") 文本噪聲標(biāo)簽在預(yù)訓(xùn)練語(yǔ)言模型(PLMs)上的特性
文本噪聲標(biāo)簽在預(yù)訓(xùn)練語(yǔ)言模型(PLMs)上的特性
數(shù)據(jù)的標(biāo)簽錯(cuò)誤隨處可見(jiàn),如何在噪聲數(shù)據(jù)集上學(xué)習(xí)到一個(gè)好的分類器,是很多研究者探索的話題。在 Learning With Noisy Labels 這個(gè)大背景下,很多方法在圖像數(shù)據(jù)集上表現(xiàn)出了非常好的效果。
而文本的標(biāo)簽錯(cuò)誤有時(shí)很難鑒別。比如對(duì)于一段文本,可能專家對(duì)于其主旨類別的看法都不盡相同。這些策略是否在語(yǔ)言模型,在文本數(shù)據(jù)集上表現(xiàn)好呢?本文探索了文本噪聲標(biāo)簽在預(yù)訓(xùn)練語(yǔ)言模型(PLMs)上的特性,提出了一種新的學(xué)習(xí)策略 SelfMix,并機(jī)器視覺(jué)上常用的方法應(yīng)用于預(yù)訓(xùn)練語(yǔ)言模型作為 baseline。
為什么選 PLMs
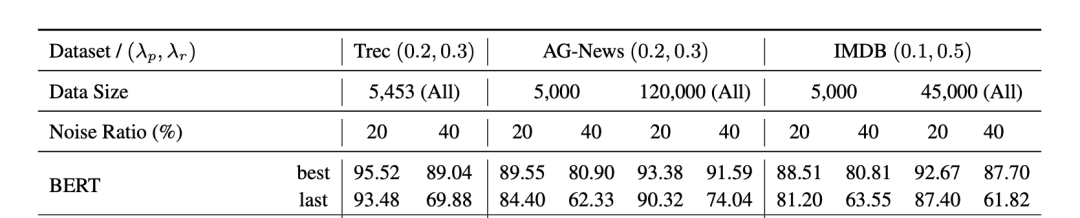
我們對(duì)于常見(jiàn)語(yǔ)言分類模型在帶噪文本數(shù)據(jù)集上做了一些前期實(shí)驗(yàn),結(jié)果如下:

首先,毫無(wú)疑問(wèn),預(yù)訓(xùn)練模型(BERT,RoBERTa)的表現(xiàn)更好。其次,文章提到,預(yù)訓(xùn)練模型已經(jīng)在大規(guī)模的預(yù)訓(xùn)練語(yǔ)料上獲得了一定的類別先驗(yàn)知識(shí)。故而在有限輪次訓(xùn)練之后,依然具有較高的準(zhǔn)確率,如何高效利用預(yù)訓(xùn)練知識(shí)處理標(biāo)簽噪聲,也是一個(gè)值得探索的話題。
預(yù)訓(xùn)練模型雖然有一定的抗噪學(xué)習(xí)能力,但在下游任務(wù)的帶噪數(shù)據(jù)上訓(xùn)練時(shí)也會(huì)受到噪聲標(biāo)簽的影響,這種現(xiàn)象在少樣本,高噪聲比例的設(shè)置下更加明顯。
方法
由此,我們提出了 SelfMix,一種對(duì)抗文本噪聲標(biāo)簽的學(xué)習(xí)策略。
基礎(chǔ)模型上,我們采用了 BERT encoder + MLP 這一常用的分類范式。
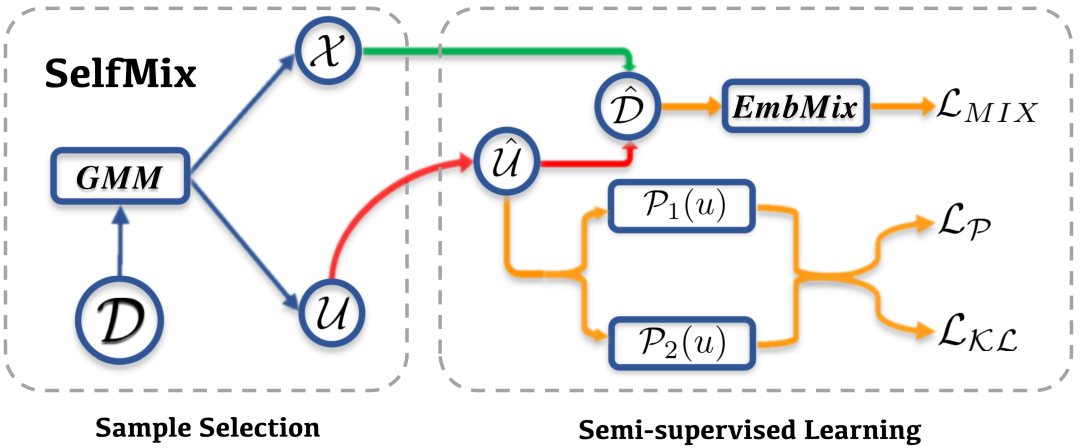
針對(duì)帶噪學(xué)習(xí)策略,主要可以分為兩個(gè)部分
Sample Selection
Semi-supervised Learning
Sample Selection
Sample Selection 部分對(duì)于原始數(shù)據(jù)集 ,經(jīng)過(guò)模型的一次傳播,根據(jù)每個(gè)樣本對(duì)應(yīng)的 loss,通過(guò) 2 核的 GMM 擬合將數(shù)據(jù)集分為干凈和帶噪聲的兩個(gè)部分,分別為 和 。因?yàn)槠渲?被認(rèn)為是噪聲數(shù)據(jù)集,所以其標(biāo)簽全部被去除,認(rèn)為是無(wú)標(biāo)簽數(shù)據(jù)集。
這里的 GMM,簡(jiǎn)單的來(lái)講其實(shí)可以看作是根據(jù)整體的 loss 動(dòng)態(tài)擬合出一個(gè)閾值(而不是規(guī)定一個(gè)閾值,因?yàn)樵谟?xùn)練過(guò)程中這個(gè)閾值會(huì)變化),將 loss 位于閾值兩邊的分別分為 clean samples 和 noise samples。
Semi-supervised Learning
關(guān)于 Semi-supervised Learning 部分,SelfMix 首先利用模型給給無(wú)標(biāo)簽的數(shù)據(jù)集打偽標(biāo)簽(這里采用了 soft label 的形式),得到 。因?yàn)榇騻螛?biāo)簽需要模型在這個(gè)下游任務(wù)上有一定的判別能力,所以模型需要預(yù)先 warmup 的少量的步數(shù)。
「Textual Mixup」:文中采用了句子 [CLS] embedding 做 mixup。Mixup 也是半監(jiān)督和魯棒學(xué)習(xí)中經(jīng)常采用的一個(gè)策略。
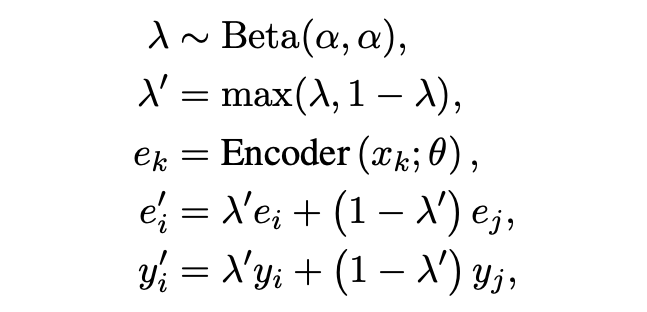
「Pseudo-Loss」:文中的解釋比較拗口,其實(shí)本質(zhì)也是一種在半監(jiān)督訓(xùn)練過(guò)程中常用的對(duì)模型輸出墑的約束。
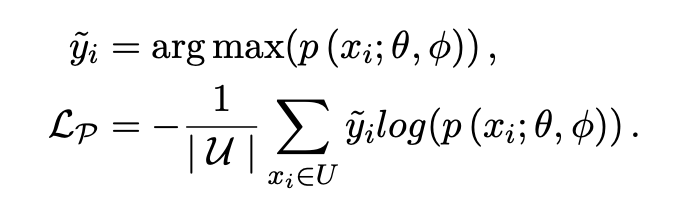
「Self-consistency Regularization」:其他的很多帶噪學(xué)習(xí)方法大都是多模型集成決策的想法,但我們認(rèn)為可以利用 dropout 機(jī)制來(lái)使得單個(gè)模型做自集成。噪聲數(shù)據(jù)因?yàn)榕c標(biāo)簽的真實(shí)分布相悖,往往會(huì)導(dǎo)致子模型之間產(chǎn)生很大的分歧,我們不希望在高噪聲環(huán)境下子模型的分歧越來(lái)越大,故而采用了 R-Drop 來(lái)約束子模型。具體的做法是,計(jì)算兩次傳播概率分布之間的 KL 散度,作為 loss 的一部分,并且消融實(shí)驗(yàn)證明這個(gè)方法是十分有效的。
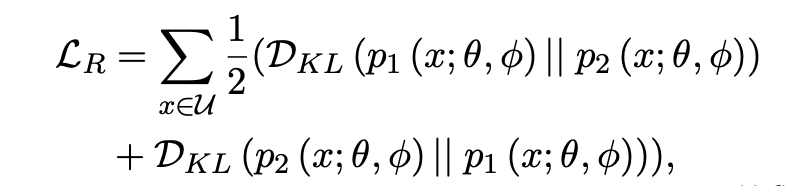
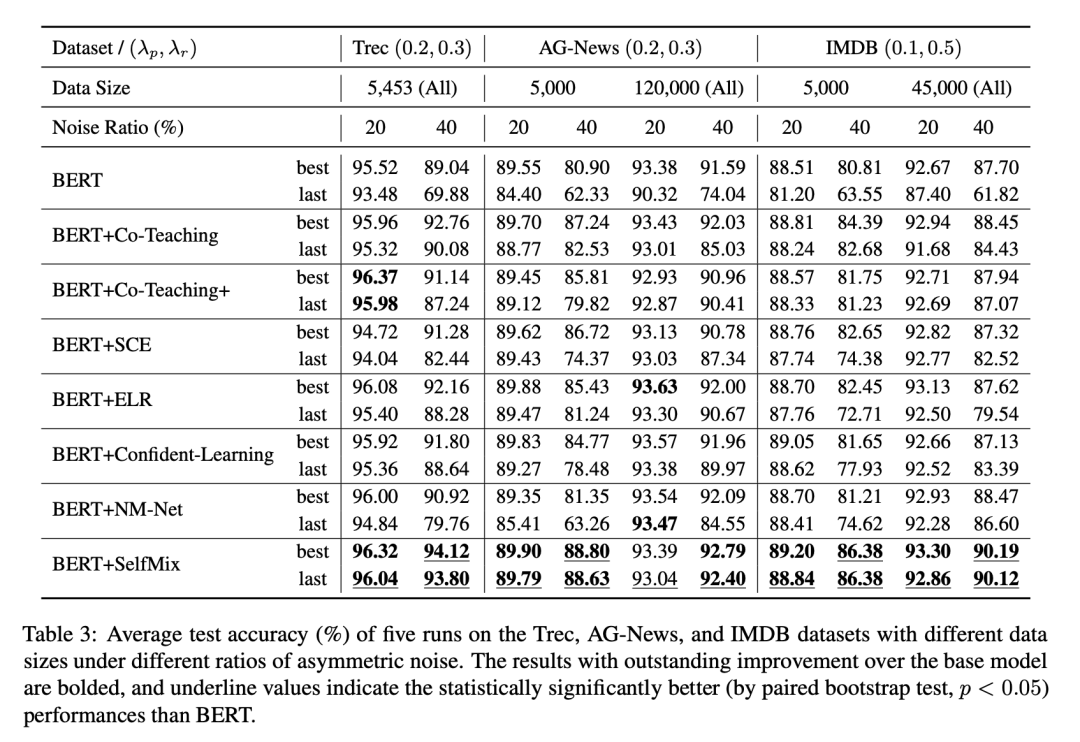
實(shí)驗(yàn)
我們?cè)?IDN (Instance-Dependent Noise) 和 Asym (Asymmetric Noise) 做了實(shí)驗(yàn),并且對(duì)數(shù)據(jù)集做了切分來(lái)擬合數(shù)據(jù)充分和數(shù)據(jù)補(bǔ)充的情況,并設(shè)置了不同比例的標(biāo)簽噪聲來(lái)擬合微量噪聲至極端噪聲下的情況,上圖!
ASYM 噪聲實(shí)驗(yàn)結(jié)果
ASYM 噪聲按照一個(gè)特定的噪聲轉(zhuǎn)移矩陣將一個(gè)類別樣本的標(biāo)簽隨機(jī)轉(zhuǎn)換為一個(gè)特定類別的標(biāo)簽,來(lái)形成類別之間的混淆。
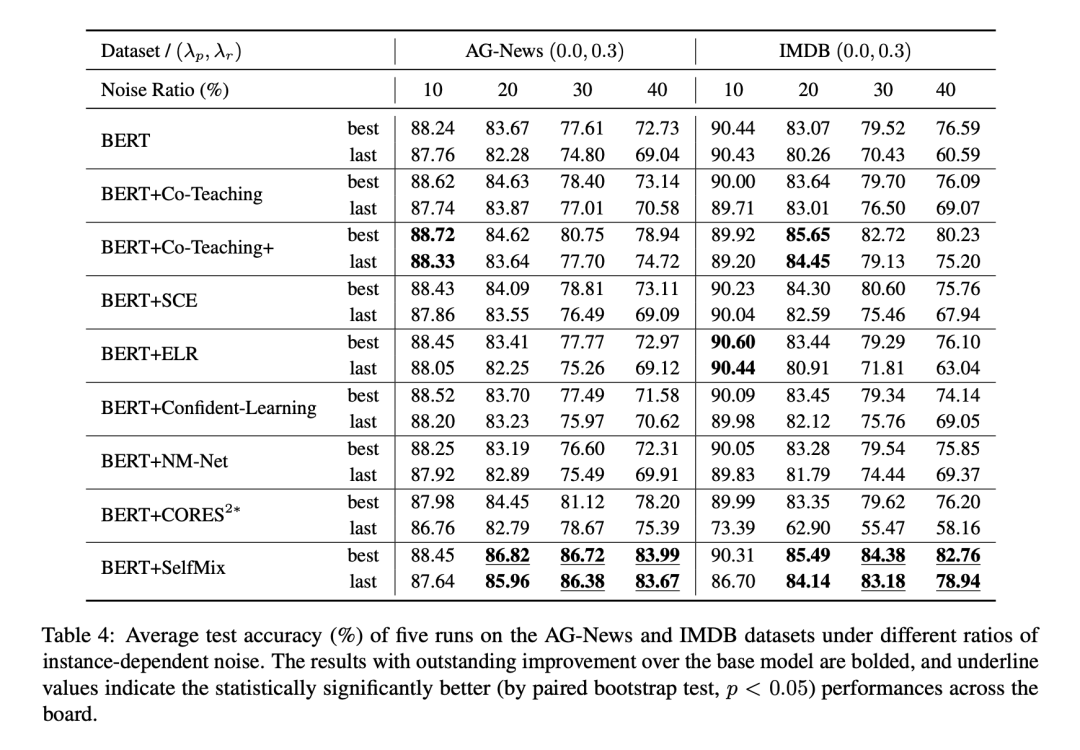
IDN 噪聲實(shí)驗(yàn)結(jié)果
為了擬合基于樣本特征的錯(cuò)標(biāo)情況,我們訓(xùn)練了一個(gè)LSTM文本分類,對(duì)于一個(gè)樣本,將LSTM對(duì)于其預(yù)測(cè)結(jié)果中更容易錯(cuò)的類別作為其可能的噪聲標(biāo)簽。
其他的一些討論
GMM 是否有效:從 a-c, d-f 可看出高斯混合模型能夠比較充分得擬合 clean 和 noise 樣本的 loss 分布。
SelfMix 對(duì)防止模型過(guò)擬合噪聲的效果是否明顯:d, h 兩張圖中,BERT-base 和 SelfMix 的 warmup 過(guò)程是完全一致的,warmup 過(guò)后 SelfMix 確實(shí)給模型的性能帶來(lái)了一定的提升,并且趨于穩(wěn)定,有效避免了過(guò)擬合噪聲的現(xiàn)象。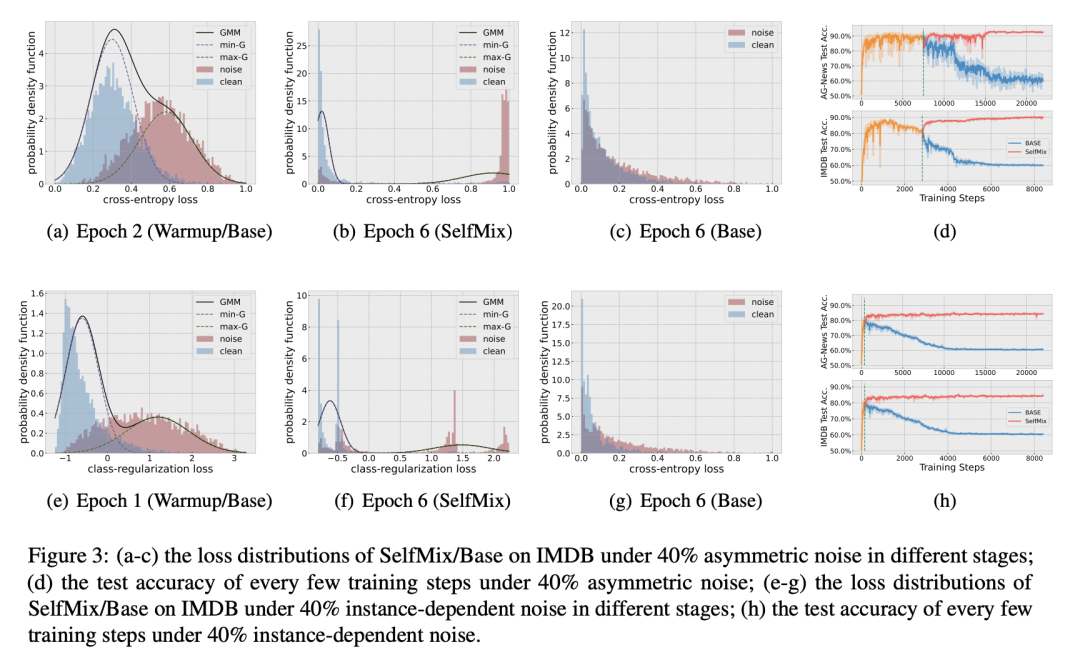
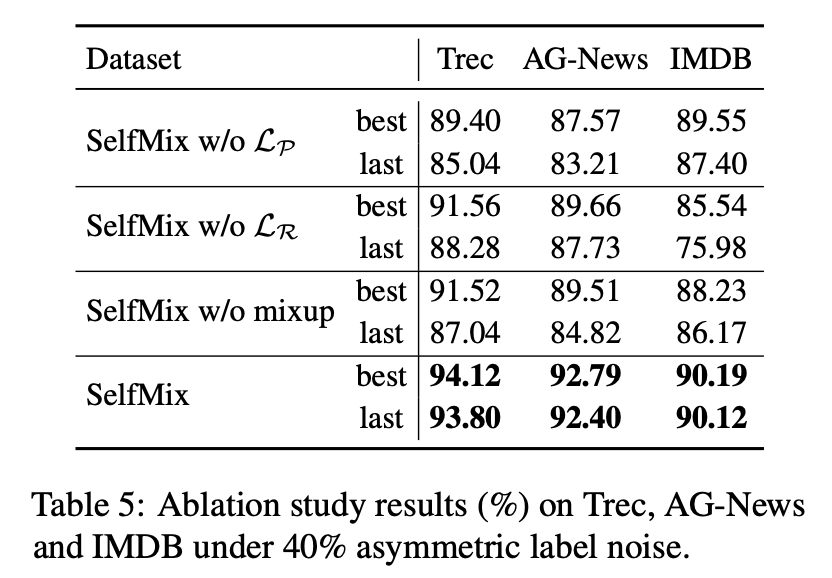
考慮到模型最終的優(yōu)化目標(biāo)包括三個(gè)項(xiàng),我們做了消融實(shí)驗(yàn),分別去掉其中一個(gè)約束來(lái)看看模型表現(xiàn)如何,最終證明每個(gè)約束確實(shí)對(duì)于處理噪聲標(biāo)簽有幫助。
-
噪聲
+關(guān)注
關(guān)注
13文章
1122瀏覽量
47442 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
530瀏覽量
10298 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24739
原文標(biāo)題:COLING'22 | SelfMix:針對(duì)帶噪數(shù)據(jù)集的半監(jiān)督學(xué)習(xí)方法
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
一文詳解知識(shí)增強(qiáng)的語(yǔ)言預(yù)訓(xùn)練模型
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的基礎(chǔ)技術(shù)
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的預(yù)訓(xùn)練
預(yù)訓(xùn)練語(yǔ)言模型設(shè)計(jì)的理論化認(rèn)識(shí)
基于BERT的中文科技NLP預(yù)訓(xùn)練模型
如何向大規(guī)模預(yù)訓(xùn)練語(yǔ)言模型中融入知識(shí)?

Multilingual多語(yǔ)言預(yù)訓(xùn)練語(yǔ)言模型的套路
一種基于亂序語(yǔ)言模型的預(yù)訓(xùn)練模型-PERT
利用視覺(jué)語(yǔ)言模型對(duì)檢測(cè)器進(jìn)行預(yù)訓(xùn)練
CogBERT:腦認(rèn)知指導(dǎo)的預(yù)訓(xùn)練語(yǔ)言模型
復(fù)旦&微軟提出?OmniVL:首個(gè)統(tǒng)一圖像、視頻、文本的基礎(chǔ)預(yù)訓(xùn)練模型
預(yù)訓(xùn)練數(shù)據(jù)大小對(duì)于預(yù)訓(xùn)練模型的影響
基于預(yù)訓(xùn)練模型和語(yǔ)言增強(qiáng)的零樣本視覺(jué)學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論