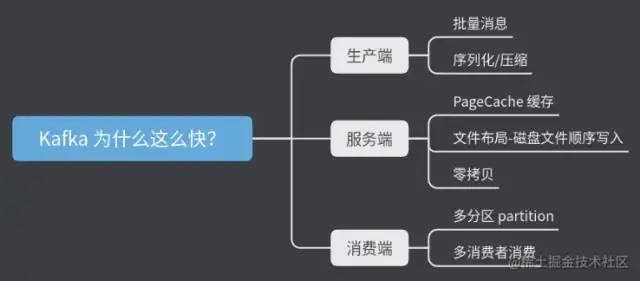
 Kafka如何做到那么高的性能
Kafka如何做到那么高的性能
有人說:他曾在一臺配置較好的機子上對 Kafka 進行性能壓測,壓測結果是 Kafka 單個節點的極限處理能力接近每秒 2000萬 條消息,吞吐量達到每秒 600MB。
那 Kafka 為什么這么快?如何做到這個高的性能?
本篇文章主要從這 3 個角度來分析:
生產端
服務端 Broker
消費端
先來看下生產端發送消息,Kafka 做了哪些優化?
(1)生產端 Producer
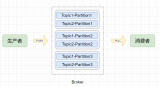
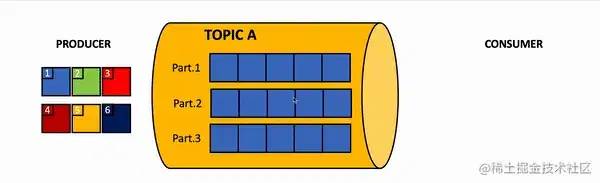 partition寫入與消費
partition寫入與消費
先來回顧下 Producer 生產者發送消息的流程:
首先指定消息發送到哪個 Topic。
選擇一個 Topic 的分區 partitiion,默認是輪詢來負載均衡。
也可以指定一個分區 key,根據 key 的 hash 值來分發到指定的分區。
也可以自定義 partition 來實現分區策略。
找到這個分區的 leader partition。
與所在機器的 Broker 的 socket 建立通信。
發送 Kafka 自定義協議格式的請求(包含攜帶的消息、批量消息)。
將思緒集中在消息發送時候,可發現這兩個華點:批量消息和自定義協議格式。
批量發送:減少了與服務端 Broker 處理請求的次數,從而提升總體的處理能力。
調用 send() 方法時,不會立刻把消息發送出去,而是緩存起來,選擇恰當時機把緩存里的消息劃分成一批數據,按批次發送給服務端 Broker。
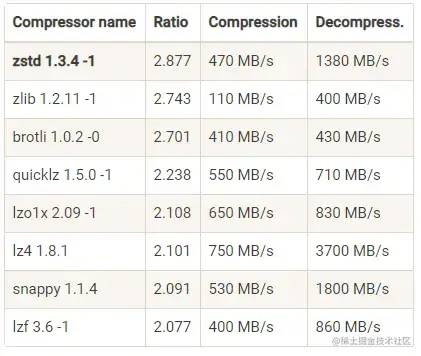
自定義協議格式:序列化方式和壓縮格式都能減少數據體積,從而節省網絡資源消耗。
各種壓縮算法對比:
吞吐量方面:LZ4 > Snappy > zstd 和 GZIP
壓縮比方面:zstd > LZ4 > GZIP > Snappy
(2)服務端 Broker
Broker 的高性能主要從這 3 個方面體現:
PageCache 緩存
Kafka 的文件布局 以及 磁盤文件順序寫入
零拷貝 sendfile:加速消費流程
下面展開講講。
1)PageCache 加速消息讀寫
使用 PageCache 主要能帶來如下好處:
寫入文件的時候:操作系統會先把數據寫入到內存中的 PageCache,然后再一批一批地寫到磁盤上,從而減少磁盤 IO 開銷。
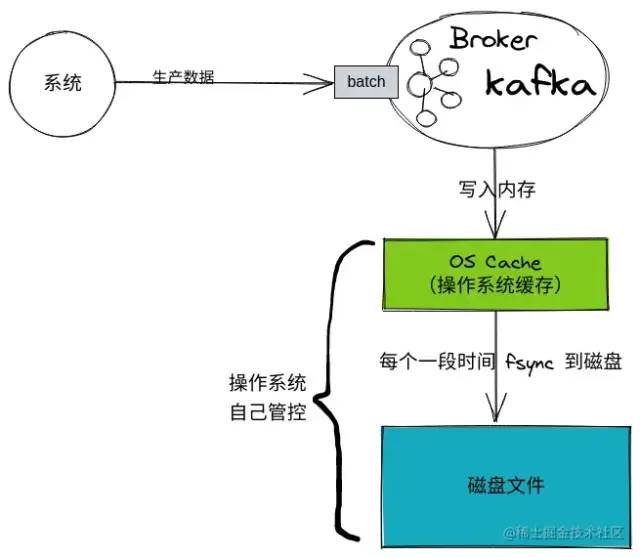 數據寫入
數據寫入
讀取文件的時候:也是從 PageCache 中來讀取數據。
如果消息剛剛寫入到服務端就會被消費,按照 LRU 的“優先清除最近最少使用的頁”這種策略,讀取的時候,對于這種剛剛寫入的 PageCache,命中的幾率會非常高。
2)Kafka 的文件布局 以及 磁盤文件順序寫入
文件布局如下圖所示:

主要特征是:文件的組織方式是“topic + 分區”,每一個 topic 可以創建多個分區,每一個分區包含單獨的文件夾。
Kafka 在分區級別實現文件順序寫:即多個文件同時寫入,更能發揮磁盤 IO 的性能。
相對比 RocketMQ: RocketMQ 在消息寫入時追求極致的順序寫,所有的消息不分主題一律順序寫入 commitlog 文件, topic 和 分區數量的增加不會影響寫入順序。
弊端: Kafka 在消息寫入時的 IO 性能,會隨著 topic 、分區數量的增長先上升,后下降。
所以使用 Kafka 時,要警惕 Topic 和 分區數量。
3)零拷貝 sendfile:加速消費流程
當不使用零拷貝技術讀取數據時:
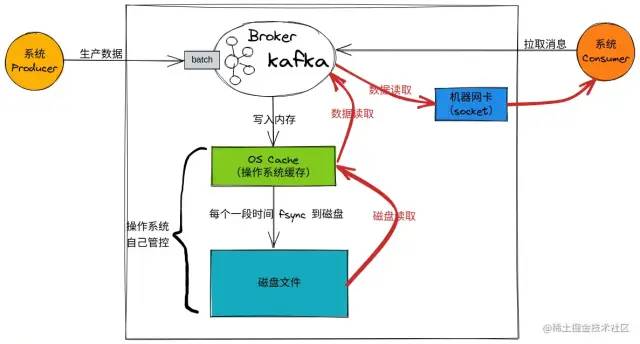 數據讀取
數據讀取
流程如下:
消費端 Consumer:向 Kafka Broker 請求拉取消息
Kafka Broker 從 OS Cache 讀取消息到 應用程序的內存空間:
若 OS Cache 中有消息,則直接讀取
若 OS Cache 中無消息,則從磁盤里讀取
再通過網卡,socket 將數據發送給 消費端Consumer
當使用零拷貝技術讀取數據:
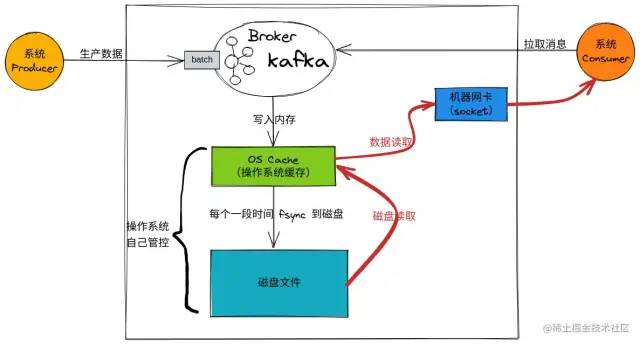 數據讀取2
數據讀取2
Kafka 使用零拷貝技術可以把這個復制次數減少一次,直接從 PageCache 中把數據復制到 Socket 緩沖區中。
這樣不用將數據復制到用戶內存空間。
DMA 控制器直接完成數據復制,不需要 CPU 參與,速度更快。
(3)消費端 Consumer
消費者只從 Leader分區批量拉取消息。
為了提高消費速度,多個消費者并行消費比不可少。Kafka 允許創建消費組(唯一標識 group.id),在同一個消費組的消費者共同消費數據。
舉個栗子:
有兩個 Kafka Broker,即有 2個機子
有一個主題:TOPICA,有 3 個分區(0, 1, 2)
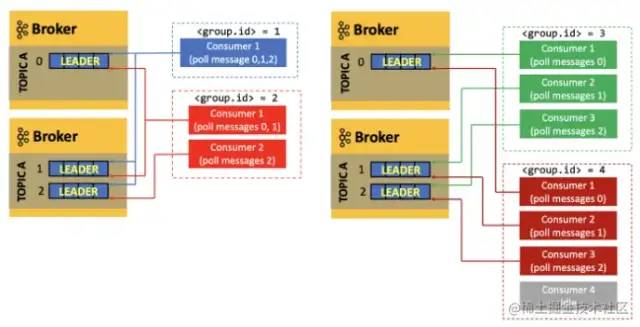
如上圖,舉例 4 中情況:
group.id = 1,有一個消費者:這個消費者要處理所有數據,即 3 個分區的數據。
group.id = 2,有兩個消費者:consumer 1消費者需處理 2個分區的數據,consumer2 消費者需處理 1個分區的數據
group.id = 3,有三個消費者:消費者數量與分區數量相等,剛好每個消費者處理一個分區
group.id = 4,有四個消費者:消費者數量 > 分區數量,第四個消費者則會處于空閑狀態
-
數據
+關注
關注
8文章
7002瀏覽量
88943 -
壓縮
+關注
關注
2文章
102瀏覽量
19373 -
kafka
+關注
關注
0文章
51瀏覽量
5216
原文標題:Kafka 為什么那么快?
文章出處:【微信號:AndroidPush,微信公眾號:Android編程精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
kafka設計原理的深度探討
請問I/Q demodulator如何做到頻率與相位的同步?
基于閃存存儲的Apache Kafka性能提升方法
小間距LED如何做到低亮高灰
Kafka的概念及Kafka的宕機
探究Kafka宕機引發的高可用問題
Kafka 的簡介






 工商網監
工商網監
評論