") 基于訓練階段使用知識庫+KNN檢索相關(guān)信息輔助學習方法
基于訓練階段使用知識庫+KNN檢索相關(guān)信息輔助學習方法
在prompt learning中一個核心問題是模型存在死記硬背現(xiàn)象。Prompt learnin主要應用在few-shot learning場景,先將訓練數(shù)據(jù)轉(zhuǎn)換成prompt的形式,在訓練過程模型側(cè)重于記憶訓練數(shù)據(jù),然后使用記憶的信息做預測。這個過程會導致模型缺乏泛化能力,一些長尾的case預測效果不好。
NIPS 2022中浙大和阿里提出使用檢索方法增強prompt learning,利用訓練數(shù)據(jù)構(gòu)造知識庫,在訓練階段使用知識庫+KNN檢索相關(guān)信息輔助學習,通過這種方式將需要記憶的信息從模型中拆分出來,直接輸入到模型中。通過這種方式,可以讓模型參數(shù)更側(cè)重泛化信息的學習,而不是過擬合訓練數(shù)據(jù)。下面為大家詳細介紹一下這篇工作。
NLP Prompt系列——Prompt Engineering方法詳細梳理
1 Prompt Learning回顧
Prompt learning主要面向的是訓練數(shù)據(jù)較少的場景。首先需要一個預訓練模型,然后將下游任務轉(zhuǎn)換成完形填空的形式。對于分類問題,判斷某個text屬于哪個label,轉(zhuǎn)換成如下的文本輸入到預訓練語言模型中:
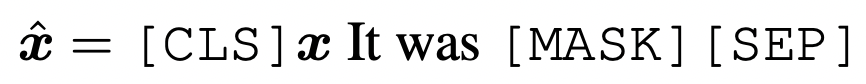
利用預訓練語言模型,預測出[MASK]對應的文本,后面接一個文本到label的映射函數(shù),即可實現(xiàn)文本分類任務。Prompt learning的好處是可以充分利用預訓練語言模型的知識,讓下游任務和預訓練任務更加適配,以提升樣本量不足情況下的效果。我在之前的文章NLP Prompt系列——Prompt Engineering方法詳細梳理詳細介紹過prompt相關(guān)工作,感興趣的同學可以進一步閱讀。
雖然這種方法充分運用了預訓練語言模型的知識,但畢竟finetune的數(shù)據(jù)少,模型更像在死記硬背訓練prompt數(shù)據(jù)中的信息。這對于長尾樣本或非典型的句子的預測效果不友好。為了解決上述問題,本文的核心思路是,如果我們把這些需要記憶的信息單獨拿出來存儲到一個知識庫中,在需要的時候檢索它們并作為模型額外輸入,就能讓模型參數(shù)沒必要再死記硬背這些信息了,從而實現(xiàn)記憶和泛化更好的平衡,有點【好記性不如爛筆頭】的感覺。下圖是本文提出的基本框架示意圖。
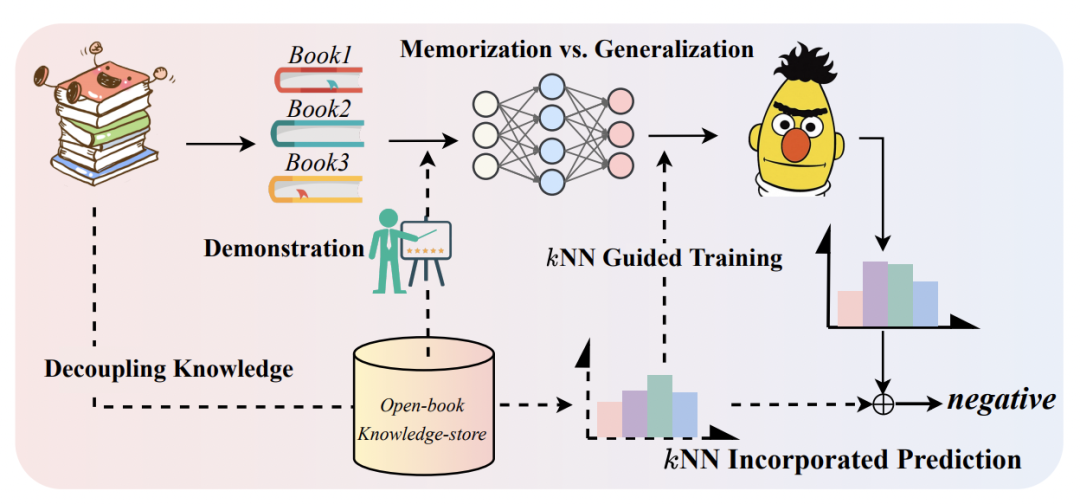
2 從知識庫中檢索信息
實現(xiàn)上面的框架核心是從知識庫中檢索信息,這也就涉及到兩個問題,一個是如何構(gòu)造知識庫,另一個是如何進行信息檢索和利用。
在知識庫的構(gòu)造上,文中構(gòu)造的是一個{K, V}格式的數(shù)據(jù),訓練集中的每條樣本對應一個{K, V}。K代表這個樣本的prompt輸入模型后[MASK]位置的隱向量,V代表這個樣本的label對應的單詞。由于K是模型輸出的向量,因此每訓練幾輪,就會動態(tài)更新知識庫中的Key,避免Key和模型最新參數(shù)隔代太多不匹配。
在信息檢索和利用上,對于當前樣本模型先得到其[MASK]位置的向量,然后用這個向量在知識庫中進行KNN檢索,每個類別的樣本都取出topK個,檢索的距離度量是向量內(nèi)積。對于每個類別檢索出的向量,使用內(nèi)積做softmax后進行加權(quán)融合,得到這個類別最終向量,拼接到當前樣本embedding后面輸入到模型中:
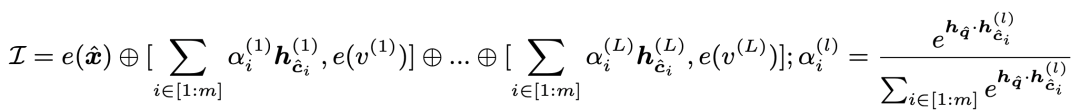
這部分檢索出來的樣本就是將需要記憶的知識直接引入到了當前樣本中,不再需要模型參數(shù)去記憶了。此外,這種將向量引入而不是引入對應的token,可以讓信息的擴展更方便,直接引入樣本的token會拉長輸入樣本長度,導致模型性能下降,且長度也有上限。
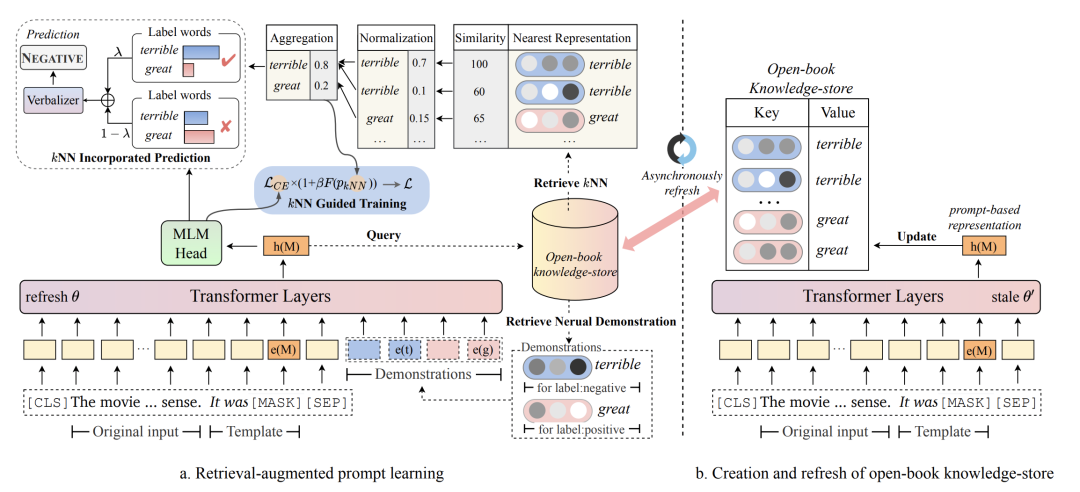
3 使用KNN指導模型訓練和預測
上面收的引入知識庫+KNN的方法,緩解了模型參數(shù)需要強記憶訓練樣本的問題。此外,文中還通過KNN檢索結(jié)果來指導模型的學習過程。KNN檢索的好處是不需要模型訓練,直接根據(jù)預訓練的表示計算距離,利用鄰居樣本的label,就能預測當前樣本的label。這對于模型來說是另一個維度的信息補充,文中通過區(qū)分難樣本指導訓練和在inference階段指導預測兩個方面進一步指導模型的訓練和預測。
KNN的檢索結(jié)果可以用來區(qū)分難樣本和簡單樣本。通過KNN檢索以及檢索鄰居的label,可以得到當前樣本各個類別的預測概率。這個KNN的預測結(jié)果可以作為是否是難樣本的參考,如果模型預測預測結(jié)果和KNN結(jié)果不一致,就是難樣本。對于難樣本,加大其學習權(quán)重,通過將KNN預測概率引入到交叉熵損失中實現(xiàn):
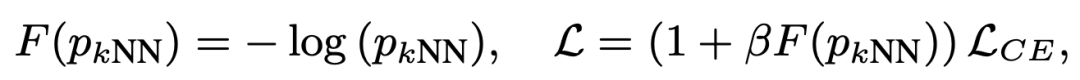
另一方面,在預測階段,也直接將KNN的預測結(jié)果拿出來和模型對于[MASK]的預測結(jié)果做插值,得到最終的預測結(jié)果:
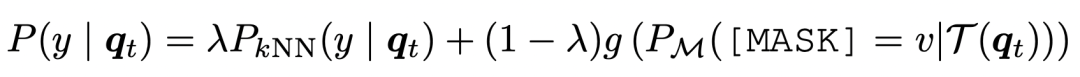
4 實驗結(jié)果
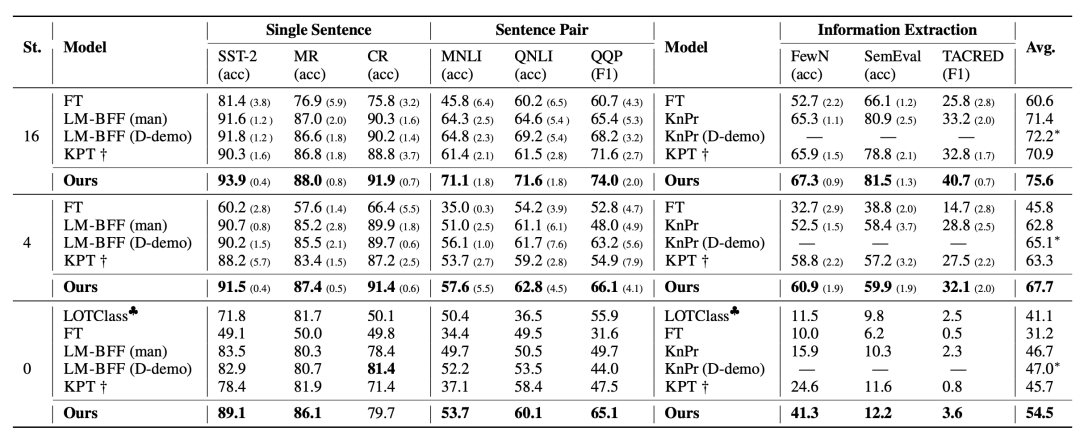
文中在9個NLU數(shù)據(jù)集的few-shot和zero-shot learning上對比了效果,可以看到本文提出的方法對于效果的提升還是非常明顯的。
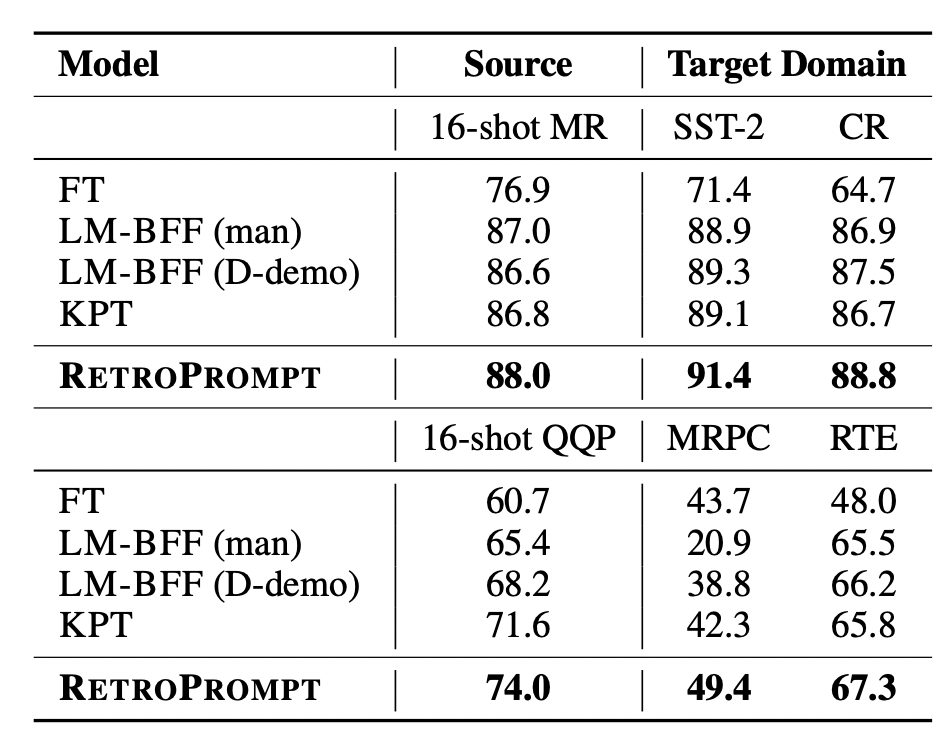
此外,文中也對比了跨領(lǐng)域的效果,在source domain進行prompt learning,對比在target domain上的效果:
5 總結(jié)
檢索在NLP各類任務中的應用越來越多,本文也將檢索用于分離可記憶的信息來提升模型的泛化能力,并取得了顯著效果。檢索通過信息記憶+查詢的方式,引入了豐富的外部信息,能夠讓模型更多的容量服務于學習泛化性,而非簡單的記住訓練數(shù)據(jù)。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7223瀏覽量
90170 -
KNN
+關(guān)注
關(guān)注
0文章
22瀏覽量
10883 -
語言模型
+關(guān)注
關(guān)注
0文章
550瀏覽量
10423
原文標題:不要讓模型死記硬背—用檢索增強Prompt Learning
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
《AI Agent 應用與項目實戰(zhàn)》閱讀心得3——RAG架構(gòu)與部署本地知識庫
學習STM32必備的知識庫
基于知識庫的智能策略翻譯技術(shù)
一種基于解釋的知識庫綜合
領(lǐng)域知識庫的研究與設計
本體知識庫的模塊與保守擴充
虛擬儀器知識庫文件的結(jié)構(gòu)組成和知識庫文件自動生成器的設計與應用

復雜知識庫問答任務的典型挑戰(zhàn)和解決方案
如何基于亞馬遜云科技LLM相關(guān)工具打造知識庫
無監(jiān)督域自適應場景:基于檢索增強的情境學習實現(xiàn)知識遷移






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論