 采用帶有transformer的端到端框架獲取對應集合結果
采用帶有transformer的端到端框架獲取對應集合結果
1.摘要
最近將學習的方式引入點云配準中取得了成功,但許多工作都側重于學習特征描述符,并依賴于最近鄰特征匹配和通過RANSAC進行離群值過濾,以獲得姿態估計的最終對應集合。在這項工作中,我們推測注意機制可以取代顯式特征匹配和RANSAC的作用,從而提出一個端到端的框架來直接預測最終的對應集。我們使用主要由自注意力和交叉注意力的transformer層組成的網絡架構并對其訓練,以預測每個點位于重疊區域的概率及其在其他點云中的相應位置。然后,可以直接根據預測的對應關系估計所需的剛性變換,而無需進一步的后處理。盡管簡單,但我們的方法在3DMatch和ModelNet基準測試中取得了一流的性能。我們的源代碼可以在https://github.com/yewzijian/RegTR.
2.引言
剛性點云配準指找到對齊兩個點云的最佳旋轉和平移參數的問題。點云配準的通用解決方案流程如下:1)檢測關鍵點,2)計算這些關鍵點的特征描述符,3)通過最近鄰匹配獲得假定的對應關系,4)通常使用RANSAC以穩健的方式估計剛性變換。近年來,研究人員將學習的方式應用于點云配準,這些工作中有許多側重于學習特征描述符,也有包括關鍵點檢測,且最后兩個步驟通常保持不變,因為這些方法仍然需要最近鄰匹配和RANSAC來獲得最終轉換。這些算法在訓練過程中沒考慮后處理,其性能對后處理的選擇很敏感,以選擇正確的對應關系,如RANSAC中采樣的興趣點或距離閾值。
一些方法通過使用從局部特征相似性得分計算的軟對應來估計對齊方式,從而避免了不可微的最近鄰匹配和RANSAC步驟。在這項工作中,我們采用了稍微不同的方法。我們注意到,這些工作中學習到的局部特色主要用于建立對應關系。因此,讓網絡直接預測一組清晰的對應關系,而不是學習好的特征。受到最近一系列工作的激勵,這些工作利用transformer注意力層,以最少的后處理來預測各種任務的最終輸出。雖然注意機制以前曾被用于點云和圖像的配準中,但這些工作主要是利用注意力層來聚集上下文信息,以學習更多的區分性的特征描述符,后續的RANSAC或最優轉換步驟仍然經常用來獲得最終的對應關系。相比之下,Regis-tration Transformer(REGTR)利用注意力層直接輸出一組一致的最終點對應關系,如圖1所示。由于網絡輸出清晰的對應關系,可以直接估計所需的剛性轉換,而不需要額外的近鄰匹配和RANSAC步驟。

圖1 REGTR網絡流程圖
首先,REGTR主干使用點卷積來提取一組特征,同時對輸入的點云進行下采樣。這兩個點云的特征被傳遞到多個transformer層,這些transformer層包含多頭自注意力和交叉注意力,方便全局信息聚合。同時通過位置編碼考慮點的位置,以允許網絡利用剛性約束糾正不好的對應關系。然后,使用生成的特征預測下采樣點的相應變換位置。此外,通過預測重疊概率分數來計算剛性變換時預測的對應關系。與常見的通過最近鄰特征匹配計算對應關系的方法不同,該方法要求興趣點位于兩個點云中的相同位置,本文提出的網絡經過訓練可以直接預測出相應的點位置。因此,不需要對大量興趣點或產生可重復點的關鍵點檢測器進行采樣,而是在簡單的網格下采樣點上建立對應關系。
盡管REGTR設計簡單,但它在3DMatch和ModelNet數據集上實現了最先進的性能。由于不需要在大量假對應上運行RANSAC,因此運行時間也很快。總之,我們的貢獻是:
?通過自注意力和交叉關注力直接預測一組一致的最終點對應,而不使用常用的RANSAC或最優轉換層。
?對多個數據集進行了評估,雖然使用了少量對應關系,但仍實現了精確配準,并展示了最先進的性能。
3.定義問題
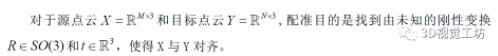
4.方法設計
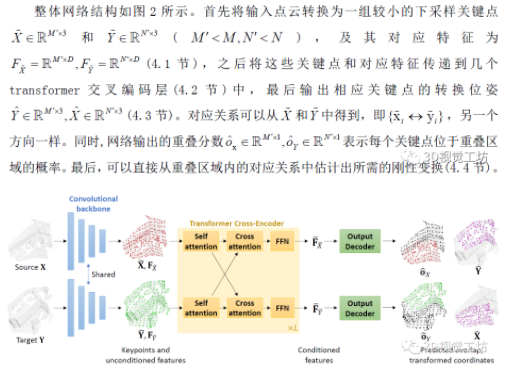
圖2 REGTR網絡整體結構
4.1 下采樣和特征提取

4.2 交叉編碼的transformer層
前一節中的KPConv特征會線性投影到低維(d=256),然后饋入交叉編碼的transformer層(L=6)。每個交叉編碼的transformer有三個子層:1)分別在兩個點云上運行的多頭自注意力層;2)使用其他點云信息更新特征的多頭交叉注意力層;3)位置型前饋網絡。交叉注意力使網絡能夠比較來自兩個不同點云的點,而自注意力允許點在預測其自身變換位置時與同一點云內的其他點交互。值得注意的是網絡權重在兩個點云之間共享,但在層之間不共享。
子層注意力。每個子層中多頭注意力定義為:
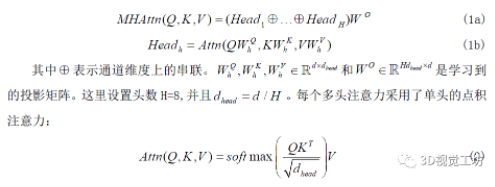
每個子層都應用殘差連接和層歸一化,并使用pre-LN排序,因為更容易優化。query,key,value設置在相同點云的自注意力層中,這能夠關注到同一點云的其余部分。對于交叉注意力層,key和value被設置為來自其他點云的特征,這可以讓每個點與其他點云中的點交互。
位置型前饋網絡。該子層分別對每個關鍵點的特征進行操作。和通常的實現方式一樣,在第一層后使用帶ReLU激活函數的兩層前饋網絡,還應用了殘差連接和層歸一化。
位置編碼。與以往使用注意力來學習區分特征的方案不同,本文的transformer層取代了RANSAC,即向每個transformer層的輸入添加正弦位置編碼來合并位置信息。

4.3解碼輸出
現在約束特征可用于預測出轉換的關鍵點坐標,因此使用兩層MLP獲取需要的坐標。

4.4估計剛性變換

4.5損失函數
使用ground truth位姿進行端對端的訓練網絡,采用如下損失進行監督:
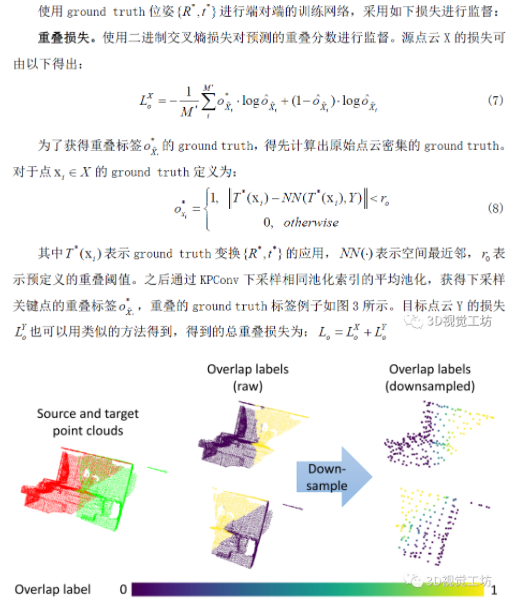
圖3一對點云(左),密集點對應的ground truth標簽(中),下采樣關鍵點(右)
對應關系損失。對重疊區域中關鍵點的預測變換位置應用L1損失:

5.實驗
本文以3DMatch和ModelNet40數據集進行實驗與測試,以配準召回率(RR),相對旋轉誤差(RRE)和相對平移誤差(RTE)為評價指標。配準結果
5.1數據集和結果
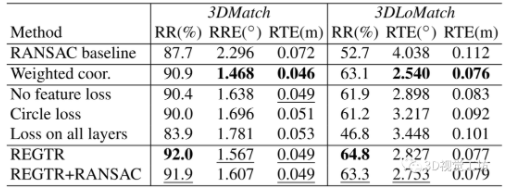
3DMatch。對比結果如表1所示,可以看出本文方法實現了跨場景的最高平均配準召回率,在3DMatch和3DLoMatch基準上都達到了最低的RTE和RRE,雖然只使用了少量的點進行位姿估計。
表1 在3DMatch和3DLoMatch數據集上的性能對比
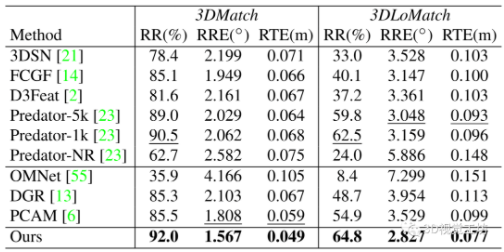
ModelNet40。跟基于對應關系的端對端的配準方法進行比較,在正常重疊(ModelNet)和低重疊(ModelLoNet)下, REGTR在所有指標上都大大優于所有對比方法。本文的注意力機制能夠超越最佳轉換(RPM-Net)和RANSAC步驟(Predator)。定性結果如圖4所示。
表2 ModelNet40數據集評估結果
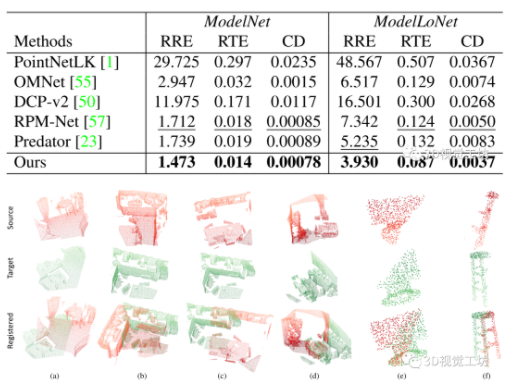
圖4 定性分析結果((a,b)為3DMatch,(c,d)為3DLoMatch, (e)為ModelNet40, (f)為ModelLoNet)
5.2分析對比
運行時間。將本文方法和表3中的方法進行對比,可以發現本文方法在100ms以下運行,可以應用于許多實時程序中。
表3 3DMatch測試集的運行時間對比(ms)
注意力可視化。如圖5所示,當該點位于非信息區域,因此該點會關注第一個transformer層中其他點云中的多個類似外觀區域(圖5a)。在第六層,該點確信其位置,并且主要關注其正確的對應位置(圖5b)。自注意力(圖5c)顯示了利用豐富特征區域幫助定位到正確位置。
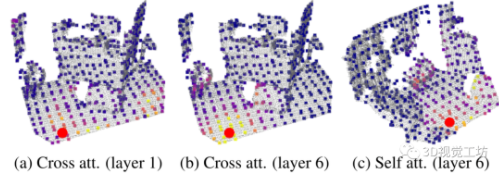
圖5 注意力權重可視化
5.3消融實驗
本節進一步對3DMatch數據集進行消融實驗研究,以了解各種成分的作用,結果如表4所示。
與RANSAC的比較。嘗試將RANSAC應用于REGTR進行預測對應,以確定性能是否進一步提高。表4第7行顯示的配準召回情況稍差。這表明RANSAC對已經與剛性變換一致的預測對應不再有益。
解碼方案。將坐標解碼為坐標的加權和(公式4)與使用MLP回歸坐標的方法相比,將坐標計算為加權和可以獲得更好的RTE和RRE,但配準召回率更低,見表4第2行和第6行。
消融損失。表4第3-6行顯示了配置不同損失函數時的配準性能。在沒有特征損失來指導網絡輸出的情況下,3DMatch和3DLoMatch的注冊召回率分別降低了1.6%和2.9%,使用circle損失也表現不佳,因為網絡無法有效地將位置信息合并到特征中。
表4 消融實驗對比結果
6.局限性
本文使用具有二次復雜度的transformer層阻止了它在大規模點云上使用,并且只能將其應用于下采樣后的點云。雖然直接預測對應關系減輕了分辨率問題,但更精細的分辨率可能會導致更高的性能。我們嘗試了具有線性復雜度的transformer層,但其性能較差,可能替代的解決方法包括使用稀疏注意力,或執行從粗到細的配準。
7.結論
本文提出了用于剛性點云配準的REGTR網絡,它使用多個transformer層直接預測清晰的點對應關系,無需進一步的最近鄰特征匹配或RANSAC步驟,即可根據對應關系估計剛性變換。直接預測對應關系克服了使用下采樣特征帶來的分辨率問題,并且我們的方法在場景和對象點云數據集上都達到了最先進的性能。
審核編輯:郭婷
-
檢測器
+關注
關注
1文章
868瀏覽量
47737 -
數據集
+關注
關注
4文章
1208瀏覽量
24764
原文標題:REGTR:帶有transformer的端對端點云對應(CVPR2022)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
端到端自動駕駛技術研究與分析
端到端在自動泊車的應用
黑芝麻智能端到端算法參考模型公布
爆火的端到端如何加速智駕落地?
連接視覺語言大模型與端到端自動駕駛

端到端讓智駕強者愈強時代來臨?
智駕進程發力?小鵬、蔚來端到端模型上車
恩智浦完整的Matter端到端解決方案

周光:不是真“無圖”,談何端到端

小鵬汽車發布端到端大模型
理想汽車自動駕駛端到端模型實現

采用端到端的逆設計方法實現多維度多通道超構表面全息設計





 工商網監
工商網監
評論