 基于全局特征的自頂向下分類的混合錨系統
基于全局特征的自頂向下分類的混合錨系統
1. 介紹
車道檢測是自動駕駛和高級駕駛輔助系統(ADAS)的基本組成部分,用于識別和定位道路上的車道標記。雖然深度學習模型已經取得了巨大的成功,但仍有一些重要和具有挑戰性的問題有待解決。
第一個是效率問題。在實際應用中,由于下游任務對檢測速度要求較高,在車輛計算設備有限的情況下,車道檢測算法被快速執行來提供實時的感知結果。此外,以往的車道檢測方法主要基于分割,采用密集的自底向上的學習范式,這導致難以取得較快的運行速度。

除了效率問題,另一個挑戰是無視覺線索問題,如圖1所示。車道檢測任務是尋找車道的位置,不管車道是否可見。因此,如何處理嚴重遮擋和極端光照條件下沒有可見信息的場景是車道檢測任務中的一個主要難點。為了緩解這個問題,能夠潛在影響檢測結果的額外線索是至關重要的。例如,道路形狀、車輛行駛方向趨勢、不被遮擋的車道線端點等都有利于檢測。為了利用額外線索,通過擴大感受野來利用更多信息對車道檢測是可取的。
這就提出了一個自然的問題:我們能否找到一種具有大感受野快速且全局的范式用于車道檢測任務?基于上述動機,我們提出了一個稀疏的自頂向下的范式來解決效率問題和無視覺線索問題。首先,我們提出了一種新穎的 row-anchor-driven 的車道表示。一條車道可以用一系列預定義的行錨上的坐標表示。由于一個車道可以很好地由一組關鍵點表示(在一個固定的稀疏行錨系統中),效率問題可以通過錨驅動表示的稀疏性來解決。其次,我們提出了一種基于分類的方式來學習錨驅動表示的車道坐標。使用基于分類的方式(與整個全局特征一起工作),感受野與整個輸入一樣大。它使網絡能夠更好地捕獲全局和長程信息用于車道檢測,有效地解決了無視覺線索的問題。
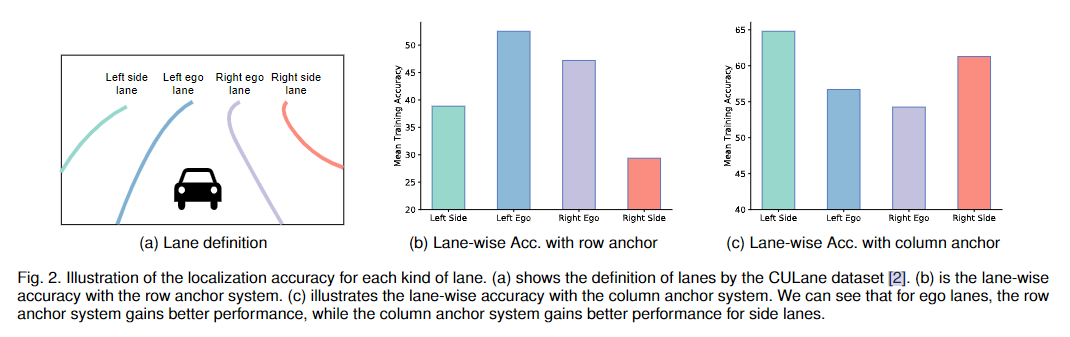
此外,我們在此次工作中把車道線的行錨表示擴充為混合錨系統。根據我們的觀察,行錨不能很好地適用于所有的車道線,而且會導致放大的定位問題。如圖2a和2b所示,使用行錨時,側邊車道的定位精度明顯低于當前車道。如果我們使用列錨呢?在圖2c中,我們可以看到相反的現象,列錨系統對當前車道的定位能力較差。這個問題使得行錨難以定位水平車道(側車道),同樣也使得列錨難以定位垂直車道(當前車道)。根據上述觀察結果,我們建議使用混合錨(行錨和列錨)來分別表示不同的車道。具體地說,我們對當前車道使用行錨,對側邊車道使用列錨。這樣可以緩解放大定位誤差問題,提高性能。
在混合錨系統中,一條車道線可以用錨系統上的坐標表示。如何有效地學習這些坐標是另一個重要的問題。最直接的方法是使用回歸。通常,回歸方法只進行局部范圍的預測,而對長期和全局定位的建模則相對較弱。為了應對全局范圍預測,我們提出了基于分類的方式學習車道坐標,不同的坐標用不同的類別表示。在這項工作中,我們進一步把原始分類擴展為有序分類。在序數分類中,相鄰類之間有密切的序數關系,這與原始分類不同。例如,在ImageNet[18]分類任務中,第7類是黃貂魚(一種魚),第8類是公雞。在我們的工作中,類是有序的(例如,第8類的車道坐標總是在第7類的車道坐標的右側)。有序分類的另一個性質是類的空間是連續的。例如,7.5類這樣的非整數類是有意義的,它可以被視為第7類和第8類之間的中間類。為了實現序數分類,我們提出了兩個損失函數來建模類之間的順序關系,包括基本的分類損失和數學期望損失。利用順序關系和連續類別空間性質,我們能使用數學期望代替argmax來得到連續的預測類。期望損失是為了約束被預測的連續類等于真值。同時約束基本損失和期望損失,可以使輸出具有更好的順序關系,有利于車道的定位。
總而言之,我們工作的主要貢獻有三個方面。
我們提出了一種新穎、簡單、有效的車道檢測范式。與之前的方法相比,我們的方法將車道表示為anchor-based坐標,并以基于分類的方式學習坐標。這個范式在解決沒有視覺線索的問題時是非常快速和有效的。
在此基礎上,提出了一種混合錨系統,進一步擴展了之前的行錨系統,可以有效降低定位誤差。進一步將基于分類的學習擴展到有序分類問題,利用自然順序關系進行分類定位。
所提出的方法達到了最先進的速度和性能。我們最快的模型可以達到300+ FPS,與最先進的性能相當。
本文是我們之前會議出版物[20]的擴展。與會議版本相比,本文有如下擴展:
Hybrid Anchor System通過對放大誤差問題的觀察,我們提出了一種新的混合錨系統,與之前的文章相比,可以有效地減少定位誤差。
Ordinal Classification Losses我們提出了新的損失函數,將車道定位視為一個有序分類問題,進一步提高了性能。
Presentation & Experiments論文的大部分內容被重寫,以提供更清晰的陳述和插圖。我們提供更多的分析、可視化和結果,以更好地覆蓋我們的工作空間。這個版本還提供了更強的結果,在相同的速度下性能提高了6.3個點。
2. 相關工作
自底向上的車道線檢測建模
傳統方法通常使用low-level 圖像處理技術來解決車道線檢測問題。通過使用low-level 圖像處理,傳統方法本質上是以自底向上的方式工作的。他們的主要想法是通過HSI顏色模型和邊緣提取算法等圖像處理來利用視覺線索。Gold是使用立體視覺系統的邊緣提取算法檢測車道線和障礙物的最早嘗試之一。除了利用不同顏色模型和邊緣提取方法的特征外,[25]還提出利用射影幾何和逆透視基于來利用現實世界中車道通常是平行的先驗信息。雖然許多方法嘗試了不同的傳統車道特征,但從low-level 圖像處理中獲得的語義信息在復雜場景中仍然相對不足。這樣,tracking是一種受歡迎的后處理解決辦法,它增強了魯棒性。除tracking外,還采用馬爾可夫和條件隨機場作為后處理方法。此外,還提出了一些采用模板匹配、決策樹、支持向量機等學習機制的方法。
隨著深度學習的發展,一些基于深度神經網絡的方法在車道檢測中顯示出優越性。這些方法通常使用表示車道存在性和位置的heatmap來處理車道線檢測任務。在這些早期的嘗試之后,主流方法開始將車道檢測視為分割問題。例如VPGNet提出了一種由消失點引導的多任務分割網絡,用于車道和道路標記檢測。為了擴大像素級分割的接收域,提高分割性能,SCNN在分割模塊中采用了特殊的卷積運算。它通過對切片特征進行處理,將不同維度的信息一一疊加在一起,類似于循環神經網絡。RONELD提出了一種通過分別尋找和構造直線和曲線動態車道線來增強SCNN的方法。RESA也提出了一種類似的方法,通過周期性特征平移來擴大感受野。由于分割方法的計算量較大,一些研究試圖探索用于實時的輕量級方法。自注意力蒸餾(Self-attention distillation)采用注意力蒸餾機制,將上層和下層的注意力分別視為教師和學生。IntRA-KD還利用inter-region affinity distillation來提高學生網絡的性能。這樣,通過注意力蒸餾,一個淺層網絡可以有與深層網絡相似的表現。CurveLane-NAS引入神經體系結構搜索技術來搜索為車道線檢測量身定制的分割網絡。在LaneAF中,提出了以基于分割的affinity fields形式的投票檢測車道線的方法。FOLOLane采用自底向上的方式,利用全局幾何解碼器對局部模式進行建模,實現全局結構的全局預測。
自頂向下的車道線檢測建模
除了主流的分割范式,一些工作也試圖探索其他范式的車道檢測。在[39]中,采用長短期記憶(LSTM)網絡來處理車道的長線結構。同樣的原理,Fast-Draw預測每個車道點的車道方向,然后按順序將其繪制出來。在[41]中,將車道線檢測問題視為通過聚類二值分割段進行實例分割。E2E提出通過可微最小二乘擬合檢測車道線,并直接預測車道線多項式系數。同樣,Polylanenet和LSTR也分別提出通過深度多項式回歸和Transformer[45]預測車道多項式系數。LaneATT提出使用以圖像中的線條為錨的目標檢測流水線。然后從密集線錨中對車道進行分類和定位。按照利用消隱點先驗和目標檢測流水線,SGNet 提出使用消失點引導的線錨。與2D視角的先前工作不同,也有很多方法嘗試以3D的形式表示車道線。
與以往自下而上的工作不同,我們的方法是一種自頂向下的建模方法。通過自頂向下建模,該方法自然可以更多地關注全局信息,有利于解決無視覺線索問題。與以往的自頂向下方法相比,我們的方法旨在建立一種新的基于行錨和混合錨的車道檢測范式,可以大大降低學習難度,加快檢測速度。通過之前會議版本[20]中提出的范式,我們的工作已經成功地采用并推廣到其他方法[52]。
3. ULTRA FAST LANE DETECTION
在本節中,我們將描述方法的細節。首先,我們在提出的混合錨系統上演示了用坐標表示車道線的方法。其次,展示了網絡架構的設計和相應的有序分類損失。最后,闡述了復雜性分析。
3.1 使用anchors的車道線表示
為了表示車道,我們引入行錨進行車道檢測,如圖3所示。線用行錨上的點表示。但是,行錨系統可能會造成放大定位誤差的問題,如圖2所示。這樣,我們將行錨系統進一步擴展為混合式錨系統。
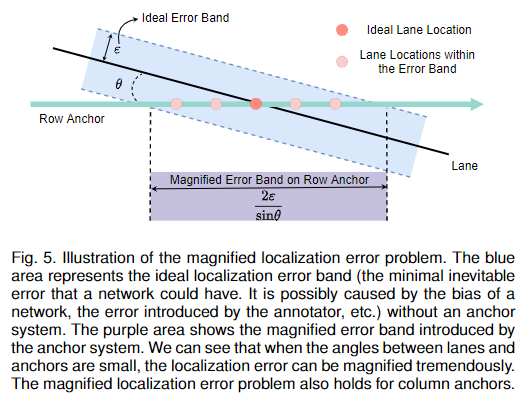
產生這個問題的原因如圖5所示。假設在沒有任何錨系統的情況下,理想的最小定位誤差為,該誤差可由網絡偏差、標注誤差等因素引起。我們可以看到行錨系統的誤差帶需要乘以一個系數 。當車道線和錨的角度非常小時,放大因子 會趨近于無窮大。例如,當車道是嚴格水平的,就不可能用行錨系統來表示車道。這個問題使得行錨難以定位更水平的車道(通常是側邊車道),同樣地,它也使得列錨難以定位更垂直的車道(通常是當前車道)。相反,當車道線和錨垂直時,錨系統引入的誤差最小(),它等于理想定位誤差。
基于上述觀察結果,我們進一步提出使用混合錨來表示車道。針對不同類型的車道線,采用不同的錨系統來減小被放大的定位誤差。具體來說,規則是:一條車道線只能分配一種錨,選擇更垂直的錨類型。在實際操作中,CULane[2]、TuSimple[53]等車道檢測數據集只標注了兩個當前車道和兩個側邊車道,如圖2a所示。這樣,我們將行錨用于當前車道,列錨用于側邊車道,混合錨系統可以緩解放大定位誤差問題。
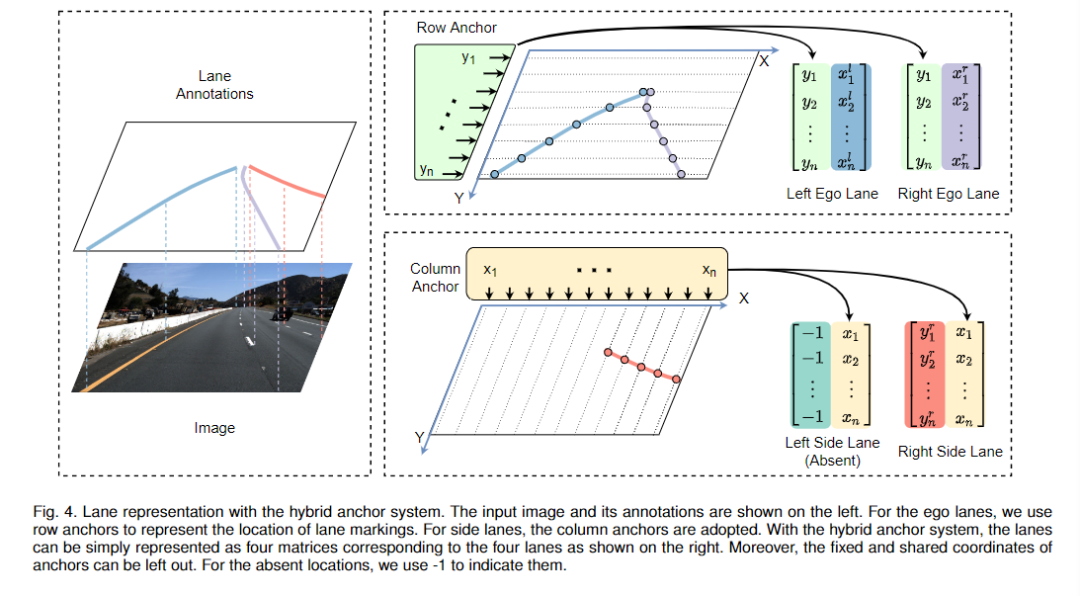
對于混合錨系統,我們可以將車道表示為錨上的一系列坐標,如圖4所示。表示為行錨的數量,為列錨的數量。對于每個車道線,我們首先分配相應的定位誤差最小的錨系統。然后我們計算車道線和每個錨之間的線-線交點,記錄交點的坐標。如果車道線與某些固定的anchors不相交,坐標將被設置為-1. 設行錨的車道線數為,列錨的車道線數為。圖像中的車道線可以用一個固定大小的target T表示,其中每個元素要么是車道的坐標,要么是-1,其長度為 . T可以被分成兩部分 和,對應于行錨和列錨的部分,大小分別是.
3.2 基于anchor的網絡結構設計
我們設計網絡的目標是利用混合錨的車道表示方法,采用分類方式學習固定大小的目標和。為了采用分類方式學習和,我們將和中的不同坐標映射到不同的類。假設和被歸一化(和的元素范圍為0到1或等于- 1,即“無車道”的情況),類別的數量為和。映射可以寫成:
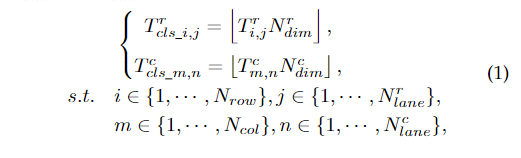
其中,和是坐標的映射類別標簽, 是向下取整, 是 的第i行第j列中的元素。這樣,我們就可以將混合錨上的坐標學習轉化為兩個維數分別為和的分類問題。對于無車道情況,即和 等于 -1,我們使用額外的二分類表示:

其中為坐標存在性的類別標簽,為第i行第j列的元素。列錨的存在性target與之類似:
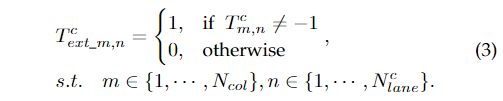
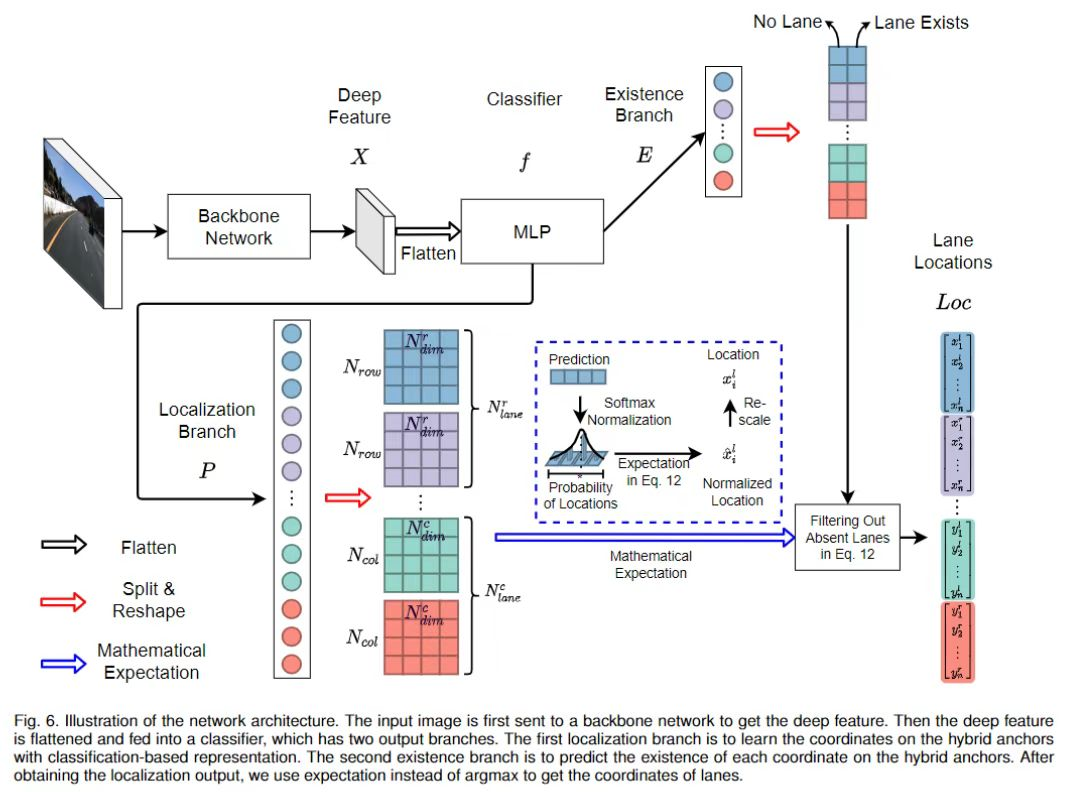
通過以上推導,整個網絡就是學習,,,,,有兩個分支,分別是定位分支和存在性分支。
假設輸入圖像的深度特征為,則網絡可以寫成:
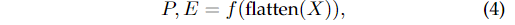
其中和為定位分支和存在性分支,為分類器,為展平操作。和的輸出都由兩部分組成(, , 和),分別對應行錨和列錨。, 的大小分別為,其中和為行錨和列錨的映射分類維度。和的大小分別為。在等式 4中,我們直接將來自主干的深度特征展平,并將其提供給分類器。傳統的分類網絡使用了GAP (global average pooling)。我們之所以使用flatten而不是GAP,是因為我們發現空間信息對基于分類的車道檢測網絡至關重要。使用GAP會消除空間信息,導致性能較差。
3.3 有序分類損失
由式1可以看出,上述分類網絡的一個基本性質是類之間存在順序關系。與傳統的分類不同,我們的分類網絡將相鄰類定義為緊密有序的關系。為了更好地利用順序關系的先驗性,我們提出使用基本分類損失和期望損失。基本分類損失定義如下:
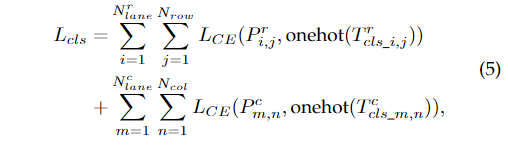
其中 是交叉熵損失, 為第i個車道分配給行錨和第j個行錨的預測,為對應的分類標簽 ,為第m個車道分配給列錨和第n個列錨對應的分類標簽, 對應的分類標簽,為獨熱編碼函數。由于類別是有序的,因此預測的期望可以看作是平均投票結果。為方便起見,我們將期望表示為:
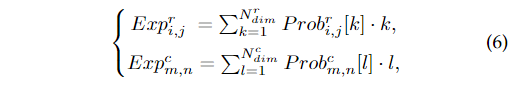
其中表示索引操作符。的定義為:
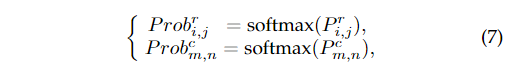
這樣,我們就可以約束預測的期望,使其更接近真實值。因此,我們有如下期望損失:
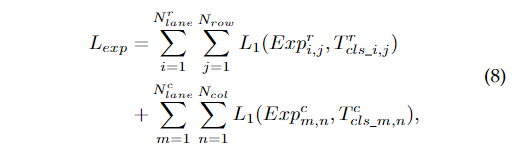
其中 是平滑L1損失。
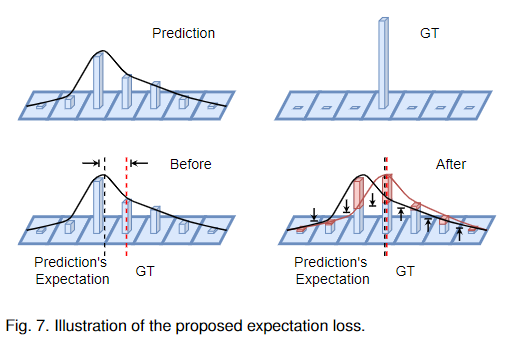
期望損失的說明如圖7所示。我們可以看到,期望損失可以將預測分布的數學期望推向真值位置,從而有利于車道的定位。
另外存在性分支的損失函數定義為:

最終,所有的損失可以被寫為:
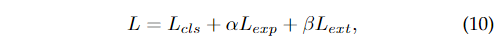
其中是loss的系數。
3.4 網絡推理
在本節中,我們將展示如何在推理期間獲得檢測結果。以行錨系統為例,設和是第i車道和第j個錨的預測。那么和的長度分別為和。每個車道位置的概率可以寫成:
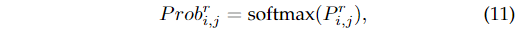
其中,的長度為,然后根據預測分布的數學期望得到車道線的位置。并且根據存在性分支的預測濾除不存在的車道的預測:
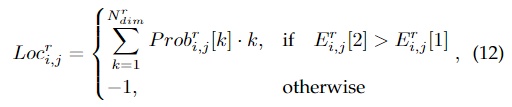
最后,對得到的位置進行縮放以適應輸入圖像的大小。網絡架構的總體示意圖如圖6所示。
分析和討論
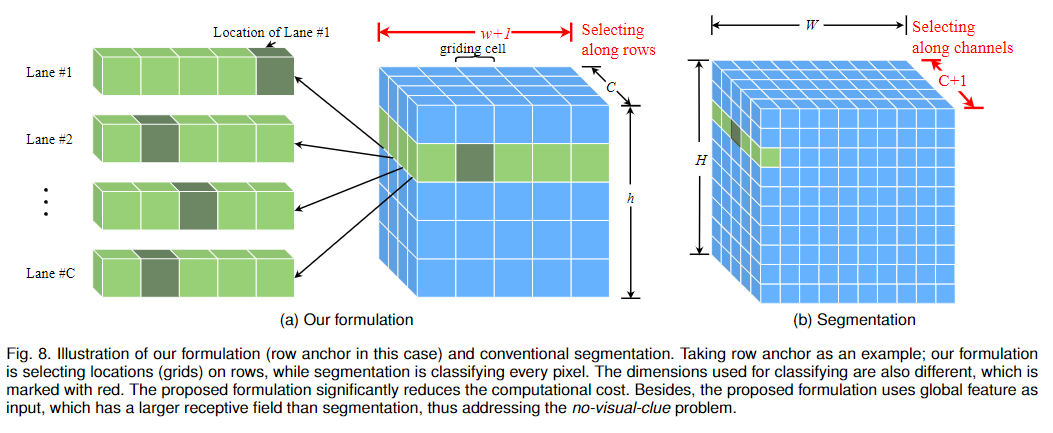
在這一節中,我們首先分析了我們的方法的復雜度,并給出了我們的方法能夠實現超高速的原因。為了分析復雜度,我們使用分割作為基準。我們的公式(以行錨為例)和分割的差異如圖8所示。可以看出,我們的范式比常用的分割要簡單得多。假設圖像大小為。由于分割是像素分類,所以需要進行分類。對于我們的方法,包含混合錨上車道線的坐標的學習目標T的長度為。因為我們只需要少量錨點來表示車道線,則, 。和車道分別為行錨和列錨的車道數,這和其他變量相比是很小的。這樣,我們有:
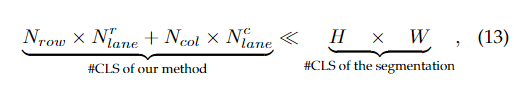
其中#CLS表示“分類數量”.以CULane數據集的設置為例,我們有。我們的方法的分類數為118,而分割的分類數為。考慮到分類維度,我們的方法的理想計算數為,而分割的理想計算數為。我們的分類頭和分割頭使用ERFNet的計算代價分別為和。

除理論分析外,本文方法的實際前向推理耗時如圖9a所示。我們可以看到骨干占據了大部分的時間。相比之下,基于分類的車道檢測頭效率高,只花費不到整個推理時間的5%。
4. 實驗
在本節中,我們通過大量的實驗證明了我們方法的有效性。以下章節主要圍繞三個方面展開:1)實驗設置。2)本方法的消融研究。3)四種主要車道檢測數據集的結果。
4.1.3 實現細節
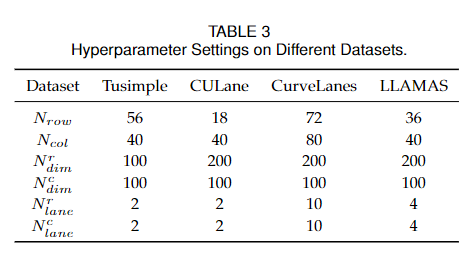
超參數設置如表3所示。關于錨數量和類別維度的消融研究分別見4.2.4節和4.2.5節。在優化過程中,CULane和TuSimple上的圖片大小分別調整為1600×320和800×320。式10中的損失函數系數α和β分別設為0.05和1。batch size設置為每個GPU 16個,所有數據集的訓練epoch總數設置為30個。使用SGD優化器,學習率被設置為0.1,并在第25個epoch降低10倍。所有模型均使用PyTorch[60]和Nvidia RTX 3090 gpu進行訓練和測試。
4.1.4 特征級測試時數據增強
在這一部分,我們展示了我們的方法的測試時數據增強方法。因為我們的方法以基于全局特征的分類方式工作,這為我們提供了一個在特征級別上進行快速測試時間增加的機會。與目標檢測中通常需要反復計算整個骨干的TTA不同,我們直接在骨干特征的基礎上進行FLTTA。主干特征計算一次,然后在向上、向下、向左、向右的方向進行空間平移。然后,將5個增強特征副本批量輸入分類器。最后,對輸出進行集成,以便在測試過程中提供更好的預測。由于主干特征只計算一次,分類器的計算以批處理的方式工作,這利用了gpu的并行機制,所以FLTTA的工作速度幾乎與沒有TTA的普通測試一樣快。圖9b為FLTTA前向推理的時序餅圖。
4.1.5 數據增強
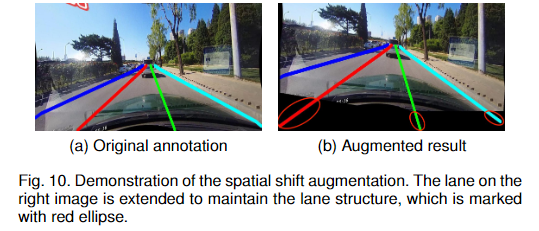
在調整大小和裁剪等簡單的數據增強條件下,該方法可以快速地對整個訓練集進行過擬合(訓練精度接近100%,但在測試集上的表現較差)。為了克服過擬合問題,我們提出了一種空間平移數據增強方法,在空間上隨機移動整個圖像和車道線標注,使網絡能夠學習車道線的不同空間模式。由于空間變換后部分圖像和車道線標注被裁剪,我們將車道線標注擴展到圖像邊界。圖10顯示了增強效果。
4.2 消融實驗
在本節中,我們通過幾個消融研究來驗證我們的方法。實驗設置均與4.1節相同。所有消融實驗都是在ResNet-18網絡的主干上進行的。
4.2.1 混合anchor系統的高效性
正如我們在3.1節中所述,行錨和列錨系統在車道線檢測中發揮著不同的作用。基于此,我們提出了一種混合錨系統,該系統將不同的車道線分配給相應的錨類型。
為了驗證混合錨系統的有效性,我們在CULane上進行了三個實驗。結果如表4所示。
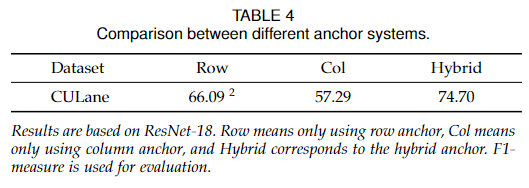
可見,混合錨系統相比行錨和列錨有明顯的改善,證明了混合錨的有效性。
4.2.2 有序分類的有效性
我們的方法將車道檢測定義為一個有序分類問題。一個很自然的問題是,與其他方法如回歸和常規分類相比如何呢?對于回歸方法,我們用一個相似的回歸頭替換管道中的分類器頭。training loss替換為Smooth L1 loss。對于傳統的分類方法,我們使用與流水線中相同的分類器頭。分類與有序分類的區別在于損失和后處理。
1)分類設置只使用交叉熵損失,而順序分類設置則使用Eq. 10中的三種損失。2)分類設置使用argmax作為標準后處理,有序分類設置使用期望。比較如表5所示。
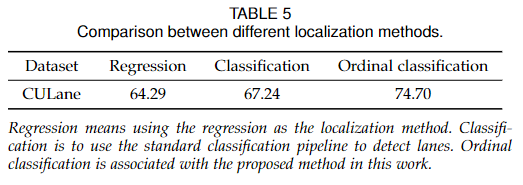
我們可以看到,期望分類方法可以獲得比標準分類方法更好的性能。同時,基于分類的方法始終優于基于回歸的方法。
4.2.3 有序分類損失的消融
如3.3節所述,我們將車道檢測問題建模為有序分類問題。為了驗證該模塊的有效性,我們展示了有序分類損失的消融研究。如表6所示,我們提出的期望損失約束有效地提高了車道檢測的性能。與標準交叉熵損失相比,所提出的期望損失具有不同的幾何性質,即期望損失類似于通過減少遠離真實值的logits和增加接近真實值的logits來逐步將預測的期望推向真實值。同時,與傳統分類方法相比,平均定位誤差也有所降低。

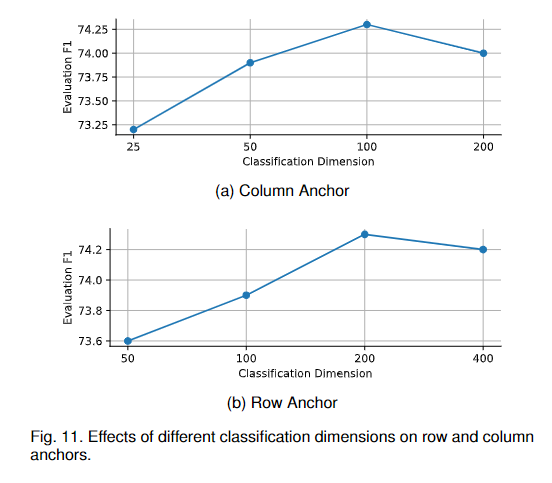
4.2.4 分類維度的影響
如Eq. 4所示,我們使用基于分類的范式來檢測車道線,不同的車道線位置用不同的類別表示。這就產生了一個問題,需要多少類來進行車道線檢測。為了討論這個問題,我們首先設置行錨的分類維數為200,列錨的分類維數為25、50、100、200進行實驗。結果如圖11a所示。然后,我們將設定為100,并在為50、100、200、400時進行實驗。結果如圖11b所示。我們可以看到,隨著分類維度的增加,性能呈現先增加后降低的趨勢。維度越小,分類就越容易,但每個類代表的位置范圍就越大,即每個類的定位能力就越差。維度越大,每個類代表的位置范圍就越窄(每個類的本地化能力就更好),但是分類本身就更難。最終的性能是分類難度和每個類的定位能力之間的權衡。所以我們設置為100,為200。
4.2.5 錨數量的影響
在我們的方法中還有另一個重要的超參數:用于表示車道的錨點數量(和)。這樣,我們將行錨定的數量設置為18,并將列錨定的數量設置為10、20、40、80和160進行實驗。結果如圖12a所示。然后,我們將設為40,并將設為5、9、18、36和72進行實驗。結果如圖12b所示。
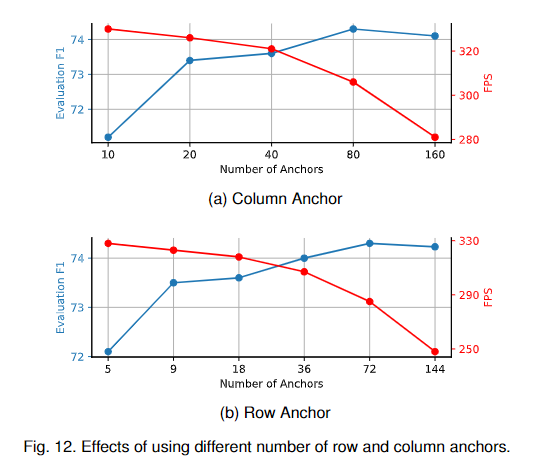
我們可以看到,隨著行錨數量的增加,性能也會普遍提高。但檢測速度也會逐漸下降。通過這種方式,我們將和分別設置為18和40,以在基于resnet -18的模型中獲得性能和速度之間的平衡。對于像ResNet-34這樣的大型模型,我們將和分別設置為72和80。
結果
本節展示了四個車道檢測數據集的結果,分別是TuSimple、CULane、CurveLanes和LLAMAS數據集。在這些實驗中,我們使用ResNet-18和ResNet-34作為我們的骨干網絡。
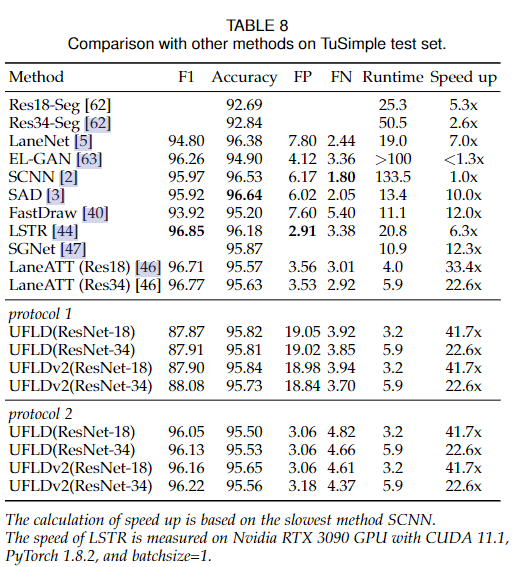
從表7可以看出,我們的方法達到了最快的速度。與之前的會議版本相比,在相同的速度下,我們的性能提升了6.3個點,得到了更強的結果。它證明了所提出的公式在這些具有挑戰性的場景中的有效性,因為我們的方法可以利用全局信息來解決無視覺線索和效率問題。最快的模式達到300+ FPS。
為了驗證我們的方法,我們使用了兩個協議。協議1輸出所有車道線,不存在的車道線用invalid表示,與會議版本相同。協議2直接丟棄不存在的車道線。結果如表8所示。
另一個我們應該注意到的有趣現象是,當骨干網絡與普通分割相同時,我們的方法獲得了更好的性能和更快的速度,這是一個帶有resnet骨干網的DeeplabV2[62]模型。結果表明,該方法優于分割方法,驗證了該方法的有效性。
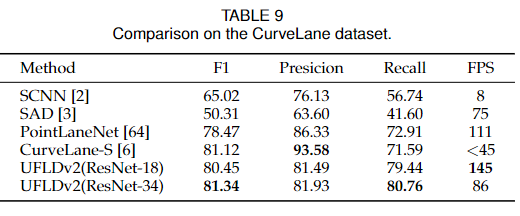
對于CurveLanes數據集,我們在表9中顯示了結果。我們可以看到,與CurveLane-S方法相比,我們的方法在保持更快速度的同時取得了更好的性能。
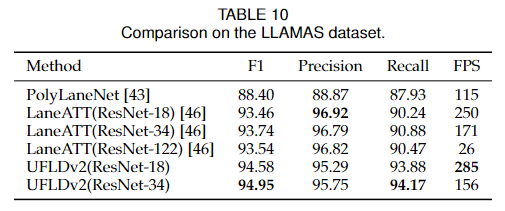
對于LLAMAS數據集,我們在表10中顯示了結果。可以看出,我們的方法也取得了最好的性能和最快的速度。
我們的方法在四個數據集上的可視化結果如圖13和圖14所示。


結論
在本文中,我們提出了一種混合錨系統和有序分類新范式,以實現優秀的速度和精度。該方法將車道線檢測看作是在基于全局特征的自頂向下分類的混合錨系統上直接學習稀疏坐標。這樣可以有效地解決效率和無視覺線索的問題。通過定性和定量實驗驗證了所提出的混合錨系統和有序分類損失的有效性。我們的方法中輕量級的ResNet-18版本甚至可以達到300+ FPS。我們的方法也存在一些缺點。
審核編輯:郭婷
-
adas
+關注
關注
309文章
2184瀏覽量
208633 -
自動駕駛
+關注
關注
784文章
13787瀏覽量
166404
原文標題:速度精度雙SOTA! TPAMI2022最新車道線檢測算法(Ultra-Fast-Lane-Detection-V2)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
錨桿與圍巖加載過程紅外特征研究
基于自頂向下技術的工程機械Digital Prototyping設計方法及應用
基于自頂向下技術的工程機械Digital Prototyping設計方法及應用
空間雙索面自錨式懸索橋總體布置

一種新的基于全局特征的極光圖像分類方法
電能質量混合擾動分類
EDA設計一般采用自頂向下的模塊化設計方法
計算機網絡:自頂向下
eda自頂向下的設計方法 eda自頂向下設計優點
微美全息(NASDAQ:WIMI)探索全局-局部特征自適應融合網絡框架在圖像場景分類中的創新運用





 工商網監
工商網監
評論