


現(xiàn)在,機(jī)器學(xué)習(xí)有很多算法。如此多的算法,可能對(duì)于初學(xué)者來(lái)說(shuō),是相當(dāng)不堪重負(fù)的。今天,我們將簡(jiǎn)要介紹 10 種最流行的機(jī)器學(xué)習(xí)算法,這樣你就可以適應(yīng)這個(gè)激動(dòng)人心的機(jī)器學(xué)習(xí)世界了!
01 線性回歸
線性回歸(Linear Regression)可能是最流行的機(jī)器學(xué)習(xí)算法。線性回歸就是要找一條直線,并且讓這條直線盡可能地?cái)M合散點(diǎn)圖中的數(shù)據(jù)點(diǎn)。它試圖通過(guò)將直線方程與該數(shù)據(jù)擬合來(lái)表示自變量(x 值)和數(shù)值結(jié)果(y 值)。然后就可以用這條線來(lái)預(yù)測(cè)未來(lái)的值!
這種算法最常用的技術(shù)是最小二乘法(Least of squares)。這個(gè)方法計(jì)算出最佳擬合線,以使得與直線上每個(gè)數(shù)據(jù)點(diǎn)的垂直距離最小。總距離是所有數(shù)據(jù)點(diǎn)的垂直距離(綠線)的平方和。其思想是通過(guò)最小化這個(gè)平方誤差或距離來(lái)擬合模型。
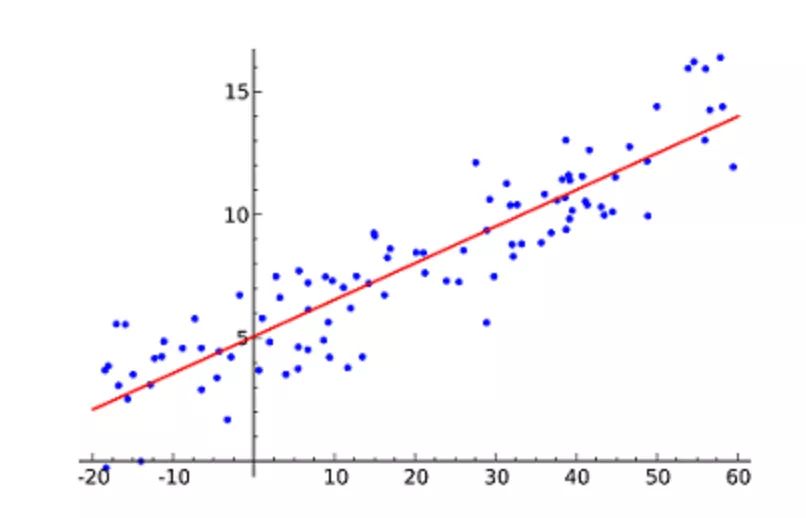
例如,簡(jiǎn)單線性回歸,它有一個(gè)自變量(x 軸)和一個(gè)因變量(y 軸)。
02 邏輯回歸
邏輯回歸(Logistic regression)與線性回歸類似,但它是用于輸出為二進(jìn)制的情況(即,當(dāng)結(jié)果只能有兩個(gè)可能的值)。對(duì)最終輸出的預(yù)測(cè)是一個(gè)非線性的 S 型函數(shù),稱為 logistic function, g()。
這個(gè)邏輯函數(shù)將中間結(jié)果值映射到結(jié)果變量 Y,其值范圍從 0 到 1。然后,這些值可以解釋為 Y 出現(xiàn)的概率。S 型邏輯函數(shù)的性質(zhì)使得邏輯回歸更適合用于分類任務(wù)。
邏輯回歸曲線圖,顯示了通過(guò)考試的概率與學(xué)習(xí)時(shí)間的關(guān)系。
03 決策樹(shù)
決策樹(shù)(Decision Trees)可用于回歸和分類任務(wù)。
在這一算法中,訓(xùn)練模型通過(guò)學(xué)習(xí)樹(shù)表示(Tree representation)的決策規(guī)則來(lái)學(xué)習(xí)預(yù)測(cè)目標(biāo)變量的值。樹(shù)是由具有相應(yīng)屬性的節(jié)點(diǎn)組成的。
在每個(gè)節(jié)點(diǎn)上,我們根據(jù)可用的特征詢問(wèn)有關(guān)數(shù)據(jù)的問(wèn)題。左右分支代表可能的答案。最終節(jié)點(diǎn)(即葉節(jié)點(diǎn))對(duì)應(yīng)于一個(gè)預(yù)測(cè)值。
每個(gè)特征的重要性是通過(guò)自頂向下方法確定的。節(jié)點(diǎn)越高,其屬性就越重要。
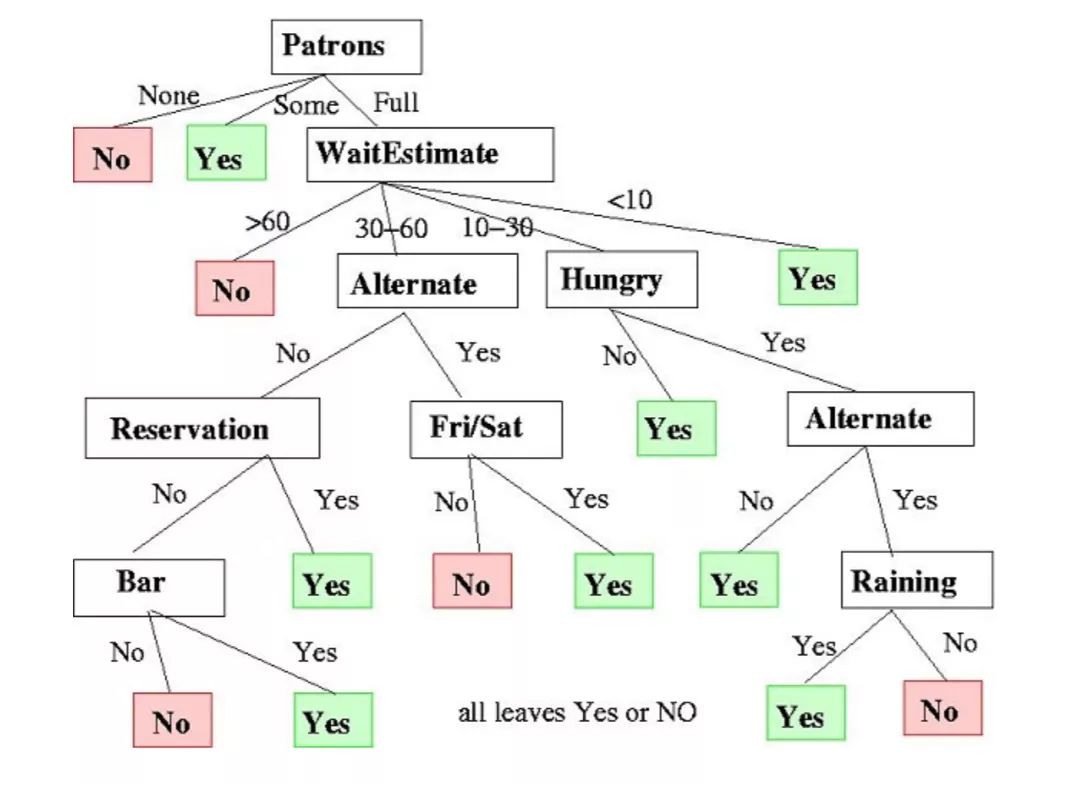
決定是否在餐廳等候的決策樹(shù)示例。
04 樸素貝葉斯
樸素貝葉斯(Naive Bayes)是基于貝葉斯定理。它測(cè)量每個(gè)類的概率,每個(gè)類的條件概率給出 x 的值。這個(gè)算法用于分類問(wèn)題,得到一個(gè)二進(jìn)制“是 / 非”的結(jié)果。看看下面的方程式。
樸素貝葉斯分類器是一種流行的統(tǒng)計(jì)技術(shù),可用于過(guò)濾垃圾郵件!
05 支持向量機(jī)(SVM)
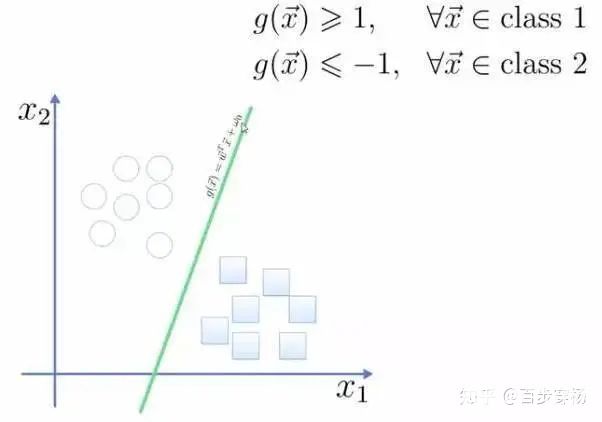
支持向量機(jī)(Support Vector Machine,SVM)是一種用于分類問(wèn)題的監(jiān)督算法。支持向量機(jī)試圖在數(shù)據(jù)點(diǎn)之間繪制兩條線,它們之間的邊距最大。為此,我們將數(shù)據(jù)項(xiàng)繪制為 n 維空間中的點(diǎn),其中,n 是輸入特征的數(shù)量。在此基礎(chǔ)上,支持向量機(jī)找到一個(gè)最優(yōu)邊界,稱為超平面(Hyperplane),它通過(guò)類標(biāo)簽將可能的輸出進(jìn)行最佳分離。
超平面與最近的類點(diǎn)之間的距離稱為邊距。最優(yōu)超平面具有最大的邊界,可以對(duì)點(diǎn)進(jìn)行分類,從而使最近的數(shù)據(jù)點(diǎn)與這兩個(gè)類之間的距離最大化。
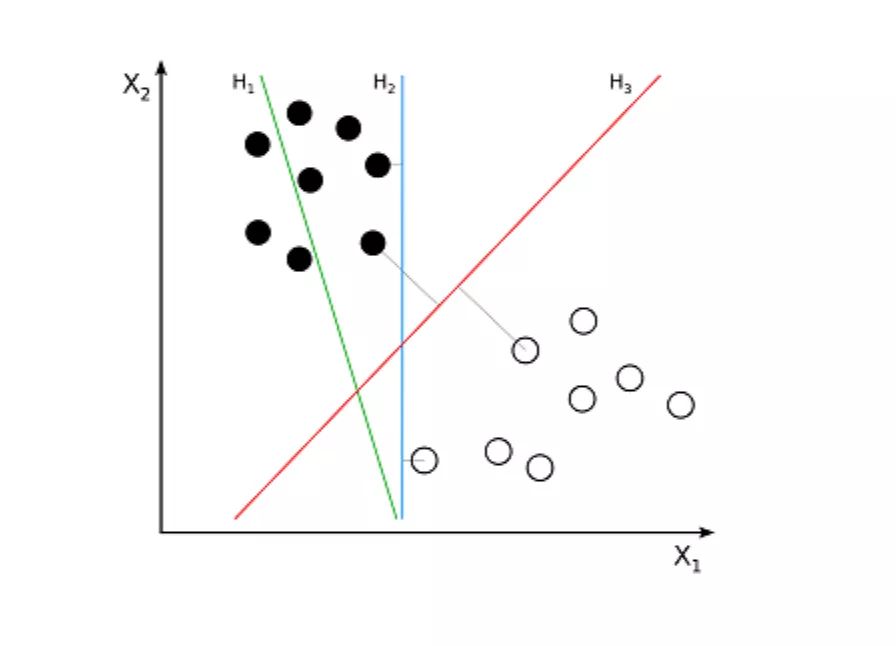
例如,H1 沒(méi)有將這兩個(gè)類分開(kāi)。但 H2 有,不過(guò)只有很小的邊距。而 H3 以最大的邊距將它們分開(kāi)了。
06 K- 最近鄰算法(KNN)
K- 最近鄰算法(K-Nearest Neighbors,KNN)非常簡(jiǎn)單。KNN 通過(guò)在整個(gè)訓(xùn)練集中搜索 K 個(gè)最相似的實(shí)例,即 K 個(gè)鄰居,并為所有這些 K 個(gè)實(shí)例分配一個(gè)公共輸出變量,來(lái)對(duì)對(duì)象進(jìn)行分類。
K 的選擇很關(guān)鍵:較小的值可能會(huì)得到大量的噪聲和不準(zhǔn)確的結(jié)果,而較大的值是不可行的。它最常用于分類,但也適用于回歸問(wèn)題。
用于評(píng)估實(shí)例之間相似性的距離可以是歐幾里得距離(Euclidean distance)、曼哈頓距離(Manhattan distance)或明氏距離(Minkowski distance)。歐幾里得距離是兩點(diǎn)之間的普通直線距離。它實(shí)際上是點(diǎn)坐標(biāo)之差平方和的平方根。
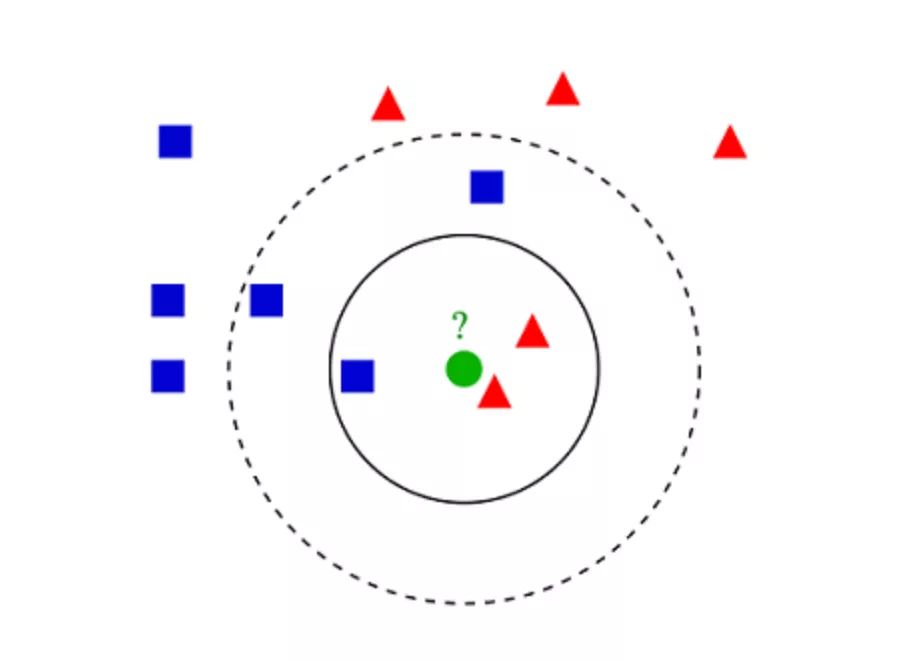 ▲KNN 分類示例 07 K- 均值
▲KNN 分類示例 07 K- 均值
K- 均值(K-means)是通過(guò)對(duì)數(shù)據(jù)集進(jìn)行分類來(lái)聚類的。例如,這個(gè)算法可用于根據(jù)購(gòu)買(mǎi)歷史將用戶分組。它在數(shù)據(jù)集中找到 K 個(gè)聚類。K- 均值用于無(wú)監(jiān)督學(xué)習(xí),因此,我們只需使用訓(xùn)練數(shù)據(jù) X,以及我們想要識(shí)別的聚類數(shù)量 K。
該算法根據(jù)每個(gè)數(shù)據(jù)點(diǎn)的特征,將每個(gè)數(shù)據(jù)點(diǎn)迭代地分配給 K 個(gè)組中的一個(gè)組。它為每個(gè) K- 聚類(稱為質(zhì)心)選擇 K 個(gè)點(diǎn)。基于相似度,將新的數(shù)據(jù)點(diǎn)添加到具有最近質(zhì)心的聚類中。這個(gè)過(guò)程一直持續(xù)到質(zhì)心停止變化為止。
08 隨機(jī)森林
隨機(jī)森林(Random Forest)是一種非常流行的集成機(jī)器學(xué)習(xí)算法。這個(gè)算法的基本思想是,許多人的意見(jiàn)要比個(gè)人的意見(jiàn)更準(zhǔn)確。在隨機(jī)森林中,我們使用決策樹(shù)集成(參見(jiàn)決策樹(shù))。
為了對(duì)新對(duì)象進(jìn)行分類,我們從每個(gè)決策樹(shù)中進(jìn)行投票,并結(jié)合結(jié)果,然后根據(jù)多數(shù)投票做出最終決定。
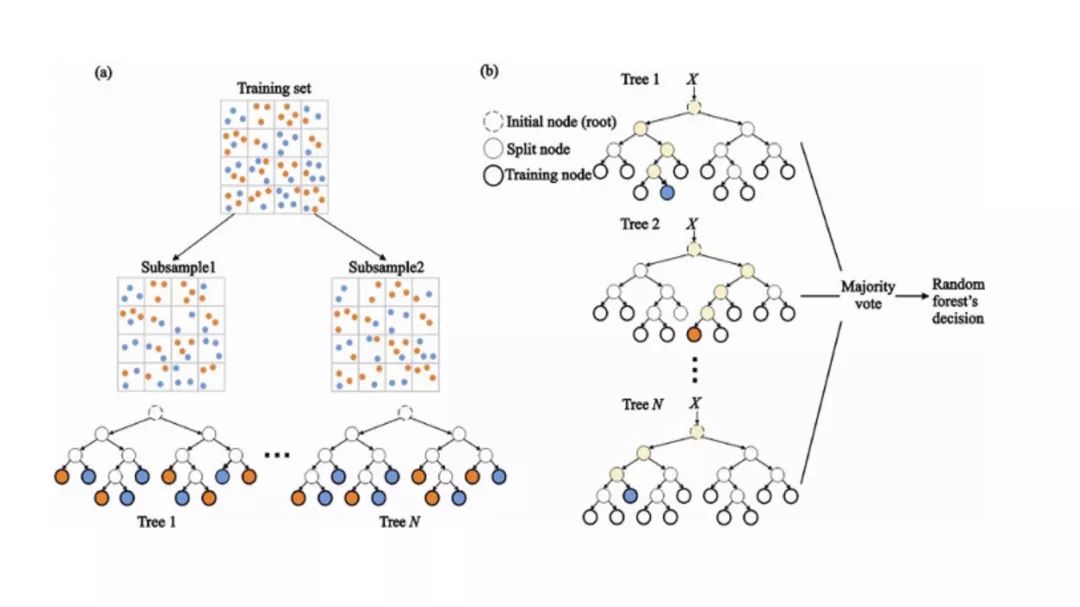
在訓(xùn)練過(guò)程中,每個(gè)決策樹(shù)都是基于訓(xùn)練集的引導(dǎo)樣本來(lái)構(gòu)建的。
在分類過(guò)程中,輸入實(shí)例的決定是根據(jù)多數(shù)投票做出的。
09 降維
由于我們今天能夠捕獲的數(shù)據(jù)量之大,機(jī)器學(xué)習(xí)問(wèn)題變得更加復(fù)雜。這就意味著訓(xùn)練極其緩慢,而且很難找到一個(gè)好的解決方案。這一問(wèn)題,通常被稱為“維數(shù)災(zāi)難”(Curse of dimensionality)。
降維(Dimensionality reduction)試圖在不丟失最重要信息的情況下,通過(guò)將特定的特征組合成更高層次的特征來(lái)解決這個(gè)問(wèn)題。主成分分析(Principal Component Analysis,PCA)是最流行的降維技術(shù)。
主成分分析通過(guò)將數(shù)據(jù)集壓縮到低維線或超平面 / 子空間來(lái)降低數(shù)據(jù)集的維數(shù)。這盡可能地保留了原始數(shù)據(jù)的顯著特征。
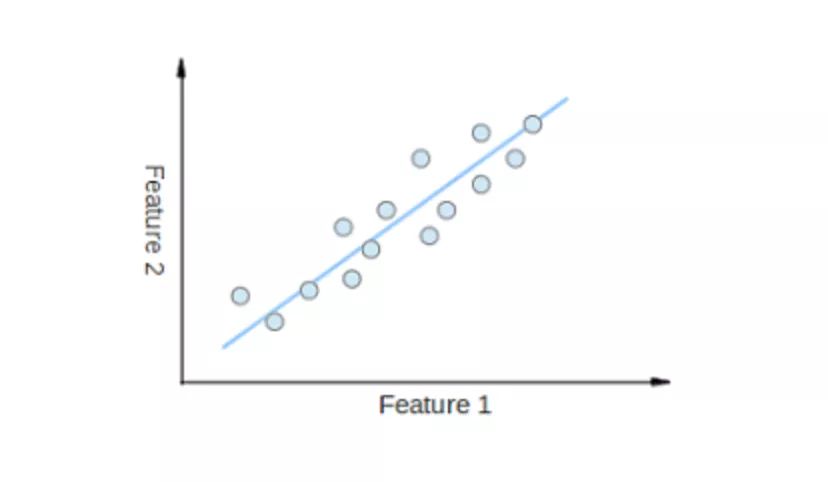
可以通過(guò)將所有數(shù)據(jù)點(diǎn)近似到一條直線來(lái)實(shí)現(xiàn)降維的示例。
10 人工神經(jīng)網(wǎng)絡(luò)(ANN)
人工神經(jīng)網(wǎng)絡(luò)(Artificial Neural Networks,ANN)可以處理大型復(fù)雜的機(jī)器學(xué)習(xí)任務(wù)。神經(jīng)網(wǎng)絡(luò)本質(zhì)上是一組帶有權(quán)值的邊和節(jié)點(diǎn)組成的相互連接的層,稱為神經(jīng)元。在輸入層和輸出層之間,我們可以插入多個(gè)隱藏層。人工神經(jīng)網(wǎng)絡(luò)使用了兩個(gè)隱藏層。除此之外,還需要處理深度學(xué)習(xí)。
人工神經(jīng)網(wǎng)絡(luò)的工作原理與大腦的結(jié)構(gòu)類似。一組神經(jīng)元被賦予一個(gè)隨機(jī)權(quán)重,以確定神經(jīng)元如何處理輸入數(shù)據(jù)。通過(guò)對(duì)輸入數(shù)據(jù)訓(xùn)練神經(jīng)網(wǎng)絡(luò)來(lái)學(xué)習(xí)輸入和輸出之間的關(guān)系。在訓(xùn)練階段,系統(tǒng)可以訪問(wèn)正確的答案。
如果網(wǎng)絡(luò)不能準(zhǔn)確識(shí)別輸入,系統(tǒng)就會(huì)調(diào)整權(quán)重。經(jīng)過(guò)充分的訓(xùn)練后,它將始終如一地識(shí)別出正確的模式。
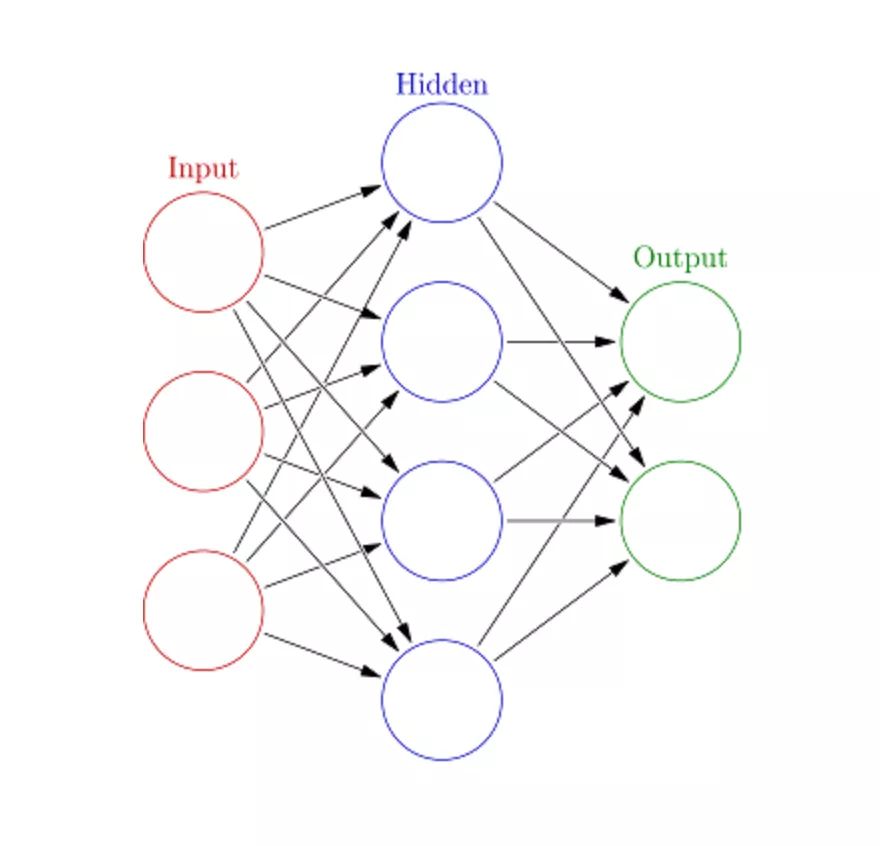
每個(gè)圓形節(jié)點(diǎn)表示一個(gè)人工神經(jīng)元,箭頭表示從一個(gè)人工神經(jīng)元的輸出到另一個(gè)人工神經(jīng)元的輸入的連接。
接下來(lái)是什么?現(xiàn)在,你已經(jīng)了解了最流行的機(jī)器學(xué)習(xí)算法的基礎(chǔ)介紹。你已經(jīng)準(zhǔn)備好學(xué)習(xí)更為復(fù)雜的概念,甚至可以通過(guò)深入的動(dòng)手實(shí)踐來(lái)實(shí)現(xiàn)它們。如果你想了解如何實(shí)現(xiàn)這些算法,可以參考 Educative 出品的 Grokking Data Science 課程,該課程將這些激動(dòng)人心的理論應(yīng)用于清晰、真實(shí)的應(yīng)用程序。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7259瀏覽量
92035 -
模型
+關(guān)注
關(guān)注
1文章
3527瀏覽量
50497 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8507瀏覽量
134731
原文標(biāo)題:機(jī)器學(xué)習(xí)必知必會(huì) 10 大算法!
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
機(jī)器學(xué)習(xí)算法概念介紹及選用建議

遷移學(xué)習(xí)
機(jī)器學(xué)習(xí)簡(jiǎn)介與經(jīng)典機(jī)器學(xué)習(xí)算法人才培養(yǎng)
機(jī)器學(xué)習(xí)算法的介紹及算法優(yōu)缺點(diǎn)的分析
Spark機(jī)器學(xué)習(xí)庫(kù)的各種機(jī)器學(xué)習(xí)算法
樸素貝葉斯等常見(jiàn)機(jī)器學(xué)習(xí)算法的介紹及其優(yōu)缺點(diǎn)比較
人工智能學(xué)習(xí) 遷移學(xué)習(xí)實(shí)戰(zhàn)進(jìn)階
機(jī)器學(xué)習(xí)算法的介紹
機(jī)器學(xué)習(xí)算法匯總 機(jī)器學(xué)習(xí)算法分類 機(jī)器學(xué)習(xí)算法模型
機(jī)器學(xué)習(xí)算法總結(jié) 機(jī)器學(xué)習(xí)算法是什么 機(jī)器學(xué)習(xí)算法優(yōu)缺點(diǎn)
機(jī)器學(xué)習(xí)算法入門(mén) 機(jī)器學(xué)習(xí)算法介紹 機(jī)器學(xué)習(xí)算法對(duì)比
機(jī)器學(xué)習(xí)vsm算法
機(jī)器學(xué)習(xí)有哪些算法?機(jī)器學(xué)習(xí)分類算法有哪些?機(jī)器學(xué)習(xí)預(yù)判有哪些算法?
常用的十大機(jī)器學(xué)習(xí)算法介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論