


每個(gè) AI 應(yīng)用程序都需要強(qiáng)大的推理引擎。無(wú)論您是部署圖像識(shí)別服務(wù)、智能虛擬助理還是欺詐檢測(cè)應(yīng)用程序,可靠的推理服務(wù)器都能提供快速、準(zhǔn)確和可擴(kuò)展的預(yù)測(cè),具有低延遲(對(duì)單個(gè)查詢的響應(yīng)時(shí)間較短)和高吞吐量(在給定時(shí)間間隔內(nèi)處理大量查詢)。然而,檢查所有這些方框可能很難實(shí)現(xiàn),而且成本高昂。
團(tuán)隊(duì)需要考慮部署可以利用以下功能的應(yīng)用程序:
具有獨(dú)立執(zhí)行后端的多種框架( ONNX 運(yùn)行時(shí)、 TensorFlow 、 PyTorch )
不同的推理類型(實(shí)時(shí)、批量、流式)
用于混合基礎(chǔ)設(shè)施( CPU 、 GPU )的不同推理服務(wù)解決方案
可以顯著影響推理性能的不同模型配置設(shè)置(動(dòng)態(tài)批處理、模型并發(fā))
這些要求使人工智能推理成為一項(xiàng)極具挑戰(zhàn)性的任務(wù),可以通過(guò) NVIDIA Triton 推理服務(wù)器 。
這篇文章提供了一個(gè)逐步提高 AI 推理性能的教程 Azure 機(jī)器學(xué)習(xí) 使用 NVIDIA Triton 模型分析儀和 ONNX 運(yùn)行時(shí)橄欖 ,如圖 1 所示。
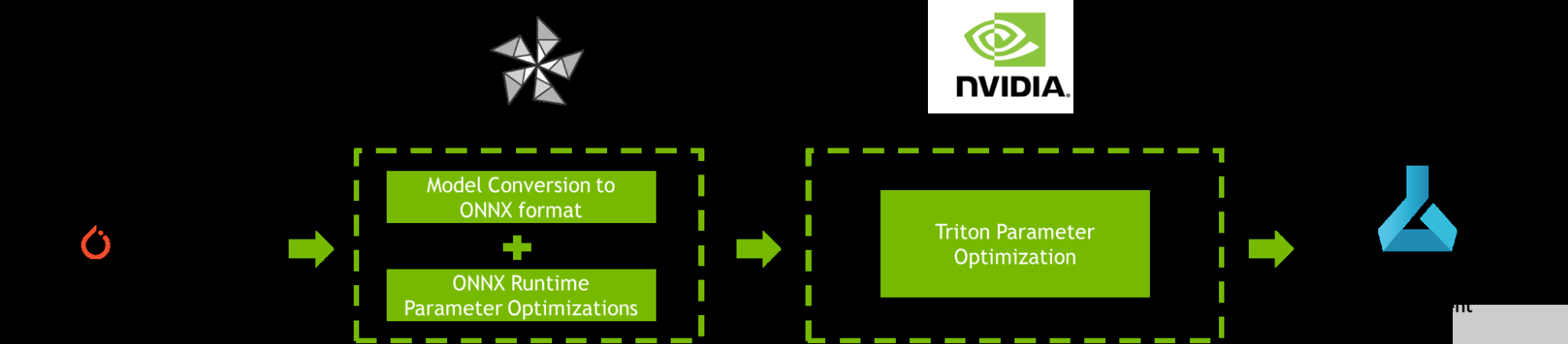
圖 1.使用 ONNX 運(yùn)行時(shí)、 OLive 、 Triton 模型分析器和 Azure 機(jī)器學(xué)習(xí)優(yōu)化 PyTorch 模型的工作流
工作流優(yōu)化的機(jī)器學(xué)習(xí)模型
為了提高 AI 推理性能, ONNX Runtime OLive 和 Triton 模型分析器在模型部署之前自動(dòng)執(zhí)行參數(shù)優(yōu)化步驟。這些參數(shù)定義了底層推理引擎將如何執(zhí)行。您可以使用這些工具來(lái)優(yōu)化 ONNX 運(yùn)行時(shí)參數(shù) (執(zhí)行提供程序、會(huì)話選項(xiàng)和精度參數(shù)),以及 Triton 參數(shù) (動(dòng)態(tài)批處理和模型并發(fā)參數(shù))。
階段 1 : ONNX 運(yùn)行時(shí)橄欖優(yōu)化
如果 Azure 機(jī)器學(xué)習(xí)是您部署 AI 應(yīng)用程序的地方,那么您可能熟悉 ONNX 運(yùn)行時(shí)。 ONNX Runtime 是微軟的高性能推理引擎,用于跨平臺(tái)運(yùn)行 AI 模型。它可以跨多種配置設(shè)置部署模型,目前 Triton ?聲波風(fēng)廓線儀支持。微調(diào)這些配置設(shè)置需要專門的時(shí)間和領(lǐng)域?qū)I(yè)知識(shí)。
OLive ( ONNX Runtime Go Live )是一個(gè) Python 包,通過(guò)使用 ONNX 運(yùn)行時(shí)自動(dòng)化加速模型的工作來(lái)加速此過(guò)程。它提供了兩種功能:將模型轉(zhuǎn)換為 ONNX 格式和自動(dòng)調(diào)整 ONNX 運(yùn)行時(shí)參數(shù),以最大化推理性能。運(yùn)行 OLive 將隔離并推薦 ONNX 運(yùn)行時(shí)配置設(shè)置,以獲得最佳核心 AI 推理結(jié)果。
您可以使用以下 ONNX 運(yùn)行時(shí)參數(shù)使用 OLive 優(yōu)化 ONNX Runtime BERT 小隊(duì)模型:
執(zhí)行提供程序:ONNX Runtime 通過(guò)其可擴(kuò)展執(zhí)行提供程序( EP )框架與不同的硬件加速庫(kù)協(xié)作,以在硬件平臺(tái)上優(yōu)化運(yùn)行 ONNX 模型,該框架可以利用平臺(tái)的計(jì)算能力優(yōu)化執(zhí)行。 OLive 探索了以下執(zhí)行提供程序的優(yōu)化:針對(duì) CPU 的 MLA (默認(rèn) CPU EP )、英特爾 DNNL 和 OpenVino 、針對(duì) GPU 的 NVIDIA CUDA 和 TensorRT 。
會(huì)話選項(xiàng):OLive 瀏覽 ONNX 運(yùn)行時(shí)會(huì)話選項(xiàng),以找到線程控制的最佳配置,包括 inter_op_num_threads、intra_op_num_threads、execution_mode和graph_optimization_level。
精度:OLive 以不同的精度級(jí)別評(píng)估性能,包括float32和float16,并返回最佳精度配置。
在運(yùn)行了優(yōu)化之后,您仍然可能會(huì)在應(yīng)用程序級(jí)別上留下一些性能。使用 Triton 模型分析器可以進(jìn)一步提高端到端吞吐量和延遲,該分析器能夠支持優(yōu)化的 ONNX 運(yùn)行時(shí)模型。
第 2 階段: Triton 模型分析器優(yōu)化
NVIDIA Triton 推理服務(wù)器 是一款開(kāi)源推理服務(wù)軟件,有助于標(biāo)準(zhǔn)化模型部署和執(zhí)行,并在生產(chǎn)中提供快速、可擴(kuò)展的人工智能推理。圖 2 顯示了 Triton 推理服務(wù)器在與客戶端應(yīng)用程序和多個(gè) AI 模型集成時(shí)如何管理客戶端請(qǐng)求。
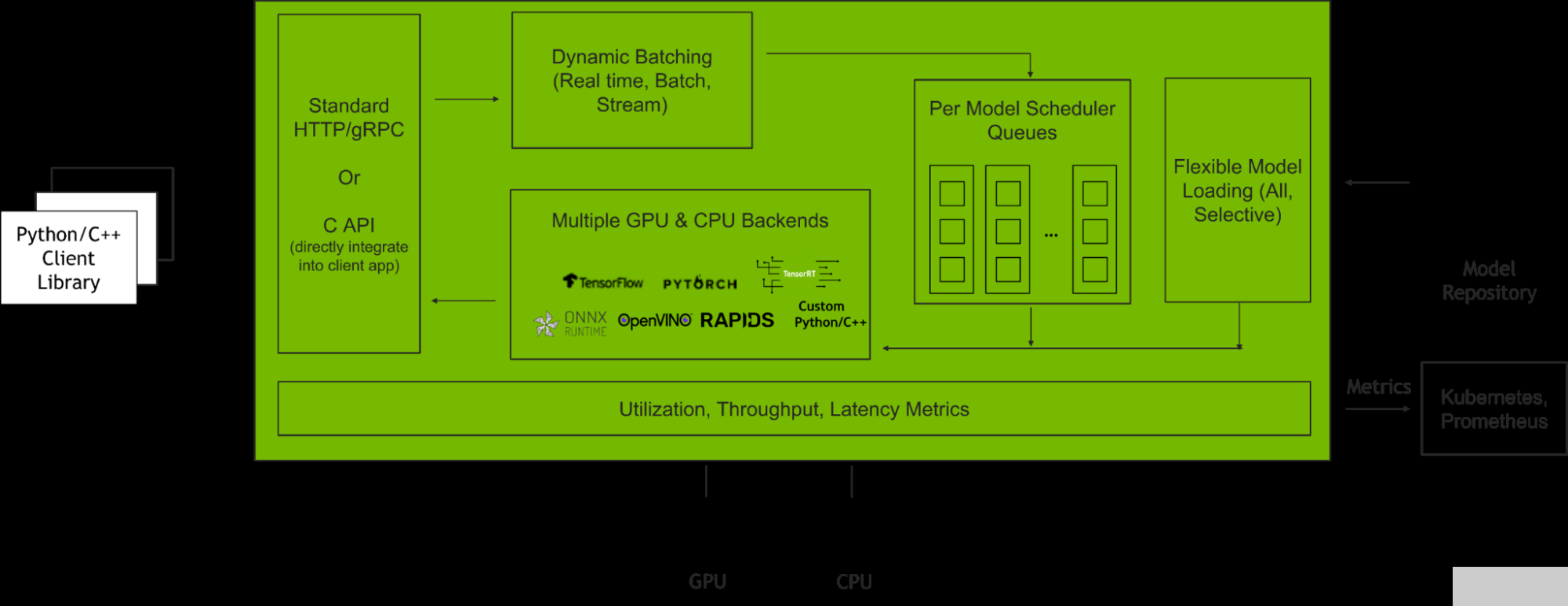
圖 2. Triton 推理服務(wù)器如何管理客戶端請(qǐng)求
這篇文章將著重于使用 Triton 模型分析器優(yōu)化兩個(gè)主要的 Parabricks 特性:
動(dòng)態(tài)配料:Triton 允許服務(wù)器組合推理請(qǐng)求,以便動(dòng)態(tài)創(chuàng)建批處理。這導(dǎo)致在固定延遲預(yù)算內(nèi)增加吞吐量。
并發(fā)模型:Triton 允許同一模型的多個(gè)模型或?qū)嵗谕幌到y(tǒng)上并行執(zhí)行。這導(dǎo)致吞吐量增加。
當(dāng)以最佳級(jí)別部署時(shí),這些功能非常強(qiáng)大。當(dāng)以次優(yōu)配置部署時(shí),性能會(huì)受到影響,使終端應(yīng)用程序容易受到當(dāng)前苛刻的服務(wù)質(zhì)量標(biāo)準(zhǔn)(延遲、吞吐量和內(nèi)存要求)的影響。
因此,基于預(yù)期用戶流量?jī)?yōu)化批量大小和模型并發(fā)級(jí)別對(duì)于充分挖掘 Triton 的潛力至關(guān)重要。這些優(yōu)化 模型配置設(shè)置 將在嚴(yán)格的延遲約束下提高吞吐量,在部署應(yīng)用程序時(shí)提高 GPU 利用率。該過(guò)程可以使用 Triton 模型分析儀實(shí)現(xiàn)自動(dòng)化。
給定一組約束,包括延遲、吞吐量目標(biāo)或內(nèi)存占用, Triton 模型分析器根據(jù)批量大小、模型并發(fā)性或其他[ZGK22]模型配置設(shè)置的不同級(jí)別,搜索并選擇最大化推理性能的最佳模型配置。部署和優(yōu)化這些功能后,您將看到令人難以置信的結(jié)果。
教程:開(kāi)始優(yōu)化推理性能
在 Azure 機(jī)器學(xué)習(xí)上使用 ONNX Runtime OLive 和 Triton 模型分析器部署優(yōu)化的機(jī)器學(xué)習(xí)模型需要四個(gè)步驟:
發(fā)射 Azure 虛擬機(jī) 使用 NVIDIA GPU 優(yōu)化的虛擬機(jī)映像( VMI )
在模型上執(zhí)行 ONNX 、 Runtime 、 OLive 和 Triton 模型分析器參數(shù)優(yōu)化
分析和自定義結(jié)果
將優(yōu)化的 Triton ONNX 運(yùn)行時(shí)模型部署到 Azure 機(jī)器學(xué)習(xí)端點(diǎn)上
要完成本教程,請(qǐng)確保您有一個(gè) Azure 帳戶,可以訪問(wèn) NVIDIA GPU 支持的虛擬機(jī)。例如,使用 Azure ND A100 v4 系列 虛擬機(jī) NVIDIA A100 GPU , NCasT4 v3 系列 對(duì)于 NVIDIA T4 GPU 或 NCv3 系列 適用于 NVIDIA V100 GPU 。雖然建議使用 ND A100 v4 系列以獲得最大規(guī)模的性能,但本教程使用標(biāo)準(zhǔn)的 NC6s _ v3 虛擬機(jī),使用單個(gè) NVIDIA V100 GPU 。
步驟 1 :使用 NVIDIA 的 GPU 優(yōu)化 VMI 啟動(dòng) Azure 虛擬機(jī)
本教程使用 NVIDIA GPU 優(yōu)化 VMI 在 Azure 市場(chǎng)上可用。它預(yù)先配置了 NVIDIA GPU 驅(qū)動(dòng)程序、 CUDA 、 Docker 工具包、運(yùn)行時(shí)和其他依賴項(xiàng)。此外,它還為開(kāi)發(fā)人員構(gòu)建 AI 應(yīng)用程序提供了一個(gè)標(biāo)準(zhǔn)化堆棧。
為了最大限度地提高性能, NVIDIA 每季度對(duì)該 VMI 進(jìn)行驗(yàn)證和更新,并提供最新的驅(qū)動(dòng)程序、安全補(bǔ)丁和對(duì)最新 GPU 的支持。
有關(guān)如何在 Azure VM 上啟動(dòng)和連接 NVIDIA GPU 優(yōu)化 VMI 的詳細(xì)信息,請(qǐng)參閱 Azure 虛擬機(jī)上的 NGC 文檔 。
第 2 步:執(zhí)行 ONNX Runtime OLive 和 Triton 模型分析器優(yōu)化
使用 SSH 連接到 Azure 虛擬機(jī)并加載 NVIDIA GPU 優(yōu)化的 VMI 后,即可開(kāi)始執(zhí)行 ONNX Runtime OLive 和 Triton 模型分析器優(yōu)化。
首先,克隆 GitHub 存儲(chǔ)庫(kù)并通過(guò)運(yùn)行以下命令導(dǎo)航到內(nèi)容根目錄:git clone https://github.com/microsoft/OLive.git
接下來(lái),加載Triton 服務(wù)器容器請(qǐng)注意,本教程使用版本號(hào) 22.06 。
docker run --gpus=1 --rm -it -v “$(pwd)”:/models nvcr.io/nvidia/tritonserver:22.06-py3 /bin/bash
加載后,導(dǎo)航到安裝 GitHub 材料的/models文件夾:
cd /models 下載 OLive 和 ONNX 運(yùn)行時(shí)包,以及要優(yōu)化的模型。然后,通過(guò)設(shè)置以下環(huán)境變量,指定要優(yōu)化的模型的位置:
導(dǎo)出模型_位置= https://olivewheels.blob.core.windows.net/models/bert-base-cased-squad.pth
導(dǎo)出模型_文件名= bert-base-cased-squad.pth
您可以使用您選擇的模型調(diào)整上面提供的位置和文件名。為了獲得最佳性能,請(qǐng)直接從 NGC 目錄 這些模型被訓(xùn)練到高精度,并且具有高級(jí)證書和代碼樣本。
接下來(lái),運(yùn)行以下腳本:
bash download.sh $model_location $export model_filename腳本將下載三個(gè)文件到您的機(jī)器上:
-
橄欖包裝:
onnxruntime_olive-0.3.0-py3-none-any.whl -
ONNX 運(yùn)行時(shí)包:
onnxruntime_gpu_tensorrt-1.9.0-cp38-cp38-linux_x86_64.whl -
PyTorch Model:
bert-base-cased-squad.pth
在運(yùn)行圖 1 中的管道之前,首先通過(guò)設(shè)置環(huán)境變量指定其輸入?yún)?shù):
-
出口
model_name=bertsquad -
出口
model_type=pytorch -
出口
in_names=input_names,input_mask,segment_ids -
出口
in_shapes=[[-1,256],[-1,256],[-1,256]] -
出口
in_types=int64,int64,int64 -
出口
out_names=start,end
參數(shù)in_names、in_shapes和in_types指模型預(yù)期輸入的名稱、形狀和類型。在這種情況下,輸入是長(zhǎng)度為 256 的序列,但它們被指定為[-1256],以允許對(duì)輸入進(jìn)行批處理。您可以更改與模型及其預(yù)期輸入和輸出相對(duì)應(yīng)的參數(shù)值。
現(xiàn)在,您可以通過(guò)執(zhí)行以下命令來(lái)運(yùn)行管道:
bash optimize.sh $model_filename $model_name $model_type $in_names $in_shapes $in_types $out_names該命令首先安裝所有必要的庫(kù)和依賴項(xiàng),并調(diào)用 OLive 將原始模型轉(zhuǎn)換為 ONNX 格式。
接下來(lái),調(diào)用 Triton 模型分析器,自動(dòng)生成帶有模型元數(shù)據(jù)的模型配置文件。然后將配置文件傳遞回 OLive ,以通過(guò)前面討論的 ONNX 運(yùn)行時(shí)參數(shù)(執(zhí)行提供程序、會(huì)話選項(xiàng)和精度)進(jìn)行優(yōu)化。
為了進(jìn)一步提高吞吐量和延遲,然后將 ONNX 運(yùn)行時(shí)優(yōu)化的模型配置文件傳遞到 Triton 模型庫(kù)中,供 Parabricks 模型分析器工具使用。 Triton 模型分析器然后運(yùn)行profile命令,它設(shè)置優(yōu)化搜索空間,并使用.yaml配置文件指定 Triton 模型存儲(chǔ)庫(kù)的位置(見(jiàn)圖 3 )。
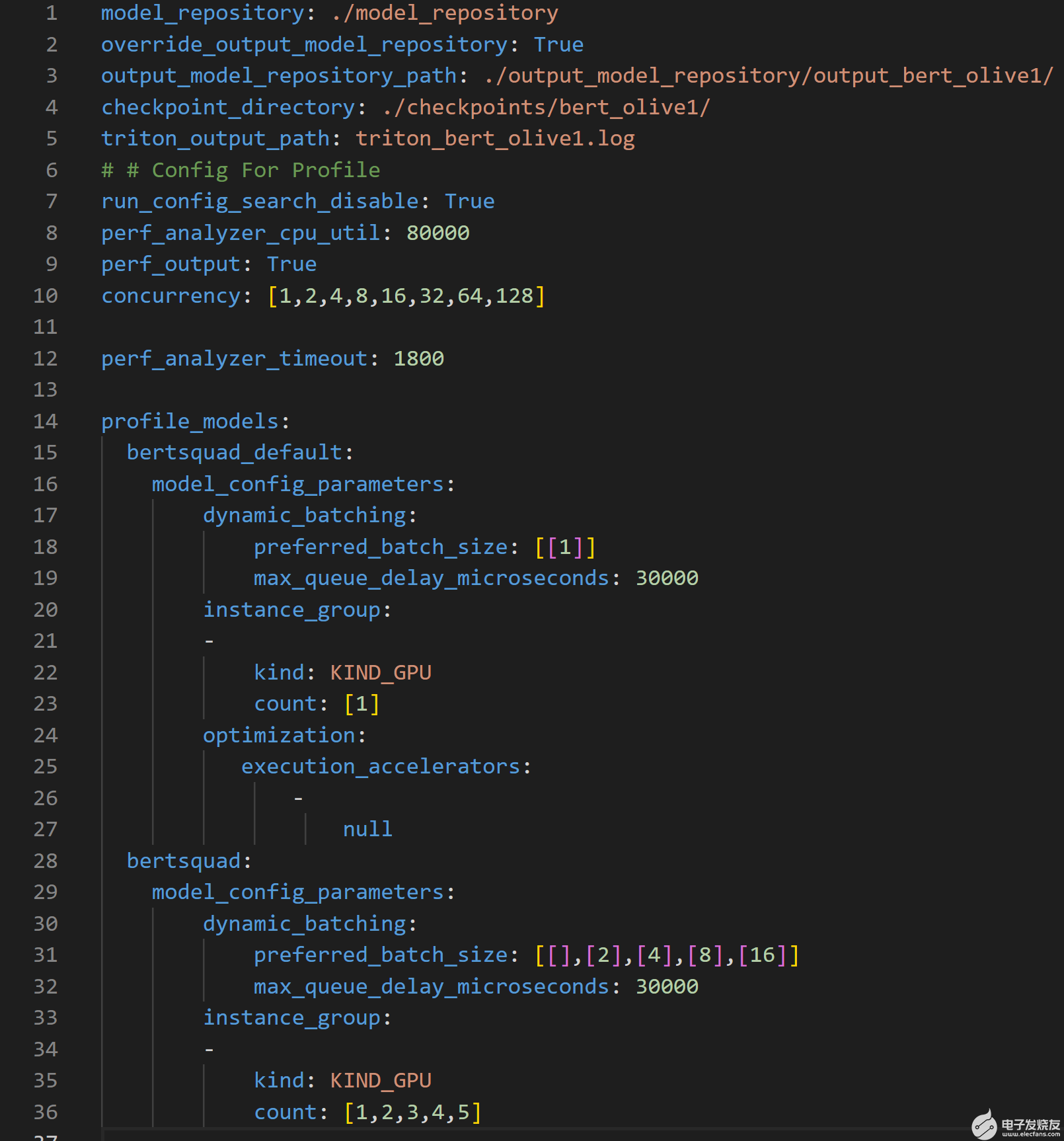
圖 3.概要配置文件概述了 Triton 模型分析器搜索空間,以優(yōu)化推理性能
上述配置文件可用于以多種方式自定義 Triton 模型分析器的搜索空間。該文件需要模型存儲(chǔ)庫(kù)的位置、要優(yōu)化的參數(shù)及其范圍,以創(chuàng)建 Triton 模型分析器用于查找最佳配置設(shè)置的搜索空間。
第 1-5 行指定了重要的路徑,例如優(yōu)化模型所在的輸出模型存儲(chǔ)庫(kù)的位置。
第 10 行指定了參數(shù) concurrency ,該參數(shù)指定了要由性能分析器,它模擬用戶流量。
第 15 行指定了bert_default 模型,其對(duì)應(yīng)于從 PyTorch 到 ONNX 轉(zhuǎn)換獲得的默認(rèn)模型。該模型是基線模型,因此使用了動(dòng)態(tài)批處理(第 17 行)和模型并發(fā)(第 20 行)的非優(yōu)化值
第 19 行和第 32 行顯示了在優(yōu)化過(guò)程中必須滿足的 30ms 延遲約束。
第 28 行指定了bertsquad 模型,其對(duì)應(yīng)于橄欖優(yōu)化模型。此模型與bert_default模型不同,因?yàn)榇颂幍膭?dòng)態(tài)批處理參數(shù)搜索空間設(shè)置為 1 、 2 、 4 、 8 和 16 ,模型并發(fā)參數(shù)搜索空間設(shè)為 1 、 3 、 4 和 5 。
profile命令記錄每個(gè)并發(fā)推理請(qǐng)求級(jí)別的結(jié)果,并且對(duì)于每個(gè)并行推理請(qǐng)求級(jí)別,記錄 25 個(gè)不同參數(shù)的結(jié)果,因?yàn)閯?dòng)態(tài)批處理和模型并發(fā)參數(shù)的搜索空間分別具有五個(gè)唯一值,總計(jì)等于 25 個(gè)不同的參數(shù)。請(qǐng)注意,運(yùn)行此操作所需的時(shí)間將隨著圖 3 中概要文件配置文件中搜索空間中提供的配置數(shù)量的增加而增加。
腳本然后運(yùn)行Triton 模型分析儀分析命令使用圖 4 所示的附加配置文件來(lái)處理結(jié)果。該文件指定了輸出模型存儲(chǔ)庫(kù)的位置,其中通過(guò)profile命令生成結(jié)果,以及將記錄性能結(jié)果的 CSV 文件的名稱。
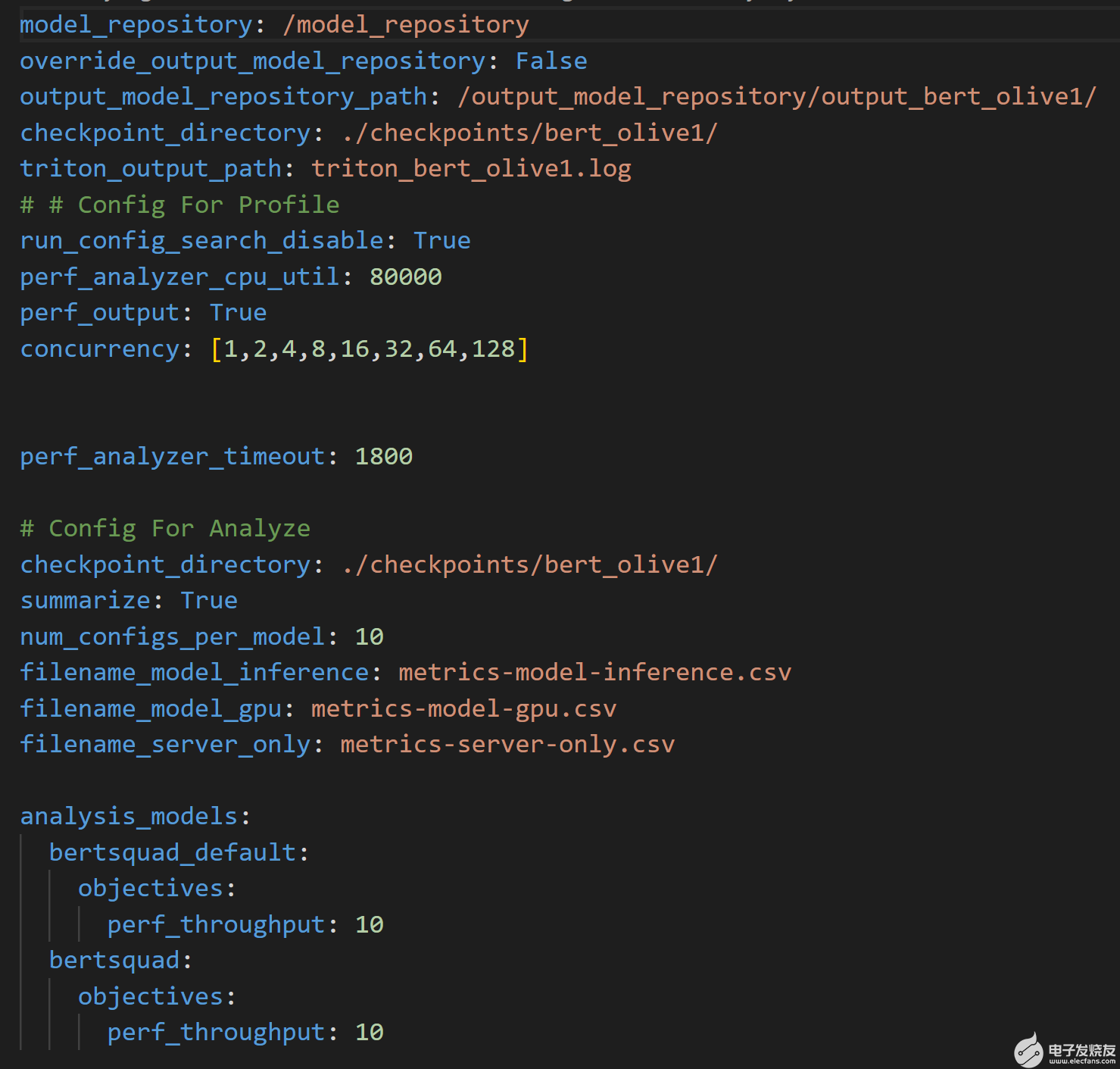
圖 4.分析用于運(yùn)行analyze命令的配置文件,并處理profile命令的結(jié)果
雖然profile和analyze命令可能需要幾個(gè)小時(shí)才能運(yùn)行,但優(yōu)化的模型配置設(shè)置將確保部署的模型具有強(qiáng)大的長(zhǎng)期推理性能。對(duì)于較短的運(yùn)行時(shí)間,調(diào)整模型配置文件(圖 3 ),在希望優(yōu)化的參數(shù)上使用較小的搜索空間。
演示運(yùn)行完成后,將生成兩個(gè)文件: optim _ Results 。 png ,如圖 5 所示,以及 Optimal _ ConfigFile _ Location 。 txt ,表示要部署在 Azure 機(jī)器學(xué)習(xí)上的最佳配置文件的位置。建立非優(yōu)化基線(藍(lán)線)。通過(guò) OLive 優(yōu)化實(shí)現(xiàn)的性能提升如圖所示(淺綠線),以及 OLive + Triton 模型分析器優(yōu)化(深綠線)。
步驟 3 :分析性能結(jié)果
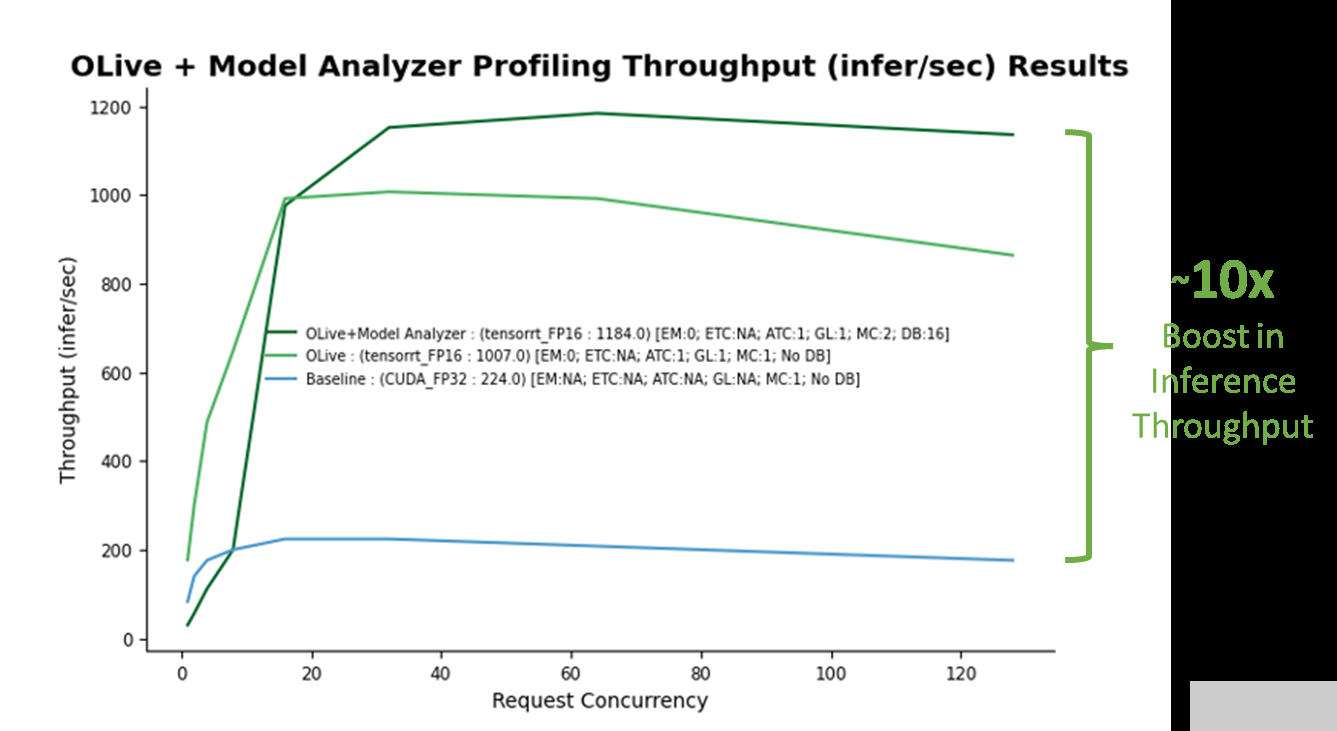
圖 5.在使用單個(gè) V100 NVIDIA GPU 的 Azure 虛擬機(jī)( Standard _ NC6s _ v3 )上應(yīng)用 OLive plus Triton Model Analyzer 優(yōu)化配置設(shè)置時(shí),推理吞吐量提高了 10 倍。(注意:這不是官方基準(zhǔn)。)
基線對(duì)應(yīng)于具有非優(yōu)化 ONNX 運(yùn)行時(shí)參數(shù)( CUDA 后端,具有全精度)和非優(yōu)化 Triton 參數(shù)(無(wú)動(dòng)態(tài)批處理和模型并發(fā))的模型。隨著基線的建立,很明顯,從 OLive 和 Triton 模型分析器在各種推理請(qǐng)求并發(fā)級(jí)別( x 軸)上的優(yōu)化中獲得的推理吞吐量性能( y 軸)有了很大提升,仿真結(jié)果如下:Triton 性能分析儀,一種通過(guò)生成推理請(qǐng)求來(lái)模擬用戶流量的工具。
OLive 優(yōu)化通過(guò)以混合精度將執(zhí)行提供程序調(diào)整為 TensorRT 以及其他 ONNX 運(yùn)行時(shí)參數(shù),提高了模型性能(淺綠線)。然而,這顯示了沒(méi)有 Triton 動(dòng)態(tài)批處理或模型并發(fā)的性能。因此,可以使用 Triton 模型分析器進(jìn)一步優(yōu)化該模型。
Triton 模型分析器在優(yōu)化模型并發(fā)性和動(dòng)態(tài)批處理后,進(jìn)一步將推理性能提高了 20% (深綠線)。 Triton 模型分析器選擇的最終最佳值是兩個(gè)模型并發(fā)性(兩個(gè) BERT 模型副本將保存在 GPU 上)和 16 個(gè)最大動(dòng)態(tài)批處理級(jí)別(一次最多 16 個(gè)推理請(qǐng)求將一起批處理)。
總體而言,使用優(yōu)化參數(shù)的推理性能增益超過(guò) 10 倍。
此外,如果您希望應(yīng)用程序具有特定級(jí)別的推理請(qǐng)求,則可以通過(guò)配置Triton perf_analyzer.您還可以調(diào)整模型配置文件,以包括:要優(yōu)化的其他參數(shù)例如延遲分批。
您現(xiàn)在可以使用 Azure 機(jī)器學(xué)習(xí)部署優(yōu)化模型了。
步驟 4 :將優(yōu)化模型部署到 Azure 機(jī)器學(xué)習(xí)端點(diǎn)
部署優(yōu)化的人工智能模型,以便在使用 Triton 的 Azure 機(jī)器學(xué)習(xí)涉及使用托管在線端點(diǎn)和Azure 機(jī)器學(xué)習(xí)工作室沒(méi)有代碼接口。
托管在線端點(diǎn)幫助您以交鑰匙方式部署 ML 模型。它負(fù)責(zé)服務(wù)、擴(kuò)展、保護(hù)和監(jiān)控您的模型,將您從設(shè)置和管理底層基礎(chǔ)設(shè)施的開(kāi)銷中解放出來(lái)。
要繼續(xù),請(qǐng)確保已下載Azure CLI,并且手頭有圖 6 所示的 YAML 文件。
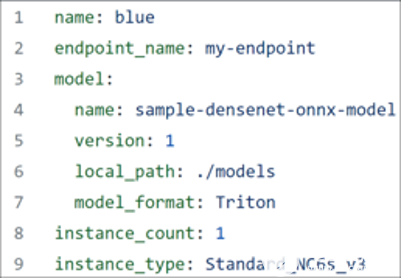
圖 6.優(yōu)化 BERT 模型的 YAML 文件
第一注冊(cè)您的模型使用上述 YAML 文件以 Triton 格式。您注冊(cè)的模型應(yīng)該類似于圖 7 ,如模型所示 Azure 機(jī)器學(xué)習(xí)工作室的頁(yè)面。
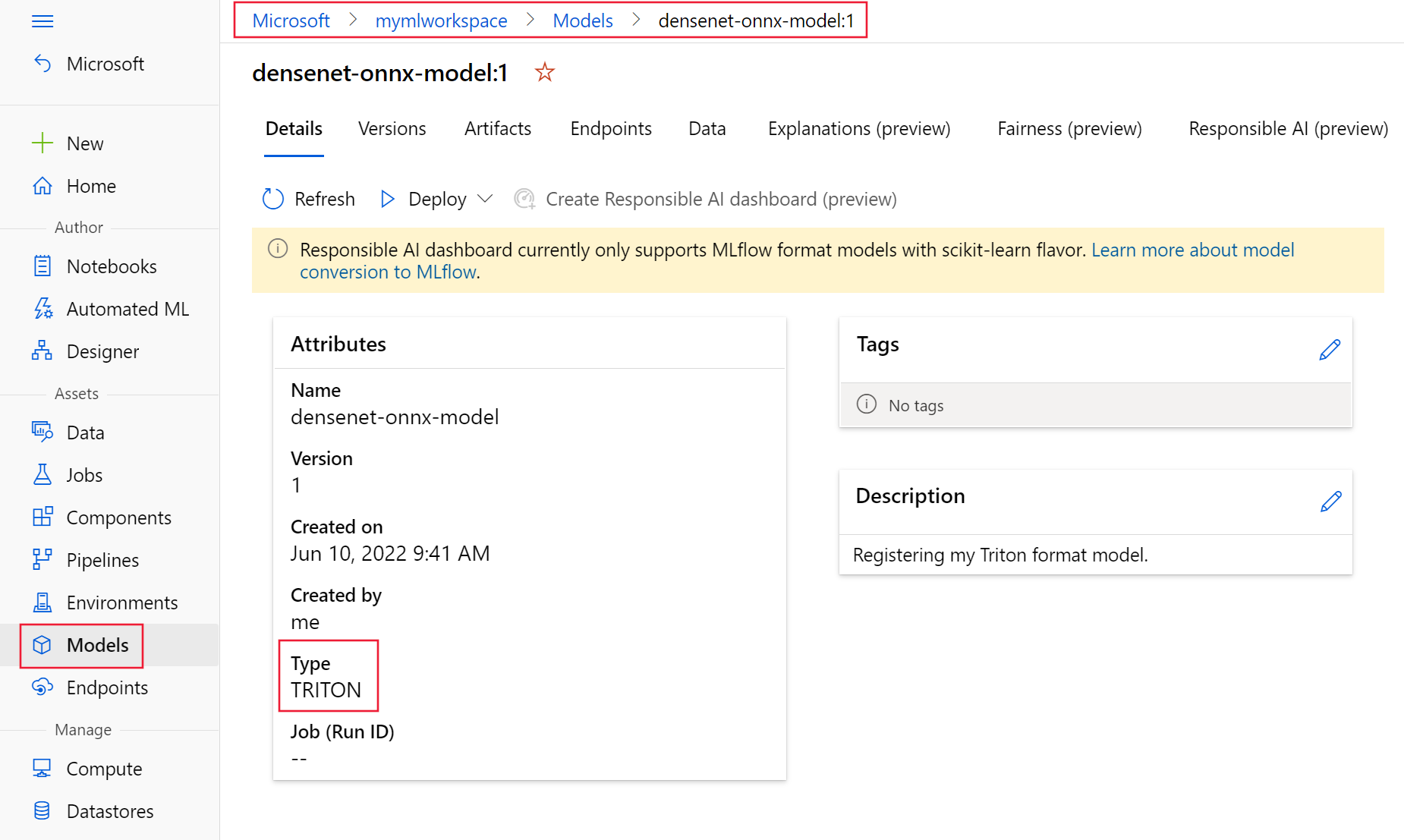
圖 7.Azure 機(jī)器學(xué)習(xí)工作室注冊(cè)的優(yōu)化模型
接下來(lái),選擇 Triton 模型,選擇“部署”,然后選擇“部署到實(shí)時(shí)端點(diǎn)”繼續(xù)通過(guò)向?qū)?ONNX 運(yùn)行時(shí)和 Triton 優(yōu)化模型部署到端點(diǎn)。請(qǐng)注意,將 Triton 模型部署到 Azure 機(jī)器學(xué)習(xí)管理端點(diǎn)時(shí),不需要評(píng)分腳本。
祝賀現(xiàn)在,您已經(jīng)在 Azure 機(jī)器學(xué)習(xí)上部署了一個(gè) BERT 小隊(duì)模型,該模型使用 ONNX 運(yùn)行時(shí)和 Triton 參數(shù)優(yōu)化了推理性能。通過(guò)優(yōu)化這些參數(shù),相對(duì)于未優(yōu)化的基線 BERT 小隊(duì)模型,您的性能提高了 10 倍。
關(guān)于作者
Manuel J.Reyes Gomez 是一位經(jīng)驗(yàn)豐富的數(shù)據(jù)科學(xué)和機(jī)器學(xué)習(xí)實(shí)踐者。他還是微軟公司的 NVIDIA 開(kāi)發(fā)者關(guān)系經(jīng)理,負(fù)責(zé)監(jiān)督兩家公司之間的協(xié)作 AI 和 ML 項(xiàng)目。
Emma Ning 是微軟人工智能框架團(tuán)隊(duì)的主要項(xiàng)目經(jīng)理,專注于人工智能模型的操作和加速,以及開(kāi)放和可互操作人工智能的 ONNX / ONNX 運(yùn)行時(shí)。她在利用機(jī)器學(xué)習(xí)技術(shù)的搜索引擎領(lǐng)域擁有超過(guò)五年的產(chǎn)品經(jīng)驗(yàn),并花了六年多的時(shí)間探索人工智能在各種企業(yè)中的應(yīng)用。她熱衷于引入人工智能解決方案來(lái)解決業(yè)務(wù)問(wèn)題,并提高產(chǎn)品體驗(yàn)。
Lei Qiao 是微軟人工智能框架團(tuán)隊(duì)的軟件工程師,專注于深度學(xué)習(xí)模型推理加速。她在將這些加速技術(shù)集成到不同的機(jī)器學(xué)習(xí)平臺(tái)方面也很有經(jīng)驗(yàn)。
Rohil Bhargava 是 NVIDIA 的產(chǎn)品營(yíng)銷經(jīng)理,專注于在特定 CSP 平臺(tái)上部署 NVIDIA 應(yīng)用程序框架和 SDK 。在加入 NVIDIA 之前,羅希爾曾擔(dān)任金融服務(wù)行業(yè)的顧問(wèn)和產(chǎn)品經(jīng)理。他的工作加速了人工智能在銀行遺留決策過(guò)程中的采用和分析工作流。他目前在卡內(nèi)基梅隆大學(xué)攻讀技術(shù)戰(zhàn)略 MBA ,并擁有西北大學(xué)工業(yè)工程和經(jīng)濟(jì)學(xué)學(xué)士學(xué)位。
審核編輯:郭婷
-
服務(wù)器
+關(guān)注
關(guān)注
13文章
9753瀏覽量
87582 -
人工智能
+關(guān)注
關(guān)注
1805文章
48899瀏覽量
247998 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8499瀏覽量
134333
發(fā)布評(píng)論請(qǐng)先 登錄
C#集成OpenVINO?:簡(jiǎn)化AI模型部署

使用NVIDIA推理平臺(tái)提高AI推理性能

人工智能和機(jī)器學(xué)習(xí)以及Edge AI的概念與應(yīng)用
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】2.具身智能機(jī)器人大模型
《具身智能機(jī)器人系統(tǒng)》第7-9章閱讀心得之具身智能機(jī)器人與大模型
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】+數(shù)據(jù)在具身人工智能中的價(jià)值
Arm KleidiAI助力提升PyTorch上LLM推理性能
Arm成功將Arm KleidiAI軟件庫(kù)集成到騰訊自研的Angel 機(jī)器學(xué)習(xí)框架
嵌入式和人工智能究竟是什么關(guān)系?
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第二章AI for Science的技術(shù)支撐學(xué)習(xí)心得
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第一章人工智能驅(qū)動(dòng)的科學(xué)創(chuàng)新學(xué)習(xí)心得
risc-v在人工智能圖像處理應(yīng)用前景分析
開(kāi)箱即用,AISBench測(cè)試展示英特爾至強(qiáng)處理器的卓越推理性能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論