") 如何充分挖掘預(yù)訓(xùn)練視覺-語言基礎(chǔ)大模型的更好零樣本學(xué)習(xí)能力
如何充分挖掘預(yù)訓(xùn)練視覺-語言基礎(chǔ)大模型的更好零樣本學(xué)習(xí)能力
融入了Prompt的新模式大致可以歸納成”pre-train, prompt, and predict“,在該模式中,下游任務(wù)被重新調(diào)整成類似預(yù)訓(xùn)練任務(wù)的形式。例如,通常的預(yù)訓(xùn)練任務(wù)有Masked Language Model, 在文本情感分類任務(wù)中,對(duì)于 "I love this movie." 這句輸入,可以在后面加上prompt "The movie is ___" 這樣的形式,然后讓PLM用表示情感的答案填空如 "great"、"fantastic" 等等,最后再將該答案轉(zhuǎn)化成情感分類的標(biāo)簽,這樣以來,通過選取合適的prompt,我們可以控制模型預(yù)測(cè)輸出,從而一個(gè)完全無監(jiān)督訓(xùn)練的PLM可以被用來解決各種各樣的下游任務(wù)。
因此,合適的prompt對(duì)于模型的效果至關(guān)重要。大量研究表明,prompt的微小差別,可能會(huì)造成效果的巨大差異。研究者們就如何設(shè)計(jì)prompt做出了各種各樣的努力——自然語言背景知識(shí)的融合、自動(dòng)生成prompt的搜索、不再拘泥于語言形式的prompt探索等等。
而對(duì)于視覺領(lǐng)域的prompt,最近在視覺語言預(yù)訓(xùn)練方面的進(jìn)展,如CLIP和ALIGN,prompt為開發(fā)視覺任務(wù)的基礎(chǔ)模型提供了一個(gè)有前途的方向。這些基礎(chǔ)模型在數(shù)百萬個(gè)有噪聲的圖像-文本對(duì)上進(jìn)行訓(xùn)練后編碼了廣泛的視覺概念,可以在不需要任務(wù)特定的訓(xùn)練數(shù)據(jù)的情況下以零目標(biāo)的方式應(yīng)用于下游任務(wù)。這可以通過適當(dāng)設(shè)計(jì)的prompt提示實(shí)現(xiàn)。
以CLIP為例,如下圖紅色方框強(qiáng)調(diào)所示,可以完成對(duì)“class label”的拓展,使得模型具有較為豐富的視覺信息。然后,可以使用CLIP對(duì)圖像進(jìn)行分類,以度量它們與各種類描述的對(duì)齊程度。因此,設(shè)計(jì)這樣的提示在以zero-shot方式將基礎(chǔ)模型應(yīng)用到下游任務(wù)中起著至關(guān)重要的作用。
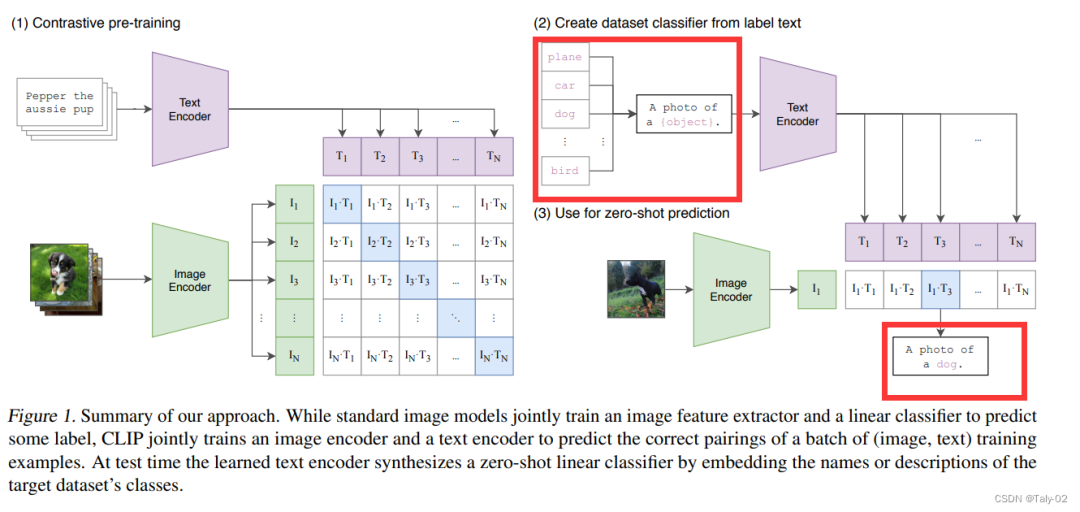
然而,這種手工制作的prompt需要特定于領(lǐng)域的靈感,因此可能較難設(shè)計(jì),所以如何設(shè)計(jì)一種模式,可以讓讓模型自適應(yīng)地學(xué)習(xí)到有關(guān)prompt的一些參數(shù)和設(shè)定是非常有必要的。與手工制作的prompt相比,這種方法可以找到更好的prompt,但學(xué)習(xí)到的prompt僅限于與訓(xùn)練數(shù)據(jù)對(duì)應(yīng)的分布和任務(wù),除此之外的泛化可能有限。
此外,這種方法需要帶注釋的訓(xùn)練數(shù)據(jù),這可能非常昂貴,而且不能很好地應(yīng)用于zero-shot的相關(guān)任務(wù)中。為了解決上述的挑戰(zhàn), 論文提出在測(cè)試階段使用test-time prompt tuning(TPT),只使用給定的測(cè)試樣本對(duì)prompt進(jìn)行調(diào)整。由于避免了使用額外的訓(xùn)練數(shù)據(jù)或標(biāo)注,TPT仍然遵守了zero-shot的設(shè)置。
. 方法
論文首先簡(jiǎn)單回顧了CLIP和基于CLIP的一些可學(xué)習(xí)參數(shù)的prompts獲取方法。對(duì)于為何要優(yōu)化prompt,論文是這樣描述的:CLIP包含了豐富的知識(shí),從前期的訓(xùn)練中獲得了海量的知識(shí)和不同的數(shù)據(jù)感知能力。然而,如何更有效地提取這些知識(shí)仍然是一個(gè)開放的問題。一個(gè)簡(jiǎn)單的策略是直接對(duì)模型進(jìn)行微調(diào),無論是端到端的還是針對(duì)的一個(gè)子集層,對(duì)一類的輸入。然而,先前的工作表明,這種微調(diào)策略導(dǎo)致特定于領(lǐng)域的行為失去了非分布泛化和魯棒性的基礎(chǔ)模型。
因此,這項(xiàng)工作的目標(biāo)是利用現(xiàn)有的CLIP知識(shí)來促進(jìn)其泛化到zero-shot的廠家中去。因此,調(diào)整prompt就是實(shí)現(xiàn)這一目標(biāo)的理想途徑。此外,我們將測(cè)試時(shí)提示調(diào)優(yōu)視為為模型提供上下文的一種方法為單個(gè)測(cè)試樣本量身定制,有助于精確檢索CLIP知識(shí)。
論文的目的很簡(jiǎn)單,就是在測(cè)試階段得不到測(cè)試樣本ground-truth標(biāo)注的時(shí)候,進(jìn)行一定的訓(xùn)練,具體表現(xiàn)為
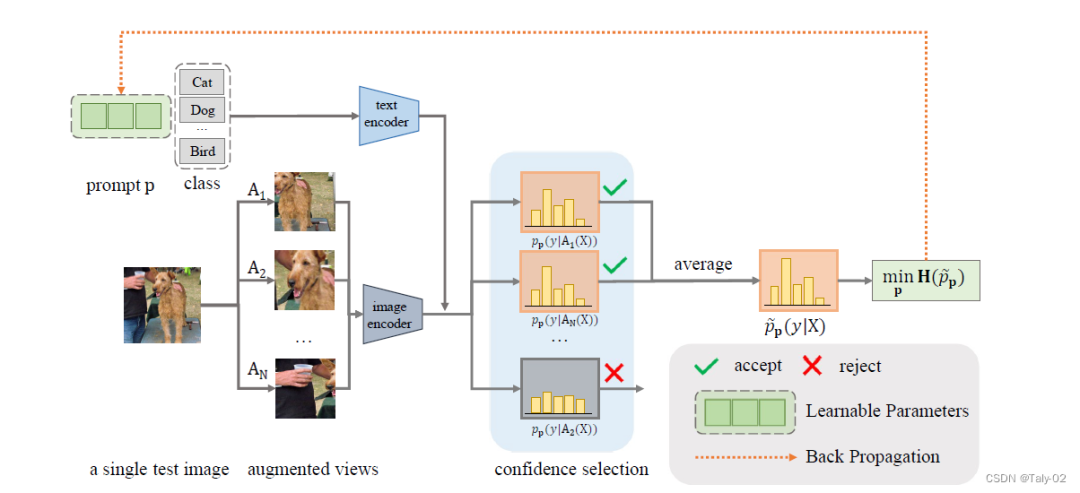
因?yàn)闃?biāo)簽不能用于測(cè)試階段的優(yōu)化,所以我們?nèi)绻朐跍y(cè)試階段進(jìn)行優(yōu)化就必須選擇用于能夠提供一定hint的無監(jiān)督損失函數(shù)來指導(dǎo)優(yōu)化。因此,論文設(shè)計(jì)了TPT目標(biāo)來促進(jìn)采用不同數(shù)據(jù)增強(qiáng)下,模型的一致性。通過對(duì)給定測(cè)試相同圖像的不同增強(qiáng)類型的特征,來依照他們預(yù)測(cè)的差值來進(jìn)行訓(xùn)練。具體來說,我們使用一個(gè)隨機(jī)增廣cluster生成測(cè)試圖像的N個(gè)隨機(jī)augumention視圖,最小化平均預(yù)測(cè)概率分布的熵:
這里 是根據(jù)物體不同prompt and the -th augmented view of the test image預(yù)測(cè)出的概率。
值得一提的是,為了減少隨機(jī)增強(qiáng)的噪聲(也就是說增強(qiáng)之后模型很難再預(yù)測(cè)出正確的分類信息,如刪去了圖像非常關(guān)鍵的content),本文還引入了一個(gè)新的機(jī)制:confidence selection,來選擇過濾增強(qiáng)產(chǎn)生的低置信度預(yù)測(cè)的view。數(shù)學(xué)表達(dá)式體現(xiàn)為:
實(shí)驗(yàn)
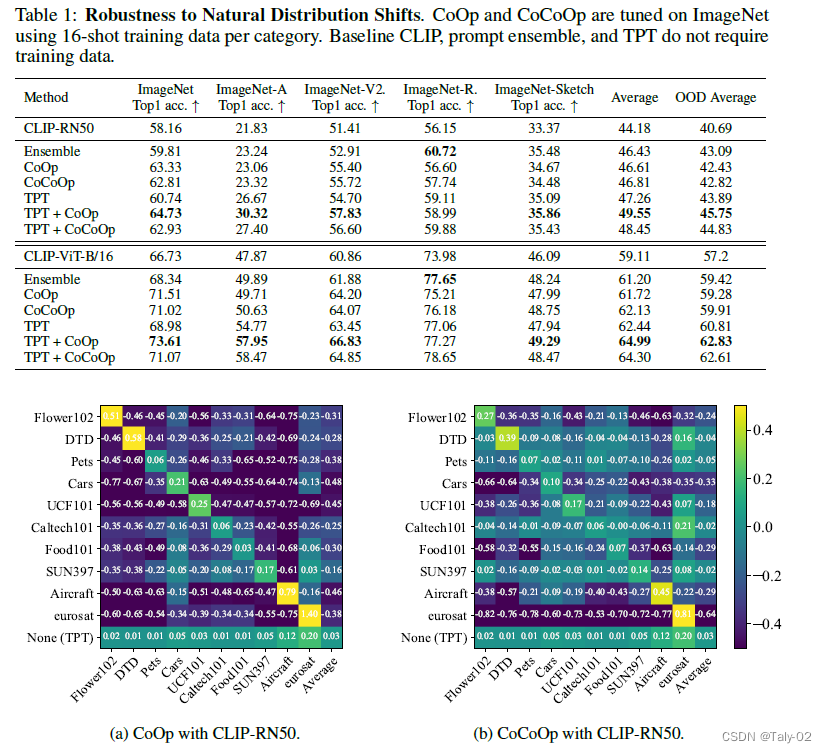
首先論文根據(jù)CoOp 和 CoCoOp的混淆矩陣可視化來判斷這兩種可學(xué)習(xí)的prompt參數(shù)化方式在不同數(shù)據(jù)集上的遷移性很差,有增加參數(shù)量過擬合的嫌疑。所以其實(shí)在訓(xùn)練階段,增加參數(shù)量來做相應(yīng)的操作不見得合理。因此才更能體現(xiàn)本文這種基于測(cè)試階段方法提出方法的優(yōu)越性。
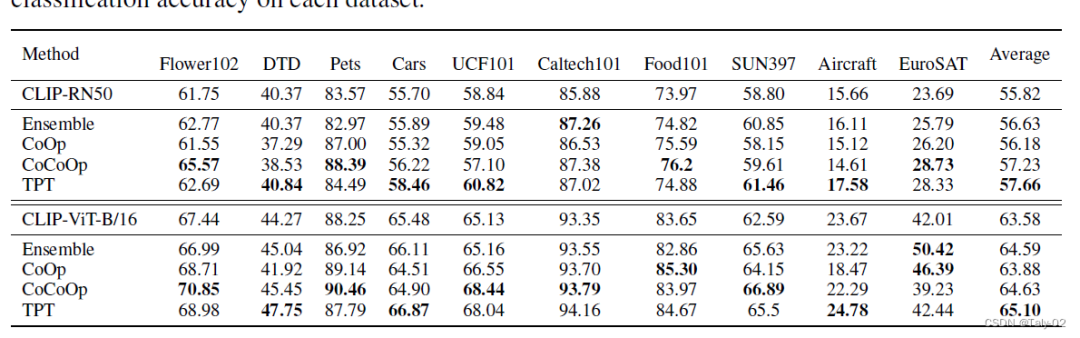
可以發(fā)現(xiàn),本文提出的這種方法在不同數(shù)據(jù)集之間的遷移性非常之好。
結(jié)論
本文研究了如何充分挖掘預(yù)訓(xùn)練視覺-語言基礎(chǔ)大模型的更好零樣本學(xué)習(xí)能力。論文提出了Test-time Prompt Tuning, TPT),這種新的prompt調(diào)整方法,可以使用單個(gè)測(cè)試樣本動(dòng)態(tài)學(xué)習(xí)自適應(yīng)提示。我們證明了該方法對(duì)自然分布變化的魯棒性跨數(shù)據(jù)集泛化,使用CLIP作為基礎(chǔ)模型。不需要任何訓(xùn)練數(shù)據(jù)或標(biāo)注,TPT提高了CLIP的zero-shot的泛化能力。
-
模型
+關(guān)注
關(guān)注
1文章
3254瀏覽量
48875 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24719 -
Clip
+關(guān)注
關(guān)注
0文章
31瀏覽量
6671 -
自然語言
+關(guān)注
關(guān)注
1文章
288瀏覽量
13355 -
大模型
+關(guān)注
關(guān)注
2文章
2476瀏覽量
2783
原文標(biāo)題:面向測(cè)試階段的prompt搜索方式
文章出處:【微信號(hào):GiantPandaCV,微信公眾號(hào):GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
【大語言模型:原理與工程實(shí)踐】大語言模型的應(yīng)用
基于深度學(xué)習(xí)的自然語言處理對(duì)抗樣本模型
基于預(yù)訓(xùn)練視覺-語言模型的跨模態(tài)Prompt-Tuning

融合零樣本學(xué)習(xí)和小樣本學(xué)習(xí)的弱監(jiān)督學(xué)習(xí)方法綜述

如何更高效地使用預(yù)訓(xùn)練語言模型
利用視覺語言模型對(duì)檢測(cè)器進(jìn)行預(yù)訓(xùn)練
使用BLIP-2 零樣本“圖生文”
預(yù)訓(xùn)練數(shù)據(jù)大小對(duì)于預(yù)訓(xùn)練模型的影響
形狀感知零樣本語義分割
一個(gè)通用的自適應(yīng)prompt方法,突破了零樣本學(xué)習(xí)的瓶頸

基于預(yù)訓(xùn)練模型和語言增強(qiáng)的零樣本視覺學(xué)習(xí)

什么是零樣本學(xué)習(xí)?為什么要搞零樣本學(xué)習(xí)?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論