 JEDEC定義了四種主要類型的DRAM
JEDEC定義了四種主要類型的DRAM
內存層次結構的變化是穩定的,但是訪問內存的方式和位置會產生很大的影響。
數據的指數增長和對提高數據處理性能的需求催生了各種新的處理器設計和封裝方法,但它也推動了內存方面的巨大變化。
雖然底層技術看起來仍然非常熟悉,但真正的轉變在于這些存儲器與系統內處理元件和各種組件的連接方式。這會對系統性能、功耗甚至整體資源利用率產生重大影響。
多年來出現了許多不同類型的存儲,盡管有一些交叉和獨特的用例,但大多數都有明確的用途。其中包括 DRAM 和 SRAM、閃存和其他專用存儲器。DRAM 和 SRAM 是易失性存儲器,這意味著它們需要電源來維護數據。非易失性存儲器不需要電力來保留數據,但讀/寫操作的數量是有限的,并且它們會隨著時間的推移而磨損。
所有這些都適合所謂的內存層次結構,從SRAM開始——一種非常快速的內存,通常用于各種級別的緩存。SRAM 速度極快,但由于每比特成本高,其應用受到限制。同樣在最低級別,通常嵌入到 SoC 或連接到 PCB 的 NOR 閃存通常用于啟動設備。它針對隨機訪問進行了優化,因此它不必遵循任何特定的存儲位置順序。
在內存層次結構中向上移動一步,DRAM是迄今為止最受歡迎的選擇,部分原因是它的容量和彈性,部分原因是它的每比特成本低。這部分是由于領先的 DRAM 供應商已經全面折舊他們的晶圓廠和設備,但隨著新型 DRAM 的上線,價格一直在上漲,為新的競爭對手打開了大門。
幾十年來,人們一直在談論要取代 DRAM,但事實證明,從市場的角度來看,DRAM 比任何人預期的都要更有彈性。在高帶寬內存(HBM) 的 3D 配置中,它也被證明是一種極快、低功耗的選擇。
JEDEC 定義了四種主要類型的 DRAM:
標準內存的雙倍數據速率 (DDRx);
低功耗 DDR (LPDDRx),主要用于移動或電池供電設備;
圖形 DDR (GDDRx),最初是為高速圖形應用程序設計的,但也用于其他應用程序,以及
高帶寬內存 (HBMx),主要用于高性能應用,例如 AI 或數據中心內部。
與此同時,NAND 閃存通常用作可移動存儲(SSD/USB 記憶棒)。由于較長的擦除/寫入周期和較低的使用壽命,閃存不適合 CPU/GPU 和系統應用。 “內存標準機構 JEDEC 正在完善雙倍數據速率 (DDR5) 和低功耗版本的 LPDDR5 規范,”西門子 EDA解決方案產品工程師 Paul Morrison 說。“DDR6 和 LPDDR6 也在開發中。其他流行的 DRAM 內存包括高帶寬內存(HBM2 和 HBM3)和圖形 DDR(GDDR6,即將發布 GDDR7)。” 但小型電池供電設備的增長以及對設備快速啟動的需求也推高了對閃存的需求。NOR 閃存通常更小,約為 1 Gbit。相比之下,NAND 閃存用于 SSD。密度現在從每單元一位到每單元四位不等,預計每單元有五位和六位版本。此外,從 2D 到 3D 陣列的轉變進一步增加了密度。 “在 AI 和許多其他領域,內存性能對于良好的系統性能至關重要,” Rambus的研究員和杰出發明家 Steven Woo 說。“以最高數據速率運行內存將提高系統性能,但考慮數據結構如何映射到內存可以提高帶寬、功率效率和容量利用率。增加內存容量還可以帶來更好的性能,而 CXL 的引入將為 AI 和其他處理器提供一種方式來增加內存容量,這超出了直連內存技術目前所能提供的范圍。”
距離很重要
內存和處理器之間的距離曾經是一個平面規劃問題,但隨著需要處理的數據量的增加以及功能的縮小,在內存和處理器之間來回移動更多數據所需的能量元素增加。更細的電線需要更多的能量來移動電子,而將它們移動更長的距離需要更多的能量并增加延遲。 這引發了對近內存和內存計算的新興趣,其中至少一些數據可以被分區和優先處理、處理和顯著減少。這減少了使用的能源總量,并且可能對性能產生重大影響。 內存計算(又名內存處理或內存計算)是指在內存(例如 RAM)內進行處理或計算。前段時間,在芯片級完成此操作之前,已經證明通過將數據分布在多個 RAM 存儲單元并結合并行處理,在投資銀行等案例中的性能提高了 100 倍。因此,雖然內存/近內存計算已經存在了很長時間,并且從 AI 設計中得到了又一次推動,但直到最近芯片制造商才開始展示這種方法的一些成功。 2021 年,三星的內存業務部門推出了在 HBM 內存中集成 AI 內核的內存處理 (PIM) 技術。在使用 Xilinx Virtex Ultrascale 和 (Alveo) AI 加速器的語音識別測試中,PIM 技術能夠實現 2.5 倍的性能提升和 62% 的能耗降低。SK 海力士和美光科技等其他存儲芯片制造商也在研究這種方法。 在內存計算領域,最近獲得博士學位的萬維爾領導的國際研究團隊宣布了一項突破性進展。畢業于斯坦福大學 Philip Wong 的實驗室,他在加州大學圣地亞哥分校從事這個想法。其他博士為這項研究做出重大貢獻的加州大學圣地亞哥分校的畢業生現在在圣母大學和匹茲堡大學經營自己的實驗室。 通過將神經形態計算與電阻式隨機存取存儲器緊密結合,NeuRRAM 芯片以高精度執行 AI 邊緣計算——在 MNIST 手寫數字識別任務上的準確率達到 99%,在 CIFAR-10 圖像分類任務上達到 85.7%。與當今最先進的邊緣 AI 芯片相比,NeuRRAM 芯片能夠提供低 1.6 到 2.3 倍的能量延遲積(EDP;越少越好)和高 7 到 13 倍的計算密度。這為降低運行各種 AI 任務的芯片的功率提供了機會,同時又不影響未來幾年的準確性和性能。 “提高內存性能的關鍵因素之一一直是最大限度地減少數據移動,”西門子 EDA 技術產品經理 Ben Whitehead 說。“通過這樣做,它還可以降低功耗。以 SSD 為例,一次數據查找可以將傳輸速度提高 400 到 4000 倍。另一種方法是將計算移到內存附近。內存計算的概念并不新鮮。在內存中添加智能將減少數據移動。該概念類似于邊緣計算,通過執行本地計算而不是來回將數據發送到云。DRAM 中的內存計算仍處于早期階段,但這將繼續成為未來內存發展的趨勢。”
內存標準更新
目前正在進行的三個主要標準組/工作可能會對所有這些產生重大影響: JEDEC:組織繼續其 50 多年來作為微電子行業內存標準領導機構的角色。它開發并發布了許多標準,重點關注主內存(DDR4 和 DDR5 SDRAM)、閃存(UFS、e.MMC、SSD、XFMD)、移動內存(LPDDR、Wide I/O)等。它將繼續成為內存標準的主導機構。 JEDEC 最近發布了兩個新標準。2022 年 8 月,它發布了 DDR5 SDRAM 規范,該規范定義了 x4、x8 和 x16 DDR5 SDRAM 設備的 8 Gb 到 32 Gb 的最低要求。這項工作是基于 DDR4 標準以及部分 DDR、DDR2、DDR3 和 LPDDR4 標準完成的。此外,2021 年 7 月 JEDEC 增加了 LPDDR5 和 LPDDR5X,定義密度范圍從 2 Gb 到 32 Gb 的 x16 單通道 SDRAM 設備和 x8 單通道 SDRAM 設備的最低要求。這項工作是根據以前的規范完成的,包括 DDR2、DDR3、DDR4、LPDDR、LPDDR2、LPDDR3 和 LPDDR4。 CXL:CXL聯盟是一個開放的行業標準組,支持 Compute Express Link ( CXL ),這是一種行業支持的高速緩存一致性互連,用于處理器、內存擴展和加速器。該技術定義了 CPU 內存空間和附加設備上的內存之間的互連,以實現資源共享,這可以提高性能,同時最大限度地降低軟件和系統成本。它還有助于定義 AI/ML 中使用的加速器。該聯盟最近發布了 CXL 2.0 規范,該規范增加了開關功能,以啟用設備扇出、內存擴展、擴展、內存池、鏈路級完整性和數據加密 (CXL IDE) 以保護數據。 UCIe:在小芯片方面是最近發布的通用小芯片互連快速(UCIe) 標準。芯片制造商將繼續采用 UCIe 連接小芯片,包括存儲器。當前的重點包括物理層(具有行業領先 KPI 的芯片到芯片 I/O)和協議 (CXL/PCIe),以確保互操作性。 “CXL 幫助加速器與系統的其他部分保持一致,因此傳遞數據、消息和執行信號量更加高效,”英特爾高級研究員兼 CXL 聯盟委員會技術任務組主席 Debendra Das Sharma 說。“此外,CXL 解決了這些應用程序的內存容量和帶寬需求。CXL 將推動內存技術和加速器的重大創新。”
關于性能優化的想法
其中一些內存方法已經存在了幾十年,但沒有什么是靜止的。內存仍然被視為功率、性能和面積/成本范式中的關鍵元素,權衡可能會對所有這些元素產生重大影響。 “內存技術不斷發展,”西門子 EDA 產品經理 Gordon Allan 說。“例如,HBM 是目前 AI 應用程序的完美選擇,但明天可能會有所不同。主要內存標準機構 JEDEC 定義了 DDR4 和 5、DIMM 4 和 5、LRDIM 以及當今的其他內存。但對于未來的內存擴展,用于定義 PCIe 和 UCIe 接口的 CXL 標準正在獲得認可和發展勢頭。” 每個處理器都需要內存來存儲數據。因此,了解內存的特性及其行為將如何影響整體系統性能非常重要。設計和選擇存儲器的一些關鍵考慮因素包括:
在給定的能量單位內最大化性能;
功率預算和熱管理;
將內存與處理需求相匹配,例如需要更高內存性能的 AI 系統,以及重復使用設計、密度和封裝(2D、2.5D、3D-IC)
根據應用程序,考慮數據如何在系統內和系統之間傳輸也很重要。 “要優化性能,您需要關注系統級別,” Cadence DDR、HBM、閃存/存儲和 MIPI IP 集團產品營銷總監 Marc Greenberg 說. “為了讓您的系統實現高吞吐量,它可能需要 80 多個內存連接到處理器。有不同的方法可以提高效率。其中之一是優化流量訪問的順序,并在給定時鐘頻率下以最小總線周期完成的任務數量最大化。一個簡單的類比是雜貨店的結賬過程。例如,客戶有五罐菠蘿、一個西瓜和其他東西。為了提高結賬效率,您可以將所有五個罐頭作為一組呈現,而不是先呈現一個罐頭,然后是西瓜,然后是另一個罐頭。同樣的概念也適用于內存。此外,在一個點上擁有一個智能內存控制器(PHY 和控制器 IP)來管理多個內存的流量協議將在內存設計中實現更好的優化。” 人工智能在許多設備中的推出使這些考慮變得更加重要。 “在 AI 訓練中,提供最高帶寬、容量和功率效率的存儲器很重要,”Rambus 的 Woo 說。“HBM2E 內存非常適合許多訓練應用,尤其是大型模型和大型訓練集。使用HBM2E的系統實現起來可能更復雜,但如果可以容忍這種復雜性,那么它是一個不錯的選擇。另一方面,對于許多推理應用程序來說,需要高帶寬、低延遲和良好的功率效率,同時具有良好的性價比。對于這些應用,GDDR6 內存可能更適合。對于物聯網等端點應用,也可以與 LPDDR 結合使用的片上存儲器是有意義的。”
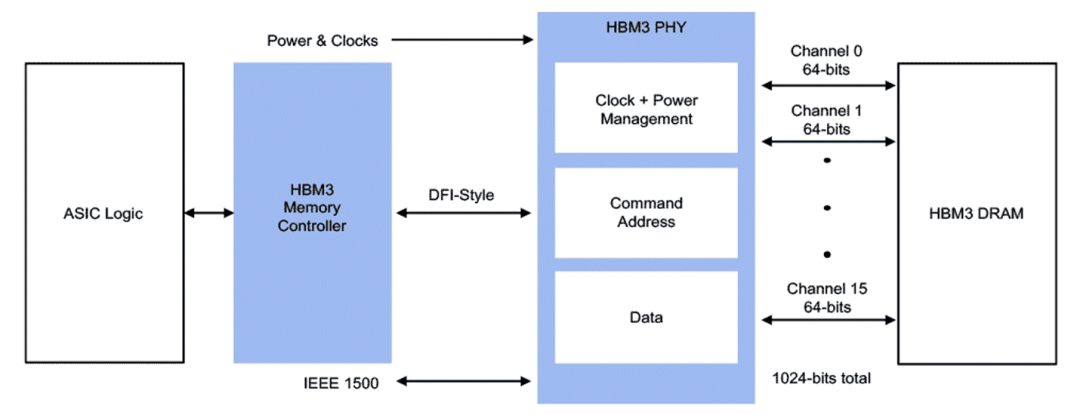
HBM 內存控制器和 PHY IP 優化了內存管理功能 根據美光的說法,內存系統比看起來更復雜。在給定的內存帶寬內,系統性能可能會受到訪問模式、位置和解決時間等因素的影響。例如,自然語言處理模型需要 50 TB/s 的內存帶寬來支持 7mS 的延遲時間來解決問題。如果可以容忍更長的延遲,則可以相應地調節它們的內存帶寬。 美光指出,架構會隨著對解決方案堆棧的全面了解而得到改進——從軟件到架構再到內存系統。因此,出發點是優化算法內的訪問模式、數據放置和延遲緩解(即數據預取),同時利用內存架構的固有優勢并解決其局限性。 JEDEC 不斷改進內存,以應對更高密度、低延遲、低功耗、更高帶寬等挑戰。通過遵循規范,內存制造商和系統設計人員將能夠利用新的創新。近年來,來自 Synopsys 和 Siemens EDA 等公司的先進工具已可用于執行所需的功能,例如測試、仿真和驗證。 “JEDEC 的目標之一是繼續提供支持進一步擴展的架構創新,”新思科技定制設計與制造集團的產品營銷總監 Anand Thiruvengadam 說。“更新的內存規格將繼續實現更高的密度、更低的功耗和更高的性能。例如,DDR4 的電源要求是 1.2V,而 DDR 5 是 1.1V。在此電壓縮放期間,必須考慮信號完整性和如何打開眼圖等因素。熱管理也得到了改進。DDR5 每個引腳有兩到三個溫度傳感器,比只有一個的 DDR4 有所改進。因此,遵循規范是有益的。” 但遵循規范是一回事。滿足規范是另一回事。“根據規范測試產品很重要,確保它通過所有最壞的情況,”Thiruvengadam 說。“復雜的分析和模擬可能需要數周時間。幸運的是,更新的仿真軟件解決方案可以將這一時間縮短到幾天。”
結論
JEDEC 將繼續定義和更新存儲器規格,涵蓋 DRAM、SRAM、FLASH 等。隨著 CXL 和 UCIe 標準的加入,內存開發社區將受益于未來的系統和小芯片互連。盡管 UCIe 相對較新,但它有望在生態系統中開辟小芯片的新世界。 此外,預計 AI/ML 將繼續推動對高性能、高吞吐量內存設計的需求。持續的斗爭將是平衡低功耗要求和性能。但涉及內存計算的突破將為世界帶來更快的發展加速。更重要的是,這些先進的內存開發將有助于推動未來基于人工智能的邊緣和端點 (IoT) 應用。
審核編輯 :李倩
-
存儲器
+關注
關注
38文章
7513瀏覽量
163988 -
RAM
+關注
關注
8文章
1369瀏覽量
114765 -
內存
+關注
關注
8文章
3034瀏覽量
74137 -
JEDEC
+關注
關注
1文章
36瀏覽量
17447
原文標題:如何通過內存設計來優化系統性能?
文章出處:【微信號:芯長征科技,微信公眾號:芯長征科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
雙軸測徑儀的四種樣式!
濾波電路的四種類型是什么
負反饋的四種類型是什么
負反饋的四種類型及判斷方法
受控源四種類型及表示方法
簡述四種基本觸發器及其功能
功率放大電路的四種類型
元器件的包裝方式及常見的四種方式
介紹MCUboot支持的四種升級模式(2)






 工商網監
工商網監
評論