

引言
YOLOv5最新版本的6.x已經支持直接導出engine文件并部署到TensorRT上了。
FP32推理TensorRT演示
可能很多人不知道YOLOv5新版本6.x中已經支持一鍵導出Tensor支持engine文件,而且只需要一條命令行就可以完成:演示如下:
python export.py --weights yolov5s.pt --include onnx engine --device 0
其中onnx表示導出onnx格式的模型文件,支持部署到:
- OpenCV DNN- OpenVINO- TensorRT- ONNXRUNTIME但是在TensorRT上推理想要速度快,必須轉換為它自己的engine格式文件,參數engine就是這個作用。上面的命令行執行完成之后,就會得到onnx格式模型文件與engine格式模型文件。--device 0參數表示GPU 0,因為我只有一張卡!上述導出的FP32的engine文件。
使用tensorRT推理 YOLOv5 6.x中很簡單,一條命令行搞定了,直接執行:
python detect.py --weights yolov5s.engine --view-img --source data/images/zidane.jpg
FP16推理TensorRT演示
在上面的導出命令行中修改為如下
python export.py --weights yolov5s.onnx --include engine --half --device 0其中就是把輸入的權重文件改成onnx格式,然后再添加一個新的參 --half 表示導出半精度的engine文件。就這樣直接執行該命令行就可以導出生成了,圖示如下:
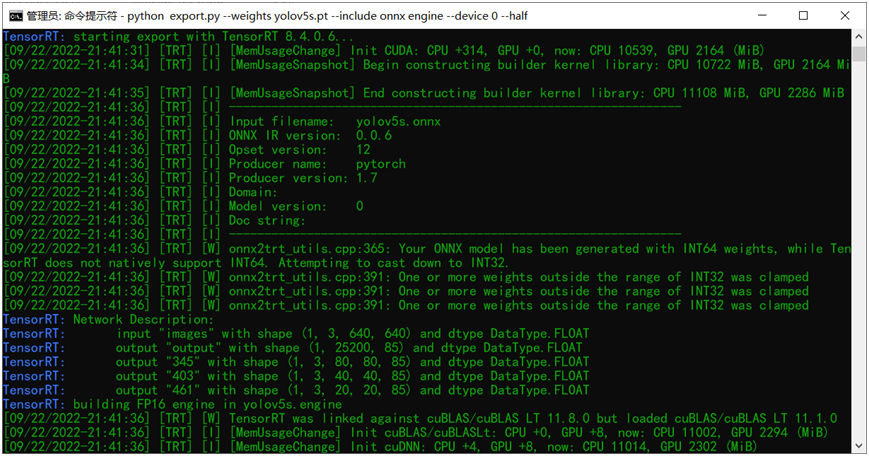
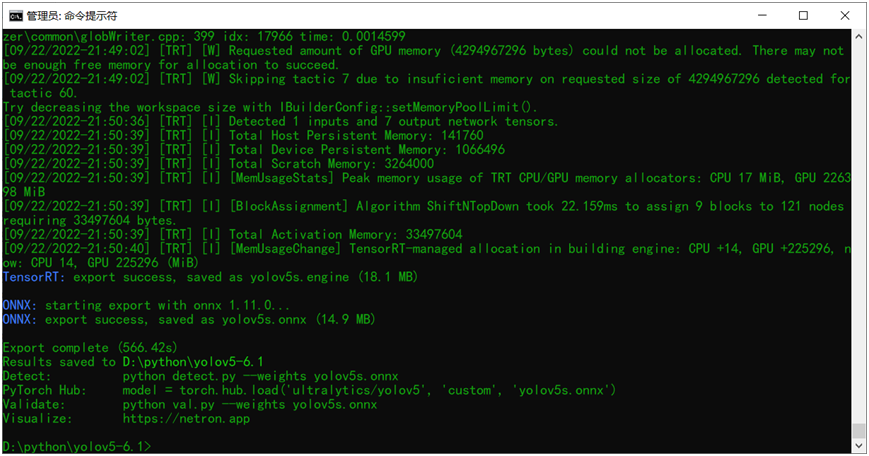
對比可以發現相比FP32大小的engine文件,FP16的engine文件比FP32的engine大小減少一半左右,整個文件只有17MB大小左右。
推理執行的命令跟FP32的相同,直接運行,顯示結果如下:
對比發現FP32跟FP16版本相比,速度提升了但是精度幾乎不受影響!
INT8量化與推理TensorRT演示
TensorRT的INT量化支持要稍微復雜那么一點點,最簡單的就是訓練后量化。只要完成Calibrator這個接口支持,我用的TensorRT版本是8.4.0.x的,它支持以下幾種Calibrator:
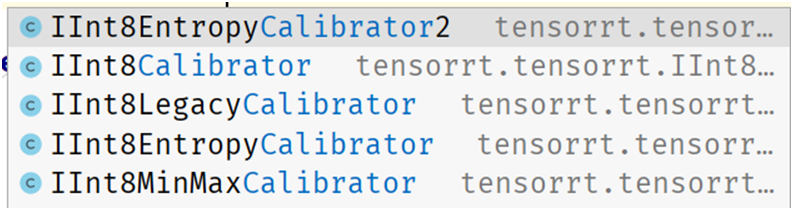
不同的量化策略,得到的結果可能稍有差異,另外高版本上的INT8量化之后到低版本的TensorRT機器上可能無法運行,我就遇到過!所以建議不同平臺要統一TensorRT版本之后,再量化部署會比較好。上面的Calibrator都必須完成四個方法,分別是:
#使用calibrator驗證時候每次張數,跟顯存有關系,最少1張get_batch_size #獲取每個批次的圖像數據,組裝成CUDA內存數據get_batch #如果以前運行過保存過,可以直接讀取量化,低碳給國家省電read_calibration_cache#保存calibration文件,量化時候會用到write_calibration_cache
這塊對函數集成不懂建議參考TensorRT自帶的例子:
TensorRT-8.4.0.6samplespythonint8_caffe_mnist幾乎是可以直接用的!Copy過來改改就好了!
搞定了Calibrator之后,需要一個驗證數據集,對YOLOv5來說,其默認coco128數據集就是一個很好的驗證數據,在data文件夾下有一個coco128.yaml文件,最后一行就是就是數據集的下載URL,直接通過URL下載就好啦。
完成自定義YOLOv5的Calibrator之后,就可以直接讀取onnx模型文件,跟之前的官方轉換腳本非常相似了,直接在上面改改,最重要的配置與生成量化的代碼如下:
# build trt enginebuilder.max_batch_size = 1config.max_workspace_size = 1 << 30config.set_flag(trt.BuilderFlag.INT8)config.int8_calibrator = calibratorprint('Int8 mode enabled')plan = builder.build_serialized_network(network, config)主要就是設置config中的flag為INT8,然后直接運行,得到plan對象,反向序列化為engine文件,保存即可。最終得到的INT8量化engine文件的大小在9MB左右。
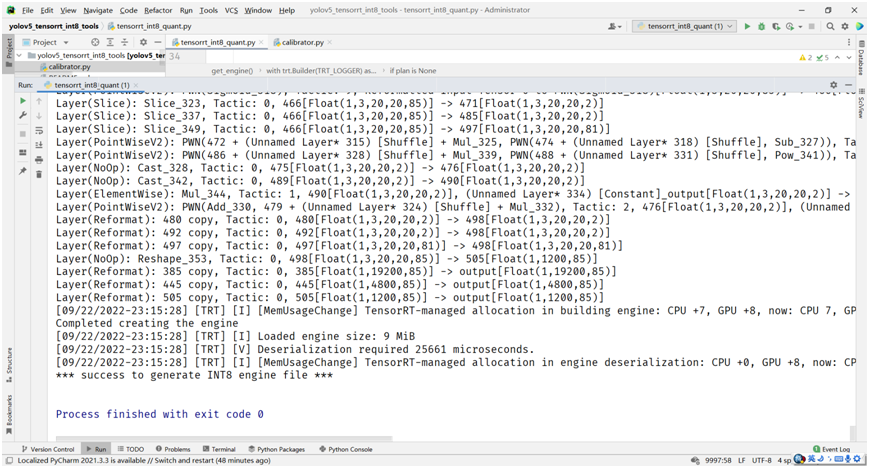
數據太少,只有128張, INT8量化之后的YOLOv5s模型推理結果并不盡如人意。但是我也懶得再去下載COCO數據集, COCO訓練集一半數據作為驗證完成的量化效果是非常好。 這里,我基于YOLOv5s模型自定義數據集訓練飛鳥跟無人機,對得到模型,直接用訓練集270張數據做完INT8量化之后的推理效果如下:
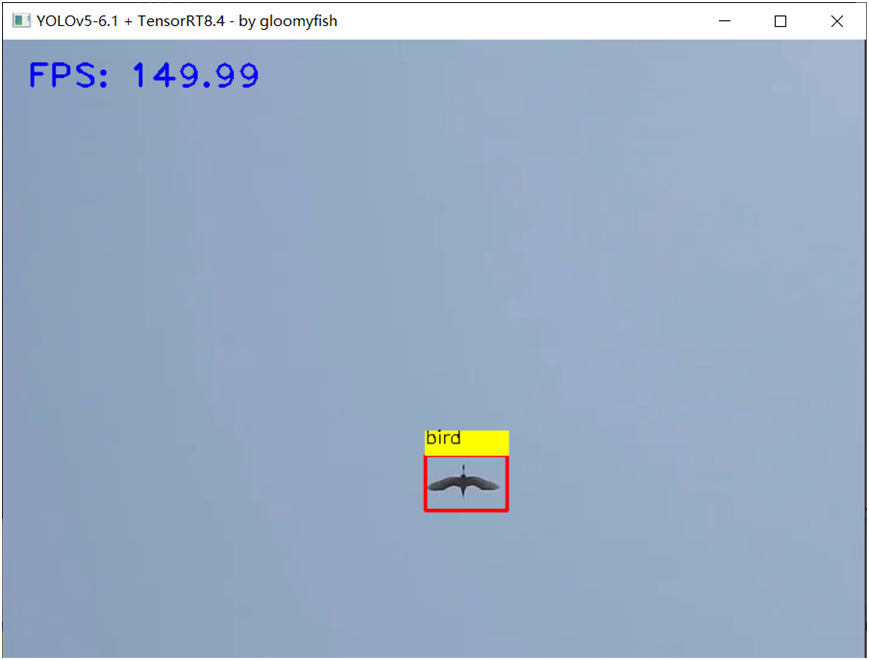
量化效果非常好,精度只有一點下降,但是速度比FP32的提升了1.5倍左右(3050Ti)。
已知問題與解決
量化過程遇到這個錯誤
[09/22/2022-2313] [TRT] [I] Calibrated batch 127 in 0.30856 seconds.[09/22/2022-2316] [TRT] [E] 2: [quantization.cpp::70] Error Code 2: Internal Error (Assertion min_ <= max_ failed. )[09/22/2022-2316] [TRT] [E] 2: [builder.cpp::619] Error Code 2: Internal Error (Assertion engine != nullptr failed. )Failed to create the engineTraceback (most recent call last):
解決方法,把Calibrator中getBtach方法里面的代碼:
img = np.ascontiguousarray(img, dtype=np.float32)
to
img = np.ascontiguousarray(img, dtype=np.float16)
這樣就可以避免量化失敗。
-
格式
+關注
關注
0文章
23瀏覽量
17000 -
模型
+關注
關注
1文章
3462瀏覽量
49789 -
數據集
+關注
關注
4文章
1220瀏覽量
25183
原文標題:YOLOv5模型部署TensorRT之 FP32、FP16、INT8推理
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何在GPU上使用TensorRT部署深度學習應用程序
全志XR806+TinyMaix,在全志XR806上實現ML推理
推斷FP32模型格式的速度比CPU上的FP16模型格式快是為什么?
C++演示中的推理速度比Python演示中的推理速度更快是為什么?
初次嘗試Tengine 適配 Ncnn FP32 模型

NVIDIA TensorRT 8.2將推理速度提高6倍
使用NVIDIA TensorRT優化T5和GPT-2

NVIDIA TensorRT和DLA分析
NVIDIA T4 GPU和TensorRT提高微信搜索速度
TensorRT 8.6 C++開發環境配置與YOLOv8實例分割推理演示
三種主流模型部署框架YOLOv8推理演示
邊緣生成人工智能推理技術面臨的挑戰有哪些

Torch TensorRT是一個優化PyTorch模型推理性能的工具

TensorRT-LLM低精度推理優化






 工商網監
工商網監

評論