


一、“光計算”背景
現如今,“大數據”(Big Data)時代提供了海量的數據,人工智能(artificial intelligence,AI)在自動駕駛,智能教育,語音識別等領域中的應用越來越廣泛。人工神經網絡(Artificial Neural Network,ANN)算法相關的機器學習(Machine Learning,ML)技術,作為AI領域中重要的計算模型,為AI的發展提供了動力,推動人類社會進入智能化時代。
但人工神經網絡強烈依賴于矩陣乘法,其訓練和推理過程本質上是對矩陣參數進行調制、優化后與外界傳輸的數據進行數學乘法。但在目前,隨著神經網絡的規模不斷擴大(深度學習模型的規模每3.5個月就翻一番),訓練量也不斷增大,需要更密集的矩陣計算,因而對算力的需求正在以驚人的速度增長。
圖1 人工智能應用場景
圖2 神經網絡架構示意圖
而現階段應用于神經網絡的商用硬件主要包括兩類:一類是通用芯片,如中央處理器(CentralProcessing Unit,CPU)、圖形處理單元(GraphicProcessing Unit, GPU)等;另一類是一些神經網絡加速器如張量處理單元(TensorProcessing Unit, TPU)和可編程門陣列(FieldProgrammable Gate Array, FPGA)等。
最初,普遍采用通用芯片(CPU)進行矩陣運算,然而隨著需要計算的數據量的不斷增長,由于CPU算術邏輯單元(Arithmeticand Logic Unit,ALU)的面積較小,并且CPU自身的邏輯運算和控制電路也較為復雜,因而導致CPU已無法支撐大數據量帶來的大量重復性的矩陣乘法運算。因而主流硬件廠商開始將注意力轉向GPU:GPU采用的是流處理的方式,利用空間并行性,可以大大提高運算速度。
但隨著GPU的不斷迭代,其運算速度已經進入了萬億次每秒(Teraflop)的范圍,也已接近其理論極限。為了進一步提高硬件的算力,各大廠商開始了對神經網絡加速器的研究。2016年,谷歌推出了TPU,采用了片上內存以及脈動陣列設計,可在8位低精度下進行整數運算,相比于GPU具有更高的計算速度和更低的能耗。此外,在2017年,Intel也推出了面向數據中心的FPGA加速產品,可根據本身需求進行編程。
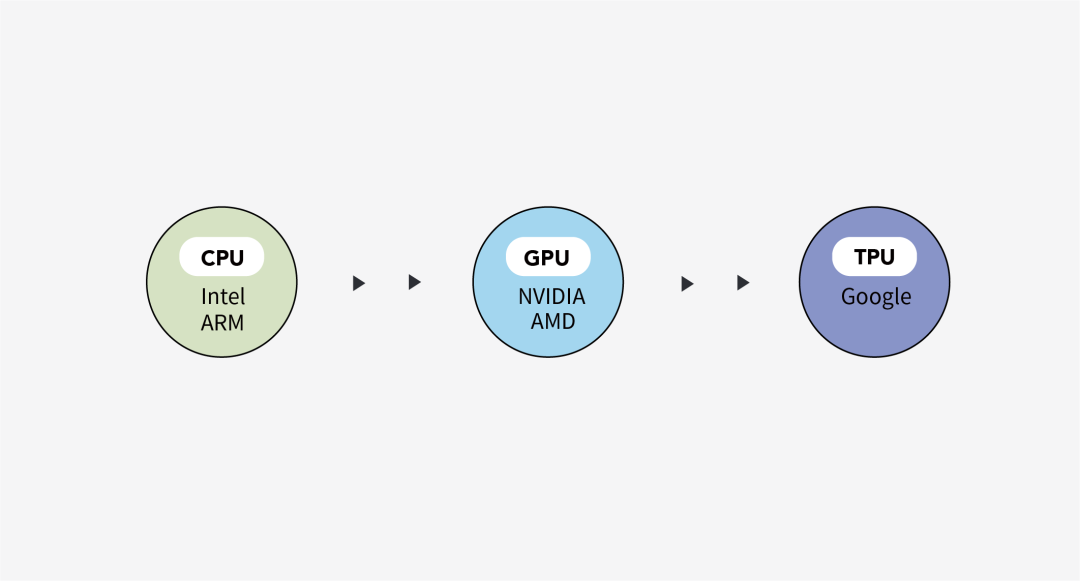
圖3 典型的商用硬件
但是,上述這些架構全部基于傳統的微電子芯片,隨著工藝技術向工藝尺寸的極限逼近,芯片的集成度不斷增加,“摩爾定律”將不再適用,即很難通過提升集成度提升芯片性能。另外,由于目前的電子計算硬件采用的處理器的邏輯單元和存儲單元是分立的馮·諾依曼(VonNeumann)結構,這種結構存在馮·諾依曼“瓶頸”(vonNeumann bottleneck),即:當算力達到一定量級時,訪問存儲單元的速度遠遠小于邏輯單元處理數據的速度,即使采用多核并行架構也無法突破速度的極限。
二、“電”向“光”的轉變
為了突破電子芯片的一系列弊端,相關研究者們開始考慮從“電”向“光”的轉化,利用光子(photon)作為硬件的載體,用光計算去代替傳統電子計算中的計算密集型操作,從而提高算力,降低能耗。
光可以來做載體主要是因為其有以下優勢:首先,光子是玻色子,其物理特性決定了其不易被擾動;而電子是費米子,容易被擾動。其次,光信號具有高速率的特點,可以保證足夠高的計算速度,幾乎沒有延遲。此外,光波可以通過時間、空間、波長、偏振、模式進行復用,提供天然的并行計算能力。最后,光學器件(尤其是無源器件),幾乎不消耗任何能量,解決了困擾高性能計算的能耗問題。
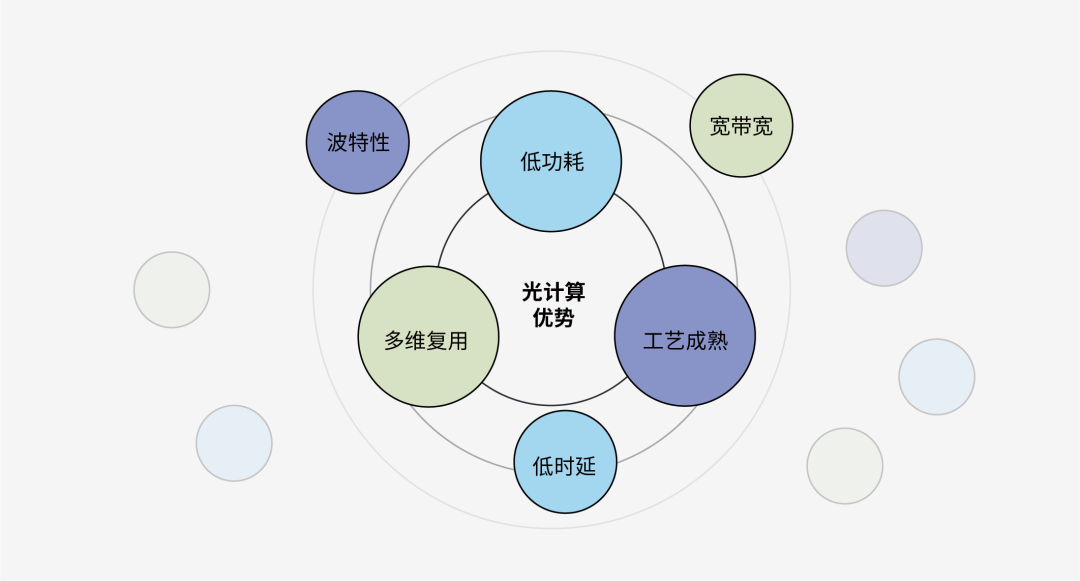
圖4 光計算的主要優勢
三、全光 VS 光電混合
目前,根據神經元內信號的物理表現,光作為硬件的載體的方式可分為兩大類:光-電-光(光電混合)與全光。
全光的方式即依賴于許多材料中出現的半導體載流子或光敏性,不涉及將神經元信號表表示為電流的過程。例如,德國明斯特大學Feldmann 在2019年提出了一種包含140個相變微環光開關的神經網絡結構,可實現簡單的英文字母識別。但從目前來看,相變材料自身通常有一定的使用壽命限制,從而導致該硬件難以長期工作;并且相變材料通常對應的響應速度也較慢,難以實現足夠高的計算速度;除此之外,利用光敏性的實現也存在著一系列問題。總的來說,由于光學元件的精度要求大,進行邏輯運算成本也高,在處理信號的方面沒有電信號來得方便,這些限制了全光運算的發展,導致全光難以取代電成為計算硬件的主流。
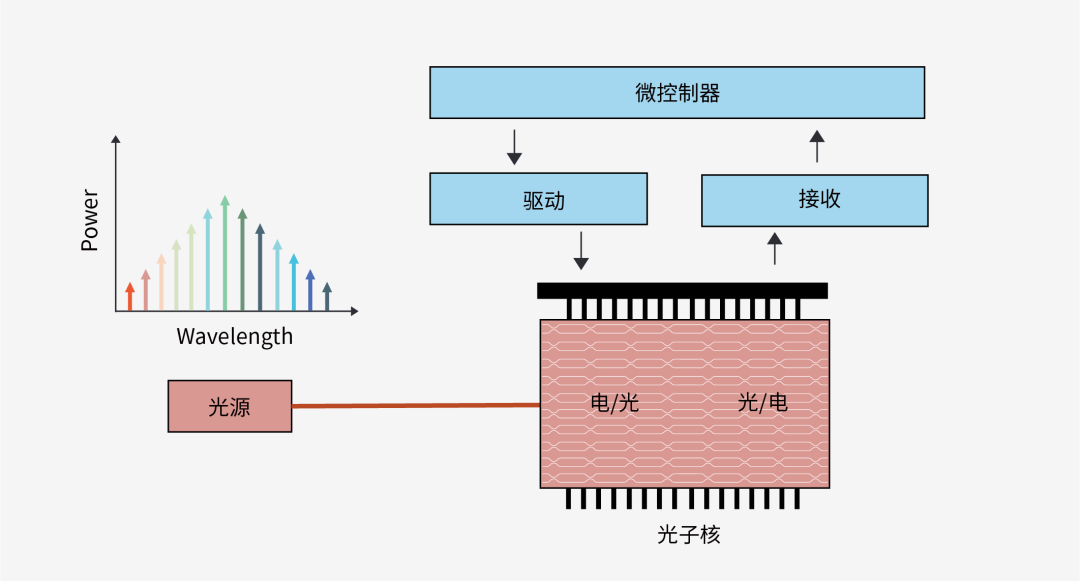
圖5 光電混合計算示意圖
而光電混合計算更像是取光和電兩者所長的結果。舉例來說,一個具體的實現方式是保持輸入數據仍然是數字信號,首先用數模轉換器轉成模擬電信號去驅動光芯片上的光調制器,矩陣計算則是用光信號完成,之后的非線性運算則需把光信號再轉回到數字信號進行。事實上,雖然這樣的來回光電信號切換增加了功耗,但對于光芯片內的距離來說,光損耗幾乎可以忽略不計。因此,光連接中不存在像電連接中與每個連接長度成正比的能量成本,而是預先耗費從電領域轉換到光領域再返回的能量成本,因而只要E/O/E轉換的成本低于在相同距離上給金屬線充電的成本,光電混合計算就能在效率上擊敗電計算。綜上所述,現階段的商用硬件,光電混合計算仍是最佳選擇。
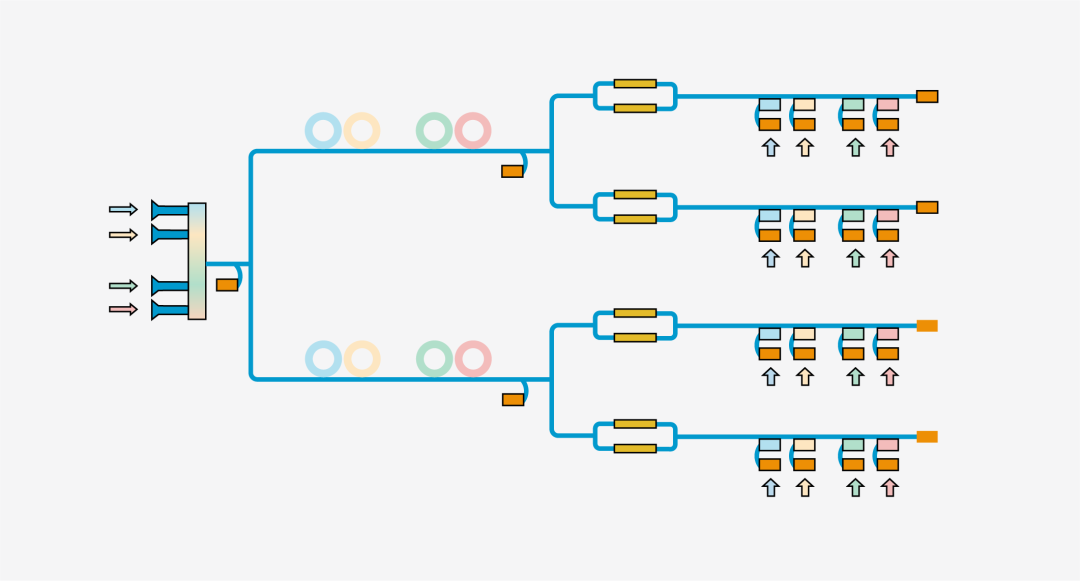
圖6 光子核架構示意圖
四、硅基光電子計算
而要具體實現光電混合計算,首先要考慮光芯片的平臺。傳統光電子芯片主要基于InP等三五族平臺,而大部分微電子器件基于硅的平臺,如果要把這些不同材料平臺的器件集成到一起往往是非常困難的。因此,相關研究者們再次將目光投向了在微電子領域并取得了成功——具有一系列優勢的硅材料:首先,硅材料的地表儲存量十分巨大,其材料成本十分低廉;其次,硅材料的折射率較大(約為3.5左右),可以獲得更小的彎曲半徑以實現結構非常緊湊的集成光學器件;此外,硅材料的機械性能、耐高溫能力非常好,便于各種加工和封裝。最后,最重要的是相比于傳統的三五族器件,集成度更好,并且與互補金屬氧化物半導體(COMS)工藝兼容。
目前,硅基光電子技術不斷發展。國內外眾多高校和企業都在研究硅基光子學,并在技術優勢和現實需求的推動下,許多高性能的光學關鍵器件:波導(Waveguide)、光耦合器(Coupler)、偏振分束器、模式轉換器、高速電光調制器、濾波器(Filter)、鍺探測器、光開關均有報道,其中大部分部件的性能已經達到甚至超過同期商業化的產品,為商用光電混合計算的實現提供了先決條件,進而將由電芯片和硅光芯片通過2.5D或3D封裝堆疊組成光電混合計算的硬件推向市場。
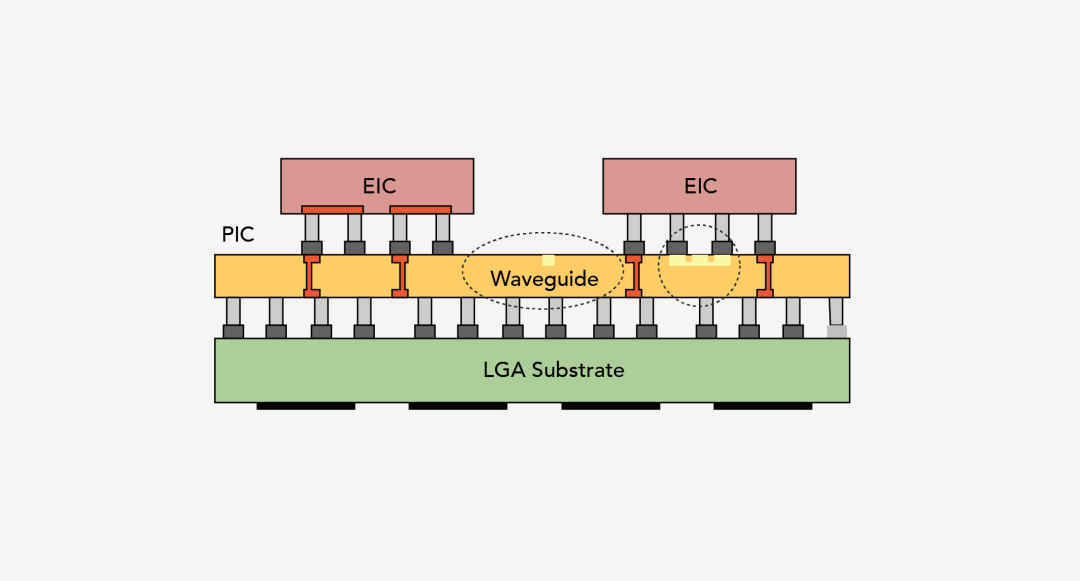
圖7 硅基光電計算封裝示意圖
總結來說,硅基光電混合技術既利用了光技術的優點,同時又可以結合電領域的技術進行數據處理,最終實現在提升計算速度的同時也可以降低運行功耗。而在未來的發展過程中,硅基光電子混合集成芯片一定會為人工智能領域以及計算硬件帶來重大的產業升級。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
104299 -
硬件
+關注
關注
11文章
3496瀏覽量
67724 -
人工智能
+關注
關注
1810文章
49188瀏覽量
251158
原文標題:“曦”科技|計算范疇下硅光的優勢
文章出處:【微信號:曦智科技,微信公眾號:曦智科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
注塑PEEK光伏接線盒的高性能與工藝優勢

GPU加速計算平臺的優勢
光伏電站智能運維管理系統的作用與優勢





 工商網監
工商網監

評論