


隨著摩爾定律的放緩,開發其他技術來提高同一技術過程節點上芯片的性能變得越來越重要。我們的方法使用人工智能設計更小、更快、更高效的電路,以在每一代芯片中提供更高的性能。
大量的算術電路陣列為 NVIDIA GPU 提供了動力,使其在人工智能、高性能計算和計算機圖形學方面實現了前所未有的加速。因此,改進這些算術電路的設計對于提高 GPU 的性能和效率至關重要。
如果人工智能能夠學會設計這些電路呢?在 PrefixRL :使用深度強化學習優化并行前綴電路 中,我們證明了人工智能不僅可以從頭開始學習設計這些電路,而且人工智能設計的電路也比最先進的電子設計自動化( EDA )工具設計的電路更小更快。最新 NVIDIA Hopper GPU 結構 擁有近 13000 個人工智能設計電路實例。

圖 1 。由 PrefixRL AI (左)設計的 64b 加法器電路比由最先進的 EDA 工具(右)設計的電路小 25% ,同時速度快,功能等效
在圖 1 中,電路對應于圖 5 中 PrefixRL 曲線中的( 31.4 μ m 2, 0.186ns )點。
電路設計游戲
計算機芯片中的算術電路是使用邏輯門(如 NAND 、 NOR 和 XOR )和導線組成的網絡構建的。理想電路應具有以下特性:
Small: 一個較低的區域,以便在一個芯片上可以容納更多的電路。
Fast: 降低延遲以提高芯片性能。
耗電更少: 芯片功耗更低。
在本文中,我們重點研究了電路面積和延遲。我們發現功耗與感興趣電路的面積密切相關。電路面積和延遲通常是相互競爭的屬性,因此我們希望找到有效權衡這些屬性的設計的帕累托前沿。簡單地說,我們希望在每個延遲時都有最小面積電路。
在 PrefixRL 中,我們關注一類流行的算術電路,稱為(并行)前綴電路。 GPU 中的各種重要電路,如加法器、增量器和編碼器,都是前綴電路,可以在更高級別上定義為前綴圖。
在這項工作中,我們特別提出了一個問題:人工智能代理能否設計出良好的前綴圖?所有前綴圖的狀態空間都很大O(2^n^n),無法使用蠻力方法進行探索。
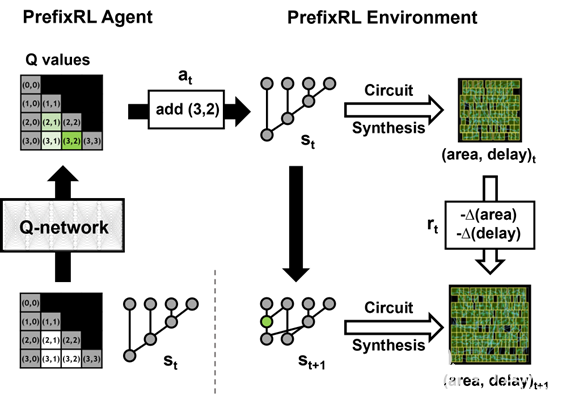
圖 2:PrefixRL 的一次迭代與 4b 電路示例
使用電路生成器將前綴圖轉換為具有導線和邏輯門的電路。然后,使用物理合成優化(如柵極尺寸、復制和緩沖器插入)通過物理合成工具進一步優化這些生成的電路。
由于這些物理合成優化,最終電路特性(延遲、面積和功率)不會直接從原始前綴圖特性(如電平和節點數)轉換。這就是為什么人工智能代理學習設計前綴圖,但優化由前綴圖生成的最終電路的屬性。
我們將算術電路設計作為強化學習( RL )任務,在該任務中,我們訓練代理優化算術電路的面積和延遲特性。對于前綴電路,我們設計了一個環境,在該環境中, RL 代理可以在前綴圖中添加或刪除節點,然后執行以下步驟:
前綴圖合法化,以始終保持正確的前綴和計算。
從合法化的前綴圖生成電路。
使用物理合成工具對電路進行物理合成優化。
測量了電路的面積和延遲特性。
在一集中, RL 代理通過添加或刪除節點逐步建立前綴圖。在每個步驟中,代理都會收到相應電路區域的改進和延遲作為獎勵。
狀態和動作表示與深度強化學習模型
我們使用 Q 學習算法來訓練電路設計代理。我們對前綴圖使用網格表示,其中網格中的每個元素唯一地映射到前綴節點。這種網格表示法用于 Q 網絡的輸入和輸出。輸入網格中的每個元素表示節點是否存在。輸出網格中的每個元素表示用于添加或刪除節點的 Q 值。
我們使用完全卷積神經網絡架構作為智能體的輸入和輸出, Q 學習智能體是網格表示。該代理單獨預測面積和延遲屬性的 Q 值,因為面積和延遲的回報在訓練期間是可以單獨觀察到的。
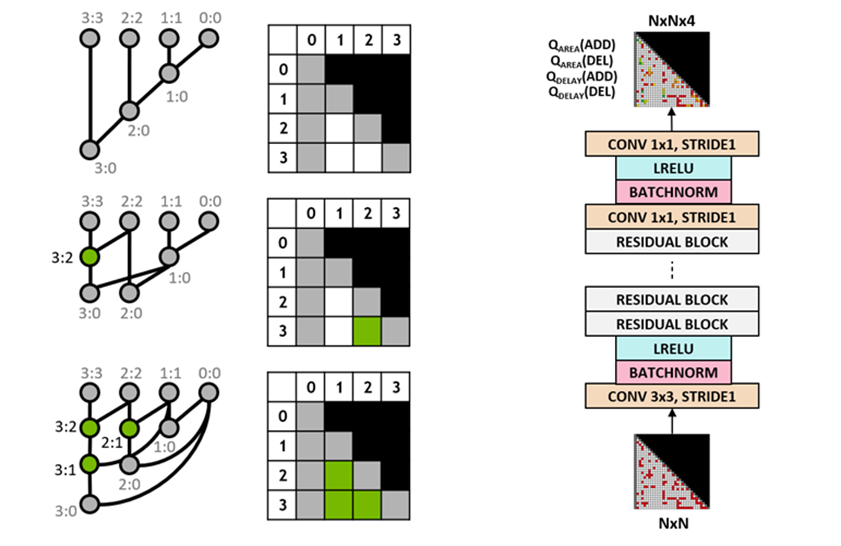
圖 3 。某些 4b 前綴圖(左)和全卷積 Q 學習代理架構(右)的表示
Raptor 分布式訓練
PrefixRL 是一項計算要求很高的任務:物理模擬每個 GPU 需要 256 CPU ,訓練 64b 案例需要 32000 GPU 小時。
我們開發了 Raptor ,這是一個內部分布式強化學習平臺,它利用了 NVIDIA 硬件的特殊優勢來進行這種工業強化學習(圖 4 )。
Raptor 具有一些增強可擴展性和訓練速度的功能,例如作業調度、自定義網絡和 GPU 感知的數據結構。在 PrefixRL 的上下文中, Raptor 使工作分布在 CPU 、 GPU 和 Spot 實例的混合中成為可能。
此強化學習應用程序中的網絡具有多樣性,并從以下方面受益。
Raptor 在 NCCL 之間切換的能力,用于點到點傳輸,以將模型參數直接從學習者 GPU 傳輸到推理 GPU 。
Redis 用于異步和較小的消息,如獎勵或統計信息。
JIT 編譯的 RPC ,用于處理高容量和低延遲請求,例如上載體驗數據。
最后, Raptor 提供了支持 GPU 的數據結構,例如重播緩沖區,該緩沖區具有多線程服務器,用于接收來自多個工作人員的經驗,并并行地批處理數據并將其預取到 GPU 上。
圖 4 顯示,我們的框架支持并行訓練和數據收集,并利用 NCCL 有效地向參與者發送最新參數。
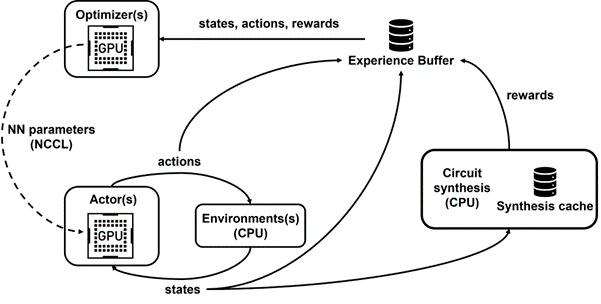
圖 4 。我們使用 Raptor 進行解耦并行訓練和獎勵計算,以克服電路合成延遲
獎勵計算
我們使用[0 , 1]中的折衷權重 w 來組合面積和延遲目標。我們訓練具有不同權重的各種代理,以獲得平衡面積和延遲之間權衡的帕累托前沿設計。
RL 環境中的物理合成優化可以生成各種解決方案,以在面積和延遲之間進行權衡。我們應該使用與訓練特定代理相同的權衡權重來驅動物理合成工具。
在循環中執行物理合成優化以進行獎勵計算有幾個優點。
RL 代理學習直接優化目標技術節點和庫的最終電路屬性。
通過在物理合成過程中包含周圍邏輯, RL 代理可以聯合優化目標算術電路及其周圍邏輯的屬性。
然而,執行物理合成是一個緩慢的過程( 64b 加法器約 35 秒),這會大大減緩 RL 訓練和探索。
我們將獎勵計算與狀態更新解耦,因為代理只需要當前前綴圖狀態來采取行動,而不需要電路合成或之前的獎勵。多虧了 Raptor ,我們可以將冗長的獎勵計算轉移到 CPU 工作人員池中,并行執行物理合成,而演員代理無需等待即可在環境中穿行。
當 CPU 工作者返回獎勵時,可以將轉換插入重播緩沖區。緩存合成獎勵,以避免在狀態重新計數時進行冗余計算。
后果
RL 代理純粹通過從合成電路屬性反饋的學習來學習設計電路。圖 5 顯示了使用 PrefixRL 設計的 64b 加法器電路的最新結果*, Pareto 主導的加法器電路來自最先進的 EDA 工具,在面積和延遲方面。
在相同延遲下,最好的 PrefixRL 加法器的面積比 EDA 工具加法器低 25% 。這些經過物理綜合優化后映射到帕累托最優加法器電路的前綴圖具有不規則結構。
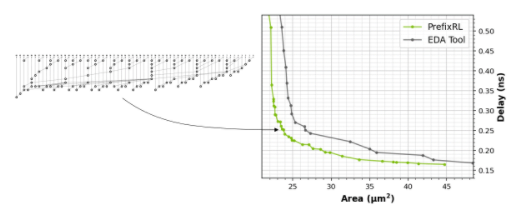
圖 5 。 PrefixRL 設計的算術電路比最先進的 EDA 工具設計的電路更小更快。(左)電路架構;(右)對應的 64b 加法器電路特性圖
結論
據我們所知,這是第一種使用深度強化學習代理設計算術電路的方法。我們希望該方法可以成為將人工智能應用于現實電路設計問題的藍圖:構建動作空間、狀態表示、 RL 代理模型、針對多個競爭目標進行優化,以及克服物理合成等緩慢的獎勵計算過程。
關于作者
Rajarshi Roy 是 NVIDIA 應用深度學習研究小組的高級研究科學家。他研究了使用深度學習、機器學習和強化學習改進芯片設計、架構和系統的新方法。在研究之前, Rajarshi 作為 NVIDIA GPU ASIC 團隊的硬件工程師,對幾種 GPU 架構的設計和驗證做出了貢獻。拉賈希在斯坦福大學獲得電氣工程碩士學位。
Jonathan Raiman 是 NVIDIA 應用深度學習研究小組的高級研究科學家,致力于大規模分布式強化學習和系統人工智能。此前,他是 OpenAI 的研究科學家,在那里他共同創建了 OpenAI Five ,一個超人深度強化學習 Dota 2 機器人。在百度 SVAIL ,他共同創建了幾個神經文本語音轉換系統(深度語音 1 、 2 和 3 ),并致力于語音識別(深度語音 2 )和問答(全球標準化閱讀器)。他也是 DeepType 1 和 DeepType 2 (一種超人實體鏈接系統)的創建者。他正在巴黎薩克萊完成博士學位,此前在麻省理工學院獲得碩士學位。
Saad Godil 是 NVIDIA 應用深度學習研究的主管,他領導的團隊正在探索在我們的芯片設計和硬件項目中使用人工智能的新方法。在此之前,他是 NVIDIA 的 GPU 驗證主管,在半導體行業有十多年的經驗。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5346瀏覽量
106804 -
gpu
+關注
關注
28文章
4976瀏覽量
132022 -
計算機
+關注
關注
19文章
7686瀏覽量
91137 -
eda
+關注
關注
71文章
2950瀏覽量
178848 -
深度強化學習
+關注
關注
0文章
14瀏覽量
2410
發布評論請先 登錄
什么是深度強化學習?深度強化學習算法應用分析

深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
薩頓科普了強化學習、深度強化學習,并談到了這項技術的潛力和發展方向
如何深度強化學習 人工智能和深度學習的進階
深度強化學習是否已經到達盡頭?
模型化深度強化學習應用研究綜述

基于深度強化學習的路口單交叉信號控制
基于深度強化學習仿真集成的壓邊力控制模型
《自動化學報》—多Agent深度強化學習綜述







 工商網監
工商網監

評論