


在 Pandas 中有很多種方法可以進(jìn)行DF的合并。
本文將研究這些不同的方法,以及如何將它們執(zhí)行速度的對(duì)比。
合并
Pandas 使用 .merge() 方法來(lái)執(zhí)行合并。
importpandasaspd #adictionarytoconverttoadataframe data1={'identification':['a','b','c','d'], 'Customer_Name':['King','West','Adams','Mercy'],'Category':['furniture','OfficeSupplies','Technology','R_materials'],} #ourseconddictionarytoconverttoadataframe data2={'identification':['a','b','c','d'], 'Class':['First_Class','Second_Class','Same_day','StandardClass'], 'Age':[60,30,40,50]} #ConvertthedictionaryintoDataFrame df1=pd.DataFrame(data1) df2=pd.DataFrame(data2)運(yùn)行我們的代碼后,有兩個(gè) DataFrame,如下所示。
identificationCustomer_NameCategory 0aKingfurniture 1bWestOfficeSupplies 2cAdamsTechnology 3dMercyR_materials identificationClassAge 0aFirst_Class60 1bSecond_Class30 2cSame_day40 3dStandardClass50
使用 merge() 函數(shù)進(jìn)一步合并。
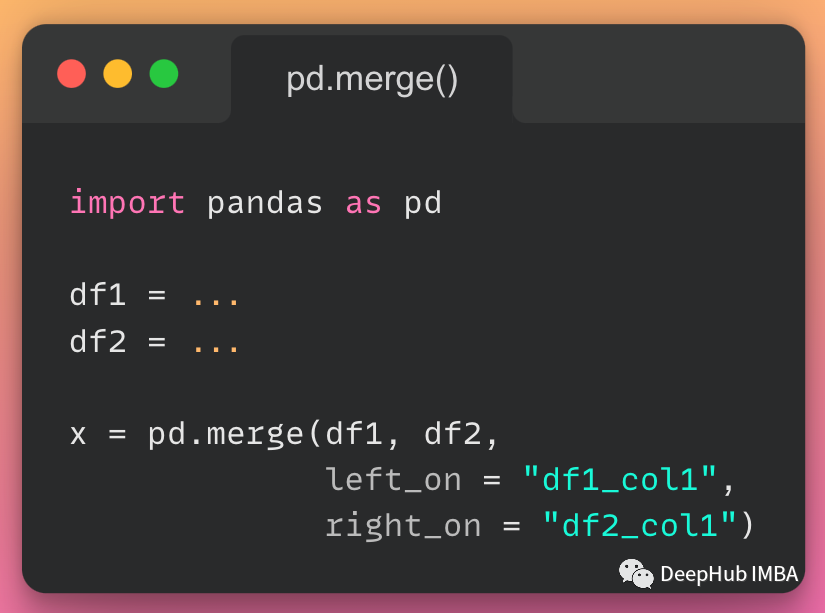
#using.merge()function new_data=pd.merge(df1,df2,on='identification')這產(chǎn)生了下面的新數(shù)據(jù);
identificationCustomer_NameCategoryClassAge 0aKingfurnitureFirst_Class60 1bWestOfficeSuppliesSecond_Class30 2cAdamsTechnologySame_day40 3dMercyR_materialsStandardClass50
.join() 方法也可以將不同索引的 DataFrame 組合成一個(gè)新的 DataFrame。我們可以使用參數(shù)‘on’參數(shù)指定根據(jù)哪列進(jìn)行合并。
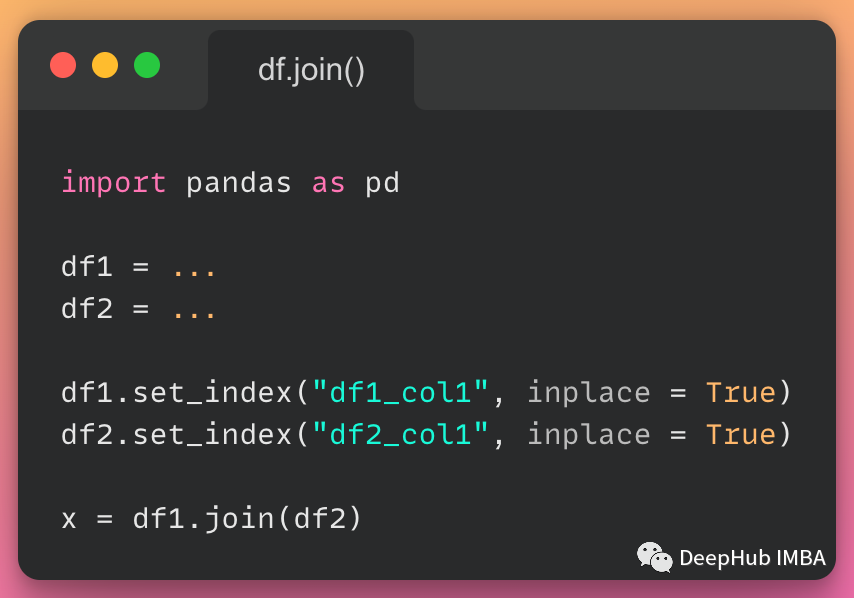 ? 讓我們看看下面的例子,我們?nèi)绾螌嗡饕?DataFrame 與多索引 DataFrame 連接起來(lái);
? 讓我們看看下面的例子,我們?nèi)绾螌嗡饕?DataFrame 與多索引 DataFrame 連接起來(lái);
importpandasaspd
#adictionarytoconverttoadataframe
data1={
'Customer_Name':['King','West','Adams'],
'Category':['furniture','OfficeSupplies','Technology'],}7
#ourseconddictionarytoconverttoadataframe
data2={
'Class':['First_Class','Second_Class','Same_day','StandardClass'],
'Age':[60,30,40,50]}
#ConvertthedictionaryintoDataFrame
Ndata=pd.DataFrame(data1,index=pd.Index(['a','b','c'],name='identification'))
index=pd.MultiIndex.from_tuples([('a','x0'),('b','x1'),
('c','x2'),('c','x3')],
names=['identification','x'])19
#ConvertthedictionaryintoDataFrame
Ndata2=pd.DataFrame(data2,index=index)
print(Ndata,"
",Ndata2)
#joiningsinglyindexedwith
#multiindexed
result=Ndata.join(Ndata2,how='inner')
我們的結(jié)果如下所示;
Customer_NameCategoryClassAge identificationx3ax0KingfurnitureFirst_Class60 bx1WestOfficeSuppliesSecond_Class30 cx2AdamsTechnologySame_day40 x3AdamsTechnologyStandardClass50
連接DF
Pandas 中concat() 方法在可以在垂直方向(axis=0)和水平方向(axis=1)上連接 DataFrame。我們還可以一次連接兩個(gè)以上的 DataFrame 或 Series。
讓我們看一個(gè)如何在 Pandas 中執(zhí)行連接的示例;
importpandasaspd
#adictionarytoconverttoadataframe
data1={'identification':['a','b','c','d'],
'Customer_Name':['King','West','Adams','Mercy'],
'Category':['furniture','OfficeSupplies','Technology','R_materials'],}
#ourseconddictionarytoconverttoadataframe
data2={'identification':['a','b','c','d'],
'Class':['First_Class','Second_Class','Same_day','StandardClass'],
'Age':[60,30,40,50]}
#ConvertthedictionaryintoDataFrame
df1=pd.DataFrame(data1)
df2=pd.DataFrame(data2)
#performconcatenationherebasedonhorizontalaxis
new_data=pd.concat([df1,df2],axis=1)
print(new_data)
這樣就獲得了新的 DataFrame :
identificationCustomer_NameCategoryidentification 0aKingfurniturea31bWestOfficeSuppliesb42cAdamsTechnologyc53dMercyR_materialsd ClassAge 0First_Class60 1Second_Class30 2Same_day40 3StandardClass50
Merge和Join的效率對(duì)比
Pandas 中的Merge Joins操作都可以針對(duì)指定的列進(jìn)行合并操作(SQL中的join)那么他們的執(zhí)行效率是否相同呢?下面我們來(lái)進(jìn)行一下測(cè)。 兩個(gè) DataFrame 都有相同數(shù)量的行和兩列,實(shí)驗(yàn)中考慮了從 100 萬(wàn)行到 1000 萬(wàn)行的不同大小的 DataFrame,并在每次實(shí)驗(yàn)中將行數(shù)增加了 100 萬(wàn)。我對(duì)固定數(shù)量的行重復(fù)了十次實(shí)驗(yàn),以消除任何隨機(jī)性。下面是這十次試驗(yàn)中合并操作的平均運(yùn)行時(shí)間。
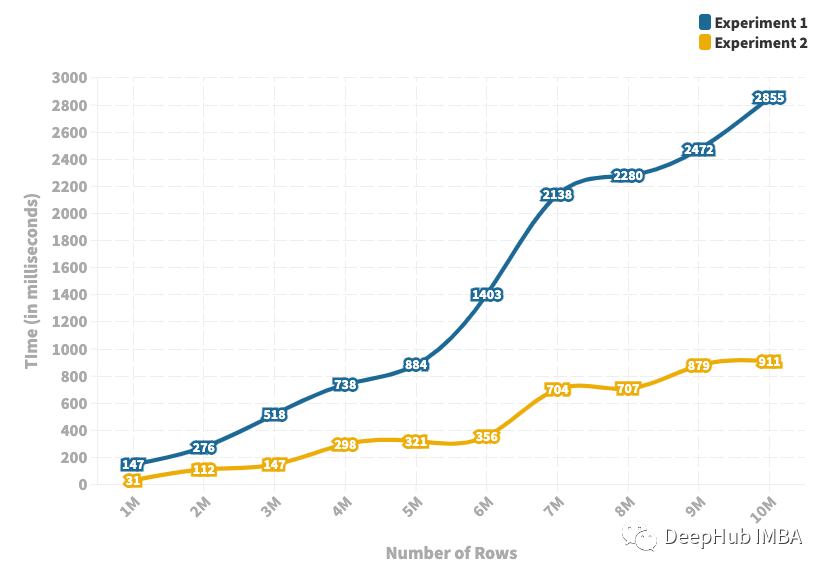
上圖描繪了操作所花費(fèi)的時(shí)間(以毫秒為單位)。
正如我們從圖中看到的,運(yùn)行時(shí)間存在顯著差異——最多相差 5 倍。隨著 DataFrame 大小的增加,運(yùn)行時(shí)間之間的差異也會(huì)增加。兩個(gè) JOIN 操作幾乎都隨著 DataFrame 的大小線性增加。但是,Join的運(yùn)行時(shí)間增加的速度遠(yuǎn)低于Merge。
如果需要處理大量數(shù)據(jù),還是請(qǐng)使用join()進(jìn)行操作。
-
函數(shù)
+關(guān)注
關(guān)注
3文章
4379瀏覽量
64801 -
代碼
+關(guān)注
關(guān)注
30文章
4900瀏覽量
70663 -
merge
+關(guān)注
關(guān)注
0文章
5瀏覽量
2566 -
concat
+關(guān)注
關(guān)注
0文章
3瀏覽量
1986
原文標(biāo)題:Pandas 中使用 Merge、Join 、Concat 合并數(shù)據(jù)的效率對(duì)比
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Fork/Join的框架機(jī)制詳解
pandas是什么
pandas使用步驟
pandas是什么?
pandas是什么?
對(duì)于merge、join和concat三者的區(qū)別分析

Git命令解析-merge、rebase
5個(gè)必須知道的Pandas數(shù)據(jù)合并技巧
應(yīng)用層關(guān)聯(lián)的優(yōu)勢(shì) MySQL不推薦使用join的原因
如何優(yōu)化MySQL中的join語(yǔ)句
Python Pandas如何來(lái)管理結(jié)構(gòu)化數(shù)據(jù)
git rebase和git merge的區(qū)別
pandas中合并數(shù)據(jù)的5個(gè)函數(shù)

Pandas DataFrame的存儲(chǔ)格式性能對(duì)比





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論