 自然語言處理(NLP)領域的高效方法
自然語言處理(NLP)領域的高效方法
訓練越來越大的深度學習模型已經成為過去十年的一個新興趨勢。如下圖所示,模型參數量的不斷增加讓神經網絡的性能越來越好,也產生了一些新的研究方向,但模型的問題也越來越多。
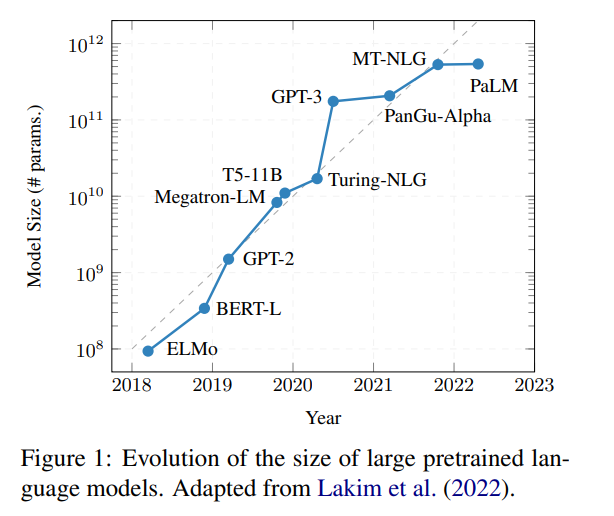
首先,這類模型往往有訪問限制,沒有開源,或者即使開源,仍然需要大量的計算資源來運行。第二,這些網絡模型的參數是不能通用的,因此需要大量的資源來進行訓練和推導。第三,模型不能無限擴大,因為參數的規模受到硬件的限制。為了解決這些問題,專注于提高效率的方法正在形成一種新的研究趨勢。
近日,來自希伯來大學、華盛頓大學等多所機構的十幾位研究者聯合撰寫了一篇綜述,歸納總結了自然語言處理(NLP)領域的高效方法。
效率通常是指輸入系統的資源與系統產出之間的關系,一個高效的系統能在不浪費資源的情況下產生產出。在 NLP 領域,我們認為效率是一個模型的成本與它產生的結果之間的關系。
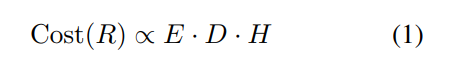
方程(1)描述了一個人工智能模型產生某種結果(R)的訓練成本(Cost)與三個(不完備的)因素成正比:
(1)在單個樣本上執行模型的成本(E);
(2)訓練數據集的大小(D);
(3)模型選擇或參數調整所需的訓練運行次數(H)。
然后,可以從多個維度衡量成本 Cost(·) ,如計算、時間或環境成本中的每一個都可以通過多種方式進一步量化。例如,計算成本可以包括浮點運算(FLOPs)的總數或模型參數的數量。由于使用單一的成本指標可能會產生誤導,該研究收集和整理了關于高效 NLP 的多個方面的工作,并討論了哪些方面對哪些用例有益。
該研究旨在對提高 NLP 效率的廣泛方法做一個基本介紹,因此該研究按照典型的 NLP 模型 pipeline(下圖 2)來組織這次調查,介紹了使各個階段更高效的現有方法。
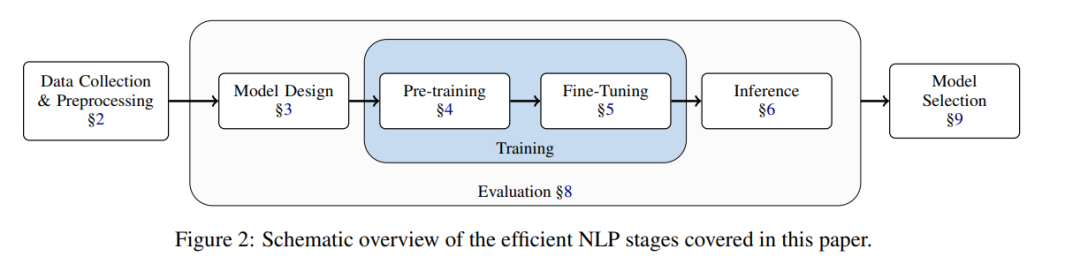
這項工作給 NLP 研究人員提供了一個實用的效率指南,主要面向兩類讀者:
(1)來自 NLP 各個領域的研究人員,幫助他們在資源有限的環境下工作:根據資源的瓶頸,讀者可以直接跳到 NLP pipeline 所涵蓋的某個方面。例如,如果主要的限制是推理時間,論文中第 6 章描述了相關的提高效率方法。
(2)對改善 NLP 方法效率現狀感興趣的研究人員。該論文可以作為一個切入點,為新的研究方向尋找機會。
下圖 3 概述了該研究歸納整理的高效 NLP 方法。
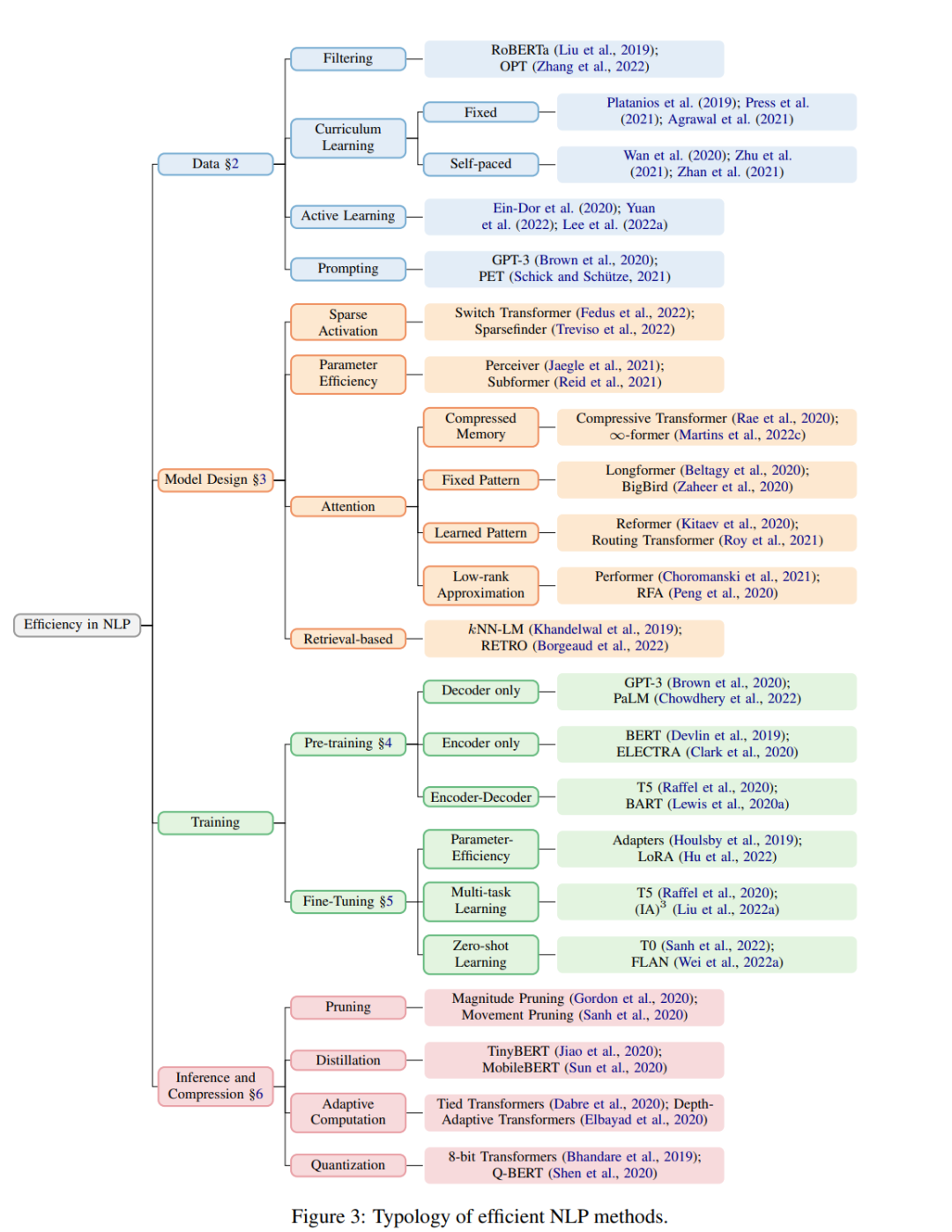
此外,雖然硬件的選擇對模型的效率有很大的影響,但大多數 NLP 研究者并不能直接控制關于硬件的決定,而且大多數硬件優化對于 NLP pipeline 中的所有階段都有用。因此,該研究將工作重點放在了算法上,但在第 7 章中提供了關于硬件優化的簡單介紹。最后,該論文進一步討論了如何量化效率,在評估過程中應該考慮哪些因素,以及如何決定最適合的模型。
-
網絡模型
+關注
關注
0文章
44瀏覽量
8444 -
自然語言
+關注
關注
1文章
288瀏覽量
13359 -
nlp
+關注
關注
1文章
489瀏覽量
22052
原文標題:資源受限如何提高模型效率?一文梳理NLP高效方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是自然語言處理_自然語言處理常用方法舉例說明






 工商網監
工商網監
評論