 預訓練模型在搜索中使用的思路和方案
預訓練模型在搜索中使用的思路和方案
當然了,和往常的文章一樣,我不會復述這一篇文章,而是聊聊里面的一些關鍵點和一些有意思的內容,拿出來和大家討論一下。
搜索的常規結構
有關搜索的結構,其實在很多之前的文章都已經有聊過,這里再借這篇文章聊聊吧,直接上圖:
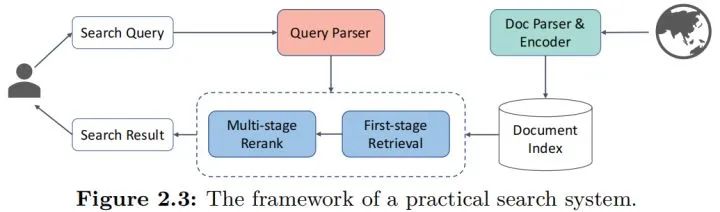
先從左邊開始,是用戶視角的處理流程,用戶輸入檢索query后,需要經過一系列的預處理和解析,包括以前常說的意圖識別,在這個圖里都算入parser中,經過預處理后,就會進入常規的信息檢索流程,現在的主流就是“檢索+召回”的模式,即先從庫里面找出一整批比較接近的,然后經過一定的排序模型對這些結果進行排序,最終給出搜索結果。
而從右邊開始,是各種文檔,或者說物料的輸入到入庫的流程,Parser和Encoder就是預處理和編碼的流程,然后就可以入庫了,這里用“index”就是一個索引的過程,索引本身是一個協助檢索加速的過程,有了索引能讓檢索過程變得足夠快,畢竟用戶視角的檢索速度不能因為庫很大而被降低,這其實是搜索里面非常重要的問題了,因和本文無關這個點到為止。
因此,其實要算法工作的地方,其實就這幾個:
Query Parser,即query預處理和理解部分,需要通過算法的方式對query進行解析。
Retrieval,即檢索部分,從庫里面粗篩出可能對的結果的部分。
Rerank,即排序部分,這里涉及的就是排出最優的結果有限放到用戶面前的過程。
Doc Parser&Encoder,即對文檔處理的部分,什么樣的解析和表征能更好地入庫檢索的同時,更快更準地被Retrieval找到。
Retrieval
所謂的檢索,其實就是輸入用戶query,然后從庫里面找到和query最相關的TOPN的結果的這個過程,而一般地,主要是3種情況,按照論文的說法:
sparse,稀疏型,其實就是經典的全匹配的形式,我理解是因為onehot化后其實就是稀疏的所以這么說吧。
dense,稠密型,說白了就是我們常說的向量表征后用ANN的方式來進行查詢的方法。
綜合型,就是綜合上述兩者來進行的操作。
首先聊聊sparse型吧,這應該是前一個階段比較流行的方案了,但是現在仍方興未艾。在預訓練的使用上,則更聚焦在稀疏型特征的更精準地抽取上,例如上游意圖識別的處理(這個其實放在了后續的章節里),或者是在詞權重問題上的進一步優化(term-weighting),這些其實在比較老的階段已經有一些比較優秀的方案,但是換上預訓練模型后,確實有不小的提升,同時從系統層面,系統的迭代升級,直接更換模型會比較方便,風險低而且可控性高,確實是大家更容易想到的手段了。
而dense型,對應的就是我們說的語義向量召回,別以為只是把表征模塊換成預訓練模型那么簡單(如SBERT),其實還有很多花樣,我來列舉一下:
單向量表征和多向量表征,即在計算相似度的時候是用一個向量還是多個向量,這種用多個向量的其實并不少見,至少在論文里。
專門為了向量檢索而設計的預訓練模型和任務,也可以說是Further pretrain或者是fine-tuning的一種思路。
難負例的挖掘和使用的探索,這方面在排序階段也有提及,屬于語義相似度上的老問題了。
而綜合型,則是一些統一考慮兩種類型特征,一起使用的方案,本質上研究的是這兩種信息的融合方式,同時也是在探索兩者的分工和地位,例如有的研究是讓預訓練模型擬合BM25后的殘差,有的研究這是考慮復雜的融合。
Rerank
排序也是搜索中非常重要的部分,要最終的結果足夠準,排序肯定是更為關鍵的一環,甚至更為極端的,很多搜索在架構上,設計的排序模塊是多層多元的,和推薦類似,所以更多大家會叫reranker,這個點到為止,回到排序本身,而常見的,模型在排序側,尤其是預訓練模型的使用上,會有兩種形式:
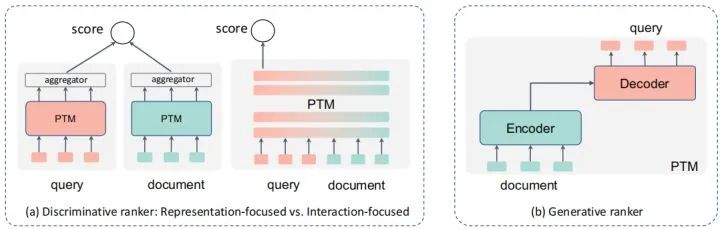
判別式,即直接用類似分類的方式,直接給出query對各個doc的打分,選下圖種中間的那個形式。
生成式,假設文檔和query中間存在一個生成的過程,通過刻畫文檔->query或相反的過程來判斷兩者的相似關系。
判別式排序
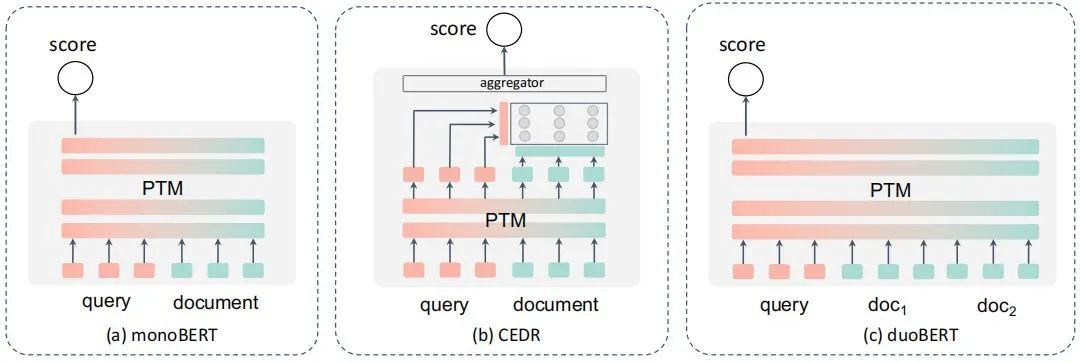
先聊聊前者,這個大家也比較熟悉,說白了就是直接通過分類的方式來計算得分,按照論文的總結,應該就是這幾個形式,在NLP里,更多其實可以理解為交互式的語義相似度計算吧,但是由于一對多的存在,所以演化了更多的形式:
而與常規的NLP不同的是,搜索還需要面臨這些問題:
長文本問題,雖然query大都還比較短,但是doc很少是短文本了,因此有了一些類似BERT-firstP、BERT-sumP之類選擇最優段落等的一些方案和PARADE等的一些用來聚合全文信息再來計算的方案。
性能問題。多個文檔和query都要計算匹配度,性能扛不住,所以有了一些類似延遲交互、蒸餾、動態建模的方案。
生成式排序
然后聊聊生成式排序模型,思路上就是這個形式:
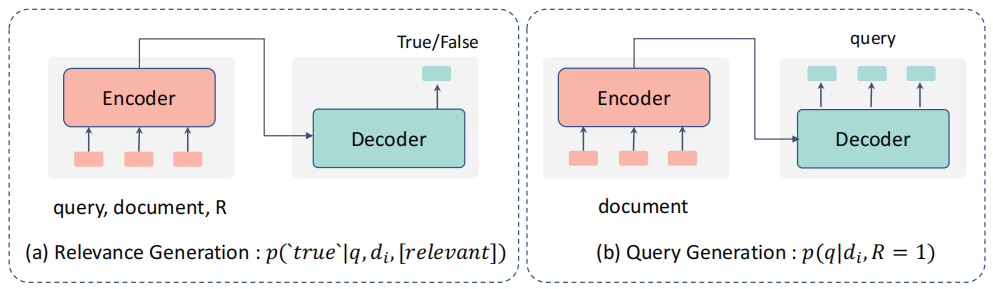
前者是把query和doc都輸入文本,生成True/False的結果,個人感覺其實和上面的判別型多少有些類似,只是解釋的視角不同吧,后者則是借助Doc生成Query的方式,隨后用條件概率來判斷兩者的相關性。
混合型排序
混合型排序則是混合了上述生成式和判別式方案的特點,例如通過多任務學習等的方案進行,這里不贅述了。
其他檢索相關的組件
檢索本就是一個系統,內部有大量的組件,而因此,預訓練模型也不見得只用在上面的召回和排序階段,例如query理解,這塊我自己是已經用了不少了,例如分類、實體抽取等,當然還有論文里提到的query拓展改寫,和其他的特征,這些是query側的,而物料側,則有很多類似文本摘要之類的方案,論文里面也有不少,大家可以看看拓展下思路。
檢索專用預訓練方案
要讓預訓練方案在特定場景表現更好,肯定離不開對這個場景適配的一些研究,甚至有一些針對對話場景的預訓練技術,首先是預訓練任務的設計,讓預訓練模型能更好適配檢索任務,例如ICT從論文中隨機采樣一句話來和剩余句子進行匹配,這些思路的核心其實就是強調預訓練模型對query-doc這種信息匹配類任務的理解能力;另一方面,就是一些比較大膽的,對Transformer結構的調整,例如在淺層先隔離q和d之間的關系,后續再來聯合的預訓練結構,算是一種思路的拓展吧。
自己的一些其他的想法
全文給我的收獲其實挺大的,能在論文里看到很多有關預訓練模型在搜索中使用的思路和方案,這些也打開了我的思路。但是感覺還有不少問題可能還有待進一步的探索和研究吧,也是自己比較關注和研究的,當然這些也比較實踐化,科研視角可能很難關心到。
目前的論文方案似乎都是把整個檢索系統割裂來看的,即任務拆解后,逐一優化實現的,小到term-weight問題,達到召回和排序的問題,但是對于一個系統,將預訓練模型集成到系統中的時候,有很多問題需要考慮,我舉幾個例子:
一個系統這么多任務,每個都布一個預訓練模型,系統能支撐嗎?這時候的性能優化,就不只是優化一個算法一個任務這么簡單了,而是一個系統問題。
什么位置上預訓練模型對端到端結果收益會更高。
上游計算預訓練的中間信息,有沒有可能用到下游,產生新的提升,即有沒有可能“一肉多吃”。(這個其實論文里有提,具體論文也有看到,感覺是個方向吧)
再者,表面上看這些任務是對應到了檢索系統,但是多少還是沒有離開預訓練所固有的NLP場景,有些搜索的特定特征或者這種信息,并沒有考慮引入到模型中,如有點率、點擊量等,都沒有考慮到融合預訓練模型中,說白了,其實還是只是考慮了文檔和Query之間語義的相關性而已,沒有考慮更多更復雜的信息匹配,而這些信息其實在現實應用中也必不可少,例如“最新消息”之類的query,是和時效性有關的,本身和語義關系真不大,這個例子可能有些極端了,但是在一個相對綜合的系統中,確實是個不能忽略的重要問題。
小結
當然了,文章中還有很多內容我沒有提到,例如現有數據集和對應的sota,大家可以根據自己的興趣在論文里看,另外對于自己感興趣的部分,作者都有列出出處,大家可以進一步深入閱讀,很久前就和大家說過讀綜述的好處就是能快速理解一個方向比較全面的研究現狀,也能把握住一些研究熱點和前沿,所以非常建議大家精讀,我花了一個中秋節假期的事件來看,感覺收獲不小,希望也對大家有用吧。
-
編碼
+關注
關注
6文章
957瀏覽量
54911 -
nlp
+關注
關注
1文章
489瀏覽量
22068 -
訓練模型
+關注
關注
1文章
36瀏覽量
3878
原文標題:綜述 | 預訓練模型在信息檢索中的應用
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于不同量級預訓練數據的RoBERTa模型分析
【大語言模型:原理與工程實踐】大語言模型的預訓練
為什么要使用預訓練模型?8種優秀預訓練模型大盤點

2021 OPPO開發者大會:NLP預訓練大模型





 工商網監
工商網監
評論