 解決自動語音識別部署難題
解決自動語音識別部署難題
成功部署自動語音識別( ASR )應用程序可能是令人沮喪的體驗。例如,考慮到存在許多不同的方言和發音, ASR 系統很難在保持低延遲的同時正確識別單詞。
無論您使用的是商業解決方案還是開源解決方案,在構建 ASR 應用程序時都有許多挑戰需要考慮。
在這篇文章中,我強調了開發人員在向應用程序添加 ASR 功能時面臨的主要痛點。我以 NVIDIA Riva 語音 AI SDK 為例,分享如何應對和克服這些挑戰。
構建 ASR 應用程序的挑戰
以下是創建任何 ASR 系統時存在的一些挑戰:
低延遲
計算資源分配
靈活的部署和可擴展性
定制
監測和跟蹤
高精度
衡量語音識別準確性的一個關鍵指標是單詞錯誤率( WER )。 WER 定義為轉錄過程中識別的不正確和缺失單詞總數與標記轉錄本中出現的單詞總數之比。
有幾個原因導致 ASR 模型中的轉錄錯誤,導致信息的誤解:
訓練數據集的質量
不同的方言和發音
口音和語音變化
自定義或特定領域的詞和首字母縮略詞
詞的語境關系
區分語音相似的句子
由于這些因素,很難建立具有低 WER 分數的穩健 ASR 模型。
低延遲
一個對話人工智能 應用程序是由語音人工智能和自然語言處理( NLP )組成的端到端管道。
對于任何對話式人工智能應用程序,響應時間都是進行任何自然對話的關鍵因素。如果客戶在等待 1 分鐘后才收到響應,則與機器人對話是不實際的。
據觀察,任何對話 AI 應用程序都應: 提供小于 300 毫秒的延遲 因此,確保語音 AI 模型等待時間遠低于 300 毫秒限制,以集成到實時會話 AI 應用的端到端流水線中變得至關重要。
許多因素影響 ASR 模型的總體延遲:
Model size: 大型和復雜的模型具有更好的精度,但與較小的模型相比,需要大量的計算能力并增加延遲;即推斷成本高。
Hardware: 這種復雜模型的邊緣部署進一步增加了延遲要求的復雜性。
Network bandwidth: 流式傳輸音頻內容和轉錄本需要足夠的帶寬,尤其是在基于云的部署情況下。
計算資源分配
優化 ASR 模型及其資源利用適用于所有人工智能模型,而不僅僅是 ASR 模型。然而,這是影響運行任何人工智能應用程序的總體延遲和計算成本的關鍵因素。
優化模型的全部目的是在計算級別和延遲級別降低推理成本。但是,對于特定架構,在線可用的所有模型都不是平等創建的,并且不具有相同的代碼質量。他們在表現上也有巨大的差異。
此外,并非所有這些方法都以相同的方式響應知識提取、修剪、量化和其他優化技術,從而在不影響精度結果的情況下提高推理性能。
靈活的部署和可擴展性
創建準確高效的模型只是任何實時人工智能應用程序的一小部分。所需的周邊基礎設施龐大而復雜。例如,部署基礎設施應包括:
流式支持
資源管理處
服務基礎設施
分析工具支持
監測服務
創建一個定制的端到端優化部署管道,以支持任何 ASR 應用程序所需的延遲要求,這是一個挑戰,因為它需要在每個管道階段進行優化和加速。
根據給定實例必須支持的音頻流的數量,語音識別應用程序應該能夠自動擴展應用程序部署,以提供可接受的性能。
定制
讓模型開箱即用始終是我們的目標。然而,當前可用模型的性能取決于其訓練階段使用的數據集。模型通常適用于它們已經暴露的用例,但一旦在不同的域應用程序中部署,同一模型的性能可能會下降。
具體來說,在 ASR 的情況下,模型的性能取決于口音或語言以及語音變化。您應該能夠根據應用程序用例定制模型。
例如,在醫療保健或金融相關應用中部署的語音識別模型需要支持特定領域的詞匯表。該詞匯與 ASR 模型培訓期間通常使用的詞匯不同。
為了支持 ASR 的區域語言,您需要一套完整的培訓管道,以便輕松定制模型并有效地處理不同的方言。
監測和跟蹤
實時監控和跟蹤有助于獲得即時洞察、警報和通知,以便您及時采取糾正措施。這有助于根據傳入流量跟蹤資源消耗,從而可以自動縮放相應的應用程序。還可以設置配額限制,以在不影響總體吞吐量的情況下最小化基礎設施成本。
捕獲所有這些統計數據需要集成多個庫,以捕獲 ASR 管道各個階段的性能。
Riva SDK 如何應對 ASR 挑戰的示例
高級 SDK 可用于方便地為應用程序添加語音接口。在這篇文章中,我演示了如何在構建語音識別應用程序時使用 GPU 加速 SDK (如 Riva )來解決這些挑戰。
高精度和計算優化
您可以在 NGC 中使用預訓練的 Riva 語音模型,該模型可以使用 TAO 工具包在自定義數據集上進行微調,從而將特定領域的模型開發進一步加速 10 倍。
為 GPU 部署優化并加速了所有 NGC 模型,以實現更好的識別精度。 NVIDIA TensorRT 優化也完全支持這些模型。 Riva 的高性能推理由 TensorRT 優化提供支持,并使用 NVIDIA Triton 推理服務器來優化整體計算需求,進而提高服務器吞吐量
例如,以下是一些 NGC 上的 ASR 模型,它們作為 Riva 管道的一部分進一步優化,以獲得更好的性能:
Conformer-CTC xLarge
Citrinet 512
從模型、軟件到硬件, Riva 的整個堆棧不斷優化,實現了以下目標: 12 與上一代相比的增益 。
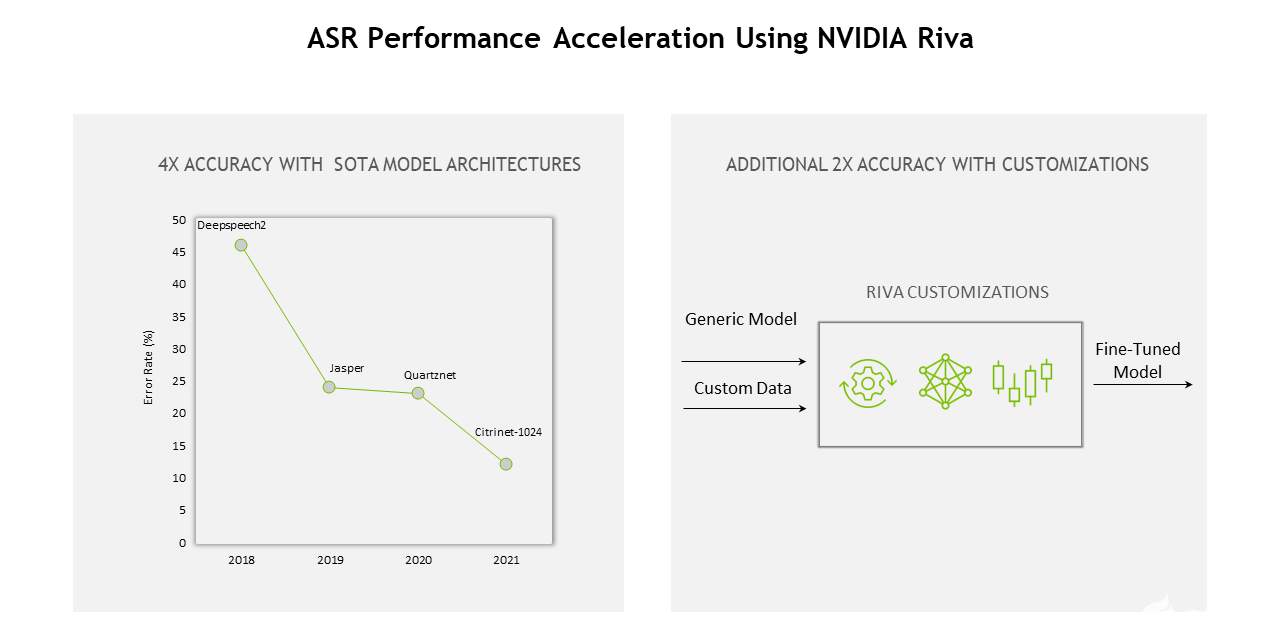
圖 1.使用 NVIDIA Riva 的 ASR 性能加速
低延遲
流式和離線配置的延遲和吞吐量測量報告在 ASR 性能 Riva 文件部分。
在“流式低延遲” Riva ASR 模型部署模式中,大多數情況下的平均延遲( ms )遠小于 50 ms 。使用這樣的 ASR 模型,創建實時會話 AI 管道變得更容易,并且仍然達到《 300 毫秒的延遲要求。
靈活的部署和擴展
在任何平臺上輕松部署語音識別應用程序都需要全面支持。 Riva SDK 在每一步都提供了靈活性,從對特定領域數據集的模型進行微調到定制管道。它還可以部署在云、本地、邊緣和嵌入式設備中。
為了支持擴展, Riva 是完全容器化的,可以擴展到成百上千個并行流。 Riva 也包含在 NGC Helm 倉庫 ,這是一個設計用于自動按下按鈕的圖表 部署到 Kubernetes 集群 。
定制
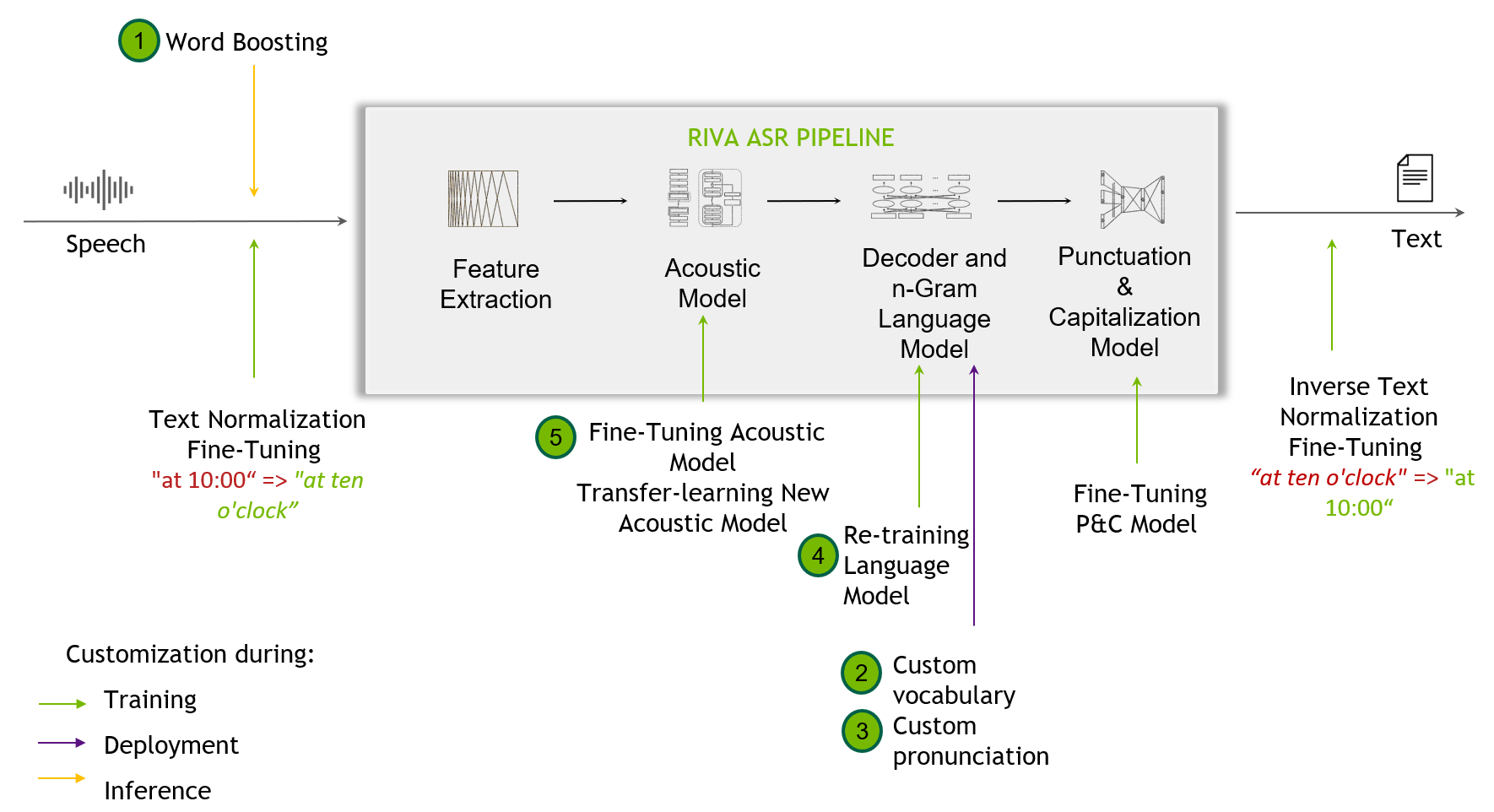
Figure 2. 定制技術包括從單詞提升到微調標點和大寫模型
定制技術 當開箱即用 Riva 模型無法處理訓練數據中未出現的挑戰性場景時,這是有用的。這可能包括識別窄域術語、新口音或嘈雜環境。
類似 Riva 的 SDK 支持 定制 ,從單詞增強級別開始,并為最終用戶提供定制訓練其聲學模型。
Riva 語音技能還提供了跨多種語言的高質量、預訓練模型。有關支持的語言的所有模型的更多信息,請參閱 語言支持 部分。
監測和跟蹤
在 Riva,基礎 Triton 推理服務器度量 基于自定義和儀表板創建,可供最終用戶使用。這些指標僅通過訪問端點可用。
NVIDIA Triton 提供普羅米修斯指標,以及指示 GPU 和請求統計。這有助于監控和跟蹤生產部署設置。
關鍵要點
這篇文章為您提供了開發具有 ASR 功能的 AI 應用程序時出現的常見痛點的高級概述。了解影響 ASR 應用程序整體性能的因素有助于簡化和改進端到端開發過程。
Sunil Kumar Jang Bahadur 是 NVIDIA Inception 團隊的高級解決方案架構師,專注于印度的人工智能初創企業。他在各種工業部門的軟件開發和技術解決方案方面擁有 12 年以上的經驗。他喜歡教機器,讓它們更人性化。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4978瀏覽量
102993 -
語音識別
+關注
關注
38文章
1739瀏覽量
112635
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論