 更改CTC規則以減少訓練和解碼中的內存消耗
更改CTC規則以減少訓練和解碼中的內存消耗
訓練自動語音識別( ASR )模型的損失函數并不是一成不變的。舊的損失函數規則不一定是最優的。考慮一下 connectionist temporal classification ( CTC ),看看改變它的一些規則如何能夠減少 GPU 內存,這是訓練和推斷基于 CTC 的模型所需的內存,等等。
聯結主義時間分類綜述
若你們要訓練一個 ASR 模型,無論是卷積神經網絡還是遞歸神經網絡、transformer 還是組合,你們很可能是用 CTC 損失訓練它。
CTC 簡單方便,因為它不需要每幀關于“什么聲音何時發音”(所謂的音頻文本時間對齊)的信息。在大多數情況下,這種知識是不可用的,就像在一個典型的 ASR 音頻數據集中,關聯文本沒有時間標記。
真正的時間校準并不總是微不足道的。假設大部分錄音沒有講話,結尾只有一個簡短短語。 CTC 損失并不能告訴模型何時準確地發出預測。相反,它允許每一種可能的對齊,并且只調整這些對齊的形式。
下面是 CTC 如何管理所有可能的方式來將音頻與文本對齊。
首先,對目標文本進行標記化,即將單詞切成字母或單詞片段。結果單元的數量(無論它們是什么)應小于音頻“時間段”的數量:長度為 0.01 到 0.08 秒的音頻段。
如果時間段少于單位,則算法失敗。在這種情況下,你應該縮短時間。否則,只有 RNN 傳感器可以挽救您。如果時間框架與單位一樣多,那么只能有一個對齊(百萬分之一的情況)。
大多數時候,時間段比單位要長得多,因此一些幀沒有單位。對于這種空幀, CTC 有一個特殊的 單元。本單元告訴您,在這個特定的框架下,模型沒有任何內容可以提供給您。這可能是因為沒有演講,或者模型太懶,無法預測有意義的東西。 CTC 最重要的規則 提供了如果模型不想做什么也不能預測的能力。
其他規則與單元延續有關。假設您的單元是一個持續時間超過一幀的元音。模型應在兩幀中的哪一幀上輸出單元? CTC 允許在多個連續幀上進行相同的單位發射。但是,應該將相同的連續單元合并為一個單元,以將識別結果轉換為一系列類似文本的單元。
現在,如果標記化文本本身包含相同的重復單位,如“ ll ”或“ pp ”,該怎么辦?如果不進行處理,這些單元將合并為一個單元,即使它們不應該合并。對于這種特殊情況, CTC 有一條規則,如果目標文本有重復的單位,那么在推理過程中這些單位必須用 分隔。
綜上所述,在幾乎每一幀中,模型都可以從上一幀 發射相同的單元,或者如果下一幀與上一幀不同,則可以發射下一個單元。這些規則比 規則更為復雜,對于反恐委員會來說,它們并不完全必要。
反恐委員會的執行
以下是如何表示 CTC 損失。與機器學習中的大多數損失函數一樣,它通常表示為一個動態算法,將這些規則應用于訓練語句或模型的 softmax 輸出。
在訓練中,損失值和梯度由適用于 CTC 規則的 Baum–Welch algorithm 根據所有可能路線的條件概率計算得出。 CTC 實現通常有數百到數千行代碼,很難修改。
幸運的是,還有另一種執行反恐委員會的方法。除了其他應用領域外,加權有限狀態傳感器( WFST )方法允許模型將動態算法表示為一組圖形和相關圖形操作。這種方法使您能夠通過將 CTC 規則應用于特定的音頻和文本,并通過計算損失和梯度來解耦 CTC 規則。
CTC WFST 應用程序
有了 WFST ,您可以輕松地采用 CTC 規則,并使用不同的標準,如最大互信息( MMI )。這些模型通常具有比 CTC 模型更低的字錯誤率( WER )。 MMI 將先前的語言信息納入培訓過程。
與 CTC 相比, MMI 不僅最大化了最可行路徑的概率,而且最小化了其他路徑的概率。為此, MMI 有一個所謂的分母圖,它可以在訓練期間占用大量 GPU 內存。幸運的是,可以修改一些 CTC 規則以減少分母內存消耗,而不會影響語音識別的準確性。
此外, CTC 規則的 WFST 表示,或所謂的 topology ,可用于對 CTC 模型進行 WFST 解碼。為此,您可以將 N -gram 語言模型轉換為 WFST 圖,并將其與拓撲圖組合在一起。生成的解碼圖可以傳遞給,例如, Riva CUDA WFST Decoder 。
解碼圖可能很大,以至于無法放入 GPU 內存。但通過一些 CTC 拓撲修改,您可以減少 CTC 的解碼圖形大小。
CTC 拓撲
圖 1 顯示了 CTC 拓撲, Correct CTC 。這是一個帶自循環的有向完整圖,因此對于 N 單元(包括空白),有 N 狀態和弧的平方數。
正確的反恐委員會是最常用的反恐委員會代表。看看這個拓撲產生的典型大小。對于 LibriSpeech 4 字語言模型和 256 個模型詞匯單元,解碼圖大小為~ 16Gb 。對于型號詞匯表大小為 2048 的 32Gb GPU ,僅當批次大小為 1 時,才可以進行冷啟動 MMI 培訓。
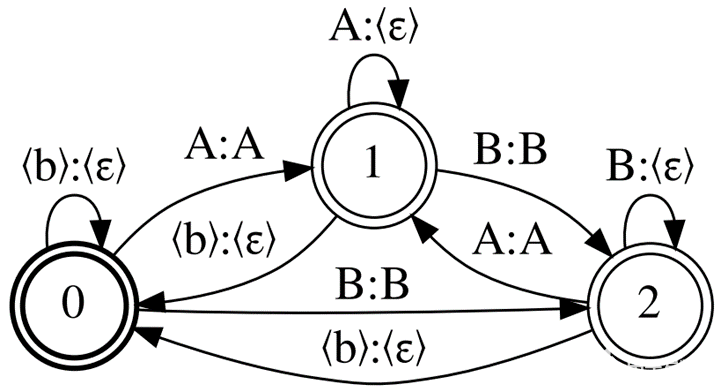
圖 1.三單元詞匯表的正確 CTC 示例:《 blank 》、 a 和 B
通過刪除一些 CTC 規則來減少 Correct CTC 引起的內存消耗。首先,使用 刪除重復單元的強制分隔。如果沒有這個規則,您最終會得到一個名為 CompactCTC 的拓撲(圖 2 )。它有 3 個 N – 2 個弧用于 N 單元。
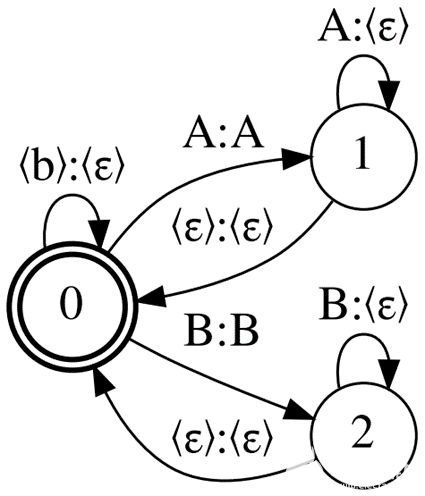
圖 2.緊湊型 CTC 示例
盡管有純

(虛擬)弧,但這種拓撲結構可用于訓練和解碼,不會對識別質量產生負面影響。如果您想知道這是如何工作的,請參閱 CTC Variations Through New WFST Topologies 或 執行 NVIDIA NeMo 。
使用 Compact CTC 的解碼圖形大小比使用 Correct CTC 的小四分之一。它還需要 2x 更少的 GPU 內存用于 MMI 訓練。
現在在多個連續幀上丟棄相同的單位發射,只保留 規則。這樣,您得到的拓撲只有一個狀態和 N 單元的 N 弧。
這是可能的最小 CTC 拓撲,所以我們稱之為最小 CTC (圖 3 )。它需要更少的 GPU 內存用于 MMI 訓練(與 Correct CTC 相比減少了 4 倍),但與基線相比,使用 Minimal CTC 拓撲的 MMI 訓練模型的精度會降低。
最小的拓撲還產生最小的解碼 WFST ,其大小為基線圖的一半。用 Minimal CTC 編譯的解碼圖與用 Correct CTC 或 Compact CTC 構建的模型不兼容。
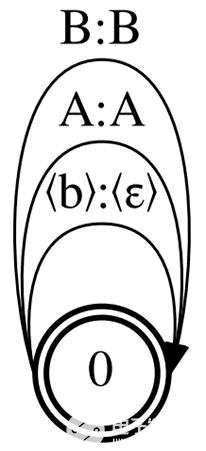
圖 3.最小 CTC 示例
最后,我回到了 Correct CTC ,但這次離開了強制分離重復單元,并放棄了單元繼續。名為 Selfless CTC 的拓撲結構旨在彌補 Minimal CTC 的缺點。
圖 1 和圖 4 顯示, Correct CTC 和 Selfles CTC 僅在非 自我循環中有所不同。這兩種拓撲結構還提供了相同的 MMI 模型精度,如果模型具有較長的上下文窗口,則可以提供更好的精度。然而, Selfless CTC 在解碼時也與 Minimal CTC 兼容。通過 Minimal CTC ,您只需增加 0.2% 的 WER ,即可將圖形大小減少 2 倍。
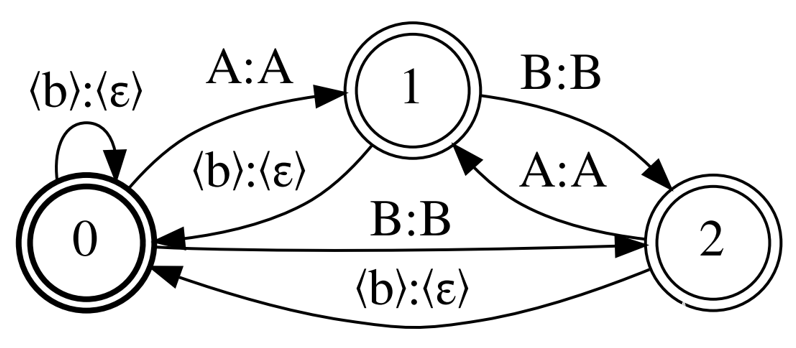
圖 4.Selfless CTC 示例;基于正確的 CTC
結論
有幾個技巧可以提高性能:
在解碼圖構造和 MMI 訓練中,使用 Compact CTC 代替 Correct CTC 。
為了最大程度地減小解碼圖形的大小,請使用 Selfles CTC 訓練您的模型,并使用 Minimal CTC 解碼。
損失函數不是一成不變的:嘗試使用現有損失函數的 WFST 表示法并創建新的表示法。這很有趣!
關于作者
Aleksandr Laptev 是 ITMO 大學的博士生,也是 NVIDIA 的高級研究科學家。他的科學興趣是自動語音識別、語音合成( TTS )和自然語言處理。他撰寫開放獲取科學文章,為開放源代碼軟件做出貢獻,并參加國際語音識別比賽。他目前的研究領域是可微加權有限狀態傳感器。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4981瀏覽量
103000 -
語音識別
+關注
關注
38文章
1739瀏覽量
112638
發布評論請先 登錄
相關推薦
如何在CubeIDE中更改內存區域?
減少電流消耗的技巧和竅門有哪些?
LC7461紅外遙控器和解碼程序
什么是音頻的編碼和解碼/HZ(赫茲)
基于STM32的BMP圖片解碼系統

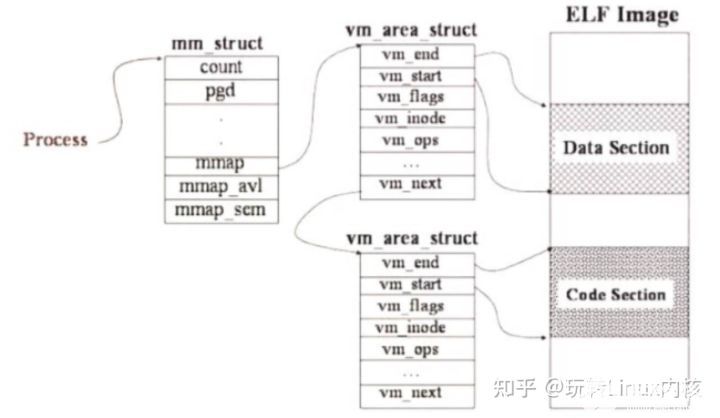
Linux進程的內存消耗和泄漏詳解






 工商網監
工商網監
評論