

自然語言處理( NLP )可以定義為人工智能( AI )、計算機(jī)科學(xué)和計算語言學(xué)的結(jié)合,以理解人類交流并從非結(jié)構(gòu)化口語或書面材料中提取意義。
在過去幾年中,醫(yī)療保健的非線性規(guī)劃用例有所增加,以通過語言理解和預(yù)測分析加快治療學(xué)的發(fā)展,提高患者護(hù)理質(zhì)量。
醫(yī)療保健行業(yè)產(chǎn)生大量非結(jié)構(gòu)化數(shù)據(jù),但如果不找到以可計算形式構(gòu)造和表示該數(shù)據(jù)的方法,就很難獲得見解。開發(fā)人員需要將非結(jié)構(gòu)化數(shù)據(jù)轉(zhuǎn)換為結(jié)構(gòu)化數(shù)據(jù)的工具,以幫助醫(yī)療保健組織利用相關(guān)見解,改善醫(yī)療保健服務(wù)和患者護(hù)理。
Transformer – 基于文本的自然語言處理已成為基于文本的醫(yī)療保健工作流性能的范式轉(zhuǎn)變。由于其多功能性, NLP 幾乎可以構(gòu)建任何專有或公共數(shù)據(jù),以 Spark 洞察醫(yī)療保健,從而產(chǎn)生各種下游應(yīng)用,直接影響患者護(hù)理或擴(kuò)大和加速藥物發(fā)現(xiàn)。
藥物發(fā)現(xiàn)的自然語言處理
非線性規(guī)劃在加速小分子藥物發(fā)現(xiàn)方面發(fā)揮著關(guān)鍵作用。關(guān)于藥物可制造性或禁忌癥的先驗知識可以從學(xué)術(shù)出版物和專有數(shù)據(jù)集中提取。 NLP 還可以幫助進(jìn)行臨床試驗分析,并加快將藥物推向市場的過程。
Transformer 體系結(jié)構(gòu)在自然語言處理中很流行,但這些工具也可以用于理解化學(xué)和生物語言。例如,基于文本的化學(xué)結(jié)構(gòu)表示,例如 SMILES (簡化輸入分子線輸入系統(tǒng)),可以通過基于轉(zhuǎn)換器的架構(gòu)來理解,從而實現(xiàn)藥物性質(zhì)評估和生成化學(xué)的難以置信的能力。
MegaMolBART ,一個由阿斯利康和 NVIDIA 開發(fā)的大型 transformer 模型,用于廣泛的任務(wù),包括反應(yīng)預(yù)測、分子優(yōu)化和從頭生成分子。
基于 Transformer 的非線性規(guī)劃模型有助于理解和預(yù)測類生物分子蛋白質(zhì)的結(jié)構(gòu)和功能。與自然語言一樣,基于 transformer 的蛋白質(zhì)序列表示提供了強(qiáng)大的嵌入,用于下游人工智能任務(wù),如預(yù)測蛋白質(zhì)的最終折疊狀態(tài),了解蛋白質(zhì) – 蛋白質(zhì)或蛋白質(zhì) – 小分子相互作用的強(qiáng)度,或設(shè)計提供生物靶點的蛋白質(zhì)結(jié)構(gòu)。
臨床試驗見解的 NLP
一旦藥物開發(fā)出來,患者數(shù)據(jù)在將其推向市場的過程中起著重要作用。通過護(hù)理過程收集的大部分患者數(shù)據(jù)都包含在自由文本中,例如患者就診的臨床記錄或程序結(jié)果。
雖然這些數(shù)據(jù)很容易被人解讀,但結(jié)合跨臨床自由文本文檔的見解需要使跨不同文檔的信息具有互操作性,以便以有用的方式表示患者的健康。
現(xiàn)代非線性規(guī)劃算法加快了我們獲得這些見解的能力,有助于比較具有類似癥狀的患者,提出治療建議,發(fā)現(xiàn)診斷未遂事件,并提供臨床護(hù)理導(dǎo)航和次優(yōu)行動預(yù)測。
NLP 提高臨床體驗
許多患者與醫(yī)院系統(tǒng)的互動是遠(yuǎn)程的,部分原因是源于 2019 冠狀病毒疾病的遠(yuǎn)程醫(yī)療服務(wù)的使用越來越多。這些遠(yuǎn)程醫(yī)療就診可以在 NLP 的幫助下轉(zhuǎn)換為結(jié)構(gòu)化信息。
對于內(nèi)科醫(yī)生和外科醫(yī)生來說,語音到文本的功能可以將與患者和臨床團(tuán)隊的口頭討論轉(zhuǎn)化為文本,然后可以存儲在電子健康記錄( EHR )中。應(yīng)用包括總結(jié)患者就診、捕捉未遂事件和預(yù)測最佳治療方案。
消除每個患者就診的臨床文檔負(fù)擔(dān)可以讓提供者花費更多的時間和精力為每個患者提供最佳護(hù)理,同時減少醫(yī)生的倦怠感。 NLP 還可以幫助醫(yī)院預(yù)測患者結(jié)果,例如 重新接納 或敗血癥。
關(guān)于作者
Anthony Costa 在 NVIDIA 領(lǐng)導(dǎo)醫(yī)療保健和生命科學(xué)分析的開發(fā)人員關(guān)系,專注于自然語言處理、對話式 AI 和藥物發(fā)現(xiàn)應(yīng)用程序。 Anthony 的背景包括計算化學(xué)和物理學(xué),在過去十年中,他領(lǐng)導(dǎo)了主要學(xué)術(shù)衛(wèi)生系統(tǒng)中的許多醫(yī)療保健和生命科學(xué)轉(zhuǎn)化人工智能計劃。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5274瀏覽量
105982 -
人工智能
+關(guān)注
關(guān)注
1805文章
48862瀏覽量
247629 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22540
發(fā)布評論請先 登錄
人工智能驅(qū)動醫(yī)療保健行業(yè)變革
醫(yī)療保健領(lǐng)域數(shù)字化轉(zhuǎn)型的核心驅(qū)動力與主要應(yīng)用場景
醫(yī)療機(jī)器人在醫(yī)療保健領(lǐng)域的應(yīng)用
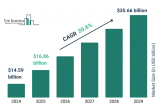
TE Connectivity產(chǎn)品塑造醫(yī)療保健技術(shù)的未來
邊緣AI將如何重塑醫(yī)療保健領(lǐng)域的未來?

基于HPM_SDK_ENV開發(fā)應(yīng)用程序的升級處理

利用低功耗微控制器產(chǎn)品組合簡化醫(yī)療保健和工業(yè)物聯(lián)網(wǎng)設(shè)計
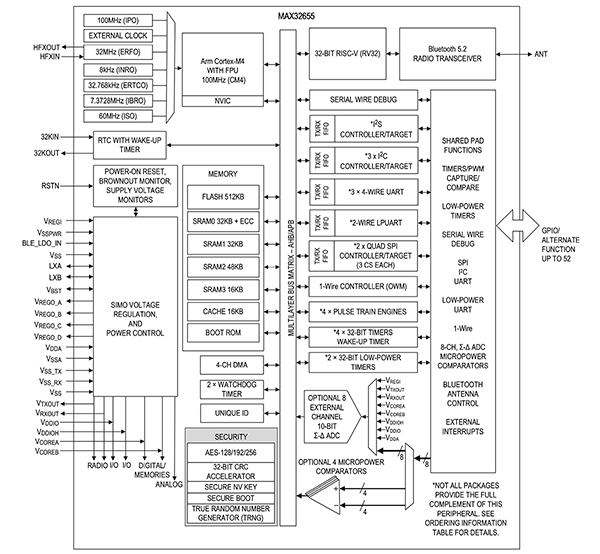
安富利:以IoMT創(chuàng)新引領(lǐng)醫(yī)療保健未來
Murata醫(yī)療保健設(shè)備解決方案
AWTK-WEB 快速入門(1) - C 語言應(yīng)用程序

智能醫(yī)療保健設(shè)備的設(shè)計實例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論