 深度學習-會開發AI的AI:超網絡有望讓深度學習大眾化
深度學習-會開發AI的AI:超網絡有望讓深度學習大眾化
超網絡(hypernetwork)可以加快訓練AI的過程。
編者按:在執行特定類型任務,如圖像識別、語音識別等方面,AI已經可以與人類相媲美了,甚至有時候已經超越了人類。但這些AI事先必須經過訓練,而訓練是個既耗時又耗計算能力的過程,有上百萬甚至幾十億的參數需要優化。但最近研究人員做出了能瞬時預測參數的超網絡。通過利用超網絡(hypernetwork),研究人員現在可以先下手為強,提前對人工神經網絡進行調優,從而節省部分訓練時間和費用。文章來自編譯。譯者:boxi。
劃重點:
人工智能是一場數字游戲,訓練耗時耗力
超網絡可以在幾分之一秒內預測出新網絡的參數
超網絡的表現往往可以跟數千次 SGD 迭代的結果不相上下,有時甚至是更好
超網絡有望讓深度學習大眾化
人工智能在很大程度上是一場數字游戲。10 年前,深度神經網絡(一種學習識別數據模式的 AI 形式)之所以開始超越傳統算法,那是因為我們終于有了足夠的數據和處理能力,可以充分利用這種AI。
現如今的神經網絡對數據和處理能力更加渴望。訓練它們需要對表征參數的值進行仔細的調整,那些參數代表人工神經元之間連接的強度,有數百萬甚至數十億之巨。其目標是為它們找到接近理想的值,而這個過程叫做優化,但訓練網絡達到這一點并不容易。 DeepMind研究科學家Petar Veli?kovi? 表示:“訓練可能需要數天、數周甚至數月之久”。
但這種情況可能很快就會改變。加拿大安大略省圭爾夫大學(University of Guelph)的Boris Knyazev和他的同事設計并訓練了一個“超網絡”——這有點像是凌駕于其他神經網絡之上的最高統治者——用它可以加快訓練的過程。給定一個為特定任務設計,未經訓練的新深度神經網絡,超網絡可以在幾分之一秒內預測出該新網絡的參數,理論上可以讓訓練變得不必要。由于超網絡學習了深度神經網絡設計當中極其復雜的模式,因此這項工作也可能具有更深層次的理論意義。
目前為止,超網絡在某些環境下的表現出奇的好,但仍有增長空間——考慮到問題的量級,這是很自然的。如果他們能解決這個問題,Veli?kovi?說:“這將對機器學習產生很大的影響。”。
變成“超網絡”
目前,訓練和優化深度神經網絡最好的方法是隨機梯度下降(SGD) 技術的各種變種。訓練涉及到將網絡在給定任務(例如圖像識別)中所犯的錯誤最小化。 SGD 算法通過大量標記數據來調整網絡參數,并減少錯誤或損失。梯度下降是從損失函數的高位值一級級向下降到某個最小值的迭代過程,代表的是足夠好的(或有時候甚至是可能的最好)參數值。
但是這種技術只有在你有需要優化的網絡時才有效。為了搭建最開始的神經網絡(一般由從輸入到輸出的多層人工神經元組成),工程師必須依靠自己的直覺和經驗法則。這些結構在神經元的層數、每層包含的神經元數量等方面可能會有所不同。
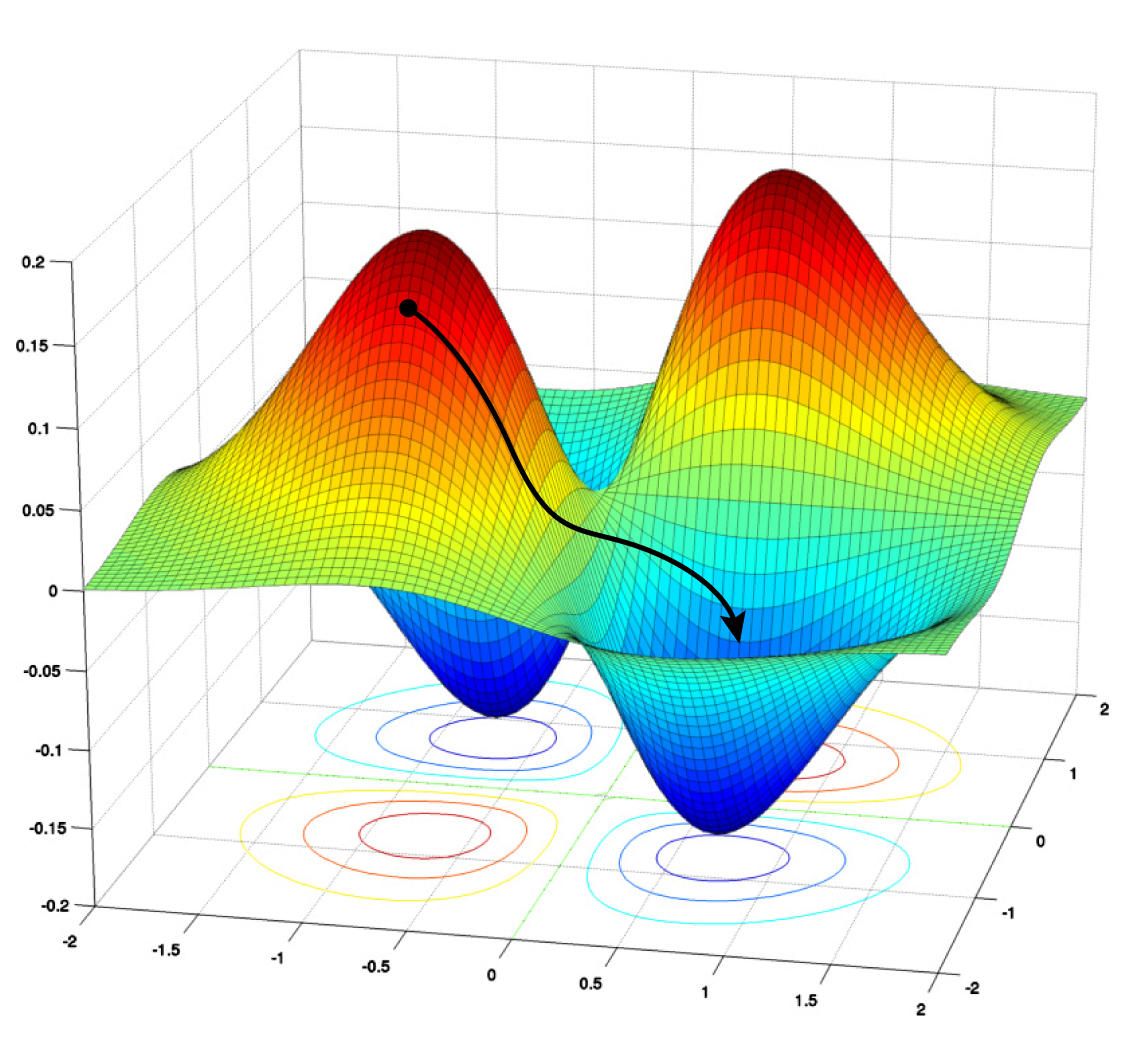
梯度下降算法讓網絡沿著其“損失景觀”向下走,其中高位值表示較大錯誤或損失。算法旨在找到全局最小值,讓損失最小化。
理論上可以從多個結構出發,然后優化每個結構并選出最好的。但Google Brain 訪問學者 MengYe Ren 說:“訓練需要花費相當多的時間,要想訓練和測試每以個候選網絡結構是不可能的。這種做法擴展不好,尤其是如果要考慮到數百萬種可能設計的話。”
于是 2018 年,Ren 與自己在多倫多大學的前同事 Chris Zhang ,以及他們的指導 Raquel Urtasun 開始嘗試一種不同的方法。他們設計出一種所謂的圖超網絡(Graph Hypernetwork, GHN),這種網絡可以在給出一組候選結構的情況下,找出解決某個任務的最佳深度神經網絡結構。
顧名思義,“圖”指的是深度神經網絡的架結構,可以認為是數學意義的圖——由線或邊連接的點或節點組成的集合。此處節點代表計算單元(通常是神經網絡的一整層),邊代表的是這些單元互連的方式。
原理是這樣的。圖超網絡從任何需要優化的結構(稱其為候選結構)開始,然后盡最大努力預測候選結構的理想參數。接著將實際神經網絡的參數設置為預測值,用給定任務對其進行測試。Ren 的團隊證明,這種方法可用于來對候選結構進行排名,并選擇表現最佳的結構。
當 Knyazev 和他的同事想出圖超網絡這個想法時,他們意識到可以在此基礎上進一步開發。在他們的新論文里,這支團隊展示了 GHN 的用法,不僅可以用來從一組樣本中找到最佳的結構,還可以預測最好網絡的參數,讓網絡表現出絕對意義上的好。在其中的最好還沒有達到最好的情況下,還可以利用梯度下降進一步訓練該網絡。
在談到這項新工作時,Ren 表示:“這篇論文非常扎實,里面包含的實驗比我們多得多。他們在非常努力地提升圖超網絡的絕對表現,這是我們所樂見的。”
訓練“訓練師”
Knyazev和他的團隊將自己的超網絡稱為是 GHN -2,這種網絡從兩個重要方面改進了Ren及其同事構建的圖超網絡。
首先,他們需要依賴 Ren 等人的技術,用圖來表示神經網絡結構。該圖里面的每個節點都包含有關于執行特定類型計算的神經元子集的編碼信息。圖的邊則描述了信息是如何從一個節點轉到另一節點,如何從輸入轉到輸出的。
他們借鑒的第二個想法是一種方法,訓練超網絡來預測新的候選結構的方法。這需要用到另外兩個神經網絡。第一個用來開啟對原始候選圖的計算,更新與每個節點相關的信息,第二個把更新過的節點作為輸入,然后預測候選神經網絡相應計算單元的參數。這兩個網絡也有自己的參數,在超網絡能夠正確預測參數值之前,必須對這兩個網絡進行優化。
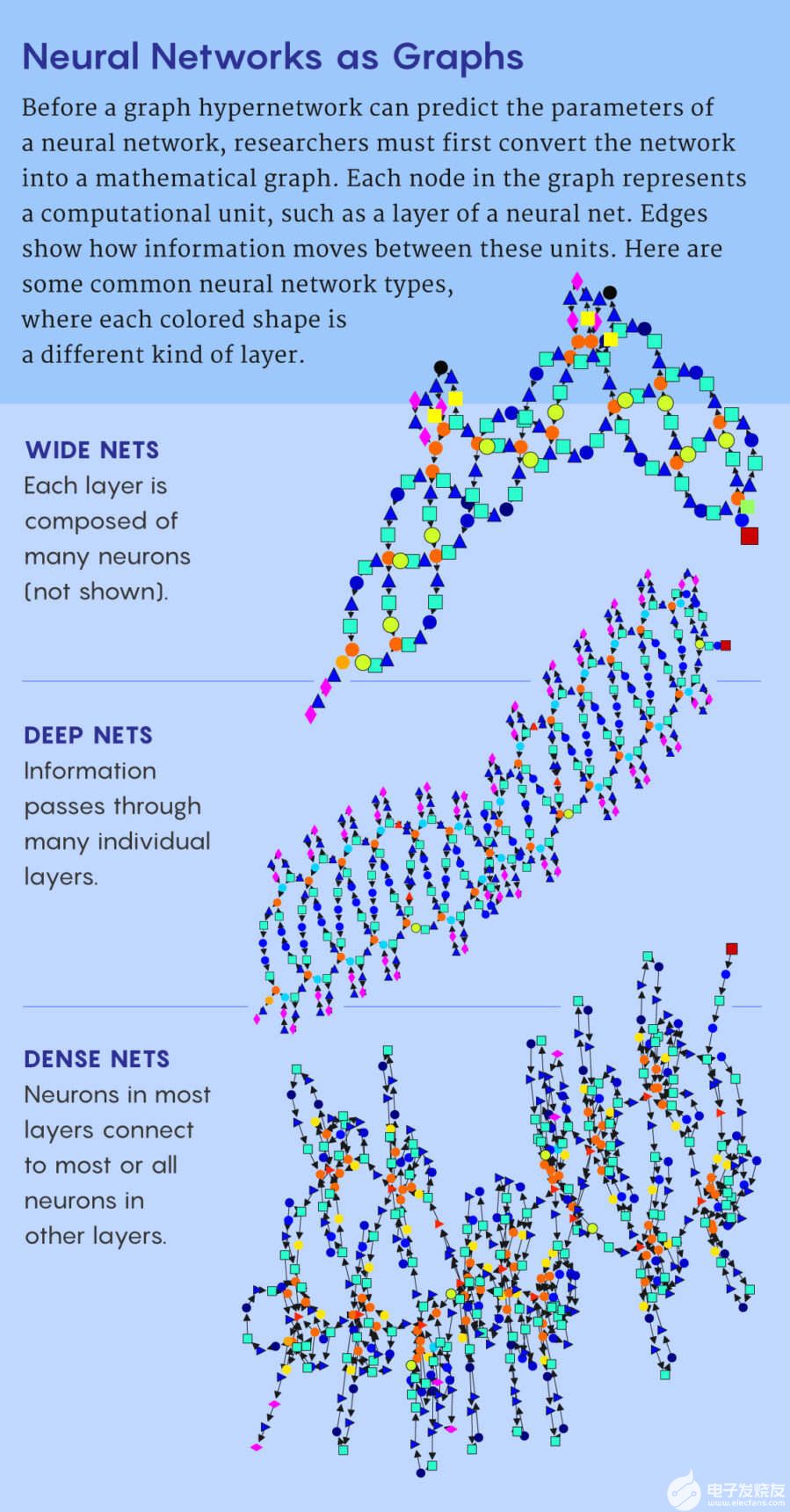
用圖來表示神經網絡
為此,你得訓練數據——在本案例中,數據就是可能的人工神經網絡(ANN)結構的隨機樣本。對于樣本的每一個結構,你都要從圖開始,然后用圖超網絡來預測參數,并利用預測的參數對候選 ANN進行初始化。然后該ANN會執行一些特定任務,如識別一張圖像。通過計算該ANN的損失函數來更新做出預測的超網絡的參數,而不是更新該ANN的參數以便做出更好的預測。這樣以來,該超網絡下一次就能做得更好。現在,通過遍歷部分標記訓練圖像數據集的每一張圖像,以及隨機樣本結構里面的每一個ANN,一步步地減少損失,直至最優。到了一定時候,你就可以得到一個訓練好的超網絡。
由于Ren 的團隊沒有公開他們的源代碼,所以Knyazev 的團隊采用上述想法自己從頭開始寫軟件。然后Knyazev及其同事在此基礎上加以改進。首先,他們確定了 15 種類型的節點,這些節點混合搭配可構建幾乎任何的現代深度神經網絡。在提高預測準確性方面,他們也取得了一些進展。
最重要的是,為了確保 GHN-2 能學會預測各種目標神經網絡結構的參數,Knyazev 及其同事創建了一個包含 100 萬種可能結構的獨特數據集。Knyazev 說:“為了訓練我們的模型,我們創建了盡量多樣化的隨機結構”。
因此,GHN-2 的預測能力很有可能可以很好地泛化到未知的目標結構。Google Research的Brain Team研究科學家 Thomas Kipf 說:“比方說,人們使用的各種典型的最先進結構他們都可以解釋,這是一大重大貢獻。”
結果令人印象深刻
當然,真正的考驗是讓 GHN-2 能用起來。一旦 Knyazev 和他的團隊訓練好這個網絡,讓它可以預測給定任務(比方說對特定數據集的圖像進行分類)的參數之后,他們開始測試,讓這個網絡給隨機挑選的候選結構預測參數。該新的候選結構與訓練數據集上百萬結構當中的某個也許具備相似的屬性,也可能并不相同——有點算是異類。在前一種情況下,目標結構可認為屬于分布范圍內;若是后者,則屬于分布范圍外。深度神經網絡在對后者進行預測時經常會失敗,所以用這類數據測試 GHN-2 非常重要。
借助經過全面訓練的 GHN-2,該團隊預測了 500 個以前看不見的隨機目標網絡結構的參數。然后將這 500 個網絡(其參數設置為預測值)與使用隨機梯度下降訓練的相同網絡進行對比。新的超網絡通常可以抵御數千次 SGD 迭代,有時甚至做得更好,盡管有些結果更加復雜。
借助訓練好的 GHN-2 模型,該團隊預測了 500 個之前未知的隨機目標網絡結構的參數。然后將這 500 個(參數設置為預測值的)網絡與利用隨機梯度下降訓練的同一網絡進行對比。盡管部分結果有好有壞,但新的超網絡的表現往往可以跟數千次 SGD 迭代的結果不相上下,有時甚至是更好。
對于圖像數據集 CIFAR-10 ,GHN-2 用于分布范圍內的結構得到的平均準確率為 66.9%,而用經過近 2500 次 SGD 迭代訓練出來的網絡,其平均準確率為 69.2%。對于不在分布范圍內的結構,GHN-2 的表現則出人意料地好,準確率達到了約 60%。尤其是,對一種知名的特定深度神經網絡架構, ResNet-50, GHN2的準確率達到了 58.6% 這是相當可觀的。在本領域的頂級會議 NeurIPS 2021 上,Knyazev說:“鑒于 ResNet-50 比我們一般訓練的結構大了有大概 20 倍,可以說泛化到 ResNet-50 的效果出奇地好。”。
不過GHN-2 應用到 ImageNet 上卻表現不佳。ImageNet 這個數據集規模很大。平均而言,它的準確率只有 27.2% 左右。盡管如此,跟經過 5000SGD 迭代訓練的同一網絡相比,GHN-2的表現也要好一些,后者的平均準確度只有 25.6%。 (當然,如果你繼續用 SGD 迭代的話,你最終可以實現95% 的準確率,只是成本會非常高。)最關鍵的是,GHN-2 是在不到一秒的時間內對ImageNet 做出了參數預測,而如果用 SGD 在GPU上預測參數,要想達到同樣的表現,花費的平均時間要比 GHN-2 要多 10000 倍。
Veli?kovi?說:“結果絕對是令人印象深刻。基本上他們已經極大地降低了能源成本。”
一旦GHN-2 從結果樣本中為特定任務選出了最佳的神經網絡,但這個網絡表現還不夠好時,至少該模型已經過了部分訓練,而且可以還進一步優化了。與其對用隨機參數初始化的網絡進行 SGD,不如以 GHN-2 的預測作為起點。Knyazev 說:“基本上我們是在模仿預訓練”。
超越 GHN-2
盡管取得了這些成功,但Knyazev 認為剛開始的時候機器學習社區會抵制使用圖超網絡。他把這種阻力拿來跟 2012 年之前深度神經網絡的遭遇相比擬。當時,機器學習從業者更喜歡人工設計的算法,而不是神秘的深度網絡。但是,當用大量數據訓練出來的大型深度網絡開始超越傳統算法時,情況開始逆轉。Knyazev :“超網絡也可能會走上同樣的道路。”
與此同時,Knyazev 認為還有很多的改進機會。比方說,GHN-2 只能訓練來預測參數,去解決給定的任務,比如對 CIFAR-10 或 ImageNet 里面的圖像進行分類,但不能同時執行不同的任務。將來,他設想可以用更加多樣化的結果以及不同類型的任務(如圖像識別、語音識別與自然語言處理)來訓練圖超網絡。然后同時根據目標結構與手頭的特定任務來做出預測。
如果這些超網絡確實能成功的話,那么新的深度神經網絡的設計和開發,將不再是有錢和能夠訪問大數據的公司的專利了。任何人都可以參與其中。Knyazev 非常清楚這種“讓深度學習大眾化”的潛力,稱之為長期愿景。
然而,如果像GHN -2 這樣的超網絡真的成為優化神經網絡的標準方法, Veli?kovi?強調了一個潛在的大問題。他說,對于圖超網絡,“你有一個神經網絡——本質上是一個黑盒子——預測另一個神經網絡的參數。所以當它出錯時,你無法解釋[它]。”
不過,Veli?kovi? 強調,如果類似 GHN-2 這樣的超網絡真的成為優化神經網絡的標準方法的話,可能會有一個大問題。他說:“你會得到一個基本上是個黑箱的神經網絡,然后再用圖超網絡去預測另一個神經網絡的參數。如果它出錯,你沒法解釋錯在哪里。”
當然,神經網絡基本上也是這樣。Veli?kovi?說:“我不會說這是弱點,我把這叫做告警信號。”
不過Kipf看到的卻是一線希望。 “讓我最為興奮的是其他東西。” GHN-2 展示了圖神經網絡在復雜數據當中尋找模式的能力。
通常,深度神經網絡是在圖像、文本或音頻信號里面尋找模式,這類信息一般都比較結構化。但 GHN-2 卻是在完全隨機的神經網絡結構圖里面尋找模式。而圖是非常復雜的數據。
還有,GHN-2 可以泛化——這意味著它可以對未知、甚至不在分布范圍內的網絡結構的參數做出合理的預測。Kipf 說:“這項工作向我們表明,不同結構的很多模式其實多少是優點相似的,而且模型能學習如何將知識從一種結構轉移到另一種結構,這可能會啟發神經網絡新理論的誕生。”
如果是這樣的話,它可能會讓我們對這些黑箱有新的、更深入的理解。
審核編輯 黃昊宇
-
AI
+關注
關注
87文章
30750瀏覽量
268901 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用
AI干貨補給站 | 深度學習與機器視覺的融合探索

《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
FPGA做深度學習能走多遠?
NVIDIA推出全新深度學習框架fVDB
基于AI深度學習的缺陷檢測系統
深度學習與nlp的區別在哪
深度學習與卷積神經網絡的應用
深度學習的模型優化與調試方法
泰禾智能攜AI智選深度學習系列新品亮相臨沂花生展
FPGA在深度學習應用中或將取代GPU
【技術科普】主流的深度學習模型有哪些?AI開發工程師必備!

詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論