 知識圖譜——技術與行業應用
知識圖譜——技術與行業應用
從一開始的Google搜索,到現在的聊天機器人、大數據風控、證券投資、智能醫療、自適應教育、推薦系統,無一不跟知識圖譜相關。
隨著移動互聯網的發展,萬物互聯成為了可能,這種互聯所產生的數據也在爆發式地增長,而且這些數據恰好可以作為分析關系的有效原料。如果說以往的智能分析專注在每一個個體上,在移動互聯網時代則除了個體,這種個體之間的關系也必然成為我們需要深入分析的很重要一部分。 在一項任務中,只要有關系分析的需求,知識圖譜就“有可能”派的上用場。
知識圖譜的表示
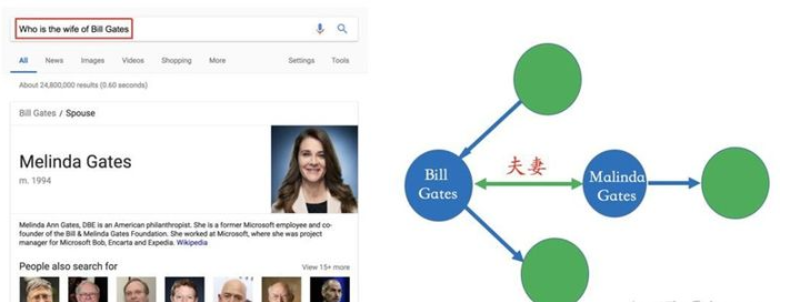
知識圖譜應用的前提是已經構建好了知識圖譜,也可以把它認為是一個知識庫。這也是為什么它可以用來回答一些搜索相關問題的原因,比如在Google搜索引擎里輸入“Who is the wife of Bill Gates?”,我們直接可以得到答案-“Melinda Gates”。這是因為我們在系統層面上已經創建好了一個包含“Bill Gates”和“Melinda Gates”的實體以及他倆之間關系的知識庫。所以,當我們執行搜索的時候,就可以通過關鍵詞提取("Bill Gates", "Melinda Gates", "wife")以及知識庫上的匹配可以直接獲得最終的答案。這種搜索方式跟傳統的搜索引擎是不一樣的,一個傳統的搜索引擎它返回的是網頁、而不是最終的答案,所以就多了一層用戶自己篩選并過濾信息的過程。
在現實世界中,實體和關系也會擁有各自的屬性,比如人可以有“姓名”和“年齡”。當一個知識圖譜擁有屬性時,我們可以用屬性圖(Property Graph)來表示。下面的圖表示一個簡單的屬性圖。李明和李飛是父子關系,并且李明擁有一個138開頭的電話號,這個電話號開通時間是2018年,其中2018年就可以作為關系的屬性。類似的,李明本人也帶有一些屬性值比如年齡為25歲、職位是總經理等。
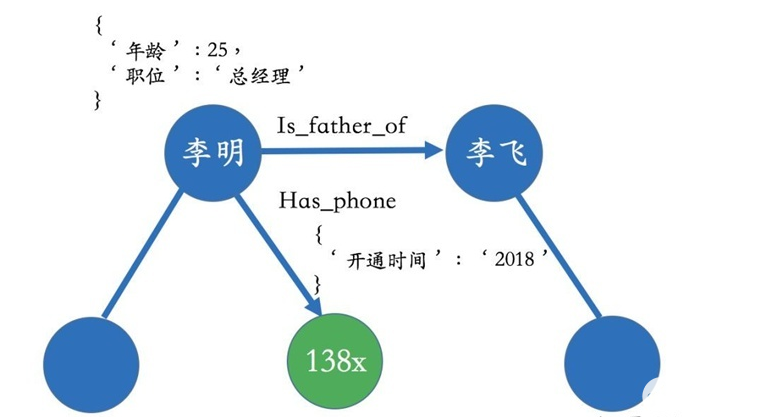
這種屬性圖的表達很貼近現實生活中的場景,也可以很好地描述業務中所包含的邏輯。除了屬性圖,知識圖譜也可以用RDF來表示,它是由很多的三元組(Triples)來組成。RDF在設計上的主要特點是易于發布和分享數據,但不支持實體或關系擁有屬性,如果非要加上屬性,則在設計上需要做一些修改。目前來看,RDF主要還是用于學術的場景,在工業界我們更多的還是采用圖數據庫(比如用來存儲屬性圖)的方式。感興趣的讀者可以參考RDF的相關文獻,在文本里不多做解釋。
知識抽取
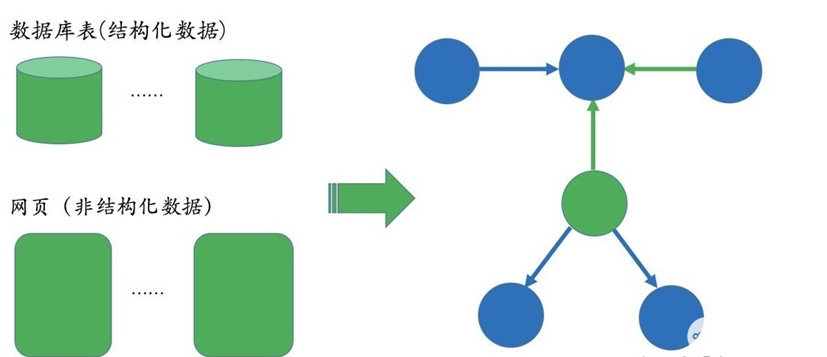
知識圖譜的構建是后續應用的基礎,而且構建的前提是需要把數據從不同的數據源中抽取出來。對于垂直領域的知識圖譜來說,它們的數據源主要來自兩種渠道:一種是業務本身的數據,這部分數據通常包含在公司內的數據庫表并以結構化的方式存儲;另一種是網絡上公開、抓取的數據,這些數據通常是以網頁的形式存在所以是非結構化的數據。
前者一般只需要簡單預處理即可以作為后續AI系統的輸入,但后者一般需要借助于自然語言處理等技術來提取出結構化信息。比如在上面的搜索例子里,Bill Gates和Malinda Gate的關系就可以從非結構化數據中提煉出來,比如維基百科等數據源。
信息抽取的難點在于處理非結構化數據。在下面的圖中,我們給出了一個實例。左邊是一段非結構化的英文文本,右邊是從這些文本中抽取出來的實體和關系。在構建類似的圖譜過程當中,主要涉及以下幾個方面的自然語言處理技術:
a. 實體命名識別(Name Entity Recognition)
b. 關系抽取(Relation Extraction)
c. 實體統一(Entity Resolution)
d. 指代消解(Coreference Resolution)
知識圖譜的存儲
知識圖譜主要有兩種存儲方式:一種是基于RDF的存儲;另一種是基于圖數據庫的存儲。它們之間的區別如下圖所示。RDF一個重要的設計原則是數據的易發布以及共享,圖數據庫則把重點放在了高效的圖查詢和搜索上。其次,RDF以三元組的方式來存儲數據而且不包含屬性信息,但圖數據庫一般以屬性圖為基本的表示形式,所以實體和關系可以包含屬性,這就意味著更容易表達現實的業務場景。

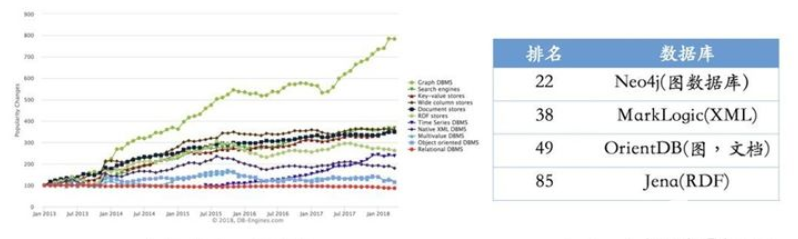
根據最新的統計(2018年上半年),圖數據庫仍然是增長最快的存儲系統。相反,關系型數據庫的增長基本保持在一個穩定的水平。同時,我們也列出了常用的圖數據庫系統以及他們最新使用情況的排名。 其中Neo4j系統目前仍是使用率最高的圖數據庫,它擁有活躍的社區,而且系統本身的查詢效率高,但唯一的不足就是不支持準分布式。相反,OrientDB和JanusGraph(原Titan)支持分布式,但這些系統相對較新,社區不如Neo4j活躍,這也就意味著使用過程當中不可避免地會遇到一些刺手的問題。如果選擇使用RDF的存儲系統,Jena或許一個比較不錯的選擇。
知識圖譜在其他行業中的應用
除了金融領域,知識圖譜的應用可以涉及到很多其他的行業,包括醫療、教育、證券投資、推薦等等。其實,只要有關系存在,則有知識圖譜可發揮價值的地方。 在這里簡單舉幾個垂直行業中的應用。
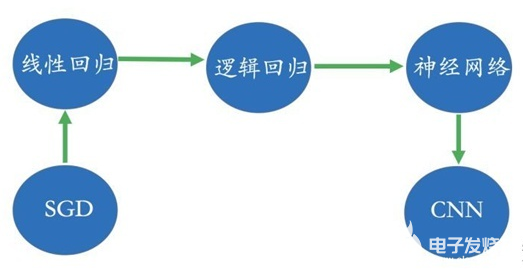
比如對于教育行業,我們經常談論個性化教育、因材施教的理念。其核心在于理解學生當前的知識體系,而且這種知識體系依賴于我們所獲取到的數據比如交互數據、評測數據、互動數據等等。為了分析學習路徑以及知識結構,我們則需要針對于一個領域的概念知識圖譜,簡單來講就是概念拓撲結構。在下面的圖中,我們給出了一個非常簡單的概念圖譜:比如為了學習邏輯回歸則需要先理解線性回歸;為了學習CNN,得對神經網絡有所理解等等。所有對學生的評測、互動分析都離不開概念圖譜這個底層的數據。
在證券領域,我們經常會關心比如“一個事件發生了,對哪些公司產生什么樣的影響?” 比如有一個負面消息是關于公司1的高管,而且我們知道公司1和公司2有種很密切的合作關系,公司2有個主營產品是由公司3提供的原料基礎上做出來的。
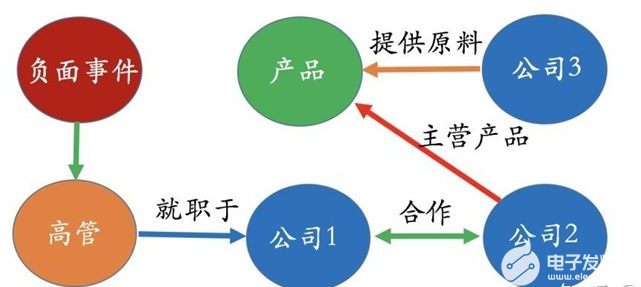
其實有了這樣的一個知識圖譜,我們很容易回答哪些公司有可能會被這次的負面事件所影響。當然,僅僅是“有可能”,具體會不會有強相關性必須由數據來驗證。所以在這里,知識圖譜的好處就是把我們所需要關注的范圍很快給我們圈定。接下來的問題會更復雜一些,比如既然我們知道公司3有可能被這次事件所影響,那具體影響程度有多大? 對于這個問題,光靠知識圖譜是很難回答的,必須要有一個影響模型、以及需要一些歷史數據才能在知識圖譜中做進一步推理以及計算。
實踐上的幾點建議
首先,知識圖譜是一個比較新的工具,它的主要作用還是在于分析關系,尤其是深度的關系。所以在業務上,首先要確保它的必要性,其實很多問題可以用非知識圖譜的方式來解決。
知識圖譜領域一個最重要的話題是知識的推理。 而且知識的推理是走向強人工智能的必經之路。但很遺憾的,目前很多語義網絡的角度討論的推理技術(比如基于深度學習,概率統計)很難在實際的垂直應用中落地。其實目前最有效的方式還是基于一些規則的方法論,除非我們有非常龐大的數據集。
最后,還是要強調一點,知識圖譜工程本身還是業務為重心,以數據為中心。不要低估業務和數據的重要性。
總之知識圖譜是一個既充滿挑戰而且非常有趣的領域。只要有正確的應用場景,對于知識圖譜所能發揮的價值還是可以期待的。我相信在未來不到2,3年時間里,知識圖譜技術會普及到各個領域當中。
審核編輯 黃昊宇
-
數據庫
+關注
關注
7文章
3868瀏覽量
65025 -
知識圖譜
+關注
關注
2文章
132瀏覽量
7792
發布評論請先 登錄
相關推薦
淵亭KGAG升級引入“高級策略推理”
微軟發布《GraphRAG實踐應用白皮書》助力開發者
利智方:驅動企業知識管理與AI創新加速的平臺
傳音旗下人工智能項目榮獲2024年“上海產學研合作優秀項目獎”一等獎

傳音旗下小語種AI技術榮獲2024年“上海產學研合作優秀項目獎”一等獎

58大新質生產力產業鏈圖譜

三星自主研發知識圖譜技術,強化Galaxy AI用戶體驗與數據安全
易智瑞榮獲“信息技術應用創新工作委員會技術活動單位”

革新未來智能版圖,神州數碼榮登IDC生成式AI圖譜

萬里紅入選《嘶吼2024網絡安全產業圖譜》8個細分領域

三星電子成功收購英國初創公司,致力開發AI核心技術
三星電子將收購英國知識圖譜技術初創企業
知識圖譜與大模型之間的關系
維智科技入選《2024中國數據智能產業圖譜1.0》






 工商網監
工商網監
評論