 基于飛騰開發板使用單目攝像頭完成了完成了全息影像的展示
基于飛騰開發板使用單目攝像頭完成了完成了全息影像的展示
1.團隊介紹
參賽單位:西安電子科技大學 指導老師:蔡覺平、丁瑞雪 參賽隊員:王瑞青、江立峰、陳培林 總決賽獎項:二等獎

2.項目簡介
2.1項目背景
由于深度對于理解三維場景非常重要,因此它被廣泛應用于機器人技術、三維建模和駕駛自動化系統等領域。如圖1所示,單目深度估計從單個RGB圖像生成像素方向的深度。單目深度估計有可能取代現有的深度傳感器,如激光雷達和紅外傳感器,成為低成本和功率單目RGB相機。由于單目RGB相機的可靠性和高精度,最近基于CNN的單目深度估計方法受到關注。然而,CNN需要大量的乘法運算,在有限的功耗限制下,很難對嵌入式系統進行實時、準確的估計。在以往的單目深度估計研究中,為了加快gpu上的訓練時間或推理速度,這些研究通常使用具有輕量級卷積(如可分離卷積)的編解碼網絡[2]。然而,gpu需要很高的功耗,并且不適合處理編碼器-解碼器網絡中使用的許多不同卷積的快速內存訪問。

2.2項目功能
單目深度估計是指從單個二維彩色圖像中估計像素級深度測量的任務。這個問題的輸入是一個2D RGB彩色圖像,輸出是一個密集的深度圖,如圖1-1所示。2D RGB圖像提供像素級的顏色信息,這有助于識別場景中對象的相對位置;然而,圖像本身并不能提供尺度感。因此,可以想象不同的RGB圖像如何能夠產生相同的深度圖,例如,保持對象的相對位置但在垂直于圖像平面的深度維度上具有縮放的距離的圖像。這對單目深度估計算法提出了挑戰,因為它們必須推斷適當的比例,以便生成精確的像素級深度測量。

2.3項目應用
深度估計對于許多機器人應用來說至關重要,尤其是導航。這通常是即時定位與地圖構建(SLAM)算法中的一個關鍵步驟,一些著作已經將基于學習的深度估計結合到SLAM框架中,例如CNN-SLAM 。深度估計也是3D重建算法的一個關鍵步驟,應用于增強現實和醫學成像。當我們考慮功率受限的小型化機器人時,單目深度估計變得也很重要,這種機器人上的機載傳感器技術可能僅限于簡單的RGB相機,并且可能不存在附加信息(例如,立體圖像對、IMU測量、稀疏深度點云、光流)。對于這樣的應用,以計算有效的方式從單個RGB圖像估計密集深度的能力成為挑戰和目標。
3.系統組成
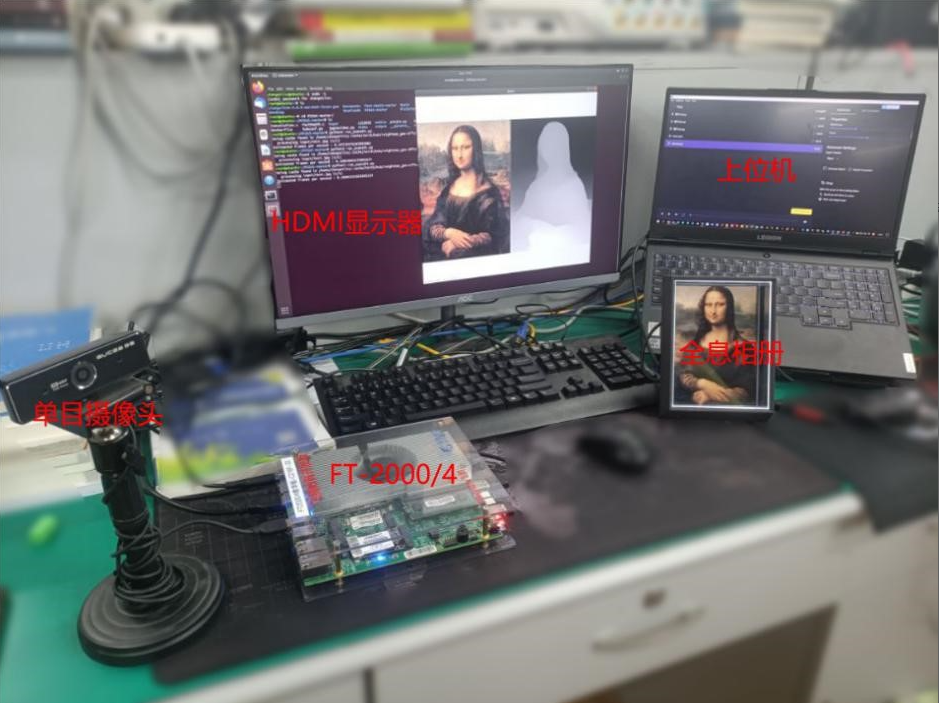
天乾C216F開發板
我們使用的開發板,完成將RGB圖像處理成深度圖像的功能
全息相冊
展示天乾C216F處理后的全息影像
上位機
發送指令,完成使系統功能在“懷舊模式”、“攝影模式”、“拍照模式”等多種模式之間的切換
單目攝像頭
可以捕獲圖像或者視頻,并輸出給天乾C216F
HDMI顯示器
顯示當前模式以及圖像處理情況
4.網路設計與優化方法
4.1FastDepth簡介
我們設計的單目深度估計網絡FastDepth主要由卷積構成,主要由編碼器-解碼器兩部分組成。編碼器從輸入圖像中提取高層次低分辨率特征。然后將這些特征輸入解碼器,在解碼器中對它們進行逐步的上采樣、細化和合并,以形成最終的高分辨率輸出深度圖。

編碼器用藍色表示;解碼器用黃色表示。中間特征圖的尺寸對應關系為高× 寬×深度。從編碼層到解碼層的箭頭表示加法跳過連接。
FastDepth的大部分卷積層使用深度可分離卷積。只有MobileNet編碼器的第一層(標準卷積層)和解碼器的最后一層(簡單的逐點卷積,然后是插值)沒有使用深度可分離卷積。FastDepth中的每個卷積層后面是一個標準化層和一個ReLU函數。在訓練之后,將標準化層和卷積層合并,從而形成一個僅由卷積層、ReLU函數和加法跳過連接操作組成的神經網絡拓撲。
我們在PyTorch中建立了FastDepth網絡,并使用官方的train/test數據分割在NYU Depth v2數據集上進行訓練。編碼層使用了已經在ImageNet上預訓練的模型的權重進行初始化。然后將網絡作為一個整體進行20個epochs的訓練,batch size為16,初始學習率為0.01。學習率每5個epochs降低2倍。
4.2網絡優化
4.2.1網絡剪枝
為了進一步減少網絡延遲,我們使用NetAdapt執行訓練后網絡修剪。NetAdapt從一個經過訓練的網絡開始,自動地從特征映射中識別和刪除冗余通道,以降低計算復雜度。在每次迭代中,NetAdapt都會生成一組從參考網絡簡化而來的網絡建議。然后選擇具有最佳精度和復雜度權衡的網絡方案作為下一次迭代的參考網絡。該過程一直持續到達到目標精度或復雜度。網絡復雜性可以通過間接指標(如mac)或直接指標(如目標硬件平臺上的延遲)來衡量。
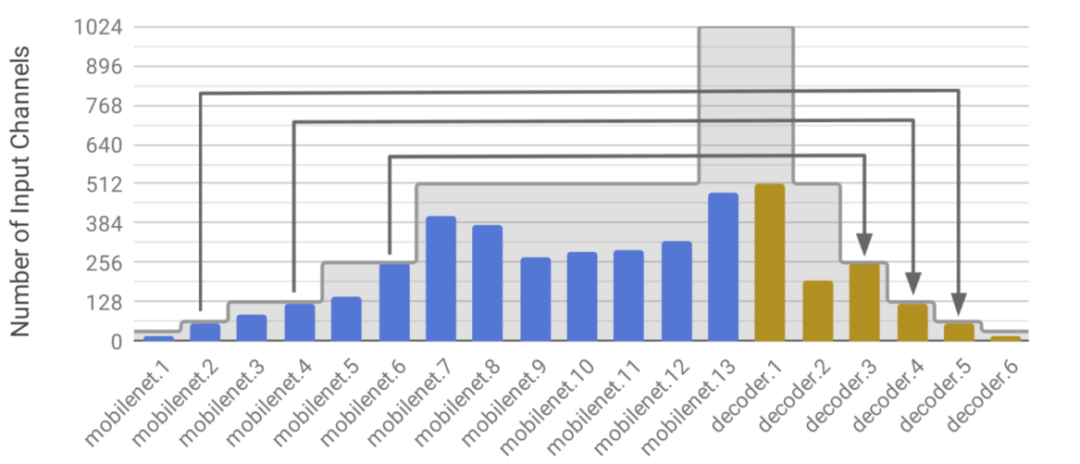
4.2.2將5×5卷積和最近鄰插值分解為3×3卷積
參考了Yazdanbakhsh等人在他們關于FlexiGAN的工作中探索的這種分解的一種變體,他們在FlexiGAN中使用了濾波器和行重新排序,以使零插入后的卷積更加緊湊和密集,從而更好地利用硬件資源。我們采用了一種類似的方法如圖所示。
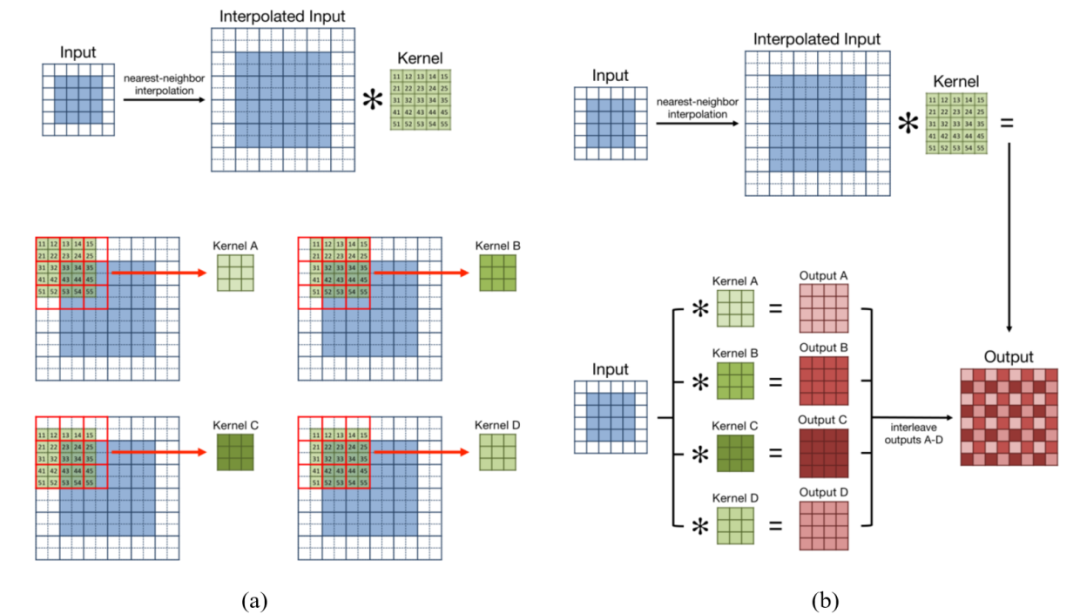
把5×5核分解成4個更小的3×3核。當5×5卷積之前是最近鄰插值。此處的紅色框表示插值輸入特征圖中具有相同值的像素窗口。隨著5×5核的滑動,2×2的窗口中的內核值將與相同的特性映射值相乘。與執行4次乘法和4次加法不同,內核值可以先預加,然后再與共享像素值相乘一次。(b)經過濾波器分解,每四個較小的3×3濾波器可與非插值輸入特征映射卷積。這將產生四個可以交錯的輸出。得到的輸出特征映射與最近鄰插值后執行的原始5×5卷積的特征映射相匹配。
5.部署方式
本文實現了兩種部署方式:通過TVM編譯器和pytorch深度學習框架部署。通過TVM端到端深度學習編譯器部署fastdepth模型,顯示效果一般,但由于對模型經過剪枝、量化等優化操作,幀率高達34.7fps;通過pytorch深度學習框架部署midas,模型精度高,顯示效果好,但幀率下降至0.82fps左右。
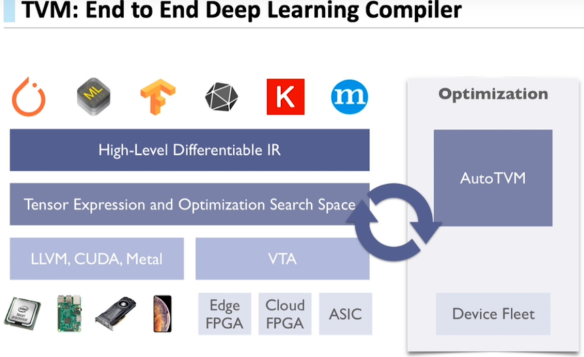
TVM是由華盛頓大學在讀博士陳天奇等人提出的深度學習自動代碼生成方法,該技術能自動為大多數計算硬件生成可部署優化代碼,其性能可與當前最優的供應商提供的優化計算庫相比,且可以適應新型專用加速器后端。
TVM可以優化CPU和其他專用硬件為后端的常見深度學習計算負載。
TVM通過利用多線程、數據布局轉化和一些新的計算原語,可以針對GPU做很多高效優化。
同時,TVM已為x86、ARM等平臺提供了同意的優化框架,利用其部署大大提高了板子資源利用率,幀率高達34.7fps。
下圖是TVM端到端深度學習編譯器的說明圖:
6.作品效果展示
通過全息相冊上位機選擇生成后的深度圖即可在全息相冊上展示。

審核編輯 :李倩
-
傳感器
+關注
關注
2550文章
51037瀏覽量
753085 -
自動化系統
+關注
關注
3文章
255瀏覽量
29653 -
cnn
+關注
關注
3文章
352瀏覽量
22204
原文標題:比賽作品分享 | 2022集創賽飛騰杯二等獎作品:基于單目深度估計網絡的全息顯示終端
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【飛凌嵌入式OK3576-C開發板體驗】 USB攝像頭拍照測試
攝像頭氣密性測試設備:高精度,高效率

基于FPGA的攝像頭心率檢測裝置設計
OpenHarmony鴻蒙南向開發案例:【智能貓眼(基于Hi3518開發板)】

OpenHarmony鴻蒙南向開發案例:【智能貓眼(基于3516開發板)】

項目分享|基于ELF 1開發板的遠程監測及人臉識別項目

全志D1-H開發板USB攝像頭拍照Demo
使用Arduino IDE 2.0開發ESP32攝像頭模塊
飛騰派開發板評測獲獎名單公布!!!






 工商網監
工商網監
評論