") 如何評(píng)估CPU、內(nèi)存以及I/O它們性能的命令
如何評(píng)估CPU、內(nèi)存以及I/O它們性能的命令
操作系統(tǒng)作為所有程序的載體,對(duì)應(yīng)用的性能影響是非常重要的。然而計(jì)算機(jī)各個(gè)組件之間的速度,是非常不均衡的。拿CPU和硬盤的速度來(lái)說(shuō),比兔子和烏龜?shù)乃俣炔顒e還要大。
下面將簡(jiǎn)單的介紹CPU、內(nèi)存、I/O的一些基本知識(shí),以及一些如何評(píng)估它們性能的命令。
1.CPU
首先介紹計(jì)算機(jī)中最重要的計(jì)算組件:中央處理器。一般我們可以通過(guò)top命令來(lái)觀測(cè)它的性能。
1.1 top命令
top命令可用于觀測(cè)CPU的一些運(yùn)行指標(biāo)。如圖,進(jìn)入top命令之后,按1鍵即可看到每核CPU的詳細(xì)狀況。
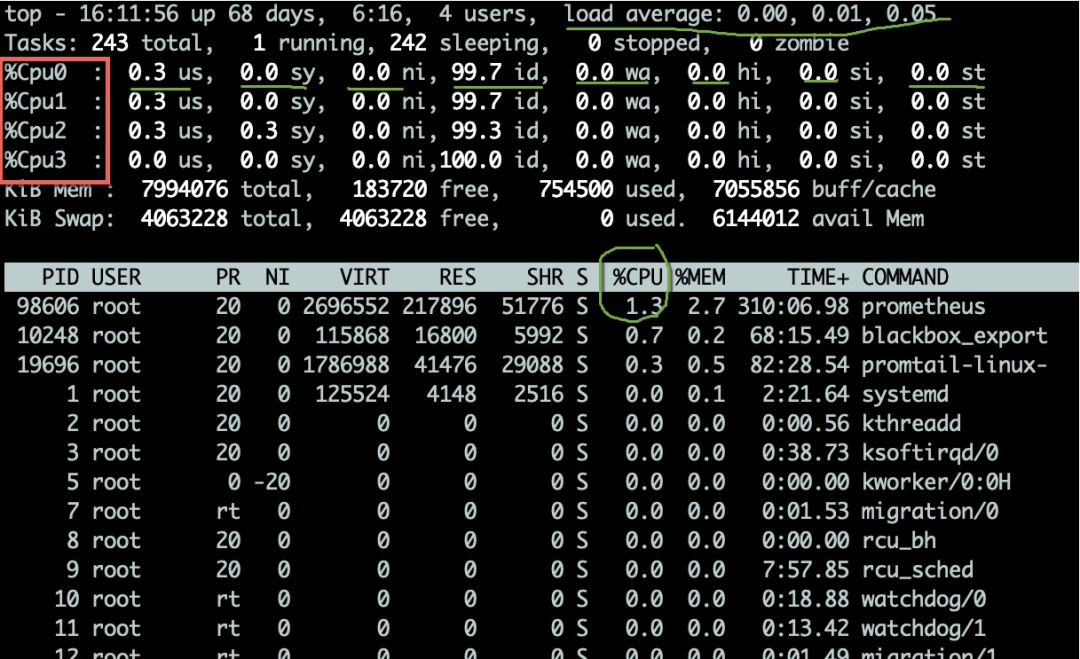
CPU的使用有多個(gè)維度的指標(biāo),以下分別說(shuō)明一下:
us用戶態(tài)所占用的CPU百分比。
sy內(nèi)核態(tài)所占用的CPU百分比。如果這個(gè)值過(guò)高,需要配合vmstat命令,查看是否是上下文切換是否頻繁。
ni高優(yōu)先級(jí)應(yīng)用所占用的CPU百分比。
wa等待I/O設(shè)備所占用的CPU百分比。如果這個(gè)值非常高,輸入輸出設(shè)備可能存在非常明顯的瓶頸。
hi硬件中斷所占用的CPU百分比。
si軟中斷所占用的CPU百分比。
st這個(gè)一般發(fā)生在虛擬機(jī)上,指的是虛擬CPU等待實(shí)際CPU時(shí)間的百分比。如果這個(gè)值過(guò)大,則你的宿主機(jī)壓力可能過(guò)大。如果你是云主機(jī),則你的服務(wù)商可能存在超賣。
id空閑CPU百分比。
一般的,我們比較關(guān)注空閑CPU的百分比,它可以從整體上體現(xiàn)CPU的利用情況。
1.2 什么是負(fù)載
我們還要評(píng)估CPU任務(wù)執(zhí)行的排隊(duì)情況,這些值就是負(fù)載(load)。top命令,顯示的CPU負(fù)載,分別是最近1分鐘、5分鐘、15分鐘的數(shù)值。
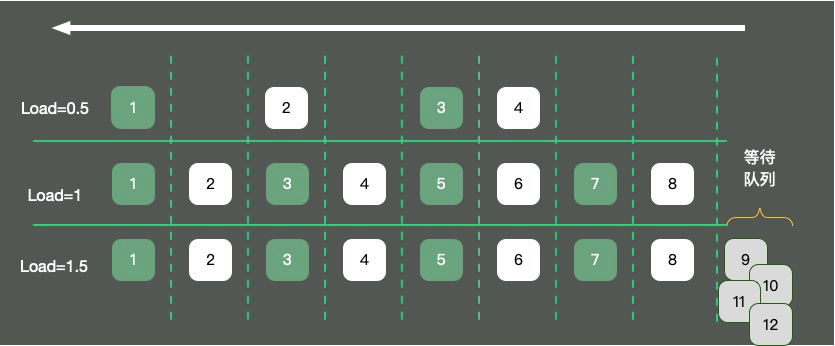
如圖,以單核操作系統(tǒng)為例,將CPU資源抽象成一條單向行駛的馬路。則會(huì)發(fā)生三種情況:
馬路上的車只有4輛,車輛暢通無(wú)阻,load大約是0.5。
馬路上的車有8輛,正好能首尾相接安全通過(guò),此時(shí)load大約為1。
馬路上的車有12輛,除了在馬路上的8輛車,還有4輛等在馬路外面,需要排隊(duì)。此時(shí)load大約為1.5。
那load為1代表的是啥?針對(duì)這個(gè)問(wèn)題,誤解還是比較多的。
很多同學(xué)認(rèn)為,load達(dá)到1,系統(tǒng)就到了瓶頸,這不完全正確。load的值和cpu核數(shù)息息相關(guān)。舉例如下:
單核的負(fù)載達(dá)到1,總load的值約1。
雙核的每核負(fù)載都達(dá)到1,總load約2。
四核的每核負(fù)載都達(dá)到1,總load約為4。
所以,對(duì)于一個(gè)load到了10,卻是16核的機(jī)器,你的系統(tǒng)還遠(yuǎn)沒(méi)有達(dá)到負(fù)載極限。通過(guò)uptime命令,同樣能夠看到負(fù)載情況。
1.3 vmstat
要看CPU的繁忙程度,還可以通過(guò)vmstat命令。下面是vmstat命令的一些輸出信息。
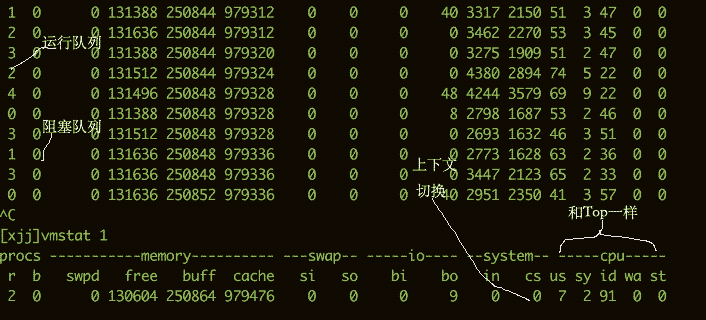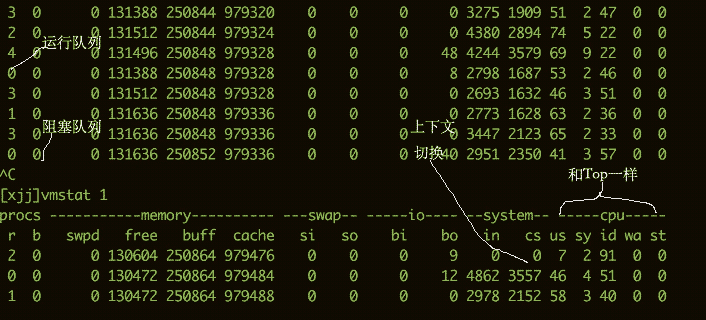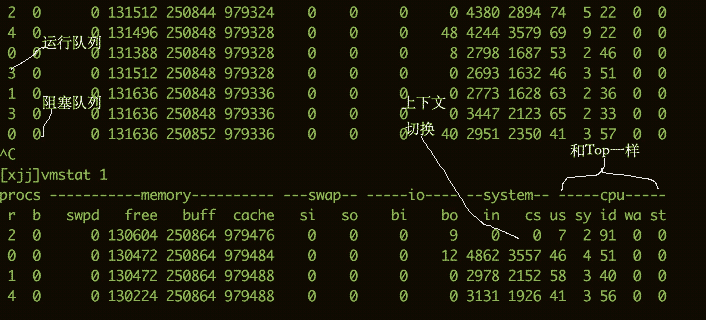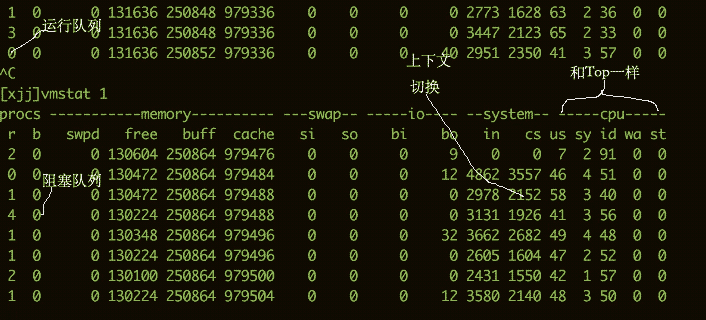
我們比較關(guān)注的有下面幾列:
b存在于等待隊(duì)列的內(nèi)核線程數(shù)目,比如等待I/O等。數(shù)字過(guò)大則cpu太忙。
cs代表上下文切換的數(shù)量。如果頻繁的進(jìn)行上下文切換,就需要考慮是否是線程數(shù)開的過(guò)多。
si/so顯示了交換分區(qū)的一些使用情況,交換分區(qū)對(duì)性能的影響比較大,需要格外關(guān)注。
$vmstat1 procs---------memory-------------swap-------io-----system--------cpu----- rbswpdfreebuffcachesisobiboincsussyidwast 3400200889792737085918280005610961300 320020088992073708591860000592132844282981100 320020089011273708591860000095012154991000 32002008895687371259185600048119002459990000 3200200890208737125918600000158984840981100 ^C
2.內(nèi)存
2.1 觀測(cè)命令
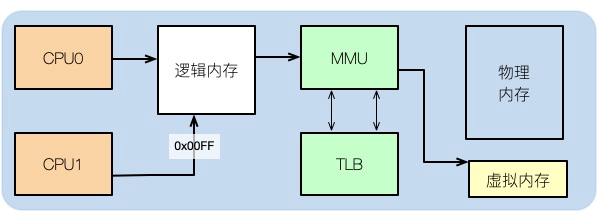
要想了解內(nèi)存對(duì)性能的一些影響,就需要從操作系統(tǒng)層面來(lái)看一下內(nèi)存的分布。
我們?cè)谄匠懲甏a后,比如寫了一個(gè)C++程序,如果去查看它的匯編,可以看到其中的內(nèi)存地址,并不是實(shí)際的物理內(nèi)存地址。
那么應(yīng)用程序所使用的,就是邏輯內(nèi)存,這個(gè)學(xué)過(guò)計(jì)算機(jī)組成結(jié)構(gòu)的同學(xué)都有了解。
邏輯地址可以映射到物理內(nèi)存和虛擬內(nèi)存上。比如你的物理內(nèi)存是8GB,分配了16GB的SWAP分區(qū),那么應(yīng)用可用的總內(nèi)存就是24GB。
從top命令可以看到幾列數(shù)據(jù),注意方塊括起來(lái)的三個(gè)區(qū)域,解釋如下:
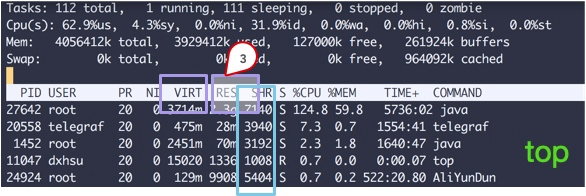
VIRT這里就是虛擬內(nèi)存,一般比較大,不用做過(guò)多關(guān)注。
RES我們平常關(guān)注的就是這一列的數(shù)值,它代表了進(jìn)程實(shí)際占用的內(nèi)存。平常在做監(jiān)控時(shí),也主要是監(jiān)控這個(gè)數(shù)值。
SHR指的是共享內(nèi)存,比如可以復(fù)用的一些so文件等。
2.2 CPU緩存
由于CPU核內(nèi)存之間的速度差異是非常大的,解決方式就是加入高速緩存。其實(shí),這些高速緩存,往往會(huì)有多層,如下圖。
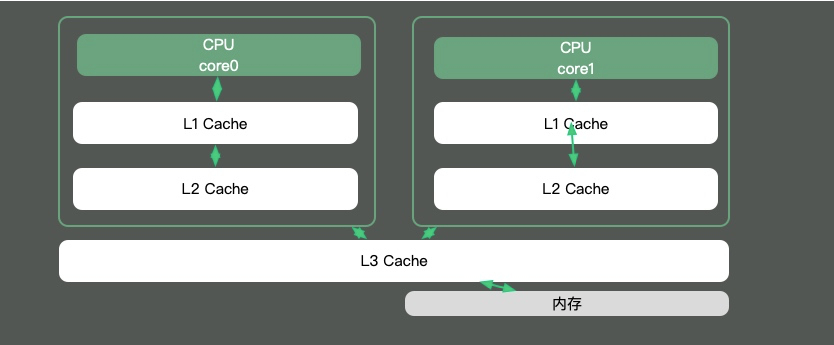
Java有大部分知識(shí)點(diǎn)是圍繞多線程的,那是因?yàn)椋绻粋€(gè)線程的時(shí)間片跨越了多個(gè)CPU,那么就會(huì)存在同步問(wèn)題。
在Java中,最典型的和CPU緩存相關(guān)的知識(shí)點(diǎn),就是并發(fā)編程中,針對(duì)Cache line的偽共享(false sharing)問(wèn)題。
偽共享是指:在這些高速緩存中,是以緩存行為單位進(jìn)行存儲(chǔ)的。哪怕你修改了緩存行中一個(gè)很小很小的數(shù)據(jù),它都會(huì)整個(gè)的刷新。所以,當(dāng)多線程修改一些變量的值時(shí),如果這些變量在同一個(gè)緩存行里,就會(huì)造成頻繁刷新,無(wú)意中影響彼此的性能。
通過(guò)以下命令即可看到當(dāng)前操作系統(tǒng)的緩存行大小。
cat/sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
通過(guò)以下命令可以看到不同層次的緩存大小。
[root@localhost~]#cat/sys/devices/system/cpu/cpu0/cache/index1/size 32K [root@localhost~]#cat/sys/devices/system/cpu/cpu0/cache/index2/size 256K [root@localhost~]#cat/sys/devices/system/cpu/cpu0/cache/index3/size 20480K
在JDK8以上的版本,通過(guò)開啟參數(shù)-XX:-RestrictContended,就可以使用注解@sun.misc.Contended進(jìn)行補(bǔ)齊,來(lái)避免偽共享的問(wèn)題。在并發(fā)優(yōu)化中,我們?cè)僭敿?xì)講解。
2.3 HugePage
回頭看我們最長(zhǎng)的那副圖,上面有一個(gè)叫做TLB的組件,它的速度雖然高,但容量也是有限的。這就意味著,如果物理內(nèi)存很大,那么映射表的條目將會(huì)非常多,會(huì)影響CPU的檢索效率。
默認(rèn)內(nèi)存是以4K的page來(lái)管理的。如圖,為了減少映射表的條目,可采取的辦法只有增加頁(yè)的尺寸。像這種將Page Size加大的技術(shù),就是Huge Page。
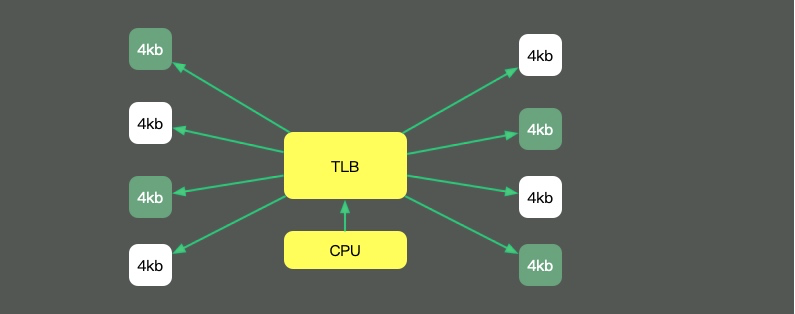
HugePage有一些副作用,比如競(jìng)爭(zhēng)加劇,Redis還有專門的研究(https://redis.io/topics/latency) ,但在一些大內(nèi)存的機(jī)器上,開啟后會(huì)一定程度上增加性能。
2.4 預(yù)先加載
另外,一些程序的默認(rèn)行為,也會(huì)對(duì)性能有所影響。比如JVM的-XX:+AlwaysPreTouch參數(shù)。默認(rèn)情況下,JVM雖然配置了Xmx、Xms等參數(shù),但它的內(nèi)存在真正用到時(shí),才會(huì)分配。
但如果加上這個(gè)參數(shù),JVM就會(huì)在啟動(dòng)的時(shí)候,把所有的內(nèi)存預(yù)先分配。這樣,啟動(dòng)時(shí)雖然慢了些,但運(yùn)行時(shí)的性能會(huì)增加。
3.I/O
3.1 觀測(cè)命令
I/O設(shè)備可能是計(jì)算機(jī)里速度最差的組件了。它指的不僅僅是硬盤,還包括外圍的所有設(shè)備。
硬盤有多慢呢?我們不去探究不同設(shè)備的實(shí)現(xiàn)細(xì)節(jié),直接看它的寫入速度(數(shù)據(jù)未經(jīng)過(guò)嚴(yán)格測(cè)試,僅作參考)。
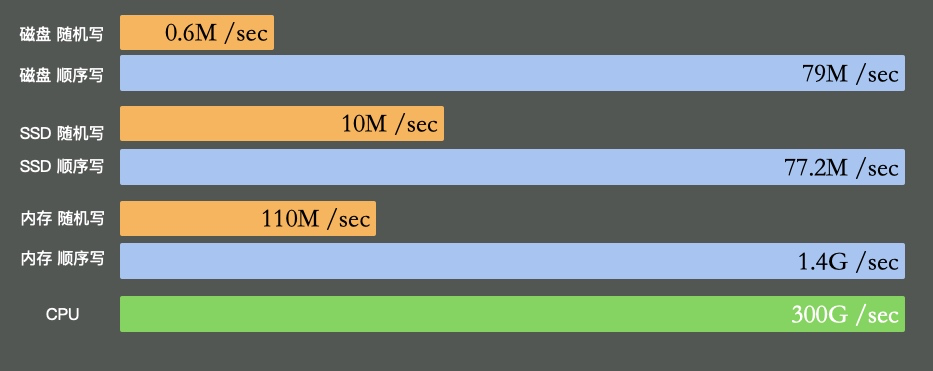
可以看到普通磁盤的隨機(jī)寫和順序?qū)懴嗖钍欠浅4蟮摹6S機(jī)寫完全和cpu內(nèi)存不在一個(gè)數(shù)量級(jí)。
緩沖區(qū)依然是解決速度差異的唯一工具,在極端情況比如斷電等,就產(chǎn)生了太多的不確定性。這些緩沖區(qū),都容易丟。
最能體現(xiàn)I/O繁忙程度的,就是top命令和vmstat命令中的wa%。如果你的應(yīng)用,寫了大量的日志,I/O wait就可能非常的高。
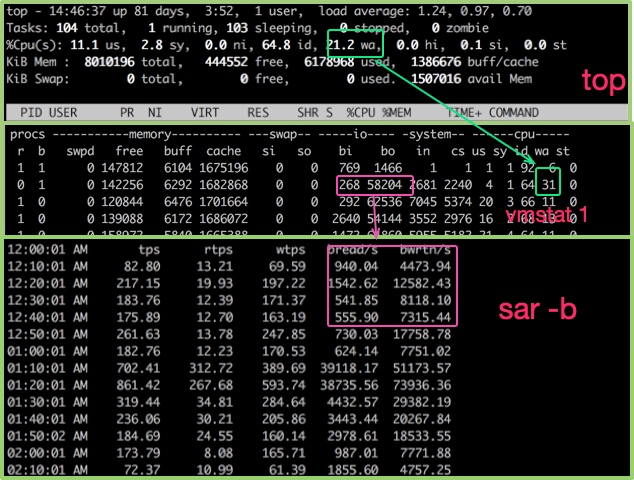
對(duì)于硬盤來(lái)說(shuō),可以使用iostat命令來(lái)查看具體的硬件使用情況。只要%util超過(guò)了80%,你的系統(tǒng)基本上就跑不動(dòng)了。
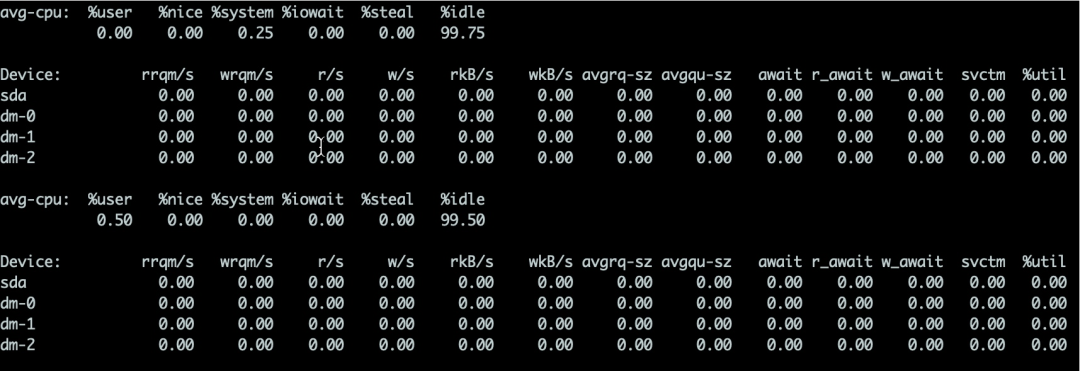
詳細(xì)介紹如下:
%util最重要的判斷參數(shù)。一般地,如果該參數(shù)是100%表示設(shè)備已經(jīng)接近滿負(fù)荷運(yùn)行了
Device表示發(fā)生在哪塊硬盤。如果你有多快,則會(huì)顯示多行
avgqu-sz這個(gè)值是請(qǐng)求隊(duì)列的飽和度,也就是平均請(qǐng)求隊(duì)列的長(zhǎng)度。毫無(wú)疑問(wèn),隊(duì)列長(zhǎng)度越短越好。
await響應(yīng)時(shí)間應(yīng)該低于5ms,如果大于10ms就比較大了。這個(gè)時(shí)間包括了隊(duì)列時(shí)間和服務(wù)時(shí)間
svctm 表示平均每次設(shè)備I/O操作的服務(wù)時(shí)間。如果svctm的值與await很接近,表示幾乎沒(méi)有I/O等待,磁盤性能很好,如果await的值遠(yuǎn)高于svctm的值,則表示I/O隊(duì)列等待太長(zhǎng),系統(tǒng)上運(yùn)行的應(yīng)用程序?qū)⒆兟?/p>
3.2 零拷貝
kafka比較快的一個(gè)原因就是使用了zero copy。所謂的Zero copy,就是在操作數(shù)據(jù)時(shí), 不需要將數(shù)據(jù)buffer從一個(gè)內(nèi)存區(qū)域拷貝到另一個(gè)內(nèi)存區(qū)域。因?yàn)樯倭艘淮蝺?nèi)存的拷貝, CPU的效率就得到提升。
我們來(lái)看一下它們之間的區(qū)別:
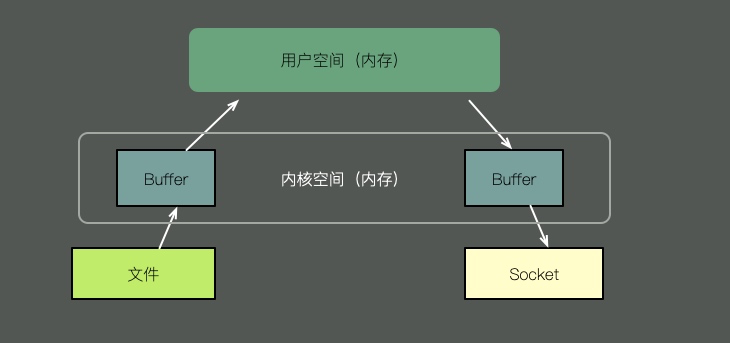
要想將一個(gè)文件的內(nèi)容通過(guò)socket發(fā)送出去,傳統(tǒng)的方式需要經(jīng)過(guò)以下步驟:
將文件內(nèi)容拷貝到內(nèi)核空間。
將內(nèi)核空間的內(nèi)容拷貝到用戶空間內(nèi)存,比如Java應(yīng)用。
用戶空間將內(nèi)容寫入到內(nèi)核空間的緩存中。
socket讀取內(nèi)核緩存中的內(nèi)容,發(fā)送出去。
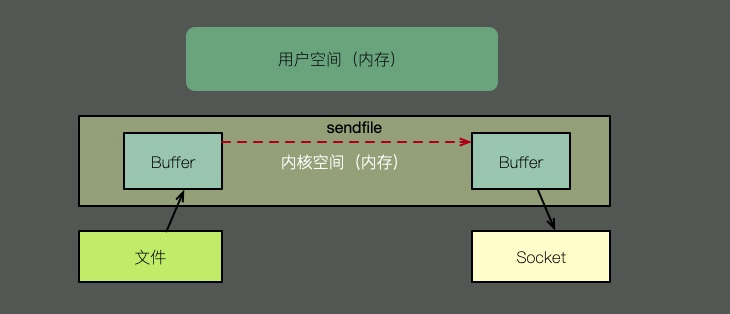
零拷貝又多種模式,我們拿sendfile來(lái)說(shuō)明。如上圖,在內(nèi)核的支持下,零拷貝少了一個(gè)步驟,那就是內(nèi)核緩存向用戶空間的拷貝。即節(jié)省了內(nèi)存,也節(jié)省了CPU的調(diào)度時(shí)間,效率很高。
除了iotop、iostat這些命令外,sar命令可以方便的看到網(wǎng)絡(luò)運(yùn)行狀況,下面是一個(gè)簡(jiǎn)單的示例,用于描述入網(wǎng)流量和出網(wǎng)流量。
$sar-nDEV1 Linux3.13.0-49-generic(titanclusters-xxxxx)07/14/2015_x86_64_(32CPU) 1248AMIFACErxpck/stxpck/srxkB/stxkB/srxcmp/stxcmp/srxmcst/s%ifutil 1249AMeth018763.005032.0020686.42478.300.000.000.000.00 1249AMlo14.0014.001.361.360.000.000.000.00 1249AMdocker00.000.000.000.000.000.000.000.00 1249AMIFACErxpck/stxpck/srxkB/stxkB/srxcmp/stxcmp/srxmcst/s%ifutil 1250AMeth019763.005101.0021999.10482.560.000.000.000.00 1250AMlo20.0020.003.253.250.000.000.000.00 1250AMdocker00.000.000.000.000.000.000.000.00 ^C
當(dāng)然,我們可以選擇性的只看TCP的一些狀態(tài)。
$sar-nTCP,ETCP1 Linux3.13.0-49-generic(titanclusters-xxxxx)07/14/2015_x86_64_(32CPU) 1219AMactive/spassive/siseg/soseg/s 1220AM1.000.0010233.0018846.00 1219AMatmptf/sestres/sretrans/sisegerr/sorsts/s 1220AM0.000.000.000.000.00 1220AMactive/spassive/siseg/soseg/s 1221AM1.000.008359.006039.00 1220AMatmptf/sestres/sretrans/sisegerr/sorsts/s 1221AM0.000.000.000.000.00 ^C
5.End
不要寄希望于這些指標(biāo),能夠立刻幫助我們定位性能問(wèn)題。這些工具,只能夠幫我們大體猜測(cè)發(fā)生問(wèn)題的地方,它對(duì)性能問(wèn)題的定位,只是起到輔助作用。想要分析這些bottleneck,需要收集更多的信息。
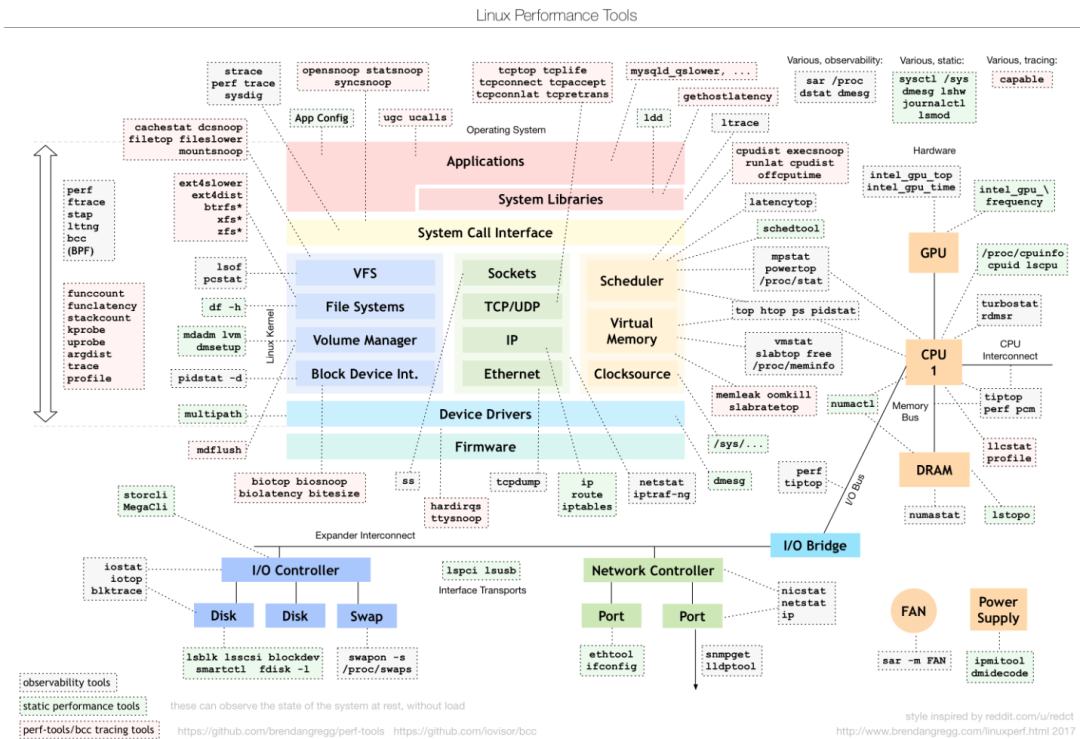
想要獲取更多的性能數(shù)據(jù),就不得不借助更加專業(yè)的工具,比如基于eBPF的BCC工具,這些牛x的工具我們將在其他文章里展開。讀完本文,希望你能夠快速的了解Linux的運(yùn)行狀態(tài),對(duì)你的系統(tǒng)多一些掌控。
審核編輯:劉清
-
cpu
+關(guān)注
關(guān)注
68文章
10947瀏覽量
213895 -
Linux
+關(guān)注
關(guān)注
87文章
11373瀏覽量
211294 -
操作系統(tǒng)
+關(guān)注
關(guān)注
37文章
6941瀏覽量
124155
原文標(biāo)題:61秒,摸透Linux的健康狀態(tài)!
文章出處:【微信號(hào):良許Linux,微信公眾號(hào):良許Linux】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
virtio I/O通信流程及設(shè)備框架的實(shí)現(xiàn)
UBIFS損耗均衡對(duì)系統(tǒng)I/O性能的影響
Linux系統(tǒng)中網(wǎng)絡(luò)I/O性能改進(jìn)方法的研究
基于Linux下的/O端口和I/O內(nèi)存詳解
超全的SPDK性能評(píng)估指南
Linux驅(qū)動(dòng)技術(shù)之一:訪問(wèn)I/O內(nèi)存
Linux查看資源使用情況和性能調(diào)優(yōu)常用的命令
EVAL-ADP5588:ADP5588鍵盤I/O擴(kuò)展器評(píng)估板

單片機(jī)I/O控制方式





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論