 使用NVIDIA ISAAC Sim和NVIDIA ISAAC Replicator縮小Sim2Real差距
使用NVIDIA ISAAC Sim和NVIDIA ISAAC Replicator縮小Sim2Real差距
合成數據是計算機視覺應用中訓練機器學習模型的重要工具。 NVIDIA 的研究人員介紹了一種 結構化域隨機化 Omniverse Replicator 中的系統,可以幫助您使用合成數據訓練和優化模型。
Omniverse Replicator 是在 NVIDIA Omniverse 平臺上構建的 SDK ,它使您能夠構建自定義的合成數據生成工具和工作流。 NVIDIA ISAAC Sim 開發團隊使用 Omniverse Replicator SDK 構建 NVIDIA ISAAC Replicator ,這是一個特定于機器人的合成數據生成工具包,在 NVIDIA ISAAC Sim 應用程序中公開。
我們探索了在最近的一個項目中使用從合成環境生成的合成數據。 Trimble 計劃部署 Boston Dynamics 的 Spot 在各種室內設置和施工環境中。但 Trimble 必須開發一個經濟高效且可靠的工作流程來訓練基于 ML 的感知模型,以便 Spot 能夠在不同的室內環境中自主運行。
通過在 NVIDIA ISAAC Replicator 內使用結構化域隨機化從合成室內環境生成數據,您可以訓練現成的物體檢測模型,以檢測真實室內環境中的門。
Sim2Real 域間隙
鑒于合成數據集是通過模擬生成的,因此彌合模擬與真實世界之間的差距至關重要。該間隙稱為域間隙,可分為兩部分:
外觀間隙:兩個圖像之間的像素級差異。這些差異可能是由于對象細節、材質的不同,或者在合成數據的情況下,所使用的渲染系統的能力不同。
內容差距:指域之間的差異。這包括場景中對象的數量、類型和位置的多樣性以及類似的上下文信息等因素。
克服這些領域差距的關鍵工具是領域隨機化( DR ),它增加了為合成數據集生成的領域的大小。 DR 有助于確保我們包括最符合現實的范圍,包括長尾異常。通過生成更廣泛的數據,我們可能會發現神經網絡可以學習更好地概括整個問題范圍。
可以使用高保真 3D 資源和基于光線跟蹤或路徑跟蹤的渲染,使用基于物理的材質(如 MDL 定義的材質),進一步縮小外觀差距。驗證的傳感器模型及其參數的域隨機化也有幫助。
創建合成場景
我們通過 NVIDIA Omniverse SketchUp 連接器將室內場景的 BIM 模型從 Trimble SketchUp 導入 NVIDIA ISAAC Sim 。然而,它看起來很粗糙,在 Sim 和現實之間有很大的外觀差距。視頻 1 顯示 Trimble _ DR _ v1.1.usd 。
合成數據生成
此時,開始了合成數據生成( SDG )的迭代過程。對于目標檢測模型,我們在所有實驗中使用 TAO DetectNet V2 和 ResNet-18 主干。
我們將所有模型超參數常數固定為其默認值,包括批量大小、學習速率和數據集擴展配置參數。在合成數據生成中,可以迭代調整數據集生成參數,而不是模型超參數。
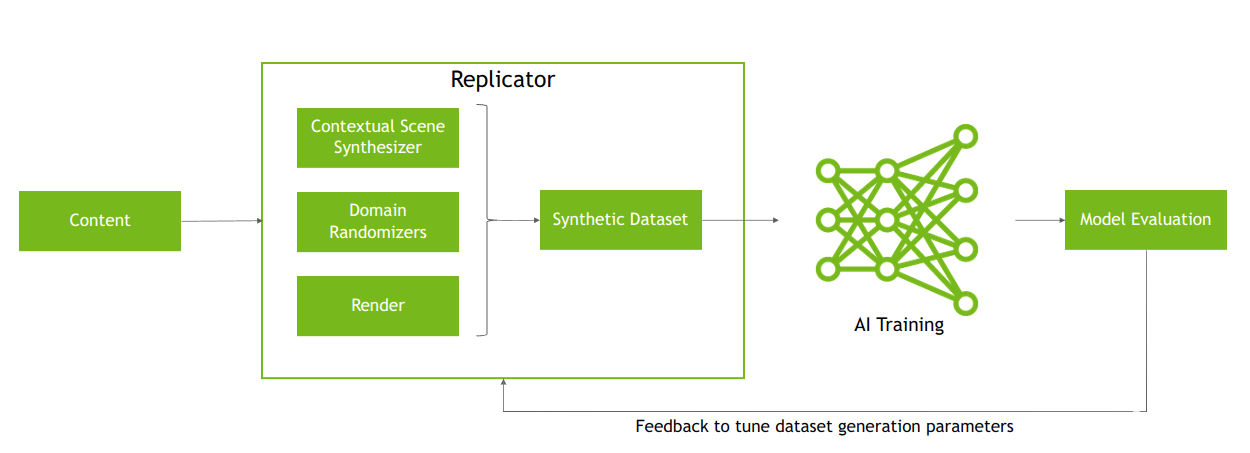
圖 3根據模型評估的反饋調整數據集生成參數的合成數據生成過程
Trimble v1.3 場景包含 500 個光線跟蹤圖像和環境道具,除門旋轉外,沒有 DR 組件。門紋理保持不變。在該場景中進行的訓練在真實測試集(約 1000 張圖像)上產生了 5% 的 AP 。
從模型對真實圖像的預測中可以看出,該模型未能充分檢測到真實的門,因為它過度適合模擬門的紋理。該模型在具有不同紋理門的合成驗證數據集上的較差性能證實了這一點。
另一個觀察結果是,模擬中的照明保持穩定不變,而現實中有各種照明條件。
為了防止過度擬合門的紋理,我們對門紋理應用了隨機化,在 30 種不同的木紋紋理之間隨機化。為了改變照明,我們在天花板上添加了 DR ,以隨機化燈光的運動、強度和顏色。現在,我們正在隨機化門的紋理,重要的是為模型提供一些學習信號,了解除了矩形外,門是由什么組成的。我們為場景中的所有門添加了逼真的金屬門把手、踢腳板和門框。在實際測試集上,對該改進場景中的 500 幅圖像進行訓練,獲得 57% 的 AP 。
這個模型比以前做得更好,但在測試真實圖像中,它仍然對盆栽植物和墻上的 QR 碼做出假陽性預測。它在走廊圖像上也做得很差,在那里我們有多個門。
為了使模型對墻壁上的 QR 碼等噪聲具有魯棒性,我們將 DR 應用于具有不同紋理的墻壁紋理,包括 QR 碼和其他合成紋理。
我們在現場增加了一些盆栽植物。我們已經有了一條走廊,所以為了從中生成合成數據,沿著走廊添加了兩個攝像頭以及天花板上的燈。
我們添加了光溫 DR ,以及強度、運動和顏色,以使模型在不同的光照條件下更好地概括。我們還注意到,在真實圖像中,有各種各樣的地板,如閃亮的花崗巖、地毯和瓷磚。為了模擬這些,我們應用 DR 將地板材料隨機分為不同種類的地毯、大理石、瓷磚和花崗巖材料。
類似地,我們添加了 DR 組件,以在不同顏色和不同種類的材料之間隨機化天花板的紋理。我們還添加了 DR 可見性組件,以便在模擬過程中在走廊中隨機添加幾個推車,希望將模型對真實圖像中推車的誤報降到最低。
通過僅對合成數據進行訓練,從該場景生成的 4000 幅圖像的合成數據集在真實測試集上獲得了約 87% 的 AP ,實現了良好的 Sim2Real 性能。
Omniverse 中的合成數據生成
使用 Omniverse 連接器、 MDL 和 DeepSearch 等易于使用的工具,沒有 3D 設計背景的 ML 工程師和數據科學家可以創建合成場景。
NVIDIA ISAAC Replicator 通過生成具有結構化域隨機化的合成數據,輕松彌補 Sim2Real 差距。通過這種方式, Omniverse 使合成數據生成可以用于引導基于 perception 的 ML 項目。
這里介紹的方法應該是可擴展的,并且應該可以增加感興趣的對象的數量,并在每次需要檢測其他新對象時輕松生成新的合成數據。
關于作者
Geetika Gupta 是 HPC + AI 和 Edge 應用的領先產品。自 NVIDIA 開普勒一代以來,她一直擔任數據中心 GPU 的產品經理,現在專注于 HPC + AI 和流式數據用例的融合。 Geetika 擁有加州大學洛杉磯分校安德森學院的 MBA 學位和 IITBHU 的機械工程學士學位。
Nyla Worker 是 NVIDIA 的解決方案架構師,專注于嵌入式設備的模擬和深入學習。她在機器人和自動車輛的深度學習邊緣應用方面擁有豐富的經驗,并為嵌入式設備開發了加速推理管道。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4978瀏覽量
102988 -
機器學習
+關注
關注
66文章
8406瀏覽量
132565
發布評論請先 登錄
相關推薦
基于Omniverse的NVIDIA Isaac Sim現已發布公測版

Isaac Sim公測版帶來數字孿生級別的機器人仿真
用NVIDIA Omniverse ISAAC Sim加速機器人仿真
NVIDIA Isaac Sim 2022.1版本的亮點及功能
使用Omniverse Replicator構建自定義合成數據生成管道
NVIDIA AI機器人開發— NVIDIA Isaac Sim入門
開發者使用NVIDIA Omniverse和Isaac Sim構建機器人
NVIDIA 公開課 | AI 機器人開發第二講 — Isaac Sim 高階開發
CES | NVIDIA 發布智能機器人高級模擬引擎 Isaac Sim 的重大更新
CES | 用 NVIDIA Isaac Sim 2022.2 模擬未來智能機器人
使用 ROS 2 MoveIt 和 NVIDIA Isaac Sim 創建逼真的機器人模擬

使用 NVIDIA Isaac Sim、ROS 和 Nimbus 開發多機器人環境

從 0 到 1 搭建機器人 | 使用 NVIDIA Isaac Sim Replicator 和 TAO 套件進行數據合成和訓練
NVIDIA Isaac 平臺先進的仿真和感知工具助力 AI 機器人技術加速發展
使用 NVIDIA Isaac 仿真并定位 Husky 機器人





 工商網監
工商網監
評論