

摘 要
準確描述和檢測 2D 和 3D 關(guān)鍵點對于建立跨圖像和點云的對應(yīng)關(guān)系至關(guān)重要。盡管已經(jīng)提出了大量基于學習的 2D 或 3D 局部特征描述符和檢測器,但目前的研究對直接地匹配像素和點的共享描述符,以及聯(lián)合關(guān)鍵點檢測器的推導仍未得到充分探索。
這項工作主要在 2D 圖像和 3D 點云之間建立細粒度的對應(yīng)關(guān)系。
為了直接匹配像素和點,提出了一個雙全卷積框架,將 2D 和 3D 輸入映射到共享的潛在表示空間中,進而同時描述并檢測關(guān)鍵點。此外,設(shè)計了一種超寬接收機制和一種新穎的損失函數(shù),以減輕像素和點的局部區(qū)域間的內(nèi)在信息變化。廣泛的實驗結(jié)果表明,我們的框架在圖像和點云之間的細粒度匹配方面,表現(xiàn)出具有競爭力的性能,并在室內(nèi)視覺定位任務(wù)中取得了SOTA的結(jié)果。 
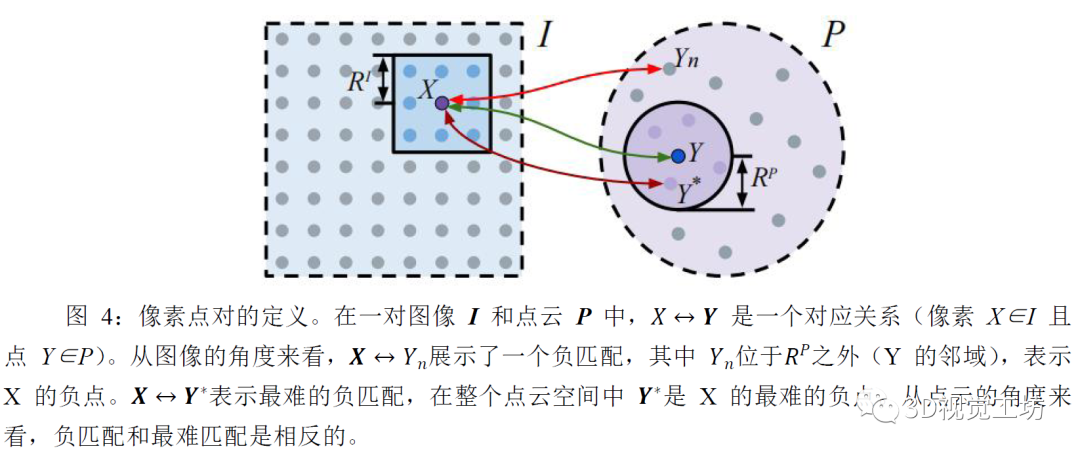
圖 1:P2-Net 獲得的 2D-3D 匹配的示例。所提出的方法,可以通過學習的聯(lián)合特征描述和檢測,直接建立跨圖像和點云的對應(yīng)關(guān)系。
一、引言
在圖像和點云之間,分別建立準確的像素級和點級的匹配是一項基本的計算機視覺任務(wù),這對于多種應(yīng)用至關(guān)重要,例如SLAM [34]、SFM [44] 、位姿估計 [35]、3D 重建 [25] 和視覺定位 [42]。 大多數(shù)方法的典型流程是:
首先,在給定圖像序列 [24, 41] 的情況下恢復(fù) 3D 結(jié)構(gòu);
然后,根據(jù) 2D 到 3D 重投影特征,執(zhí)行像素和點之間的匹配。
這些特征將是同質(zhì)的,因為重建的 3D 模型中的點,從圖像序列的相應(yīng)像素來繼承描述符。然而,這個兩步過程需要精確的 3D 重建,這并不總是可行的,例如,在具有挑戰(zhàn)性的光照場景或視點變化很大的情況下。更關(guān)鍵的是,這種方法將 RGB 圖像視為首要考量,并忽略了能夠直接捕獲 3D 點云的傳感器的等效性,例如激光雷達、成像雷達和深度相機。
這些因素促使我們考慮像素和點匹配的統(tǒng)一方法,其中可以提出一個懸而未決的問題:如何直接建立 2D 圖像中的像素和 3D 點云中的點之間的對應(yīng)關(guān)系,反之亦然。這本質(zhì)上是具有挑戰(zhàn)性的,因為 2D 圖像捕捉場景外觀,而 3D 點云編碼結(jié)構(gòu)。 為此,我們制定了直接的 2D 像素和 3D 點匹配的新任務(wù)(參見圖 1),無需任何輔助的步驟(例如:3D重建)。
這項任務(wù)對于現(xiàn)有的傳統(tǒng)和基于學習的方法來說,無疑是具有挑戰(zhàn)性的,它們無法彌合 2D 和 3D 特征表示之間的差距,因為單獨提取的 2D 和 3D 局部特征是不同的,并且不共享共同的embedding。一些最近的研究工作 [20, 39],嘗試通過將 2D 和 3D 輸入映射到共享的潛在空間來關(guān)聯(lián)來自不同域的描述符。然而,他們構(gòu)建了patch-wise描述符,僅具有粗粒度匹配結(jié)果。 即使可以成功獲得細粒度且準確的描述符,直接的像素和點間的對應(yīng)關(guān)系仍然很難建立。
首先,根據(jù)不同的策略來提取2D和3D關(guān)鍵點,這導致 2D 中具有良好匹配的因素(例如:平面、視覺上不同的區(qū)域,如海報),但不一定對應(yīng)于3D中強匹配的因素(例如:房間中照明不佳的角落)。
此外,由于點云的稀疏性,一個3D點的局部特征可以映射到許多像素特征,從空間上接近或來自該點的像素中提取得到,從而這也增加了匹配的模糊度。
其次,由于 2D 和 3D 數(shù)據(jù)屬性之間的巨大差異,以及不靈活的優(yōu)化方式,用于 2D 或 3D 局部特征描述的現(xiàn)有描述符損失公式 [18, 31, 2] 不能保證在新環(huán)境下的收斂。此外,目前檢測器的設(shè)計只專注于懲罰來自安全區(qū)域的混雜描述符,在實際中這會導致次優(yōu)匹配結(jié)果。
為了應(yīng)對所有的這些挑戰(zhàn),我們提出了一個雙全卷積框架,稱為像素和點網(wǎng)絡(luò) (P2-Net),它能夠同時實現(xiàn)2D和3D視圖之間的特征描述和檢測。此外,在提取描述符時應(yīng)用了超寬接收機制(ultra-wide reception),用于解決2D像素和3D點的局部區(qū)域間的內(nèi)在信息變化。為了優(yōu)化網(wǎng)絡(luò),我們設(shè)計了 P2-Loss,它由兩個部分組成:
圓形引導的描述符損失(circle-guided descriptor loss)與完整的采樣策略相結(jié)合,允許通過在self-paced中優(yōu)化正匹配和負匹配,從而穩(wěn)健地學習獨特的描述符;
Batch-hard檢測器損失(batchhard detector loss,),它通過鼓勵正匹配和全局最難匹配之間的差異,從而額外尋求檢測的可重復(fù)性。
總的來說,我們的貢獻如下: 1. 我們提出了一個具有超寬接收機制的聯(lián)合學習框架,用于同時描述并檢測 2D和3D 局部特征,以實現(xiàn)直接的2D 像素和3D 點的匹配。 2. 我們設(shè)計了一種新穎的損失函數(shù),由circle-guided的描述符損失和batch-hard的檢測器損失組成,以穩(wěn)健地學習獨特的描述符,同時準確地引導像素和點的檢測。 3. 我們進行了廣泛的實驗和消融研究,證明了所提出框架的實用性和新?lián)p失的泛化能力,并說明了我們選擇的道理。 據(jù)我們所知,這是第一個為直接像素和點匹配,處理 2D和3D 局部特征描述和檢測的聯(lián)合學習框架。
二、相關(guān)工作
2.1 2D局部特征的描述和檢測
以前2D 域中基于學習的方法,只是用可學習的替代方法替換了描述符 [50、51、30、19、38] 或檢測器 [43、59、4]。最近,二維局部特征的聯(lián)合描述和檢測方法,引起了越來越多的關(guān)注。LIFT [57] 是第一個完全基于學習的架構(gòu),通過使用神經(jīng)網(wǎng)絡(luò)重建 SIFT 的主要步驟來實現(xiàn)這一目標。受 LIFT 的啟發(fā),SuperPoint [16] 還將關(guān)鍵點檢測作為監(jiān)督任務(wù)處理,在描述之前使用標記的合成數(shù)據(jù),然后擴展到無監(jiān)督版本 [13]。不同的是,DELF [36] 和 LF-Net [37] 分別利用注意力機制和不對稱梯度反向傳播方案,來實現(xiàn)無監(jiān)督學習。
與之前單獨學習描述符和檢測器的研究不同,D2-Net [18] 設(shè)計了一個基于非極大值抑制的聯(lián)合優(yōu)化框架。為了進一步鼓勵關(guān)鍵點的可靠和可重復(fù),R2D2 [40] 提出了一種基于可微平均精度的list-wise排序損失。同時,基于相同的目的,ASLFeat [31] 中引入了可變形卷積。
2.2 3D局部特征的描述和檢測
3D 領(lǐng)域的大多數(shù)先前工作,集中在描述符的學習上。早期的嘗試 [46, 60] 不是直接處理 3D 數(shù)據(jù),而是從多視圖圖像中提取特征表示,從而進行3D 關(guān)鍵點的描述。相比之下,3DMatch [58] 和 PerfectMatch [23] 通過將 3D-Patch分別轉(zhuǎn)換為截斷距離函數(shù)值和平滑密度值表示的體素網(wǎng)格,從而來構(gòu)造描述符。Ppf-Net 及其擴展 [14, 15] 直接對無序點集進行操作,以描述 3D 關(guān)鍵點。然而,這種方法需要點云Patch作為輸入,導致效率問題。這種約束嚴重限制了它的實用性,特別是在需要細粒度應(yīng)用時。
除此之外,FCGF [12] 中提出了具有全卷積設(shè)置的密集特征描述。對于檢測器學習,USIP [27] 利用概率倒角損失,以無監(jiān)督的方式檢測和定位關(guān)鍵點。受此啟發(fā),3DFeat-Net [56] 首次嘗試在點塊上進行 3D 關(guān)鍵點聯(lián)合描述和檢測,然后由 D3Feat [2] 改進以處理全幀點集。
2.3 2D-3D 局部特征的描述
與在單個 2D或3D 域中,經(jīng)過充分研究的學習描述符領(lǐng)域不同,很少有人關(guān)注 2D-3D 特征描述的學習。[29] 通過將手工制作的 3D描述符直接綁定到學習的圖像描述符,為對象級的檢索任務(wù)生成 2D-3D 描述符。類似地,3DTNet [54] 為 3D-Patch學習獨特的 3D 描述符,并從 2D-Patch中提取輔助 2D 特征。
最近,2D3DMatch-Net [20] 和 LCD [39] 都提出學習的描述符,以便在 2D和3D局部Patch之間直接匹配,以解決檢索問題。但是,所有這些方法都是基于Patch的,不適用于需要高分辨率輸出的實際用途。相比之下,我們的目標是在單個前向傳遞中,提取每個3D點的描述符并檢測關(guān)鍵點的位置,以實現(xiàn)有效應(yīng)用。 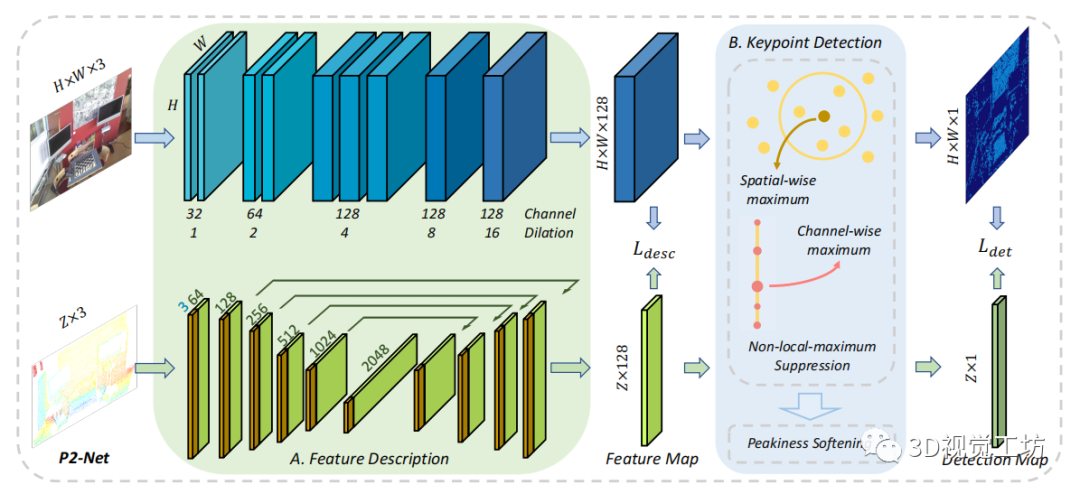
圖 2:提出的 P2-Net 框架的概述。
我們的架構(gòu)是一個雙分支全卷積網(wǎng)絡(luò),用于同時進行 2D和3D 特征的描述 (A) 以及關(guān)鍵點的檢測 (B)。
該網(wǎng)絡(luò)與描述符損失 聯(lián)合優(yōu)化,以增強相應(yīng)特征表示的相似性;同時,檢測器損失 鼓勵更高的判別對應(yīng)的檢測分數(shù)。
三、像素和點匹配
在本節(jié)中,我們首先詳細介紹了所提出的P2-Net的架構(gòu),包括聯(lián)合特征描述和關(guān)鍵點檢測[18]。接下來,我們展示我們設(shè)計的 P2-Loss,它由循環(huán)引導的描述符損失和批量硬檢測器損失組成。最后,提供了訓練和測試階段的實驗細節(jié)。
3.1 P2-Net 架構(gòu)

在被 L2 歸一化后,這些描述符可以很容易地在圖像和點云之間進行比較,使用余弦相似度作為度量來建立對應(yīng)關(guān)系。在訓練期間,描述符將被優(yōu)化,以便場景中的像素和點對應(yīng)產(chǎn)生相似的描述符,即使圖像或點云包含強烈的變化或噪聲。為清楚起見,我們在下文中仍然使用 d 來表示其規(guī)范化形式。
如圖 2.A 所示,利用兩個全卷積網(wǎng)絡(luò)分別對圖像和點云進行特征描述。然而,由于 2D和3D 局部區(qū)域之間信息密度的內(nèi)在變化,通過描述符將像素與點正確關(guān)聯(lián)并非易事(圖 3.A)。具體來說,由于點云的稀疏性,一個3D點提取的局部信息通常大于一個2D像素。
為了解決不對稱嵌入的關(guān)聯(lián)問題并更好地捕獲局部幾何信息,我們設(shè)計了基于超寬接收機制(ultra-wide reception mechanism)的 2D 提取器,如圖 3.B 所示。為了計算效率,這種機制是通過9個 3×3 卷積層實現(xiàn)的,膨脹值從 1 到 16 逐漸加倍。最后,生成 H×W×128 特征圖,然后生成其對應(yīng)的 H×W×1 檢測圖可以計算。同樣,我們修改 KPconv [49] 以輸出 128D 的描述符,以及輸入的點云中每個點的分數(shù)。

在訓練期間,使用峰值[40]將上述過程軟化為可訓練且密度不變:
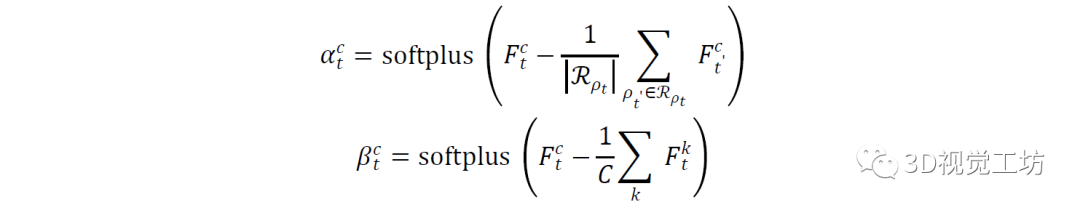
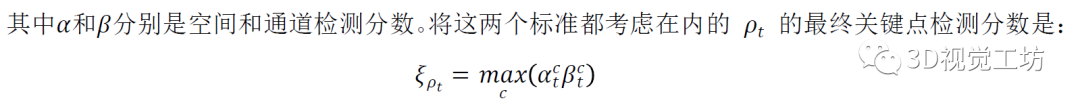
在測試過程中,將選擇得分最高的像素或點作為匹配的關(guān)鍵點。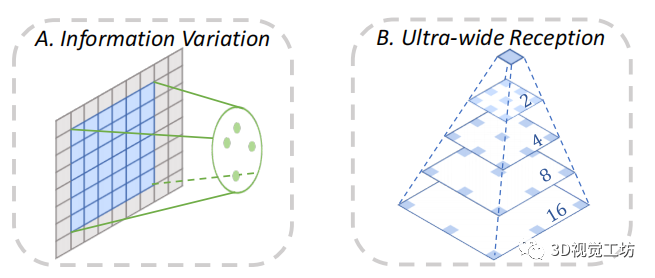
圖 3:為了減輕 2D和3D 局部區(qū)域之間的內(nèi)在信息變化 (A),在特征描述的 2D分支中應(yīng)用了具有逐漸加倍膨脹值的超寬接收機制 (B),最高可達 16。
3.2 P2-loss 公式
為了使所提出的網(wǎng)絡(luò),在單個前向傳遞中描述和檢測 2D和3D 關(guān)鍵點,我們設(shè)計了一種新的損失,它聯(lián)合優(yōu)化了像素和點的描述和檢測目標,稱為 P2-Loss:

圓形引導(Circle-guided)的描述符損失。
為了學習獨特的描述符,各種優(yōu)化策略,如hard三元組和hard對比損失 [18,31,2] 已廣泛用于 2D 或 3D 領(lǐng)域。然而,這些公式只關(guān)注hard負匹配,并且通過實驗我們發(fā)現(xiàn):它們在我們的 2D-3D 上下文中沒有收斂。受使用權(quán)重因子和圓形決策邊界的 Circle Loss [47] 的啟發(fā),我們設(shè)計了一個具有完整采樣策略的圓形引導的描述符損失,而不是僅考慮hard負匹配,這允許self-paced優(yōu)化并避免收斂模糊。
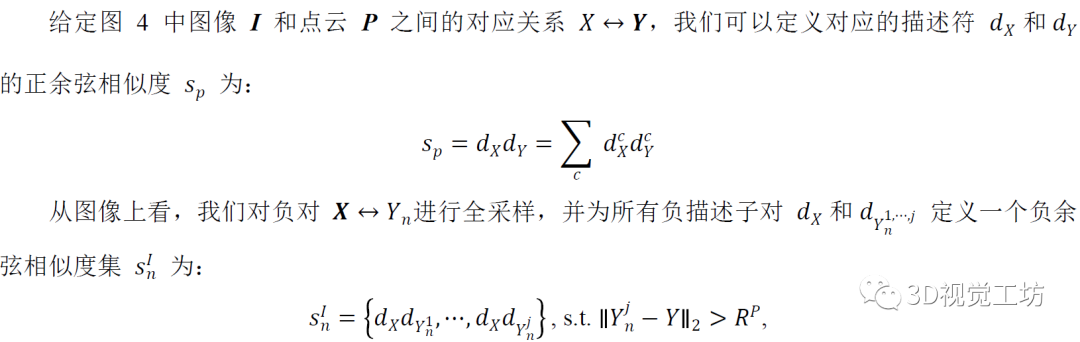

Batch-hard檢測器損失。
在檢測的情況時,關(guān)鍵點應(yīng)該足夠獨特,且可以重復(fù)檢測。然而,實現(xiàn)這一目標面臨兩個實際挑戰(zhàn): 1)特征描述中的超寬接收機制,可能會使空間上接近的像素具有非常相似的描述符; 2)我們的描述符損失中的全采樣策略,僅對安全區(qū)域之外的負匹配有效。它們都會降低關(guān)鍵點的獨特性,從而導致錯誤的分配。 為此,我們設(shè)計了一個Batch-hard檢測器損失,在整個圖像或點云空間而不是特定區(qū)域上,應(yīng)用hardest-in-batch策略 [33],以鼓勵最佳匹配的獨特性和可重復(fù)性。

3.3 實驗細節(jié)
訓練。
我們使用 PyTorch 實現(xiàn)我們的方法。在訓練期間,我們使用 1 的batch size,具有超過128個像素點對應(yīng)關(guān)系的圖像點云對。為了計算效率,個對應(yīng)從每對隨機采樣,以在每一步中進行優(yōu)化。我們設(shè)置平衡因子λ=1,邊距m=0.2,比例因子ζ=10,圖像鄰域像素,點云鄰域。最后,我們使用 ADAM 求解器訓練網(wǎng)絡(luò),并使用 10-4 的初始學習率和指數(shù)衰減。
測試。
在測試過程中,我們利用方程式2中展示的硬選擇策略。而不是軟選擇來掩蓋空間上太近的檢測。此外,類似 SIFT 的邊緣消除,應(yīng)用于圖像的關(guān)鍵點檢測。為了評估,我們選擇與方程式 4中計算的檢測分數(shù)相對應(yīng)的前 K 個關(guān)鍵點。
四、實驗
我們首先證明了 P2-Net 在直接的2D像素和3D點匹配任務(wù)上的有效性,然后在下游任務(wù)(即視覺定位)上對其進行評估。此外,我們通過分別與圖像匹配和點云配準任務(wù)中的最新方法進行比較,檢查了我們設(shè)計的 P2-Loss 在單個 2D 和 3D 域中的泛化能力。最后,我們研究了損失選擇的影響。
4.1 圖像和點云匹配
為了實現(xiàn)細粒度的圖像和點云匹配,需要一個帶有2D像素和3D點對應(yīng)標注的圖像和點云對數(shù)據(jù)集。據(jù)我們所知,沒有具有此類對應(yīng)標簽的公開可用數(shù)據(jù)集。為了解決這個問題,我們在包含 RGB-D 掃描的現(xiàn)有 3D 數(shù)據(jù)集上標注了 2D-3D 對應(yīng)標簽。
具體來說,我們數(shù)據(jù)集的 2D-3D 對應(yīng)關(guān)系是在 7Scenes 數(shù)據(jù)集 [21, 45] 上生成的,該數(shù)據(jù)集由 7 個室內(nèi)場景和 46 個 RGB-D 序列組成,包括各種相機運動狀態(tài),以及不同條件(例如運動模糊)的感知混疊和室內(nèi)沒有紋理特征的情況。眾所周知,這些條件對于圖像和點云匹配都具有挑戰(zhàn)性。
4.1.1 特征匹配評估
我們對 7Scenes 數(shù)據(jù)集采用與 [21, 45] 中相同的數(shù)據(jù)拆分策略,來準備訓練集和測試集。具體來說,選擇了 18 個序列進行測試,其中包含部分重疊的圖像和點云對應(yīng),以及 ground-truth 變換矩陣。
評估指標。
為了全面評估我們提出的 P2-Net 和 P2-Loss 在細粒度圖像和點云匹配上的性能,在以前的圖像或點云匹配任務(wù)中,五個指標廣泛使用 [31、18、3、27、58、17、2]:
Feature Matching Recall,內(nèi)點比例高于閾值(τ1 = 0.5)的圖像和點云對的百分比;
Inlier Ratio,正確的像素點匹配,在所有可能匹配中的百分比。如果像素和點對之間的距離在其ground-truth變換下低于閾值(τ2 = 4.5cm),則接受為正確匹配;
Keypoint Repeatability,可重復(fù)的關(guān)鍵點占所有檢測到的關(guān)鍵點的百分比,其中圖像中的關(guān)鍵點在真實變換下,如果與點云中最近關(guān)鍵點的距離小于閾值(τ3 = 2cm),則認為圖像中的關(guān)鍵點是可重復(fù)的;
Recall,正確匹配占所有真實匹配的百分比;
Registration Recall,圖像和點云對的估計轉(zhuǎn)換誤差小于閾值(RMSE < 5cm)的百分比。
描述符和網(wǎng)絡(luò)的比較。為了研究描述符的影響,我們報告了
傳統(tǒng) SIFT 和 SIFT3D 描述符的結(jié)果;
使用 D2-Net 損失 (P2[D2 Triplet]) [18] 訓練的 P2-Net ;
使用 D3Feat 損失 (P2[D3 Contrastive]) [2] 訓練的 P2-Net。
此外,為了證明 P2-Net 中 2D 分支的優(yōu)越性,我們將其替換為 4) R2D2 網(wǎng)絡(luò) (P2[R2D2]) [40] 和 5) ASL 網(wǎng)絡(luò) (P2[ASL]) [31]。 其他的訓練或測試設(shè)置使用,與我們提出的損失 (P2[Full]) 訓練的架構(gòu)相同,以進行公平比較。其中,P2[R2D2] 和 P2[Full] 都采用 L2-Net 風格的 2D 特征提取器[50],但后者通過我們的超寬接收機制進行了改進。
如表1中所示。傳統(tǒng)的描述符無法匹配,因為手工設(shè)計的 2D 和 3D 描述符是異構(gòu)的。P2[D2 Triplet] 和 P2[D3 Contrastive] 都不能保證像素和點的匹配任務(wù)收斂。
然而,當采用我們的損失時,由于 R2D2 和 ASL 的固有特征提取器限制,P2[R2D2] 和 P2[ASL] 模型不僅收斂,而且在大多數(shù)場景中表現(xiàn)出更好的性能,除了具有挑戰(zhàn)性的樓梯場景。此外,P2[R2D2]和P2[Full]的比較也證明了超寬接收機制的有效性。總體而言,我們的 P2[Full] 在所有評估指標上始終表現(xiàn)更好,在所有場景中都遠遠優(yōu)于所有的競爭方法。
檢測器的比較。
為了證明聯(lián)合學習檢測器和描述符的重要性,我們報告了使用我們的圓形引導描述符損失,以及:
沒有檢測器但在推理過程中隨機采樣關(guān)鍵點(P2[w/o Det]),訓練的 P2-Net 的結(jié)果;
沒有檢測器但具有傳統(tǒng)的 SIFT 和 SIFT3D 關(guān)鍵點 (P2[Mixed]);
用原始的D2Net檢測器(P2[D2 Det])[18];
使用 D3Feat 檢測器 (P2[D3 Det]) [2];
我們的 batch-hard檢測器損失,但使用隨機采樣的關(guān)鍵點進行測試(P2[Rand]),用來表明我們提出的檢測器的優(yōu)越性。
從表1可以看出,當檢測器沒有與整個模型聯(lián)合訓練時,P2[w/o Det] 在所有評估指標和場景上表現(xiàn)最差。在引入傳統(tǒng)檢測器后,P2[Mixed]對此類指標略有改進。然而,當使用所提出的檢測器時,P2[Rand] 比 P2[Mixed] 取得了更好的結(jié)果。
這些結(jié)果最終表明,檢測器的聯(lián)合學習也有利于加強描述符學習本身。在 P2[D2 Det] 和 P2[D3 Det] 中也可以觀察到類似的改進。顯然,如果我們的損失完全使用,我們的 P2[Full] 能夠在所有評估指標方面保持有競爭力的匹配質(zhì)量。值得一提的是,特別是在樓梯的場景中,P2[Full] 是唯一在所有指標上都達到出色匹配性能的方法。
相比之下,由于在這種具有挑戰(zhàn)性的場景中高度重復(fù)的紋理,大多數(shù)其他競爭方法都失敗了。這表明即使在具有挑戰(zhàn)性的條件下,關(guān)鍵點也能被穩(wěn)健地檢測并匹配,這是可靠關(guān)鍵點擁有的理想屬性。
定性結(jié)果。
圖 1 顯示了來自不同場景中,圖像和點云的前1000個檢測到的關(guān)鍵點。圖像中檢測到的像素(左,綠色)和點云中檢測到的點(右,紅色)顯示在國際象棋和樓梯上。為清楚起見,我們隨機突出顯示一些好的匹配項(藍色、橙色),以便更好地展示對應(yīng)關(guān)系。
可以看出,通過我們提出的描述符,這些檢測到的2D像素和3D點直接且穩(wěn)健地關(guān)聯(lián),這對于現(xiàn)實世界的下游應(yīng)用至關(guān)重要(例如,跨域信息檢索和定位任務(wù))。此外,由于我們的網(wǎng)絡(luò)與檢測器聯(lián)合訓練,因此關(guān)聯(lián)能夠繞過無法準確匹配的區(qū)域,例如重復(fù)模式。
更具體地說,我們的檢測器主要關(guān)注具有幾何意義的區(qū)域(例如:物體的角和邊緣),而不是無特征區(qū)域(例如:地板、屏幕和桌面),因此在環(huán)境變化中表現(xiàn)出更好的一致性。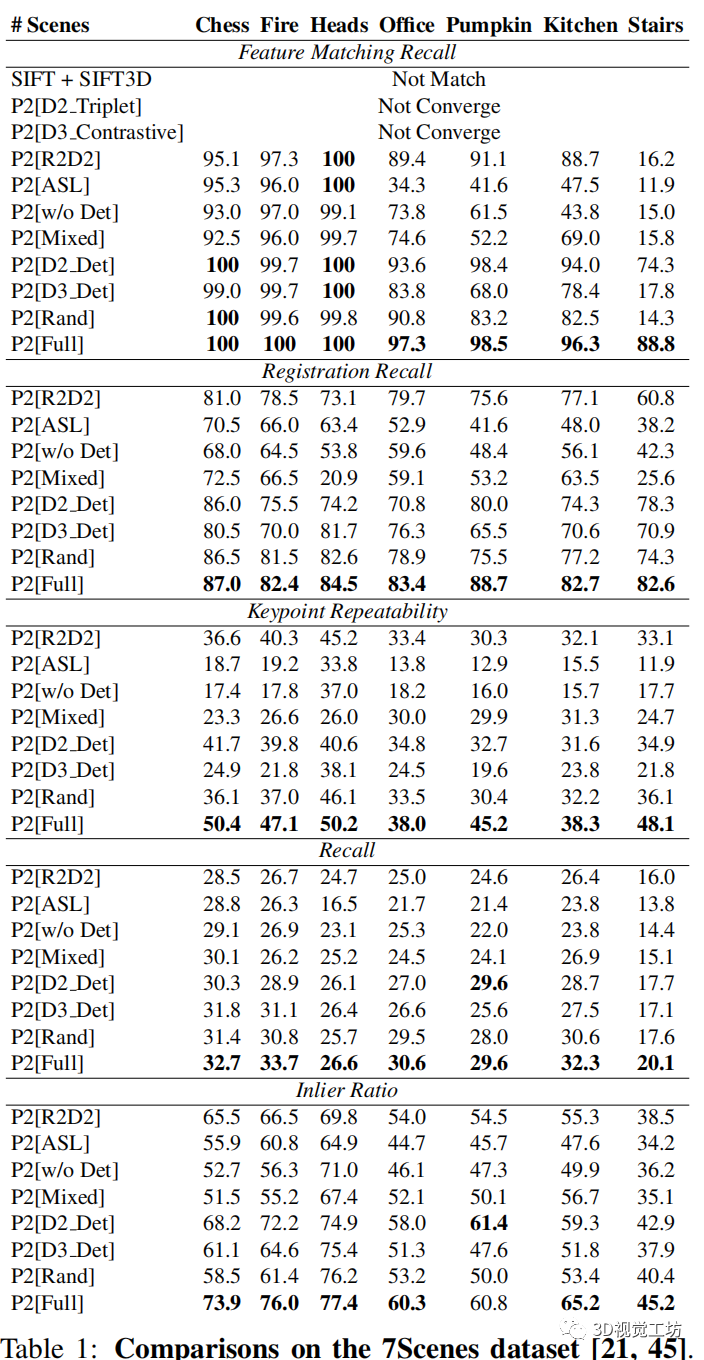
表 1:7Scenes 數(shù)據(jù)集上的比較 [21, 45]。評估指標在給定閾值時報告。
4.1.2 在視覺定位上的應(yīng)用
為了進一步說明 P2-Net 的實際用途,我們在 7-Scenes 數(shù)據(jù)集上執(zhí)行視覺定位的下游任務(wù) [52, 28]。這里的關(guān)鍵定位挑戰(zhàn)在于,在顯著運動模糊、感知混疊和無紋理模式下,像素和點之間的細粒度匹配。我們針對基于 [48、55] 和場景坐標回歸pipeline的 2D 特征匹配 [6、32、5、7、55、28] 來評估我們的方法。請注意,現(xiàn)有baseline只能定位 3D 地圖中的查詢圖像,而我們的方法不受此限制,也可以通過反向查詢從 3D 定位到 2D。進行以下實驗,以顯示我們方法的獨特性:
在給定的 3D 地圖(P2[3D Map])中恢復(fù)查詢圖像的相機位姿;
在給定的 2D 中恢復(fù)查詢點云的位姿地圖(P2[2D 地圖])。
評估標準。
我們遵循 [42, 48, 55] 中使用的相同評估pipeline。該pipeline通常將輸入作為查詢圖像和3D點云子圖(例如:由 NetVLAD [1] 檢索),并利用傳統(tǒng)的手工制作的或預(yù)訓練的深度描述符來建立像素和點之間的匹配。然后將此類匹配作為帶有RANSAC [5] 的 PnP 的輸入,以恢復(fù)最終的相機位姿。
在這里,我們采用 [55] 中的相同設(shè)置,來構(gòu)建覆蓋范圍高達 49.6 厘米的 2D或3D 子圖。由上可知,我們的目標是評估匹配質(zhì)量對視覺定位的影響,因此我們假設(shè)子圖已被檢索,并更多地關(guān)注比較關(guān)鍵點的獨特性。在測試期間,我們選擇前10000個檢測到的像素和點,用來生成用于相機姿態(tài)估計的匹配。
結(jié)果。
我們按照 [48, 55] 在 110 個測試幀上評估模型。定位精度是根據(jù)落在 (5cm, 5°) 閾值內(nèi)的預(yù)測姿態(tài)的百分比來衡量的。如圖 5 所示,在將 2D 特征與 3D 地圖匹配時,我們的 P2[3D 地圖] (68.8%) 分別比 InLoc [48] 和 SAMatch [55] 高 2.6% 和 5%,其中傳統(tǒng)的特征匹配方法用于定位查詢圖像。
此外,我們的 P2[3D Map] 比大多數(shù)基于場景協(xié)調(diào)的方法(如 RF1 [6]、RF2[32]、DSAC [5] 和 SANet [55])提供了更好的結(jié)果。DSAC* [8] 和 HSC-Net [28] 仍然表現(xiàn)出比我們更好的性能,因為它們專門針對單個場景進行了訓練,并使用單個模型進行測試。相比之下,我們直接使用從 P2[Full] 訓練的單一模型。
在將 3D 查詢定位到 2D 地圖中的獨特應(yīng)用場景中,我們的 P2[2D Map] 也顯示出可觀的性能,達到 65.1%。然而,其他baseline無法實現(xiàn)這種反向匹配。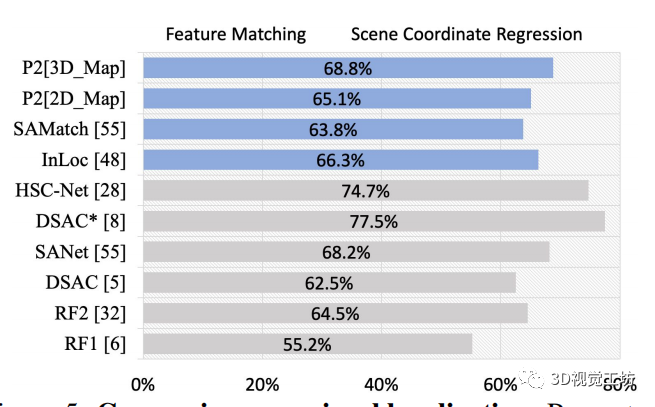
圖 5:視覺定位的比較。估計的相機位姿的百分比落在(5cm,5°) 范圍內(nèi)
4.2. 單域下匹配
在這個實驗中,我們展示了提出的新的 P2-Loss ,如何極大地提高最先進的 2D和3D 匹配網(wǎng)絡(luò)的性能。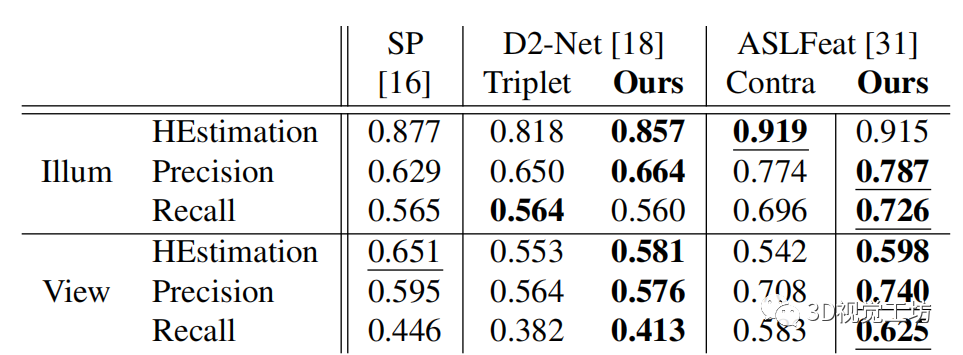
表 2:HPatches 的比較。HEstimation、Precision 和 Recall
以 3 個像素的閾值計算。方法中最好的分數(shù)用下劃線表示,損失之間較好的用粗體表示。
4.2.1 圖像匹配
在圖像匹配實驗中,我們使用 HPatches 數(shù)據(jù)集 [3],該數(shù)據(jù)集已被廣泛用于評估圖像匹配的質(zhì)量 [33、16、40、30、51、38、53]。在 D2-Net [18] 和 ASLFeat [31] 之后,我們排除了 8 個高分辨率序列,分別留下 52 個和 56 個具有照明或視點變化的序列。
為了精確再現(xiàn),我們直接使用兩種最先進的局部特征聯(lián)合描述和檢測方法 ASLFeat 和 D2-Net ,用我們的方法替換它們的損失。Super-Point (SP) [16] 也是一種強大的圖像匹配方法。然而,它采用了興趣點預(yù)訓練和自標記,需要合成形狀和單應(yīng)性適應(yīng),而我們的損失很難直接采用。
盡管如此,我們?nèi)匀辉诒?中報告了 Super-Point 的 2D 匹配結(jié)果。以更好地展示其他Baseline的增強功能。特別地是,我們在訓練和測試中保持與原論文相同的評估設(shè)置。
HPatches 上的結(jié)果。
在這里,使用了三個指標[38]:
單應(yīng)性估計(HEstimation),圖像對之間正確單應(yīng)性估計的百分比;
精度,正確匹配與可能匹配的比率;
Recall,正確預(yù)測匹配占所有真實匹配的百分比。
如表中所示。當使用我們的損失時,幾乎所有指標,都可以在光照變化下看到明顯的改進(高達 3.9%)。唯一的例外發(fā)生在 D2-Net 于Recall ,以及 ASLFeat 于 HEstimation,我們的損失幾乎可以忽略不計。另一方面,可以在視圖變化下的所有指標上觀察到,我們方法的性能增益。這一增益范圍從 1.2% 到 5.6%。我們提出的優(yōu)化策略在視圖變化下顯示出比光照變化時更顯著的改進。
4.2.2 點云配準
在 3D 域方面,我們使用 3DMatch [58],這是一種流行的室內(nèi)數(shù)據(jù)集,用于點云配準 [26、15、23、12、11、22、10]。我們遵循 [58] 中相同的評估協(xié)議,準備了訓練數(shù)據(jù)和測試數(shù)據(jù),54 個場景用于訓練,其余 8 個場景用于測試。由于 D3Feat [2] 是唯一聯(lián)合檢測和描述 3D 局部特征的工作,我們將其損失替換為我們的損失進行了比較。為了更好地展示改進,還包括 FCGF [12] 的結(jié)果。
3DMatch 上的結(jié)果。
我們報告了三個評估指標的性能:1)配準召回(Reg),2)內(nèi)部比率(IR)和3)特征匹配召回(FMR)。如表3中所示,當采用我們的 P2-Loss(D3 Ours)時,Reg 和 FMR 分別可以有 4% 和 3% 的改進(與 D3Feat 相比)。相比之下,FCGF 和 D3Feat 分別只有 2% 和 0% 的差異。特別是,對于 Inlier Ratio,我們的損失表現(xiàn)出更好的魯棒性,比 D3Feat 高出 13%,與 FCGF 相當。總體而言,P2-Loss 在所有指標方面始終保持最佳性能。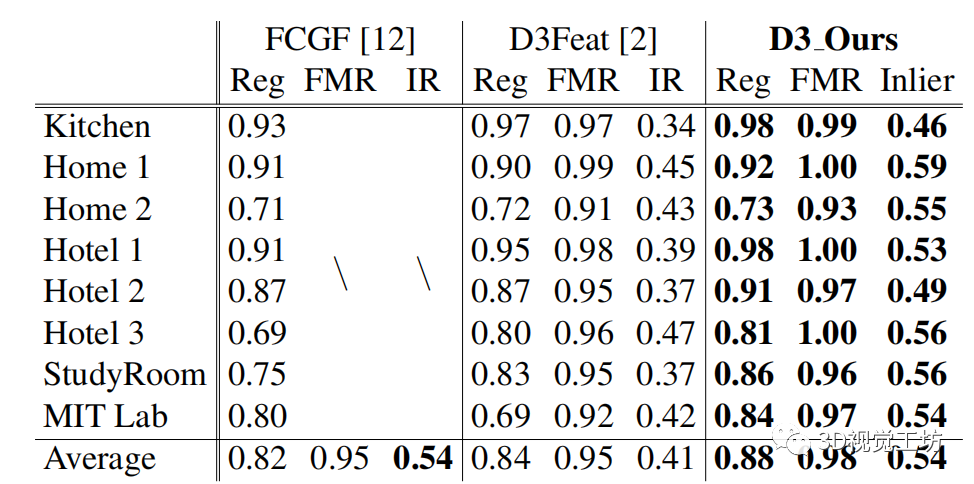
表 3:3DMatch [58] 上的比較。Reg、FMR 和 IR 在閾值 0.2 m、5% 和 0.1 m 處進行評估。
4.3. 描述符損失的影響
最后,我們分析損失選擇對同質(zhì) 或 )和異質(zhì)(2D3D)特征匹配的影響。基于方程式中的檢測器損失公式。如圖 9 所示,我們可以看到它的優(yōu)化緊緊地依賴于描述符。因此,我們對描述符優(yōu)化的三個主要度量學習損失,進行了全面研究,旨在回答:為什么圓形引導的描述符損失最適合特征匹配。
為此,我們使用各種損失公式和架構(gòu)跟蹤正相似度 dp 和最負相似度 dn* (max(dn)) 之間的差異。 如圖 6(左)顯示,在單個/同質(zhì) 2D或3D 域中,D2-Net 和 D3Feat 都可以逐漸學習獨特的描述符。D2-Net始終確保收斂,無論選擇的損失,而D3Feat失敗時,hard-triplet損失被選擇。這與[2]中的結(jié)論一致。
在跨域圖像和點云匹配中(圖6(右),我們比較了不同的損失和 2D 特征提取器。這壓倒性地證明了hard-triplet和hard對比損失都不能在任何框架(ASL、R2D2 或P2-Net)。triplet和對比損失都是不靈活的,因為每個相似性的懲罰強度被限制為相等。
此外,它們的決策邊界等價于 dp = dn,這會導致模糊收斂 [9, 33]。但是,我們的損失使所有架構(gòu)都能夠收斂,顯示出學習獨特描述符的可觀趨勢。由于引入了圓形決策邊界,所提出的描述符損失為相似性分配了不同的梯度,從而促進了更穩(wěn)健的收斂[47]。
有趣的是,我們可以觀察到,與同質(zhì)匹配不同,異構(gòu)匹配的描述符的可區(qū)別性最初是倒置的。由于2D像素和3D點描述符最初是不同的,因此對于初始階段的正匹配和負匹配,它們的相似性可能非常低。在這種情況下,相對于 dp 和 dn 范圍在 [0, 1] 之間的 Abs(梯度)幾乎分別接近 1和0 [47]。由于急劇的梯度差異,網(wǎng)絡(luò)訓練中的損失最小化傾向于過分強調(diào) dp 的優(yōu)化,而犧牲描述符的獨特性。隨著 dp 的增加,我們的損失減少了它的梯度,因此對 dn 施加了逐漸加強的懲罰,鼓勵了 dp 和 dn 之間的獨特性。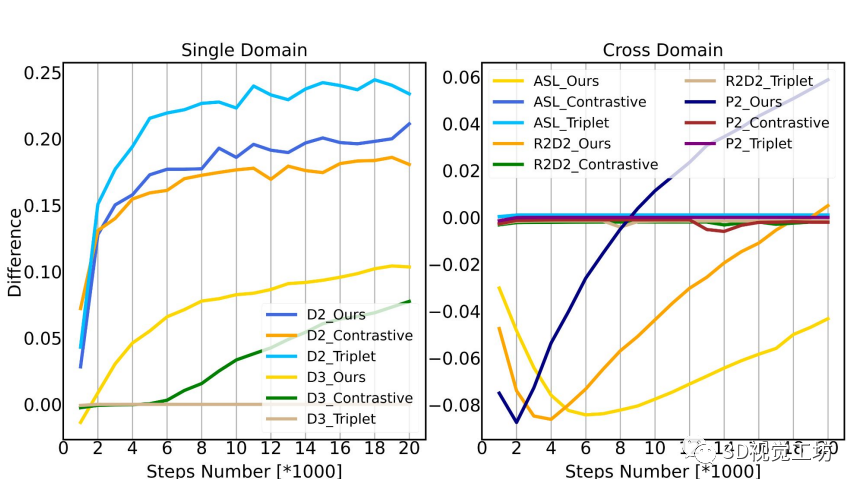
圖 6:隨著時間的推移,帶有不同網(wǎng)絡(luò)及損失的正相似度 dp 和最負相似度 dn* 之間的差異。左:單域匹配;右:跨域匹配。
五、結(jié)論
在這項工作中,我們提出了 P2-Net,這是一個雙全卷積框架,結(jié)合超寬接收機制,共同描述并檢測 2D和 D 局部特征,以實現(xiàn)2D像素和3D點之間的直接匹配。此外,提出一種新穎的損失函數(shù) P2-Loss ,由圓形引導的描述符損失和 batch-hard的檢測器損失組成,旨在明確地引導網(wǎng)絡(luò)學習獨特的描述符,并檢測2D像素和3D點的可重復(fù)關(guān)鍵點。在2D像素和3D點匹配、視覺定位、圖像匹配和點云配準方面的大量實驗,不僅展示了我們 P2-Net 的有效性和實用性,還展示了我們的 P2-Loss 的泛化能力和優(yōu)越性。
審核編輯:劉清
-
傳感器
+關(guān)注
關(guān)注
2560文章
52146瀏覽量
761335 -
檢測器
+關(guān)注
關(guān)注
1文章
882瀏覽量
48243 -
SLAM
+關(guān)注
關(guān)注
23文章
430瀏覽量
32236
原文標題:P2-Net:用于2D像素與3D點匹配的局部特征的聯(lián)合描述符和檢測器(ICCV 2021)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
HT 可視化監(jiān)控頁面的 2D 與 3D 連線效果
一種以圖像為中心的3D感知模型BIP3D
多維精密測量:半導體微型器件的2D&3D視覺方案
AN-1249:使用ADV8003評估板將3D圖像轉(zhuǎn)換成2D圖像

技術(shù)前沿:半導體先進封裝從2D到3D的關(guān)鍵
3D封裝熱設(shè)計:挑戰(zhàn)與機遇并存

蘇州吳中區(qū)多色PCB板元器件3D視覺檢測技術(shù)

英倫科技的15.6寸2D-3D可切換光場裸眼3D顯示屏有哪些特點?

Teledyne e2v公司和Airy3D公司合作,提供更實惠的3D視覺解決方案

NVIDIA Instant NeRF將多組靜態(tài)圖像變?yōu)?b class='flag-5'>3D數(shù)字場景
通過2D/3D異質(zhì)結(jié)構(gòu)精確控制鐵電材料弛豫時間

機器人3D視覺引導系統(tǒng)框架介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論