

作者:Hao Ai,Zidong Cao,Jinjing Zhu,Haotian Bai,Yucheng Chen,Lin Wang
本綜述來自于香港科技大學(廣州)王林團隊,對現有的深度學習在全景視覺上的應用進行了全面的回顧,并提供了一些新的觀點以及對全景視覺未來的應用展望。
本文首先對全景圖像的成像進行了分析,緊接著對現有的在全景圖像上的卷積方式進行了分類介紹,并對現有的全景圖像數據集進行了收集并介紹。作為第一篇全面回顧和分析深度學習方法在全景圖像應用上的綜述,我們匯總并分析對比了在眾多視覺任務上現有深度學習方法的相同與差異。最后,我們提供了一些全景圖像的新的應用方向的研究思路,以供研究者參考討論。
1、Abstract
全向圖像(ODI)數據是用360 x180的視場捕獲的,該視場比針孔相機寬得多,并且包含比傳統平面圖像更豐富的空間信息。因此,全景視覺因其在自動駕駛和虛擬現實等眾多應用中更具優勢的性能而引起了人們的廣泛關注。近年來,客戶級360相機的出現使得全景視覺更加流行,深度學習(DL)的進步顯著激發了其研究和應用。本文對深度學習方法在全景視覺方面的最新進展進行了系統、全面的綜述和分析。作者的工作包括四個主要內容:(一)介紹全向成像原理,ODI上的卷積方法,以及數據集,以突出與2D平面圖像數據相比的差異和困難;(二) 用于全景視覺的遠程學習方法的結構和層次分類;(三) 總結最新的新學習戰略和應用;(四) 通過強調潛在的研究方向,對挑戰和懸而未決的問題進行有見地的討論,以促進社區中的更多研究。
x180的視場捕獲的,該視場比針孔相機寬得多,并且包含比傳統平面圖像更豐富的空間信息。因此,全景視覺因其在自動駕駛和虛擬現實等眾多應用中更具優勢的性能而引起了人們的廣泛關注。近年來,客戶級360相機的出現使得全景視覺更加流行,深度學習(DL)的進步顯著激發了其研究和應用。本文對深度學習方法在全景視覺方面的最新進展進行了系統、全面的綜述和分析。作者的工作包括四個主要內容:(一)介紹全向成像原理,ODI上的卷積方法,以及數據集,以突出與2D平面圖像數據相比的差異和困難;(二) 用于全景視覺的遠程學習方法的結構和層次分類;(三) 總結最新的新學習戰略和應用;(四) 通過強調潛在的研究方向,對挑戰和懸而未決的問題進行有見地的討論,以促進社區中的更多研究。
2、Introduction
隨著3D技術的飛速發展和對逼真視覺體驗的追求,對計算機視覺的研究興趣逐漸從傳統的2D平面圖像數據轉向全向圖像(ODI)數據,也稱為360圖像、全景圖像或球形圖像數據。由360攝像機捕獲的ODI數據產生360x180視場(FoV),這比針孔相機寬得多;因此,它可以通過反射比傳統平面圖像更豐富的空間信息來捕獲整個周圍環境。由于沉浸式體驗和完整視圖,ODI數據已廣泛應用于眾多應用,例如增強現實(AR)/虛擬現實(VR),自動駕駛和機器人導航。通常,原始ODI數據表示為等距柱狀投影(ERP)或立方體圖投影(CP)以與成像管道一致。作為一個新穎的數據領域,ODI數據既具有領域獨特的優勢(球面成像的寬FoV,豐富的幾何信息,多種投影類型)也具有挑戰性(ERP類型中的嚴重失真,CP格式的內容不連續性)。這使得對全景視覺的研究變得有價值,但具有挑戰性。
最近,客戶級360相機的出現使全景視覺更加普及,深度學習(DL)的進步極大地促進了其研究和應用。特別是作為一項數據驅動的技術,公共數據集的持續發布,包括:SUN360、Salient 360、Stanford2D3D、Pano-AVQA和PanoContext數據集等等,已經迅速使深度學習方法取得了顯著的突破,并經常在各種全景視覺任務上實現最先進的(SoTA)性能。此外,還開發了各種基于不同架構的深度神經網絡(DNN)模型,從卷積神經網絡(CNN),遞歸神經網絡(RNN),生成對抗網絡(GAN),圖神經網絡(GNN),到vision Trasnformer(ViTs)。一般來說,SoTA-DL方法側重于四個主要方面:(I)用于從ODI數據中提取特征的卷積濾波器(全向視頻(ODV)可以被認為是ODI的一個時間集),(II)通過考慮輸入數字和投影類型進行網絡設計,(III)新穎的學習策略,以及(IV)實際應用。本文對深度學習方法在全景視覺方面的最新進展進行了系統、全面的綜述和分析。與已有的關于全景視覺的綜述不同,我們強調了深度學習的重要性,并按照邏輯地和全面地探索了全景視覺的最新進展。本研究中提出的結構和層次分類法如圖所示。
綜上所述,本研究的主要貢獻可歸納為:(1)據我們所知,這是第一份調查,全面回顧和分析了全景視覺的DL方法,包括全向成像原理,表征學習,數據集,分類學和應用,以突出與2D規劃師圖像數據的差異和困難。(2)我們總結了過去五年中發表的大多數(可能不是全部)頂級會議/期刊作品(超過200篇論文),并對DL的最新趨勢進行了分析研究,以實現分層和結構上的全景視覺。此外,我們還提供對每個類別的討論和挑戰的見解。(3)我們總結了最新的新型學習策略和全方位視覺的潛在應用。(4)由于深度學習用于全景視覺是一個活躍而復雜的研究領域,我們對挑戰和尚未解決的問題進行了深入的討論,并提出了潛在的未來方向,以刺激社區進行更深入的研究。同時,我們在多個表格中總結了一些流行的全景視覺任務的代表性方法及其關鍵策略。為了提供更好的任務內比較,我們在基準數據集上提出了一些代表性方法的定量和定性結果,所有統計數據均來自原始論文。由于空間不足,我們在補充材料的Sec.2中展示了實驗結果。(5)我們創建了一個開源存儲庫,該存儲庫提供了所有上述作品和代碼鏈接的分類。我們將繼續用這一領域的新作品更新我們的開源存儲庫,并希望它能為未來的研究提供啟示。存儲庫鏈接為https://github.com/VLISLAB/360-DL-Survey。
3、Background
3.1、全景成像原理
3.1.1 Acquisition
普通相機的FoV低于180,因此最多只能捕獲一個半球的視圖。然而,一個理想的360相機可以捕捉從各個方向落在焦點上的光線,使投影平面成為一個完整的球面。在實踐中,大多數360相機無法實現它,由于死角,這排除了頂部和底部區域。根據鏡頭數量,360相機可分為三種類型:(i)帶有一個魚眼鏡頭的相機,不可能覆蓋整個球面。但是,如果已知內在和外在參數,則可以通過將多個圖像投影到一個球體中并將它們拼接在一起來實現ODI;(ii)帶有雙魚眼鏡頭的攝像機位于相反的位置,每個鏡頭的額定值都超過 180 美元,例如 Insta360 ONE 和 LG 360 CAM。這種類型的360相機對鏡頭有最低需求,這些鏡頭便宜又方便,受到行業和客戶的青睞。然后將來自兩個相機的圖像拼接在一起以獲得全向圖像,但拼接過程可能會導致邊緣模糊;(iii) 具有兩個以上鏡頭的相機,如泰坦(八個鏡頭)。此外,GoPro Omni是第一款將六個常規相機放置在立方體的六個面上的相機裝備,其合成結果具有更高的精度和更少的邊緣模糊。這種類型的360相機是專業級的。

3.1.2 Spherical Stereo

全景圖像擁有多個投影方式,如等距柱狀投影(ERP), 立方體貼圖投影(CP), 切線投影(TP), 二十面體投影(IP)以及一些其他復雜投影方式等等,具體轉換公式請查看全文。
3.1.3 Spherical Stereo

3.2 針對全景圖像的卷積方法
由于全景圖像(ODI)的自然投影表面是一個球體,因此當球面圖像投影回平面時,標準 CNN 處理固有失真的能力較差。已經提出了許多基于CNN的方法,以增強從球形圖像中提取“無偏”信息的能力。這些方法可以分為兩類:(i)在平面投影上應用2D卷積濾波器;(ii) 直接利用球面域中的球面卷積濾波器。在本小節中,我們將詳細分析這些方法。
3.2.1 基于平面投影的卷積

作為最常見的球面投影,ERP引入了嚴重的變形,特別是在兩極。考慮到它提供了全局信息并且占用了更少的計算成本,Su 等人提出了一種具有代表性的方法,該方法基于球面坐標利用具有自適應核大小的常規卷積濾波器。受球面卷積的啟發,SphereNet提出了另一種典型的方法,通過直接調整卷積濾波器的采樣網格位置來實現失真不變性,并可以端到端地訓練,如圖所示。Distortion-aware的卷積核,如圖所示。特別是,在ODI得到廣泛應用之前,Cohen等人研究了ERP引入的空間變化失真,并提出了一種旋轉不變球面CNN方法來學習SO3表示,等等。
3.2.2 球面卷積
一些方法已經探索了球面域中的特殊卷積濾波器。Esteves等人提出了第一個球面CNN架構,該架構考慮了球面諧波域中的卷積濾波器,以解決標準CNN中的3D旋轉等價差問題。
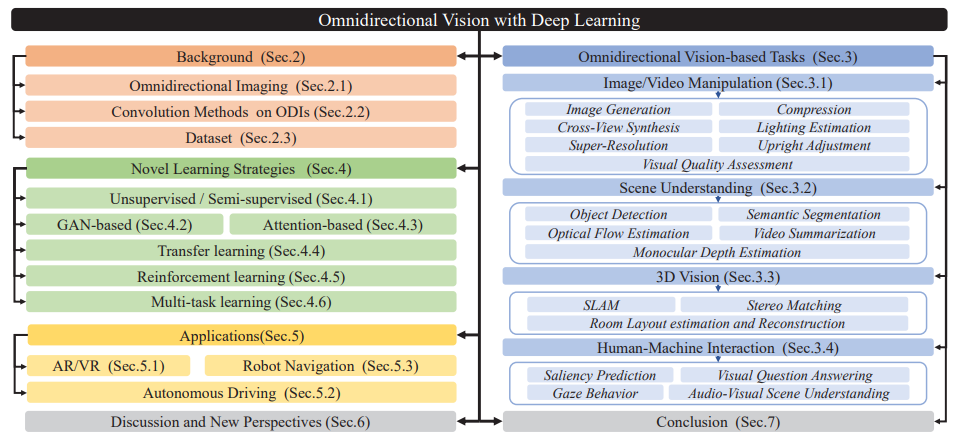
楊等人提出了一個代表性框架,將球面圖像映射到基于球面幾何形狀的旋轉等變表示中。(a),SGCN將輸入球面圖像表示為基于GICOPix的圖形。此外,它通過GCN層探索了圖的等距變換等方差。在cohen等人的文章中,提出了規范等變CNN來學習二十面體的球面表示。相比之下,shakerinava等人將二十面體擴展到柏拉圖固體的所有像素化,并在像素化的球體上推廣了規范等變CNN。由于在效率和旋轉等價差之間進行權衡,DeepSphere將采樣球體建模為連接像素的圖形,并設計了一種新穎的圖形卷積網絡 (GCN),通過調整圖上像素的相鄰像素數來平衡計算效率和采樣靈活性。與上述方法相比,在SpherePHD中提出了另一種具有代表性的ODI表示。如圖所示,球面PHD將球面圖像表示為球面多面體,并提供特定的卷積和池化方法。
3.3數據集
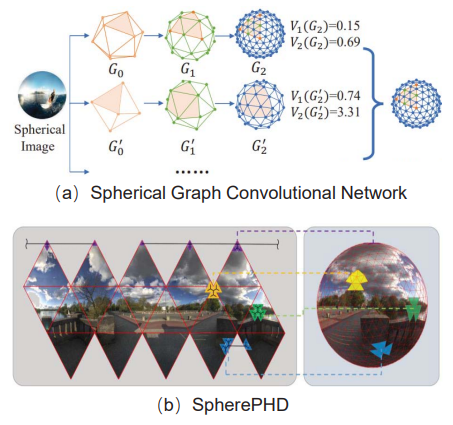
基于深度學習的方法的性能與數據集的質量和數量密切相關。隨著球面成像設備的發展,大量的ODI和OPV數據集被公開用于各種視覺任務。特別是,大多數ODV數據都是從維梅奧和優酷等公共視頻共享平臺收集的。在表格Table1中,我們列出了一些用于不同目的的代表性 ODI 和 ODV 數據集,我們還顯示了它們的屬性,例如大小、分辨率、數據源。更多的數據集可以在全文以及補充材料中找到。
4、Omnidirectional Vision Tasks
4.1、圖像/視頻處理
4.1.1 圖像生成
圖像生成旨在從部分或噪聲數據中恢復或合成完整且干凈的ODI數據. 對于ODI上的圖像生成,存在四個流行的研究方向:(i)全景深度圖補全;(二) 全景深度圖補全;(三)全景語義圖的補全;(四)在全景圖像上的視角合成。在本小節中,我們對一些代表性作品進行了全面的分析。
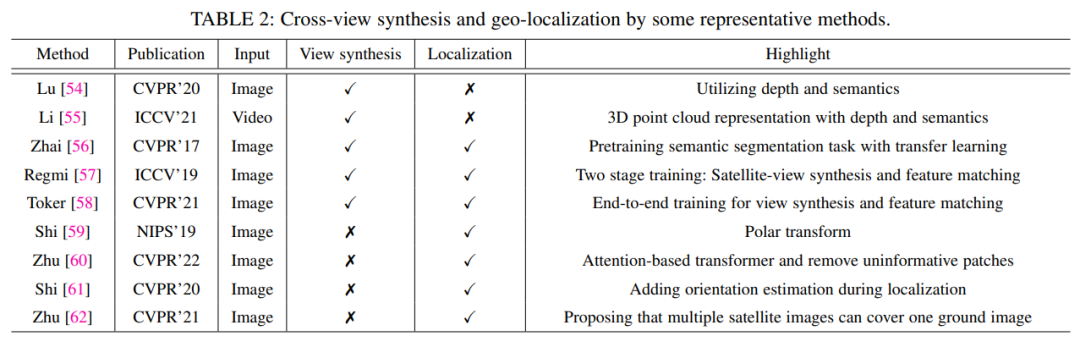
4.1.2 跨視圖合成和地理定位
跨視圖合成旨在從衛星視圖圖像中合成地面視圖ODI,而地理定位旨在匹配地面視圖ODI和衛星視圖圖像以確定它們之間的關系。
討論:大多數跨視圖合成和地理定位方法都假定參考圖像精確地位于任何查詢圖像的位置。盡管如此,在實踐中,這兩種觀點在方向和空間位置方面通常并不完全一致。因此,如何在具有挑戰性的條件下應用跨視圖合成和地理定位方法是一個有價值的研究方向。
4.1.3 圖像壓縮
與傳統的透視圖像相比,全景數據以更高的分辨率和更寬的FoV記錄更豐富的幾何信息,這使得實現有效壓縮更具挑戰性。早期的ODI壓縮方法直接利用現有的透視方法來壓縮ODI的透視投影。例如,Simone等人提出了一種自適應量化方法,以解決將ODI投影到ERP時視口圖像塊的頻率偏移。相比之下,OmniJPEG首先估計 ODI 中感興趣的區域,然后根據區域內容的幾何變換,使用一種名為 OmniJPEG 的新穎格式對 ODI 進行編碼,該格式是 JPEG 格式的擴展,可以在舊版 JPEG 解碼器上查看,等等。
4.1.4 照明估計
它旨在從低動態范圍(LDR)ODI預測高動態范圍(HDR)照明。照明恢復被廣泛用于許多現實世界的任務,從場景理解、重建到編輯。Hold-Geoffroy等人提出了一個具有代表性的戶外照度估計框架。他們首先訓練了一個CNN模型,以預測室外ODI的視口的天空參數,例如太陽位置和大氣條件。然后,他們根據預測的照明參數為給定的測試圖像重建照明環境圖。同樣,在Gardner等人的工作中,利用CNN模型來預測視口中燈光的位置,并對CNN進行微調以從ODI中預測燈光強度即環境圖。在Gardner等人2019年的一個工作中中,室內照明的幾何和光度參數從ODI的視口回歸,并利用中間潛向量重構環境貼圖。另一種代表性的方法,稱為EMLight,由回歸網絡和神經投影儀組成。回歸網絡輸出光參數,神經投影儀將光參數轉換為照度圖。特別是,光參數的地面實況由通過球面高斯函數從照明生成的高斯圖分解。
討論和潛力:從上述分析中,先前用于ODI照明估計的工作將單個視口作為輸入。原因可能是視口無失真,低成本,分辨率低。然而,它們遭受了空間信息的嚴重下降。因此,應用對比學習從切線圖像的多個視口或組件中學習穩健的表示可能是有益的。
4.1.5 圖像超分
現有的頭戴式顯示器(HMD)設備至少需要21600乘以10800像素的ODI才能獲得沉浸式體驗,這是當前相機系統無法直接捕獲的。另一種方法是捕獲低分辨率 (LR) ODI,并高效地將它們超級解析為高分辨率 (HR) ODI。LAU-Net作為第一個考慮ODI SR緯度差異的著作,引入了多級緯度自適應網絡。它將ODI劃分為不同的緯度波段,并分層地擴展這些波段,這些波段具有不同的自適應因子,這些因子是通過強化學習方案學習的。除了考慮ERP上的SR之外,Yoon等人提出了一個代表性的工作SphereSR,以學習統一的連續球面局部隱式圖像函數,并根據球面坐標查詢生成任意分辨率的任意投影。對于全景視頻(ODV) SR,SMFN是第一個基于DNN的框架,包括單幀和多幀聯合網絡和雙網絡。單幀和多幀聯合網絡融合了相鄰幀的特征,雙網限制了求解空間,以找到更好的答案。
4.1.6 Upright Adjustment
Upright Adjustment旨在糾正攝像機和場景之間方向的錯位,以提高ODI和ODV的視覺質量,同時將它們與窄視場(NFoV)顯示器(如VR應用程序)一起使用。
4.1.7 視覺質量評估
由于全向數據的超高分辨率和球體表示,視覺質量評估(V-QA)對于優化現有的圖像/視頻處理算法很有價值。接下來,我們將分別介紹一些關于ODI-QA和ODV-QA的代表性作品。
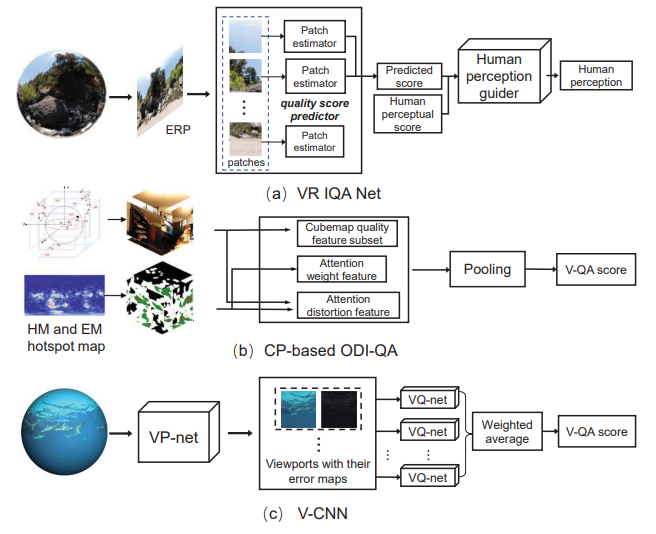
對于 ODI-QA,根據參考圖像的可用性,可以進一步將其分為兩類:full-reference (FR) ODI-QA 和no-reference (NR) ODI-QA。對于 ODV-QA,Li等人提出了一種基于具有代表性的基于視口的 CNN 方法,包括視口提案網絡和視口質量網絡,如圖所示。視口方案網絡生成多個潛在視口及其錯誤映射,視口質量網絡對每個建議視口的 V-QA 分數進行評級。最終的V-QA分數是通過所有視口V-QA分數的加權平均值計算的。Gao等人對ODV的時空扭曲進行了建模,并通過整合現有的3個ODI-QA目標指標,提出了一種新的FR目標指標。
4.2、場景理解
4.2.1 物體識別
與普通透視圖像相比,基于深度學習的ODI對象檢測仍然存在兩大難點:(i)傳統的卷積核在ODI投影中處理不規則平面網格結構的能力較弱;(ii)傳統2D物體檢測中采用的標準不適合球形圖像。
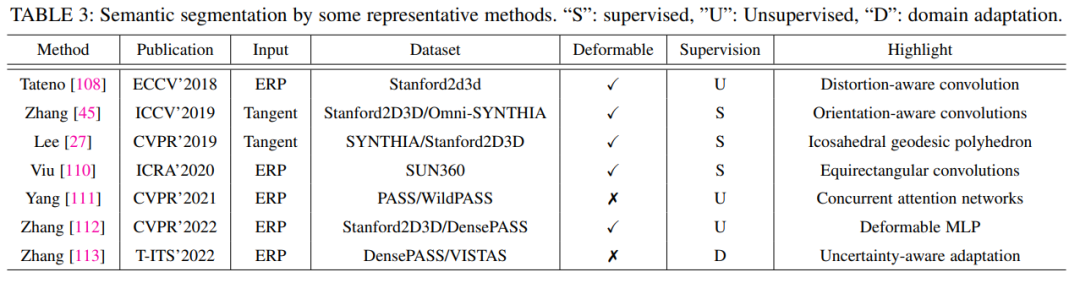
4.2.2 語義分割
基于DL的全向語義分割已被廣泛研究,因為ODI可以包含有關周圍空間的詳盡信息。實際上還存在許多挑戰,例如,平面投影中的變形,物體變形,計算復雜性和稀缺的標記數據。在文章中,我們介紹了一些通過監督學習和無監督學習進行ODI語義分割的代表性方法。
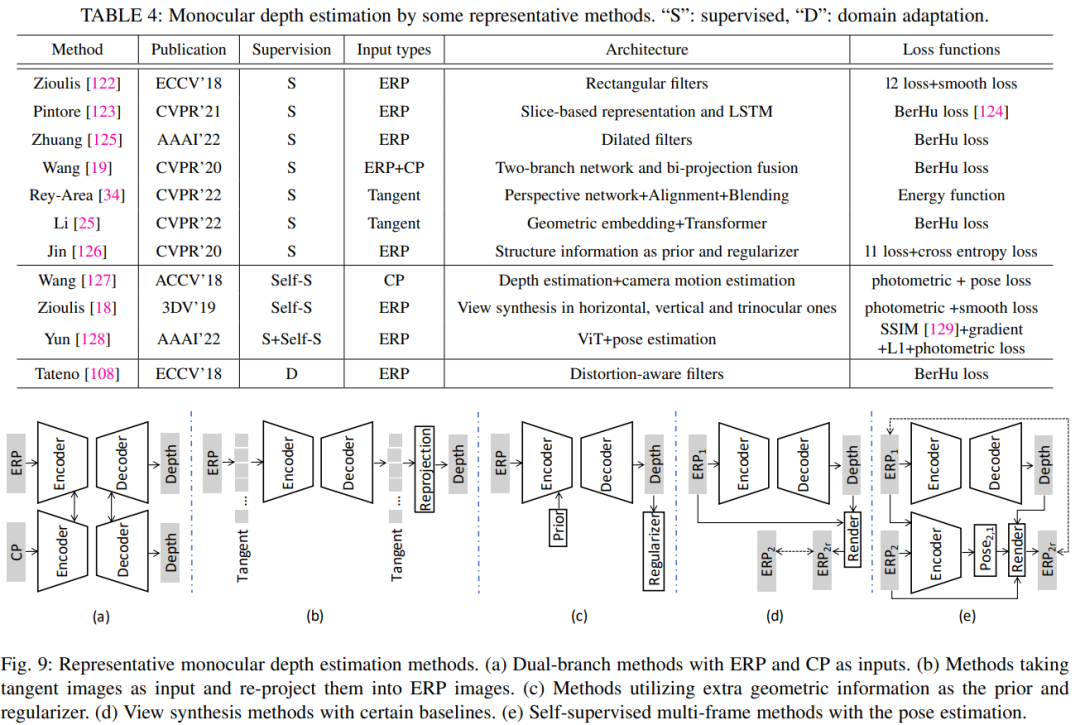
4.2.3 單目深度估計
由于大規模全景深度數據集的出現,單目深度估計發展迅速。如圖所示有幾種趨勢:(i)定制網絡,例如,失真感知卷積濾波器和魯棒表示;(ii) 基于不同的投影類型。(iii) 固有的幾何先驗。(iv) 多個視圖或姿態估計。
4.2.4 光流估計
基于現有的實驗結果表明,直接應用基于DL的二維光流估計方法對ODI進行估計,會得到不盡如人意的結果。為此,Xie等人介紹了一個小型診斷數據集FlowCLEVR,并評估了三種定制卷積濾波器的性能,即相關卷積、坐標和可變形卷積,用于估計全向光流。域適配框架受益于透視域光流估計的發展。與Cubes3DNN類似,OmniFlowNet建立在FlowNet2上。特別是作為LiteFlowNet的延伸,LiteFlowNet360采用核變換技術,解決了球面投影帶來的固有失真問題,等等。
4.2.5 視頻總結
視頻摘要旨在通過選擇包含 ODV 最關鍵信息的部分來生成具有代表性和完整的概要。與2D視頻總結方法相比,ODV的視頻總結只有少數作品被提出。Pano2Vid是代表性框架,包含兩個子步驟:檢測整個 ODV 幀中感興趣的候選事件,并應用動態編程來鏈接檢測到的事件。但是,Pano2Vid需要觀察整個視頻,并且對于視頻流應用程序的能力較差。Deep360Pilot是第一個設計用于觀眾自動ODV導航的類人在線代理的框架。Deep360pilot包括三個步驟:對象檢測以獲得感興趣的候選對象,訓練RNN選擇重要對象,以及在ODV中捕捉激動人心的時刻。AutoCam在人類行為理解之后從 ODV 生成正常的 NFoV 視頻。
討論:基于上述分析,該研究領域只有少數幾種方法存在。作為一項與時間相關的任務,將轉換器機制應用于ODV匯總可能是有益的。此外,以前的作品只考慮了ERP格式,這遭受了最嚴重的失真問題。因此,最好考慮 CP、切線投影或球體格式作為 ODV 匯總的輸入。
4.3、3D視覺
4.3.1 房間布局估計和重建
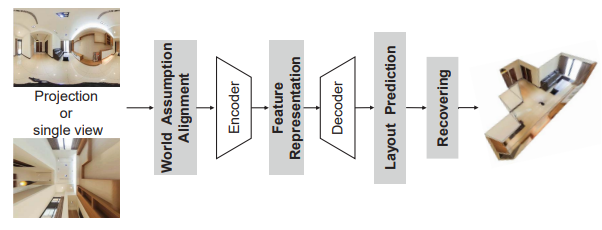
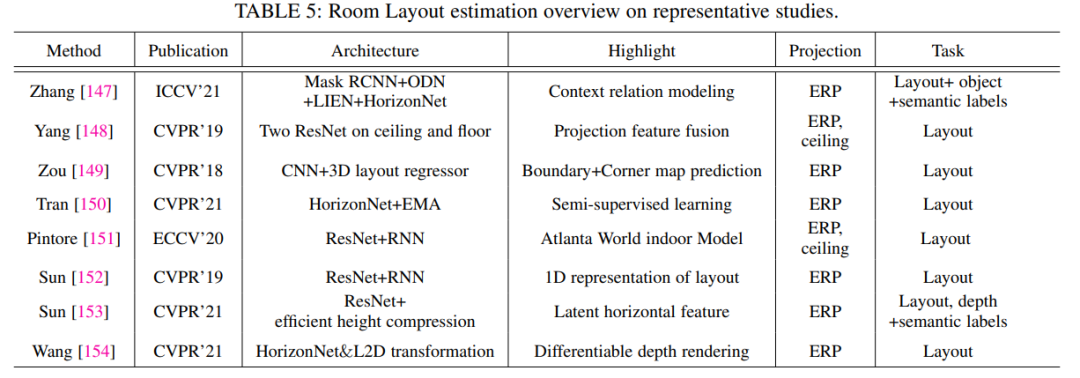
房間布局估計和重建包括多個子任務,例如布局估計、3D 對象檢測 和 3D 對象重建。這項綜合任務旨在促進基于單個 ODI 的整體場景理解。
4.3.2 立體匹配
人類雙眼視差取決于視網膜上投影之間的差異,即球體投影而不是平面投影。因此,ODI上的立體匹配更類似于人類視覺系統。在Seuffert等人的工作中,他們討論了全向失真對基于CNN的方法的影響,并比較了從透視和全向立體圖像預測的視差圖的質量。實驗結果表明,基于ODI的立體匹配對于機器人、AR/VR等多種應用更具優勢。一般立體匹配算法遵循四個步驟:(i)匹配成本計算,(ii)成本聚合,(iii)優化差異計算,以及(iv)差異細化。作為首個基于DNN的全向立體框架,SweepNet提出了一種寬基線立體系統,用于從采用超廣角FoV鏡頭的相機拍攝的一對圖像中計算匹配的成本圖,并在鉆機坐標系上使用全局球體掃描直接生成全向深度圖。
4.3.3 SLAM
SLAM是一個復雜的系統,采用多個攝像頭,例如單目,立體聲或RGB-D,結合移動代理上的傳感器來重建環境并實時估計代理姿勢。SLAM通常用于實時導航和現實增強,例如谷歌地球。立體信息,如關鍵點和dense或semi-dense深度圖引用,對于構建精確的現代SLAM系統是必不可少的。具體而言,與傳統的單目SLAM或多視角SLAM相比,全向數據由于FoV較大,可以提供更豐富的紋理和結構信息,基于全景相機的SLAM避免了不連續幀對周圍環境的影響,并享有完整定位和映射的技術優勢。Caruso等人提出了一種具有代表性的單目SLAM方法,直接闡述了圖像直接對準和像素距離濾波的全向相機。
4.4、人類行為理解
4.4.1 顯著性預測
最近,在深度學習進展的基礎上,ODI顯著性預測出現了幾個研究趨勢:(i)從2D傳統卷積到3D特定卷積;(ii) 從單一特征到多個特征;(iii) 從單一的企業資源規劃投入到多類型投入;(iv)從基于CNN的正常學習到新穎的學習策略。
4.4.2 注視行為
注視跟隨,也稱為注視估計,與檢測場景中的人們所看和吸收的內容有關。由于正常的透視圖像是NFoV捕獲的,因此注視目標總是在場景之外。ODI注視跟蹤是為了解決這個問題,因為ODI具有捕獲整個觀看環境的強大能力。以前的3D注視跟蹤方法可以直接檢測球體空間中人類受試者的注視目標,但忽略了ODI的場景信息,其執行的凝視跟隨效果不佳。Gaze360使用魚眼晶狀體校正來預處理圖像,收集了一個大型的凝視數據集。然而,由于球面投影引起的失真,遠距離凝視中的凝視目標可能不在人體主體的2D視線中,這在2D圖像中已不再相同。李等人提出了第一個ODI注視跟蹤框架,并收集了第一個ODI注視跟蹤數據集,稱為GazeFollow360。
挑戰和潛力:ODI 包含更豐富的上下文信息,可以促進對注視行為的理解。然而,仍然存在一些挑戰。首先,很少有特定于ODI的特定凝視跟蹤和凝視預測數據集。數據是基于深度學習的方法的“引擎”,因此收集定量和定性數據集是必要的。其次,由于球面投影類型中存在失真問題,未來的研究應考慮如何通過幾何變換來校正這種失真。最后,與普通2D圖像相比,ODI中的注視跟隨和注視預測都需要了解更廣泛的場景信息。應進一步探討空間背景關系。
4.4.3 視聽場景理解
由于ODV可以為觀察者提供對整個周圍環境的沉浸式理解,因此最近的研究重點是對ODV的視聽場景理解。由于它使觀眾能夠在各個方向上體驗聲音,因此ODV的空間無線電是全場景感知的重要提示。作為全向空間化問題的第一部作品,Morgado 等人設計了一個四塊架構,應用自監督學習來生成空間無線電,給定單聲道音頻和ODV作為聯合輸入。他們還提出了一個具有代表性的自我監督框架,用于從ODV的視聽空間內容中學習表示。
討論:基于上述分析,該研究領域的大多數工作將ERP圖像處理為普通2D圖像,而忽略了固有的失真。未來的研究可能會探索如何將ODI的球面成像特性和幾何信息與空間音頻線索更好地結合起來,以提供更逼真的視聽體驗。
4.4.4 視覺問答
視覺問答(VQA)是一項全面而有趣的任務,結合了計算機視覺(CV),自然語言處理(NLP)和知識表示$ &$推理(KR)。更寬的FoV ODI和ODV對于VQA研究更有價值和更具挑戰性,因為它們可以提供類似于人類視覺系統的立體空間信息。VQA 360,在~引用{chou2020可視化}中提出,是第一個關于ODI的VQA框架。它引入了一種基于CP的模型,具有多級融合和注意力擴散,以減少空間失真。同時,收集的VQA 360數據集為未來的發展提供了基準。此外,Yun等人提出了第一個基于ODV的VQA作品,全景AVQA,它結合了來自三種形式的信息:語言,音頻和ODV幀。變壓器網絡提取的融合多模態表示提供了對全向環境的整體語義理解。他們還在 ODV 上提供了第一個空間和音頻 VQA 數據集。
討論與挑戰:基于上述分析,基于ODI/ODV VQA的工作很少。與2D域中的方法相比,最大的困難是如何利用球面投影類型,例如二十面體和切線圖像。隨著2D領域中二十多個數據集和眾多有效網絡的發表,未來的研究可能會考慮如何有效地轉移知識,以學習更強大的DNN模型以實現全向視覺。
5、Novel Learning Strategies
5.1、無監督/半監督學習
由于全景注釋不足但成本高昂,因此會發生ODI數據稀缺問題。這個問題通常通過半監督學習或無監督學習來解決,它們可以利用豐富的未標記數據來增強泛化能力。對于半監督學習,Tran等人利用“平均教師”模型通過在同一場景中從標記和未標記的數據中學習來進行3D房間布局重建。對于無監督學習,Djilali等人提出了ODI顯著性預測的第一個框架。它計算來自多個場景的不同視圖之間的相互信息,并將對比學習與無監督學習相結合,以學習潛在表示。此外,無監督學習可以與監督學習相結合,以增強泛化能力。Yun等人提出將自監督學習與監督學習相結合,進行深度估計,緩解數據稀缺,增強穩定性。
5.2 GAN
為了減少透視圖像與ODI之間的域分歧,P2PDA和密集通道利用GAN框架并設計對抗性損失來促進語義分割。在圖像生成方面,BIPS提出了一個GAN框架,用于基于攝像頭和深度傳感器的任意配置來合成RGB-D室內全景圖。
5.3 注意機制
對于跨視圖地理定位,在Zhu等人中,ViT等人用于刪除無信息的圖像補丁,并將信息性圖像補丁增強到更高分辨率。這種注意力引導的非均勻裁剪策略可以節省計算成本,將其重新分配給信息補丁以提高性能。在無監督顯著性預測中采用了類似的策略。在Abdelaziz等人提出的工作中,采用自我注意模型在兩個輸入之間建立空間關系并選擇充分不變的特征。
5.4 遷移學習
有很多工作可以轉移從源2D域學到的知識,以促進ODI域中學習許多視覺任務,例如,語義分割和深度估計。從透視圖像在預訓練的模型上設計可變形的CNN或MLP可以增強ODI在眾多任務中的模型能力,例如,語義分割,視頻超分辨率,深度估計和光流估計。但是,這些方法嚴重依賴于手工制作的模塊,這些模塊缺乏針對不同場景的泛化能力。無監督域適配旨在通過減少透視圖像和ODI之間的域間隙,將知識從透視域轉移到ODI域。P2PDA和BendingRD減小透視圖像與ODI之間的域間隙,有效獲得ODI的偽密集標簽。知識提煉(KD)是另一種有效的技術,它將知識從繁瑣的教師模型中轉移出來,學習緊湊的學生模型,同時保持學生的表現。然而,我們發現很少有作品將KD應用于全向視覺任務。在語義分割中,ECANets通過來自世界各地的各種全景圖執行數據提煉。
5.5 強化學習
在顯著性預測中,MaiXu等人通過將頭部運動的軌跡解釋為離散動作來預測頭部注視,并得到正確策略的獎勵。此外,在對象檢測中,Pais等人通過考慮3D邊界框及其在圖像中的相應失真投影來提供行人在現實世界中的位置。DRL的另一個應用是在LAUNet中基于像素密度自適應地選擇放大因子,解決了ERP中像素密度分布不均勻的問題。
5.6 多任務學習
在相關任務之間共享表示可以增加模型的泛化能力,并提高所有涉及任務的性能。MT-DNN將顯著性檢測任務與視口檢測任務相結合,預測每幀的視口顯著性圖,提高ODV的顯著性預測性能。DeepPanoContext通過共同預測物體形狀、3D姿勢、語義類別和房間布局,實現全景場景理解。同樣,HoHoNet提出了一個潛在的水平特征(LHFeat)和一種新穎的視界到密集模塊來完成各種任務,包括房間布局重建和每像素密集預測任務,例如深度估計,語義分割。
6、Applications
6.1、AR 和VR
隨著技術的進步和交互場景需求的不斷增長,AR和VR近年來發展迅速。VR旨在模擬真實或虛構的環境,參與者可以通過感知和與環境互動來獲得身臨其境的體驗和個性化的內容。憑借在ODI中捕獲整個周圍環境的優勢,360 VR / AR有助于開發沉浸式體驗。
6.2、機器人導航
除了上文中提到的SLAM之外,我們還進一步討論了ODI/ODV在機器人導航領域的相關應用,包括遠程呈現系統、監控和基于DL的優化方法。
遠程呈現系統旨在克服空間限制,使人們能夠遠程訪問并相互交流。ODI/ODV通過提供更逼真、更自然的場景而越來越受歡迎,特別是在開放環境的戶外活動中. Zhang等人提出了一種基于ODV的遠程呈現系統的原型,以支持更自然的交互和遠程環境探索,在遠程環境中的真實行走可以同時控制機器人平臺的相關運動。出于安全目的,監控旨在取代人類,其中校準對于敏感數據至關重要。因此,普迪克斯提出了一種針對障礙物檢測和避障的安全導航系統,并采用校準設計來獲得適當的距離和方向。與NFoV圖像相比,全景圖像可以通過在單次拍攝中提供完整的FoV來顯著降低計算成本。此外,Ran等人提出了一個基于未校準的360相機的輕量級框架。該框架可以通過將其制定為一系列分類任務來準確估計航向,并通過保存校準和校正過程來避免冗余計算。
6.3、自動駕駛
自動駕駛需要對周圍環境有充分的了解,這是全景視覺所擅長的。一些作品專注于為自動駕駛建立360平臺。具體而言,依托Sun等人的工作,利用立體相機、偏振相機和全景相機,形成多模態視覺系統,捕捉全向景觀。除了該平臺之外,用于自動駕駛的公共全向數據集的出現對于深度學習方法的應用至關重要。Caeser等人是第一個引入相關數據集,該數據集攜帶了六個攝像頭,五個雷達和一個激光雷達。所有設備都帶有360 FoV。最近,OpenMP 數據集被六臺攝像機和四臺激光雷達捕獲,其中包含復雜環境中的場景,例如,過度曝光或黑暗的城市地區。Kumar等人提出了一個多任務視覺感知網絡,該網絡由自動駕駛中的六項重要任務組成:深度估計,視覺里程測量,感性分割,運動分割,物體檢測和鏡頭污染檢測。重要的是,由于實時性能對于自動駕駛至關重要,并且車輛中的嵌入系統通常具有有限的內存和計算資源,因此輕量級DNN模型在實踐中更受青睞。
7、Discussion and New Perspectives
7.1、投影格式的缺點
ERP是最流行的投影格式,因為它的平面格式的FoV很寬。ERP面臨的主要挑戰是向兩極的拉伸變形日益嚴重。因此,提出了許多針對失真的特定卷積濾波器的設計方法。相比之下,CP 和切線(TP)圖像通過將球面投影到多個平面上是無失真的投影格式。它們與透視圖像相似,因此可以充分利用平面域中的許多預訓練模型和數據集。然而,CP和切線圖像受到更高的計算成本,差異和不連續性的挑戰。我們總結了利用CP和切線圖像的兩個潛在方向:(i)冗余計算成本是由投影平面之間的大重疊區域引起的。但是,像素密度因不同的采樣位置而異。通過強化學習為密集區域(例如赤道)分配更多資源,為稀疏區域(例如極點)分配更少的資源,計算效率更高。(二) 目前,不同的投影平面往往是并行處理的,缺乏全球一致性。為了克服不同局部平面之間的差異,探索一個以ERP為輸入或基于注意力的變壓器來構建非局部依賴關系的分支是有效的。
7.2、數據高效學習
深度學習方法面臨的一個挑戰是需要具有高質量注釋的大規模數據集。然而,對于全向視覺,構建大規模數據集既昂貴又乏味。因此,有必要探索更高效的數據方法。一個有希望的方向是將從在標記的2D數據集上訓練的模型中學到的知識轉移到在未標記的全景數據集上訓練的模型。具體而言,可以應用域適應方法來縮小透視圖像與ODI之間的差距。KD也是一種有效的解決方案,它將學習到的特征信息從繁瑣的視角DNN模型轉移到學習ODI數據的緊湊DNN模型。最后,最近的自我監督方法,eg,Yan等人證明了預訓練的有效性,而不需要額外的訓練注釋。
7.3、物理約束
透視圖像的現有方法在推斷全球場景和看不見的區域的光照方面受到限制。由于ODI的FoV很寬,可以捕獲完整的周圍環境場景。此外,反射率可以根據照明與場景結構之間的物理約束,基于照明來揭示反射率。因此,未來的方向可以聯合利用計算機圖形學(如光線追蹤)和渲染模型來幫助計算反射率,這反過來又有助于更高精度的全局照明估計。此外,基于照明運輸理論處理和渲染ODI是有希望的。
7.4、多模態全景視覺
它指的是使用相同的DNN模型從不同類型的模態(例如,用于視覺問答的文本圖像,視聽場景理解)學習表示的過程。對于世界性愿景來說,這是一個有希望但又切實可行的方向。例如,Beltran等人引入了一個基于視覺和 LiDAR 信息的多模態感知框架,用于 3D 對象檢測和跟蹤。但是,這方面的現有工作將ODI視為透視圖像,而忽略了ODI中固有的失真。未來的工作可能會探索如何利用ODI的優勢,例如,完整的FoV,以協助其他模式的表示。重要的是,不同方式的獲取有明顯的差異。例如,捕獲 RGB 圖像比深度圖容易得多。因此,一個有希望的方向是從一種模式中提取可用信息,然后通過多任務學習,KD等轉移到另一種模式。然而,應考慮不同方式之間的差異,以確保多模式的一致性。
7.5、潛在的對抗性攻擊
很少有研究關注對全向視覺模型的對抗性攻擊。Zhang等人提出了第一種具有代表性的攻擊方法,通過僅擾動從ODI渲染的一個切線圖像來欺騙DNN模型。建議的攻擊是稀疏的,因為它只干擾了輸入ODI的一小部分。因此,他們進一步提出了一種位置搜索方法來搜索球面上的切點。該方向存在許多有前途但具有挑戰性的研究問題,例如,分析ODI不同DNN模型之間攻擊的泛化能力,網絡架構和訓練方法的白盒攻擊以及攻擊防御。
7.6、Metaverse的潛力
Metaverse旨在創建一個包含大規模高保真數字模型的虛擬世界,用戶可以在其中自由創建內容并獲得身臨其境的互動體驗。元宇宙由AR和VR頭顯促進,其中ODI由于完整的FoV而受到青睞。因此,一個潛在的方向是從ODI生成高保真2D/3D模型,并詳細模擬真實世界的對象和場景。此外,為了幫助用戶獲得身臨其境的體驗,分析和理解人類行為的技術(例如,注視跟隨,顯著性預測)可以在將來進一步探索和整合。
7.4、智慧城市的潛力
智慧城市專注于使用各種設備從城市收集數據,并利用數據中的信息來提高效率,安全性和便利性等。利用街景圖像中ODI的特性,可以促進城市形態比較的發展。如第前面所述,一個有希望的方向是將街景圖像轉換為衛星視圖圖像以進行城市規劃。
8、Discussion and New Perspectives
在本次調查中,我們全面回顧并分析了深度學習方法在全向視覺方面的最新進展。我們首先介紹了全向成像的原理,卷積方法和數據集。然后,我們提供了DL方法的分層和結構分類。針對分類學中的每項任務,我們總結了當前的研究現狀,并指出了其中的機遇和挑戰。我們進一步回顧了新的學習策略和應用。在構建了當前方法之間的聯系之后,我們討論了需要解決的關鍵問題,并指出了有希望的未來研究方向。我們希望這項工作能為研究人員提供一些見解,并促進社區的進步。
審核編輯:郭婷
-
機器人
+關注
關注
212文章
29328瀏覽量
211094 -
自動駕駛
+關注
關注
788文章
14151瀏覽量
169041 -
深度學習
+關注
關注
73文章
5550瀏覽量
122376
原文標題:港科大最新綜述:深度學習在全景視覺上的應用
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
深度自然匿名化:隱私保護與視覺完整性并存的未來!

VR全景拍攝的實用價值和未來發展
【詳解】FPGA:深度學習的未來?
深度學習在汽車中的應用
未來語音接口的展望
深度學習與傳統計算機視覺簡介
深度學習介紹
全景視覺SNS社交新媒體
人工智能深度學習的未來展望
探究深度學習在目標視覺檢測中的應用與展望
計算機視覺中的九種深度學習技術






 工商網監
工商網監

評論