 基于BlockNeRF的大場景規模化神經視圖合成
基于BlockNeRF的大場景規模化神經視圖合成
作者:Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P. Srinivasan, Jonathan T. Barron, Henrik Kretzschmar
我們提出了 Block-NeRF,一種神經輻射場的變體,可以表示大規模的場景。具體來說,我們發現,當使用 NeRF 渲染跨越多個街區的城市規模場景時,將場景分解為單獨訓練的子 NeRF 至關重要。這種分解將渲染時間與場景大小分離,使渲染能夠擴展到任意大的場景,并允許對環境進行逐塊更新。我們采用了幾項架構更改,以使 NeRF 對在不同環境條件下數月捕獲的數據具有魯棒性。我們為每個單獨的 NeRF 添加了外觀嵌入、可學習的位姿細化和可控曝光,并引入了校準相鄰 NeRF 之間外觀的程序,以便它們可以無縫組合。我們從 280 萬張圖像中構建了一個 Block-NeRF 網格,以創建迄今為止最大的神經場景表示,能夠渲染舊金山的整個社區。
主要貢獻
為了在大場景中應用神經輻射場(NeRF)模型,文章提出將大型場景分解為相互重疊的子場景 (block),每一個子場景分別訓練,在推理時動態結合相鄰 Block-NeRF 的渲染視圖。 文章在 mip-NeRF 的基礎上增加了外觀嵌入、曝光嵌入和位姿細化,以解決訓練數據橫跨數月而導致的環境變化和位姿誤差。 為了保證相鄰 Block-NeRF 的無縫合成,文章提出了在推理時迭代優化這些 Block-NeRF 的輸入外觀嵌入以校準它們的渲染結果。
方法概述
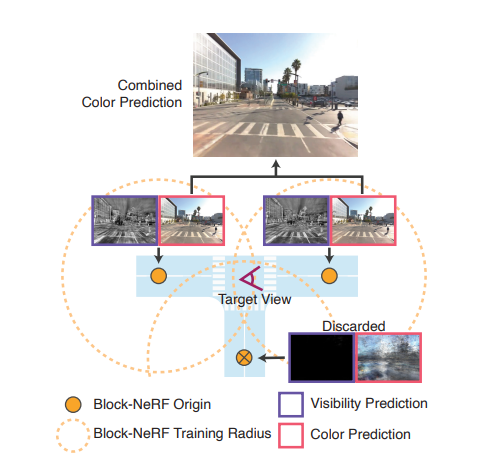
神經輻射場 (NeRF)是使用神經網絡擬合輻射場,用于視圖渲染的方法。然而,傳統的 NeRF 很難被直接擴展到大場景應用。這是因為擬合大場景所需的神經網絡也會很大,這會導致訓練和推理渲染變得很困難。本文提出將大的場景劃分為數個相互重合的小場景 (block)。如下圖所示的丁字路口被劃分為三個小場景(黃圈),針對每一個小場景單獨訓練一個 Block-NeRF。推理時合并覆蓋目標視圖范圍的 Block-NeRF 渲染生成最終的視圖。
mip-NeRF 拓展文章基于 mip-NeRF,但是由于訓練視圖在長達數月的時間內采集,不可避免地出現場景光照不同、相機曝光不同、視圖位姿存在誤差等問題。為了解決這些問題,文章在 mip-NeRF 的基礎上增加了外觀嵌入和曝光作為神經網絡的輸入(如下圖所示,其中 fσ 和 fc 分別為預測密度 σ 和顏色 RGB 的神經網絡,x 為場景中的三維坐標點,d 表示視角)。
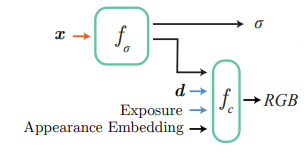
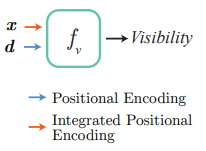
訓練時使用生成式潛碼優化的方法學習外觀嵌入,消除天氣光照等原因的影響。曝光則直接可以讀取采集記錄,只需對其進行正弦位置編碼即可。 與此同時,訓練視圖的采集跨越了多個駕駛段,這些駕駛軌跡之間不可避免地存在位姿誤差。Block-NeRF 訓練時還同時優化每一個駕駛段的位姿偏移以降低位姿誤差帶來的影響。 街道視圖中存在汽車、行人等瞬時物體,然而場景渲染通常只關注建筑、街道等靜態結構。文章于是使用語義分割網絡對訓練視圖中的動態物體進行掩蔽,這樣神經輻射場就不會學習這些動態物體,而是只關注靜態場景結構。 有時目標視圖的相鄰 Block-NeRF 可能距離上很近,但并不在目標視圖的視野之內,文章在傳統 NeRF 的兩個神經網絡 fσ 和 fc 之外,還增加了一個預測能見度的網絡 fv。給定三維坐標 x 和視角 d , fv 預測該點在給定視角下的能見度。合成多個 Block-NeRF 的渲染時,能見度低于閾值的渲染不會被用于最終的合成。訓練時能見度可以由相應點的透光率作為監督目標。
Block-NeRF 融合為提高渲染效率,渲染目標視圖時文章僅融合: 中心點在閾值半徑內 且平均能見值高于閾值的 Block-NeRFs 滿足這兩個條件的 Block-NeRFs 以反距離加權的方式融合渲染視圖。這里的距離選擇相機到 Block-NeRFs 的二維空間距離。這樣的融合方法既保證了渲染真實度又能夠滿足時空一致性。 為了保證不同視角下渲染的天氣、光線等外觀的一致性,文章還在推理時引入了外觀嵌入迭代優化。給定一個 Block-NeRF 的外觀嵌入,文章在鎖定神經網絡權重不變的基礎上,優化相鄰 Block-NeRFs 的外觀嵌入,最大化其渲染視圖的一致性。
實驗結果
文章采集并開源了兩個數據集:San Francisco Alamo Square Dataset 和 San Francisco Mission Bay Dataset,分布包含280萬和1.2萬圖片。Alamo Square Dataset覆蓋大約 0.5km2 ,采集自3個月周期內,包括不同光線條件和天氣的數據。Mission Bay Dataset 涵蓋的地理范圍遠遠小于 Alamo Square Dataset,主要被用來與 NeRF做比較。 Table 2 顯示 Block-NeRF 相較于NeRF 渲染效果更好。并且 block 數量越多越好。即便是保持神經網絡總參數量不變,Block-NeRF 仍然優于 NeRF 并且推理速度在不考慮并行計算的前提下也大大提高。
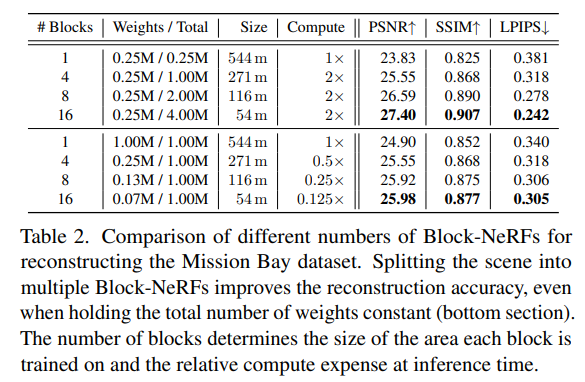
Table 1 和 Figure 7 分別定量和定性地顯示外觀嵌入、曝光輸入以及位姿優化都對提高渲染效果有幫助。
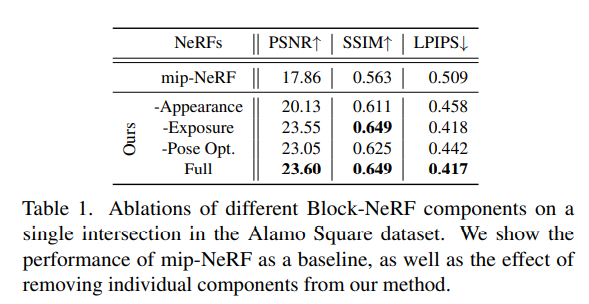

Figure 6 顯示推理時外觀嵌入優化可以將渲染從白天場景轉換成黑夜場景,從而更好地與基準 Block-NeRF 匹配,增強渲染地時空一致性。

總結
本文提出了Block-NeRF,采用 divide-and-conquer 的方法使用多個 Block-NeRFs 學習大型場景的不同分塊,最終將這些Block-NeRFs 的渲染合成目標視圖。這樣的方法使得利用 NeRF 模型渲染城市規模的場景成為了可能。 此外 Block-NeRF 還在 mip-NeRF 的基礎上,引入了外觀嵌入優化、曝光輸入和位姿細化等擴展,以解決訓練數據橫跨數月而導致的環境變化和位姿誤差。
審核編輯:郭婷
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100726
原文標題:BlockNeRF: 大場景規模化神經視圖合成(CVPR 2022)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
何勉:第一性原理和精益敏捷的規模化實施
規模化FTTH建設下的ODN質量探討

阿里攜手物聯網合作伙伴成立ICA,推動IoT產業規模化






 工商網監
工商網監
評論