") 基于谷歌中長尾item或user預(yù)測效果的遷移學習框架
基于谷歌中長尾item或user預(yù)測效果的遷移學習框架
推薦系統(tǒng)經(jīng)常面臨長尾問題,例如商品的分布服從冪率分布導致非常多的長尾樣本只出現(xiàn)過很少的次數(shù),模型在這部分樣本上的效果比較差。對長尾樣本增加權(quán)重,或者通過采樣的方法增加長尾樣本,又會影響數(shù)據(jù)分布,進而造成頭部樣本效果下降。針對這類問題,谷歌提出了一種可以實現(xiàn)頭部樣本知識遷移到尾部樣本的遷移學習框架,使推薦系統(tǒng)中長尾預(yù)測問題效果得到顯著提升,并且頭部的預(yù)測效果也沒有受到損失,實現(xiàn)了頭部尾部雙贏。
文中提出的遷移學習框架主要包括model-level transfer和item-level transfer。其中model-level transfer通過學習一個多樣本模型和一個少樣本模型,并學習一個二者參數(shù)的映射函數(shù),實現(xiàn)模型參數(shù)上的遷移;item-level transfer通過對模型訓練流程的優(yōu)化,讓映射函數(shù)同時能夠?qū)W到頭部item和尾部item之間的特征聯(lián)系。
1
Model-level Transfer
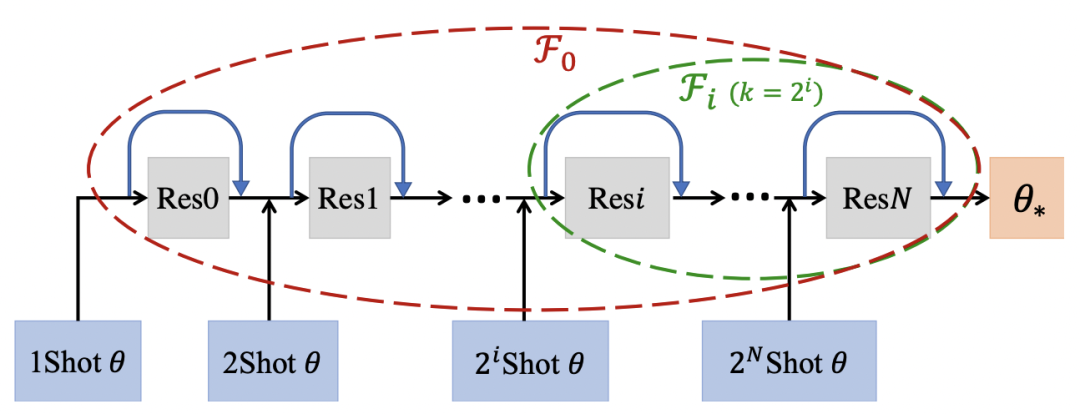
Model-level Transfer的核心思路是學習many-shot model和few-shot model的參數(shù)映射關(guān)系,這個思路最早來源于2017年NIPS上的一篇文章Learning to Model the Tail(NIPS 2017)。比如下面的例子中,living room是頭部實體,可以利用living room結(jié)合不同的樣本量,學到模型參數(shù)是如何從one-shot(theta1)變換到two-shot(theta2)一直到many-shot(theta*)。那么對于一個tail實體library,模型只能通過few-shot學到一個模型參數(shù),但是可以利用在many-shot上學到的參數(shù)變化經(jīng)驗推導出library上的參數(shù)變化。通過不斷增加數(shù)據(jù),模型參數(shù)發(fā)生變化,模型學習的是數(shù)據(jù)增強的過程如何影響了模型參數(shù)變化。
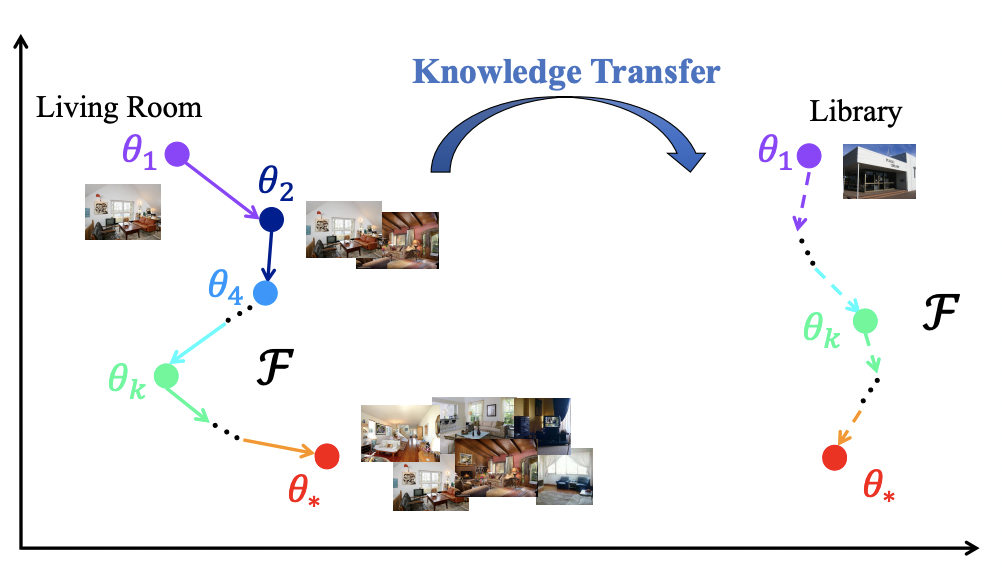
在推薦系統(tǒng)中也是同理,給定一個item和user的反饋信息,模型隱式的學習如何增加更多user的反饋信息幫助這個item的學習,也就是從少數(shù)據(jù)到多數(shù)據(jù)的模型參數(shù)變化過程。
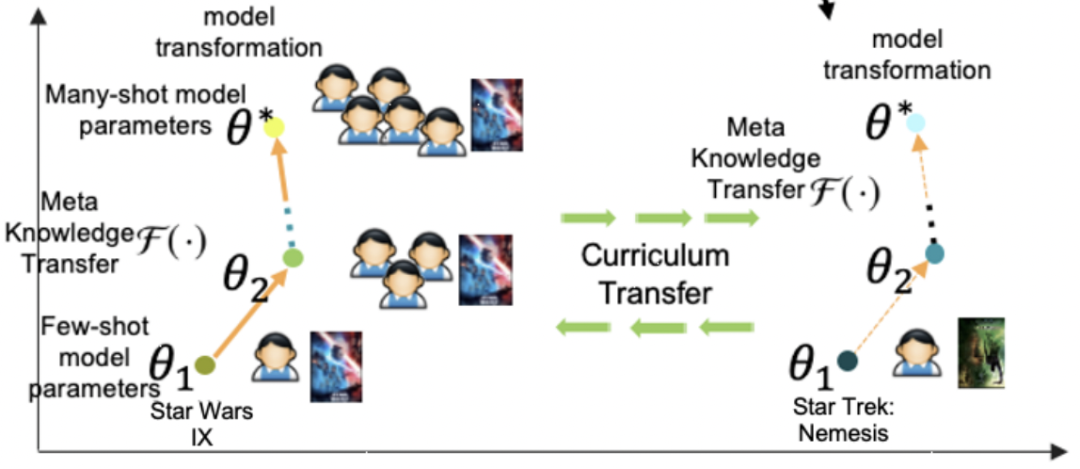
基于上述思路,本文通過一個meta-learner學習這種參數(shù)隨著shot增加的映射關(guān)系。首先構(gòu)造兩種類型的數(shù)據(jù)集,第一種數(shù)據(jù)是利用頭部商品構(gòu)造的many-shot訓練數(shù)據(jù),用來訓練一個base-learner;第二種數(shù)據(jù)是在頭部數(shù)據(jù)中進行下采樣,模擬得到的few-shot訓練數(shù)據(jù)。Meta-learner是一個函數(shù),輸入few-shot模型的參數(shù),預(yù)測出many-shot模型的參數(shù),即學習這個映射關(guān)系,損失函數(shù)如下,第一項是預(yù)測many-shot參數(shù)的損失,第二項是在few-shot數(shù)據(jù)上模型的預(yù)測效果:
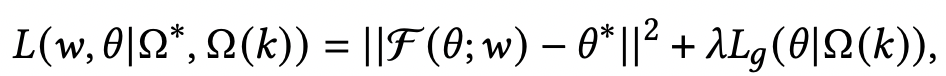
其中,本文主要優(yōu)化的部分是base-learner在user和item網(wǎng)絡(luò)中的最后一層參數(shù),因為如果學習全局參數(shù)的映射關(guān)系,計算復雜度太高。
2
量Item-level Transfer
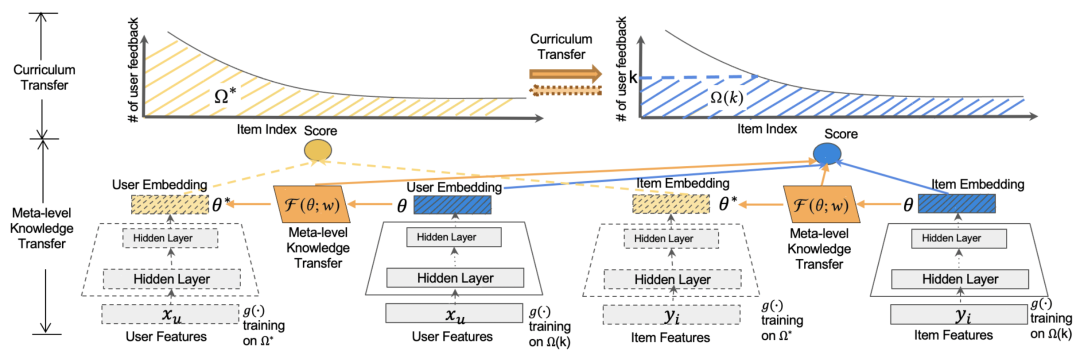
在model-level transfer中我們提到,需要構(gòu)造一個many-shot數(shù)據(jù)集和few-shot數(shù)據(jù)集。一種常用的方法是根據(jù)頭部數(shù)據(jù)(例如樣本數(shù)量大于一定閾值的)構(gòu)造many-shot數(shù)據(jù),同時利用頭部數(shù)據(jù)做下采樣構(gòu)造few-shot數(shù)據(jù)。但是在推薦系統(tǒng)中,尾部item的數(shù)量眾多,只根據(jù)頭部item這個參數(shù)的映射關(guān)系可能在尾部item上效果不好。因此本文提出了一種curriculum transfer的方法。
具體的,在數(shù)據(jù)集的構(gòu)造上,many-shot使用了包括頭部和尾部所有item的數(shù)據(jù)構(gòu)成(如上圖中的黃色區(qū)域),few-shot使用了頭部item下采樣加所有尾部item構(gòu)成(如上圖中的藍色區(qū)域)。這種方式保證了many-shot和few-shot模型在訓練過程中都能充分見到長尾樣本,提升item表示的學習效果,同時也能在few-shot訓練時,保證尾部數(shù)據(jù)的分布仍然是接近初始的長尾分布,緩解分布變化帶來的bias。同時在損失函數(shù)中,引入了logQ correction,根據(jù)樣本量平衡頭部樣本和尾部樣本對模型的影響,曾經(jīng)在Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations(2017)等論文中應(yīng)用過。
3
模型預(yù)測
在預(yù)測過程中,會融合base-learner得到的user表示,以及經(jīng)過meta-learner根據(jù)few-shot學到的參數(shù)融合到一起進行預(yù)測,通過一個權(quán)重平衡兩個表示,公式如下:
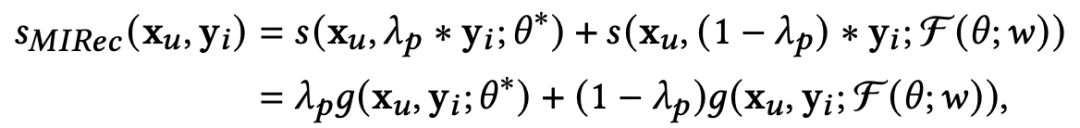
對于長尾user,也可以利用相似的方法解決。此外,文中也提出可以采用多階段的meta-learner學習方法,例如從1-shot到2-shot再到many-shot,串行學習多個meta-learner,這與Learning to Model the Tail(NIPS 2017)提供的方法比較相似。
4
實驗結(jié)果
作者在多個數(shù)據(jù)集上對比了一些解決長尾問題的方法效果,實驗結(jié)果如下表。可以看到,本文提出的MIRec方法效果要明顯好于其他方法。作者的實驗基礎(chǔ)模型是一個user側(cè)和item側(cè)的雙塔模型,具體的長尾優(yōu)化對比模型包括re-sampling類型方法(如上采樣和下采樣)、損失函數(shù)方法(如logQ校準、classbalance方法,二者思路都是在損失函數(shù)中引入不同樣本頻率加權(quán)樣本)、課程學習方法(Head2Tail,即先在全量樣本上預(yù)訓練,再在尾部樣本上finetune,Tail2Head是反過來的操作)、基于Meta-learning的方法(MeLU)。
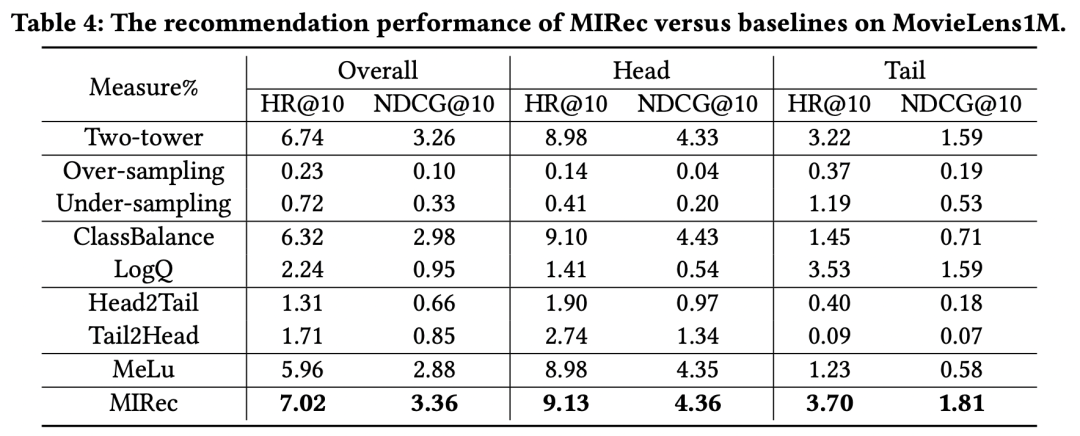
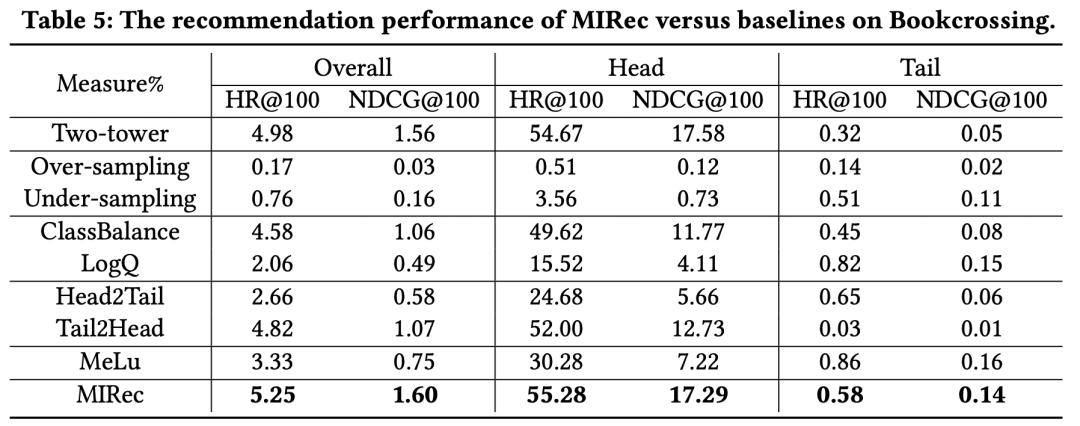
從上面的實驗結(jié)果可以看出幾個關(guān)鍵點。首先,sampling-based方法效果非常差,這主要是由于sampling改變了數(shù)據(jù)本身的分布,而推薦系統(tǒng)中,模型的效果對于數(shù)據(jù)分布是非常敏感的,使用真實分布的數(shù)據(jù)訓練效果會更好。其次,基于loss加權(quán)的方法如ClassBalance和LogQ,對于長尾的效果提升非常明顯,但是對于頭部item有明顯的負向影響。最后,MIRec在頭部和長尾都實現(xiàn)了效果提升,這是其他模型很難做到的。
5
總結(jié)
本文介紹了谷歌提出的解決推薦系統(tǒng)中長尾item或user預(yù)測效果的遷移學習框架,通過many-shot到few-shot的參數(shù)規(guī)律變化學習,結(jié)合對數(shù)據(jù)分布的刻畫,實現(xiàn)了頭部、尾部雙贏的推薦模型。
-
谷歌
+關(guān)注
關(guān)注
27文章
6211瀏覽量
106438 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7221瀏覽量
90118 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4352瀏覽量
63250
原文標題:谷歌MIRec:頭部尾部雙贏的遷移學習框架
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
遷移學習
卷積神經(jīng)網(wǎng)絡(luò)長尾數(shù)據(jù)集識別的技巧包介紹
谷歌FHIR標準協(xié)議利用深度學習預(yù)測醫(yī)療事件發(fā)生

谷歌發(fā)布機器學習框架:一個名叫NSL的神經(jīng)結(jié)構(gòu)學習框架
解決長尾和冷啟動問題的基本方法
一個基于參數(shù)更新的遷移學習的統(tǒng)一框架
一個通用的時空預(yù)測學習框架

谷歌使用機器學習模型來預(yù)測哪條路線最省油或最節(jié)能
深度學習框架連接技術(shù)
視覺深度學習遷移學習訓練框架Torchvision介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論