中x代表圖像數(shù)據(jù),y代表標(biāo)簽,則得到的新的xhat, yhat。
其中,λ是從Beta(α, α)隨機(jī)采樣的數(shù),在[0,1]之間。在訓(xùn)練過(guò)程中,僅使用(xhat, yhat)。Mixup方法主要增強(qiáng)了訓(xùn)練樣本之間的線性表達(dá),增強(qiáng)網(wǎng)絡(luò)的泛化能力,不過(guò)mixup方法需要較長(zhǎng)的時(shí)間才能收斂得比較好。
Mixup代碼如下:
for(images,labels)intrain_loader: l=np.random.beta(mixup_alpha,mixup_alpha) index=torch.randperm(images.size(0)) images_a,images_b=images,images[index] labels_a,labels_b=labels,labels[index] mixed_images=l*images_a+(1-l)*images_b outputs=model(mixed_images) loss=l*criterion(outputs,labels_a)+(1-l)*criterion(outputs,labels_b) acc=l*accuracy(outputs,labels_a)[0]+(1-l)*accuracy(outputs,labels_b)[0]
AdaBound
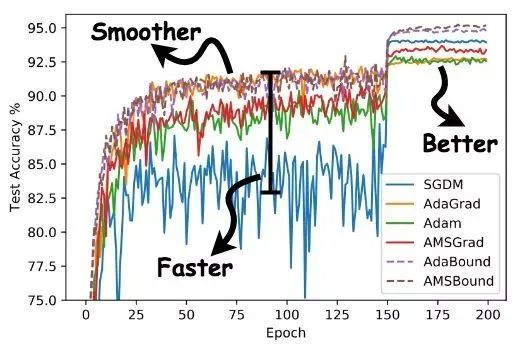
AdaBound是最近一篇論文[5]中提到的,按照作者的說(shuō)法,AdaBound會(huì)讓你的訓(xùn)練過(guò)程像adam一樣快,并且像SGD一樣好。如下圖所示,使用AdaBound會(huì)收斂速度更快,過(guò)程更平滑,結(jié)果更好。
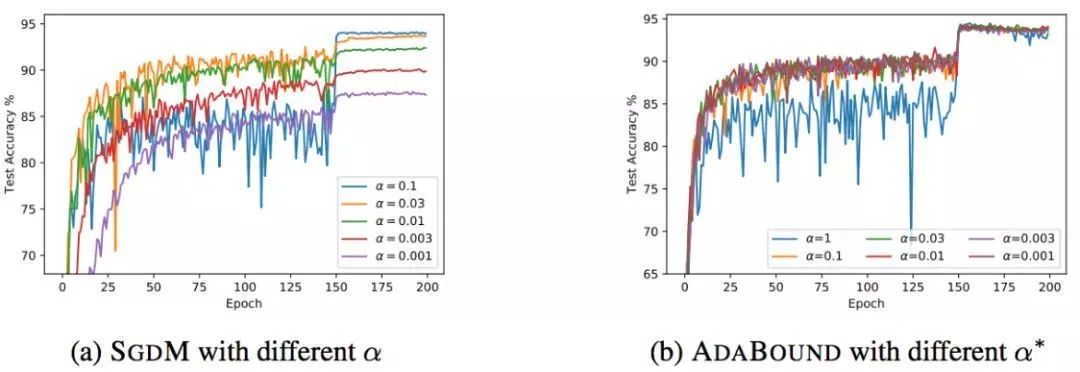
另外,這種方法相對(duì)于SGD對(duì)超參數(shù)的變化不是那么敏感,也就是說(shuō)魯棒性更好。但是,針對(duì)不同的問(wèn)題還是需要調(diào)節(jié)超參數(shù)的,只是所用的時(shí)間可能變少了。
當(dāng)然,AdaBound還沒(méi)有經(jīng)過(guò)普遍的檢驗(yàn),也有可能只是對(duì)于某些問(wèn)題效果好。
使用方法如下:安裝AdaBound
pipinstalladabound
使用AdaBound(和其他PyTorch optimizers用法一致)
optimizer=adabound.AdaBound(model.parameters(),lr=1e-3,final_lr=0.1)
AutoAugment
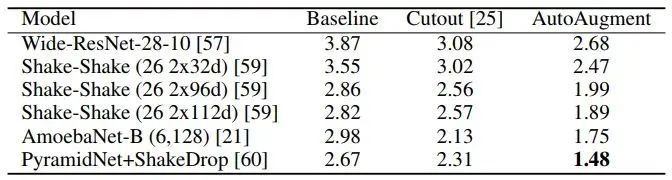
數(shù)據(jù)增強(qiáng)在圖像分類問(wèn)題上有很重要的作用,但是增強(qiáng)的方法有很多,并非一股腦地用上所有的方法就是最好的。那么,如何選擇最佳的數(shù)據(jù)增強(qiáng)方法呢?AutoAugment[11]就是一種搜索適合當(dāng)前問(wèn)題的數(shù)據(jù)增強(qiáng)方法的方法。該方法創(chuàng)建一個(gè)數(shù)據(jù)增強(qiáng)策略的搜索空間,利用搜索算法選取適合特定數(shù)據(jù)集的數(shù)據(jù)增強(qiáng)策略。此外,從一個(gè)數(shù)據(jù)集中學(xué)到的策略能夠很好地遷移到其它相似的數(shù)據(jù)集上。
AutoAugment在cifar10上的表現(xiàn)如下表,達(dá)到了98.52%的準(zhǔn)確率。
其他經(jīng)典的tricks
常用的正則化方法為
Dropout
L1/L2正則
Batch Normalization
Early stopping
Random cropping
Mirroring
Rotation
Color shifting
PCA color augmentation
...
其他
Xavier init[12]
...
審核編輯:彭靜
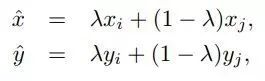
-
圖像分割
+關(guān)注
關(guān)注
4文章
182瀏覽量
17995 -
模型
+關(guān)注
關(guān)注
1文章
3226瀏覽量
48809 -
計(jì)算機(jī)視覺(jué)
+關(guān)注
關(guān)注
8文章
1698瀏覽量
45976
原文標(biāo)題:其他經(jīng)典的tricks
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于多通道分類合成的SAR圖像分類研究
基于Brushlet和RBF網(wǎng)絡(luò)的SAR圖像分類
Programming Tricks for Higher Conversion Speeds Utilizing De
圖像分類的方法之深度學(xué)習(xí)與傳統(tǒng)機(jī)器學(xué)習(xí)
基于顯著性檢測(cè)的圖像分類算法
簡(jiǎn)單好上手的圖像分類教程!
如何利用機(jī)器學(xué)習(xí)思想,更好地去解決NLP分類任務(wù)

針對(duì)遙感圖像場(chǎng)景分類的多粒度特征蒸餾方法

關(guān)于深度學(xué)習(xí)圖像分類不得不說(shuō)的技巧詳解
文本分類任務(wù)的Bert微調(diào)trick大全
跨圖像關(guān)系型KD方法語(yǔ)義分割任務(wù)-CIRKD
一種對(duì)紅細(xì)胞和白細(xì)胞圖像分類任務(wù)的主動(dòng)學(xué)習(xí)端到端工作流程
計(jì)算機(jī)視覺(jué)的5大核心任務(wù)是什么?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論