

摘要
自動(dòng)駕駛汽車(chē)的魯棒環(huán)境感知是一項(xiàng)巨大的挑戰(zhàn),這使得多傳感器配置與例如相機(jī)、激光雷達(dá)和雷達(dá)至關(guān)重要。在理解傳感器數(shù)據(jù)的過(guò)程中,3D 語(yǔ)義分割起著重要的作用。因此,本文提出了一種基于金字塔的激光雷達(dá)和攝像頭深度融合網(wǎng)絡(luò),以改進(jìn)交通場(chǎng)景下的 3D 語(yǔ)義分割。單個(gè)傳感器主干提取相機(jī)圖像和激光雷達(dá)點(diǎn)云的特征圖。一種新穎的 Pyramid Fusion Backbone 融合了這些不同尺度的特征圖,并將多模態(tài)特征組合在一個(gè)特征金字塔中,以計(jì)算有價(jià)值的多模態(tài)、多尺度特征。Pyramid Fusion Head 聚合這些金字塔特征,并結(jié)合傳感器主干的特征在后期融合步驟中進(jìn)一步細(xì)化。該方法在兩個(gè)具有挑戰(zhàn)性的戶(hù)外數(shù)據(jù)集上進(jìn)行了評(píng)估,并研究了不同的融合策略和設(shè)置。論文基于range view的lidar方法已經(jīng)超過(guò)迄今為止提出的所有融合策略和結(jié)構(gòu)。 論文的主要貢獻(xiàn)如下:
模塊化多尺度深度融合架構(gòu),由傳感器主干和新穎的金字塔融合網(wǎng)絡(luò)組成;
金字塔融合主干用于激光雷達(dá)和圖像在range view空間中的多尺度特征融合;
金字塔融合頭用于聚合和細(xì)化多模態(tài)、多尺度的金字塔特征。
相關(guān)工作
2D語(yǔ)義分割
全卷積網(wǎng)絡(luò)(FCN)開(kāi)創(chuàng)了2D語(yǔ)義分割的新局面。全卷積網(wǎng)絡(luò)專(zhuān)為端到端像素級(jí)預(yù)測(cè)而設(shè)計(jì),因?yàn)樗鼈冇镁矸e替換全連接層。由于最初的 FCN 難以捕捉場(chǎng)景的全局上下文信息 [7],因此出現(xiàn)了新的結(jié)構(gòu) [7]-[9] — 基于金字塔特征進(jìn)行多尺度上下文聚合,在收集全局上下文的同時(shí)保留精細(xì)細(xì)節(jié)。PSPNet [7] 應(yīng)用了一個(gè)金字塔池化模塊(PPM),其結(jié)合最后一個(gè)特征圖的不同尺度。因此,網(wǎng)絡(luò)能夠捕獲場(chǎng)景的上下文以及精細(xì)的細(xì)節(jié)。HRNetV2 [9] 等其他方法利用主干中已經(jīng)存在的金字塔特征進(jìn)行特征提取。對(duì)于全景分割的相關(guān)任務(wù),EfficientPS [8] 通過(guò)應(yīng)用雙向特征金字塔網(wǎng)絡(luò) (FPN) [10],自底向上和自頂向下結(jié)合各種尺度的特征,之后使用語(yǔ)義頭,包含大規(guī)模特征提取器 (LSFE)、密集預(yù)測(cè)單元 (DPC) [11] 和不匹配校正模塊 (MC),以捕獲用于語(yǔ)義分割的大尺度和小尺度特征。
3D語(yǔ)義分割
與將 CNN 應(yīng)用于規(guī)則網(wǎng)格排列的圖像數(shù)據(jù)相比,它們不能直接應(yīng)用于 3D 點(diǎn)云。目前得到廣泛應(yīng)用的已經(jīng)有幾種表示形式和專(zhuān)門(mén)的體系結(jié)構(gòu)。 直接處理非結(jié)構(gòu)化原始數(shù)據(jù)的先驅(qū)方法是 PointNet [3],它應(yīng)用共享的多層感知器來(lái)提取每個(gè)輸入點(diǎn)云的特征。由于必須對(duì)任何輸入排列保持不變,因此使用對(duì)稱(chēng)操作來(lái)聚合特征。進(jìn)一步PointNet++ [4] 通過(guò)點(diǎn)云的遞歸分層組合來(lái)利用特征之間的空間關(guān)系。 不處理原始點(diǎn)云而將其轉(zhuǎn)換為離散空間的方法,例如 2D 或 3D 柵格。一種基于球面投影的新穎的2D柵格表示,即range view。SqueezeSeg [12] 是最早利用這種表示進(jìn)行道路目標(biāo)分割的方法之一。最新的方法 SqueezeSegV3 [13] 使用空間自適應(yīng)卷積來(lái)消除range view的變化特征分布。RangeNet++ [1] 提出了一種有效的基于 kNN 的后處理步驟,以克服球面投影引起的一些缺點(diǎn)。與以前的方法相比,SalsaNext [2] 改進(jìn)了網(wǎng)絡(luò)結(jié)構(gòu)的各個(gè)方面,例如用于解碼的pixel-shuffle和 Lovasz-Softmax-Loss [14] 的使用。[15]中使用了卷積的另一種適應(yīng),這種方法應(yīng)用輕量級(jí)harmonic dense卷積來(lái)實(shí)時(shí)處理range view,并取得了不錯(cuò)的結(jié)果。此外,出現(xiàn)了利用多種表示的混合方法 [16]、[17]。
3D 多傳感器融合
多傳感器融合在計(jì)算機(jī)視覺(jué)的不同任務(wù)中受到廣泛關(guān)注。相機(jī)和激光雷達(dá)功能的結(jié)合主要用于 3D 目標(biāo)檢測(cè)。語(yǔ)義分割等密集預(yù)測(cè)所需的特征的密集融合只有少數(shù)工作[18]-[21]進(jìn)行了研究。 在 [18] 中,將基于密集和roi的融合應(yīng)用于多個(gè)任務(wù),包括 3D 目標(biāo)檢測(cè)。另一種 3D 目標(biāo)檢測(cè)方法 [19] 使用連續(xù)卷積來(lái)結(jié)合密集相機(jī)和激光雷達(dá)的BEV特征。融合層將多尺度圖像特征與網(wǎng)絡(luò)中不同尺度的激光雷達(dá)特征圖融合在一起。 LaserNet++ [20] 實(shí)現(xiàn)目標(biāo)檢測(cè)和語(yǔ)義分割兩個(gè)任務(wù)。其首先通過(guò)殘差網(wǎng)絡(luò)處理相機(jī)圖像。使用投影映射,將相機(jī)特征轉(zhuǎn)換為range view。之后,concat的特征圖被輸入到 LaserNet [22]。Fusion3DSeg [21] 對(duì)相機(jī)和激光雷達(dá)特征使用迭代融合策略。在 Fusion3DSeg 中,相機(jī)和range view特征按照迭代深度聚合策略進(jìn)行融合,以迭代融合多尺度特征。最終特征進(jìn)一步與來(lái)自 3D 分支的基于點(diǎn)云的特征相結(jié)合,而不是常用的基于 kNN 的后處理 [1]特征。 與 [18] 相比,[19] 所提出的方法是模塊化的,并且各個(gè)傳感器主干彼此獨(dú)立,因?yàn)闆](méi)有圖像特征被送到激光雷達(dá)主干。此外,[19]提出了一種新穎的雙向金字塔融合策略。而 LaserNet++ [22] 只融合一次,不使用多尺度融合。Fusion3DSeg [21] 是最相關(guān)的工作,使用了迭代融合策略,這與本文的并行自底向上和自頂向下的金字塔策略有很大不同。
方法
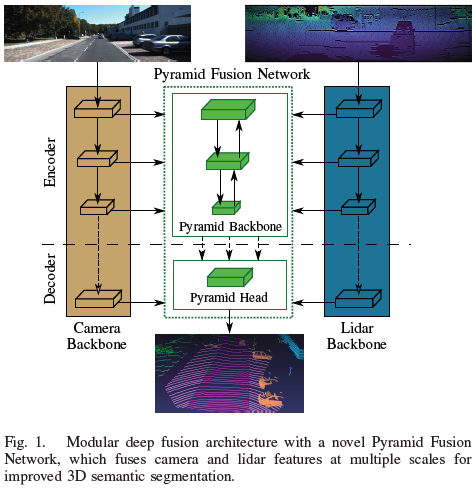
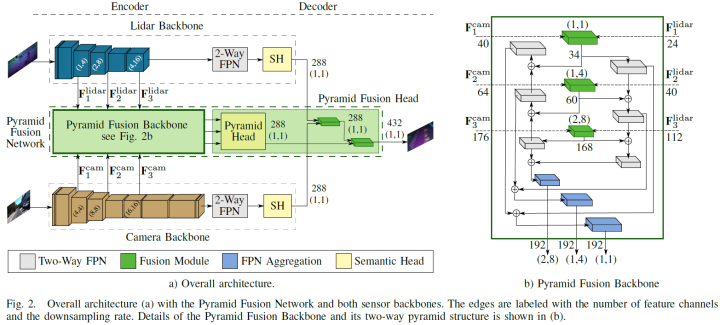
論文提出的深度傳感器融合方法PyFu由四個(gè)主要部分組成。包含兩個(gè)主干,分別提取lidar和圖像特征,之后是Pyramid Fusion Backbone,以自頂向下和自底向上的方式在不同尺度上融合兩種模式的編碼器特征。進(jìn)一步,Pyramid Fusion Head 結(jié)合了這些特征,并在后期融合步驟中將它們與兩個(gè)傳感器主干特征結(jié)合起來(lái)得到最終輸出。整體結(jié)構(gòu)如下圖a所示。模塊化的方式訓(xùn)練策略的選擇允許論文的方法處理相機(jī)不可用、更換主干或傳感器而不影響另一個(gè),并聯(lián)合預(yù)測(cè)相機(jī)和激光雷達(dá)語(yǔ)義分割任務(wù)。因此,兩個(gè)主干都對(duì)其傳感器數(shù)據(jù)進(jìn)行了預(yù)訓(xùn)練,并在整個(gè)融合架構(gòu)的訓(xùn)練過(guò)程中凍結(jié)。所以論文的算法可以預(yù)測(cè)單個(gè)傳感器的語(yǔ)義結(jié)果,作為無(wú)相機(jī)或額外相機(jī)分割的備選。
Lidar主干
激光雷達(dá)主干根據(jù) [21]、[23] 的球面投影計(jì)算輸入點(diǎn)云的特征,這些特征在range view中表示。其受 EfficientPS [8] 的啟發(fā),并適應(yīng)了range view。與相機(jī)圖像相比,range images的分辨率較小,尤其是垂直方向,因此前兩個(gè)stage的下采樣步驟僅在水平方向執(zhí)行。此外,論文使用 EfficientNet-B1 [24] 作為編碼器并刪除最后三個(gè)stage。因此,雙向 FPN 只有三個(gè)stage而不是四個(gè)stage,并且輸出通道減少到 128 個(gè),因?yàn)?EfficientNet-B1 使用的特征通道比 EfficientNet-B5 少。如上圖 a 所示,第三、第四和第六stage的特征圖輸入至 Pyramid Fusion Backbone中,用于與相機(jī)特征融合。由于移除了 FPN,相應(yīng)的 DPC 模塊 [8] 也從語(yǔ)義頭中移除。頭部為 Pyramid Fusion Head 的后期融合提供其輸出特征。
Camera主干
論文研究的第一個(gè)主干還是 EfficientPS,但使用原始的 Efficient-B5 作為編碼器。與激光雷達(dá)主干相比,EfficientPS 可以直接作為相機(jī)主干。同樣,第三、第四和第六stage的特征圖輸入至 Pyramid Fusion Backbone。對(duì)于 Pyramid Fusion Head 中的后融合步驟,使用語(yǔ)義頭的輸出。 此外,選擇基于ResNet101 [25] 的 PSPNet 作為另一個(gè)主干。ResNet101 的 conv3_4、conv4_23 和 conv5_3 層的三個(gè)特征圖作為 Pyramid Fusion Backbone 的輸入提供。PPM 的輸出作為后期融合的輸入。
金字塔融合網(wǎng)絡(luò)
融合算法的核心模塊是 Pyramid Fusion Network,其融合了激光雷達(dá)和相機(jī)的特征。融合模塊將特征轉(zhuǎn)換至同一空間下,然后對(duì)兩種模態(tài)進(jìn)行融合。Pyramid Fusion Backbone 在不同尺度下進(jìn)行融合,并且以自頂向下和自底向上的方式聚合和組合得到的融合特征,如上圖 b 所示。Pyramid Fusion Head 在后期融合步驟中對(duì)這些多模態(tài)、多尺度特征進(jìn)行組合和進(jìn)一步細(xì)化。
特征轉(zhuǎn)換
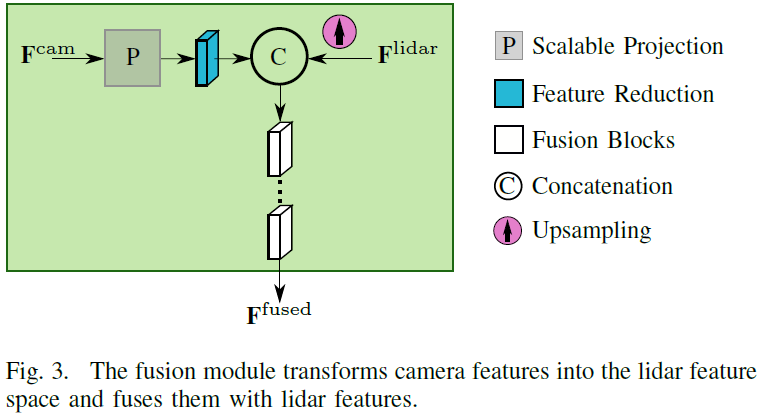
為了實(shí)現(xiàn)激光雷達(dá)和攝像頭的融合,特征需要在同一空間下。因此,需要進(jìn)行圖像到range view空間的特征投影。此外,投影必須適合不同尺度的特征圖。為了解決這個(gè)任務(wù),論文使用了Fusion3DSeg [21]、[26] 的可擴(kuò)展投影。總體思路是根據(jù)3D點(diǎn)云創(chuàng)建從圖像到range view的坐標(biāo)映射。每個(gè)點(diǎn)云都可以投影到range view以及圖像中,從而在圖像和range view坐標(biāo)之間創(chuàng)建所需的鏈接。
融合模塊
特征轉(zhuǎn)換和融合由融合模塊執(zhí)行,如下圖。首先,兩個(gè)傳感器的特征圖都被裁剪至相同的視野,因?yàn)槿诤现荒茉谶@個(gè)區(qū)域進(jìn)行。圖像特征通過(guò)上述特征轉(zhuǎn)換在空間上轉(zhuǎn)換到range view空間上,然后學(xué)習(xí)特征投影以對(duì)齊激光雷達(dá)和圖像的特征空間,由一個(gè)反向殘差塊 (IRB) [8] 實(shí)現(xiàn)。lidar特征使用雙線(xiàn)性插值對(duì)齊圖像特征的大小,以方便進(jìn)行融合。然后將對(duì)齊后的兩個(gè)特征concat,后面使用一個(gè)或多個(gè)用于學(xué)習(xí)融合的殘差模塊。該模塊旨在利用不同類(lèi)型和數(shù)量的block來(lái)實(shí)現(xiàn)不同的融合策略。論文研究了一種基于Bottleneck Residual Block (BRB) [27] 的策略,以及使用 IRB (Inverted Residual Block )的反向殘差融合策略。
金字塔融合主干
所提出的融合模塊被合并到雙向 FPN 中以融合不同尺度的多傳感器特征,然后是自底向上和自頂向下的聚合以計(jì)算多模態(tài)、多尺度特征。從激光雷達(dá)主干中,三種不同尺度的特征輸入至對(duì)應(yīng)的融合模塊。在那里,特征圖被上采樣到目標(biāo)輸出分辨率,并與來(lái)自圖像主干的特征圖融合,這些特征圖也來(lái)自三個(gè)不同的尺度。然后將融合得到的三個(gè)特征圖聚合在自底向上和自頂向下的特征金字塔中,以計(jì)算多尺度特征。這樣,不同尺度的多模態(tài)特征的進(jìn)行融合,一方面是精細(xì)的細(xì)節(jié),包含越來(lái)越多的上下文,另一方面是上下文,添加的細(xì)節(jié)越來(lái)越多。最終組合兩個(gè)金字塔輸出,并將生成的多模態(tài)、多尺度金字塔特征傳遞給 Pyramid Fusion Head。
金字塔融合head
head的第一步類(lèi)似于激光雷達(dá)主干的語(yǔ)義head,其結(jié)合了來(lái)自雙向 FPN 的三個(gè)特征圖。進(jìn)一步,論文使用圖像主干和lidar主干的最后一層特征,以改進(jìn)金字塔融合網(wǎng)絡(luò)的特征。最終的特征圖接一個(gè) 1x1 卷積和softmax,得到分割結(jié)果。論文也使用了基于 kNN 的后處理 [1]步驟。
實(shí)驗(yàn)結(jié)果
本文在SemanticKITTI [28] and PandaSet [29]兩個(gè)數(shù)據(jù)集上展開(kāi)實(shí)驗(yàn)。
金字塔融合網(wǎng)絡(luò)
論文首先在SemanticKITTI上展開(kāi)實(shí)驗(yàn),結(jié)果如下表所示。總體而言,PyFu 的性能分別優(yōu)于兩個(gè)基線(xiàn) +3.9% 和 +2.7%,推理時(shí)間為 48 毫秒。
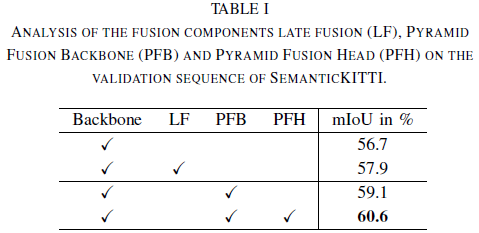
下一步,研究融合模塊內(nèi)部的不同融合策略,結(jié)果如下表所示。首先,評(píng)估不同策略對(duì)金字塔主干 PFB 的影響。使用 BRB 后跟Residual Basic Block (BB) [27] 的bottleneck fusion策略?xún)?yōu)于IRB 的反向策略。這也適用于整個(gè) Pyramid Fusion Network。
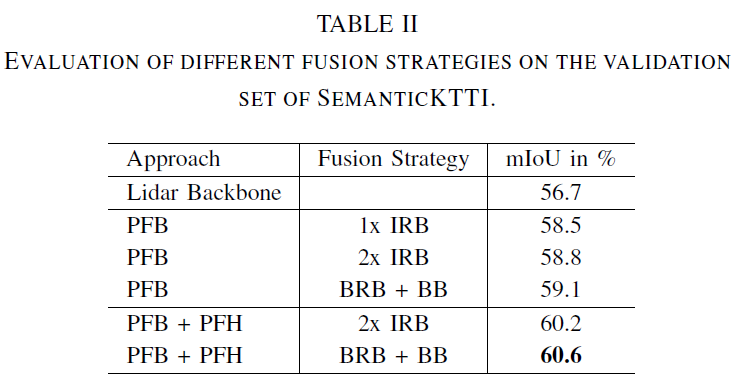
論文進(jìn)一步在PandaSet上展開(kāi)實(shí)驗(yàn),相比于基線(xiàn)實(shí)現(xiàn)了+8.8% 的顯著改進(jìn)。
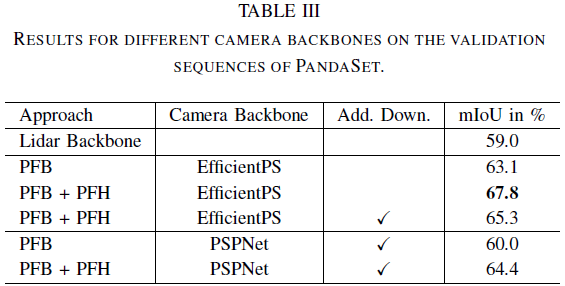
可視化結(jié)果如下:

定量結(jié)果
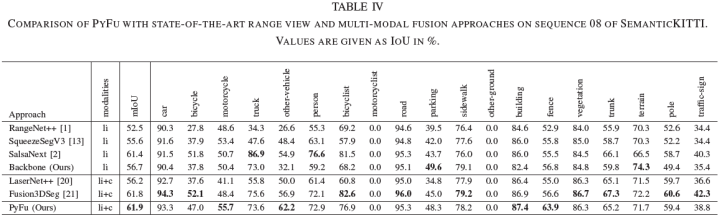
進(jìn)一步,論文與SOTA的基于range view的方法進(jìn)行比較,以評(píng)估多傳感器融合的優(yōu)勢(shì),SemanticKITTI上的結(jié)果如下表所示。總體上優(yōu)于所有激光雷達(dá)方法。值得一提的是,增益的主要來(lái)自融合,而不是基線(xiàn)。這再次強(qiáng)調(diào)了圖像特征對(duì)改進(jìn) 3D 語(yǔ)義分割的價(jià)值。論文進(jìn)一步比較了與其他融合網(wǎng)絡(luò)的性能。金字塔融合策略?xún)?yōu)于所有其他融合方法,PyFu 和 Fusion3DSeg [21] 的性能優(yōu)勢(shì)表明多尺度傳感器融合的巨大潛力。
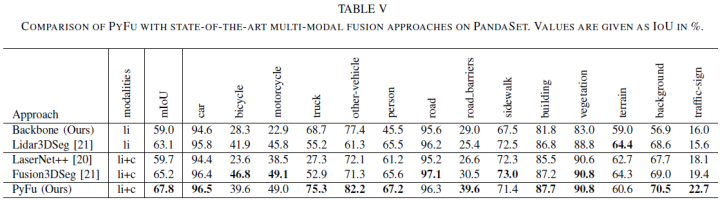
最后,論文在PandaSet數(shù)據(jù)集上對(duì)比了集中方法,結(jié)果如下表所示:
審核編輯:郭婷
-
傳感器
+關(guān)注
關(guān)注
2562文章
52524瀏覽量
763462 -
攝像頭
+關(guān)注
關(guān)注
61文章
4948瀏覽量
97634 -
激光雷達(dá)
+關(guān)注
關(guān)注
971文章
4189瀏覽量
191873
原文標(biāo)題:最新SOTA | 基于range和camera融合的多模態(tài)3D語(yǔ)義分割(IV2022)
文章出處:【微信號(hào):3D視覺(jué)工坊,微信公眾號(hào):3D視覺(jué)工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
無(wú)人駕駛技術(shù)中的激光雷達(dá)和攝像頭都干些什么?
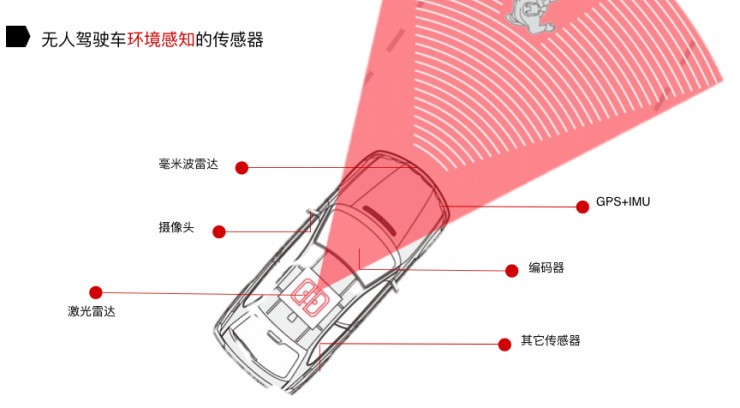
速騰聚創(chuàng)激光雷達(dá)現(xiàn)在實(shí)現(xiàn)量產(chǎn)
淺析自動(dòng)駕駛發(fā)展趨勢(shì),激光雷達(dá)是未來(lái)?
激光雷達(dá)是自動(dòng)駕駛不可或缺的傳感器
拆解的固態(tài)激光雷達(dá)有了這些新發(fā)現(xiàn)
基于深度神經(jīng)網(wǎng)絡(luò)的激光雷達(dá)物體識(shí)別系統(tǒng)
一種金字塔注意力網(wǎng)絡(luò),用于處理圖像語(yǔ)義分割問(wèn)題

英特爾實(shí)感激光雷達(dá)深度攝像頭L515解析
基于規(guī)范化函數(shù)的深度金字塔模型算法
激光雷達(dá)、單目攝像頭、雙目攝像頭原理和優(yōu)缺點(diǎn)

詳解無(wú)人駕駛傳感器:攝像頭、激光雷達(dá)、雷達(dá)、溫度傳感器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論