 查詢優化器有多重要
查詢優化器有多重要
相信大家都對大名鼎鼎的ClickHouse有一定的了解了,它強大的數據分析性能讓人印象深刻。但在字節大量生產使用中,發現了ClickHouse依然存在了一定的限制。例如:
缺少完整的upsert和delete操作
多表關聯查詢能力弱
集群規模較大時可用性下降(對字節尤其如此)
沒有資源隔離能力
因此,我們決定將ClickHouse能力進行全方位加強,打造一款更強大的數據分析平臺。后面我們將從五個方面來和大家分享,此前兩篇內容分別為大家介紹了“更新刪除”和“多表關聯查詢”,本篇將詳細介紹我們是如何構建ClickHouse的查詢優化器。
查詢優化器有多重要?
在傳統的關系型數據庫中,如Oracle、DB2、MySQL,查詢優化器都是作為幾個最重要的核心組件之一。可以說,沒有查詢優化器的數據庫是不完整的。相對 OLTP 而言在OLAP領域中更是如此;對于分析類場景,查詢更為復雜,計劃好壞的差異更大。一個優秀的查詢優化器可以防止用戶寫出不好的SQL導致執行速度慢,能夠準確的選擇出一條效率最高的執行路徑,大幅度降低查詢時間。相應的,一個不好的查詢優化器,甚至會讓查詢變慢。
常見的優化器邏輯分為兩類,一類叫“基于規則的優化(RBO)”,另一類稱為“基于代價的優化(CBO)”,實際應用過程中應當兩類兼顧才能取得最佳效果。
基于規則的優化
根據優化規則對關系表達式進行轉換,這里的轉換是說一個關系表達式經過優化規則后會變成另外一個關系表達式,同時原有表達式會被裁剪掉,經過一系列轉換后生成最終的執行計劃。RBO中包含了一套有著嚴格順序的優化規則,同樣一條SQL,無論讀取的表中數據是怎么樣的,最后生成的執行計劃都是一樣的。同時,在RBO中SQL寫法的不同很有可能影響最終的執行計劃,從而影響腳本性能。
基于代價的優化
根據優化規則對關系表達式進行轉換,這里的轉換是說一個關系表達式經過優化規則后會生成另外一個關系表達式,同時原有表達式也會保留,經過一系列轉換后會生成多個執行計劃,然后CBO會根據統計信息和代價模型(Cost Model)計算每個執行計劃的Cost,從中挑選Cost最小的執行計劃。
ByteHouse的查詢優化器
目前主流的OLAP的引擎在查詢優化器方面做的并不夠好,尤其是ClickHouse。眾所周知ClickHouse以快著稱,但是它的快是采用了力大飛磚的方式,需要用戶將數據預先生成大寬表,以避免過于復雜的多表查詢從而獲得高性能。而代價是,每次維度變化或新需求都需要大量操作,以及在必須使用多表關聯進行分析的場景中顯得十分無力。
作為一個企業級的OLAP數據庫來說一個完善且強大的優化器是必不可少的,因此,ByteHouse從零開始自研的了查詢優化器。
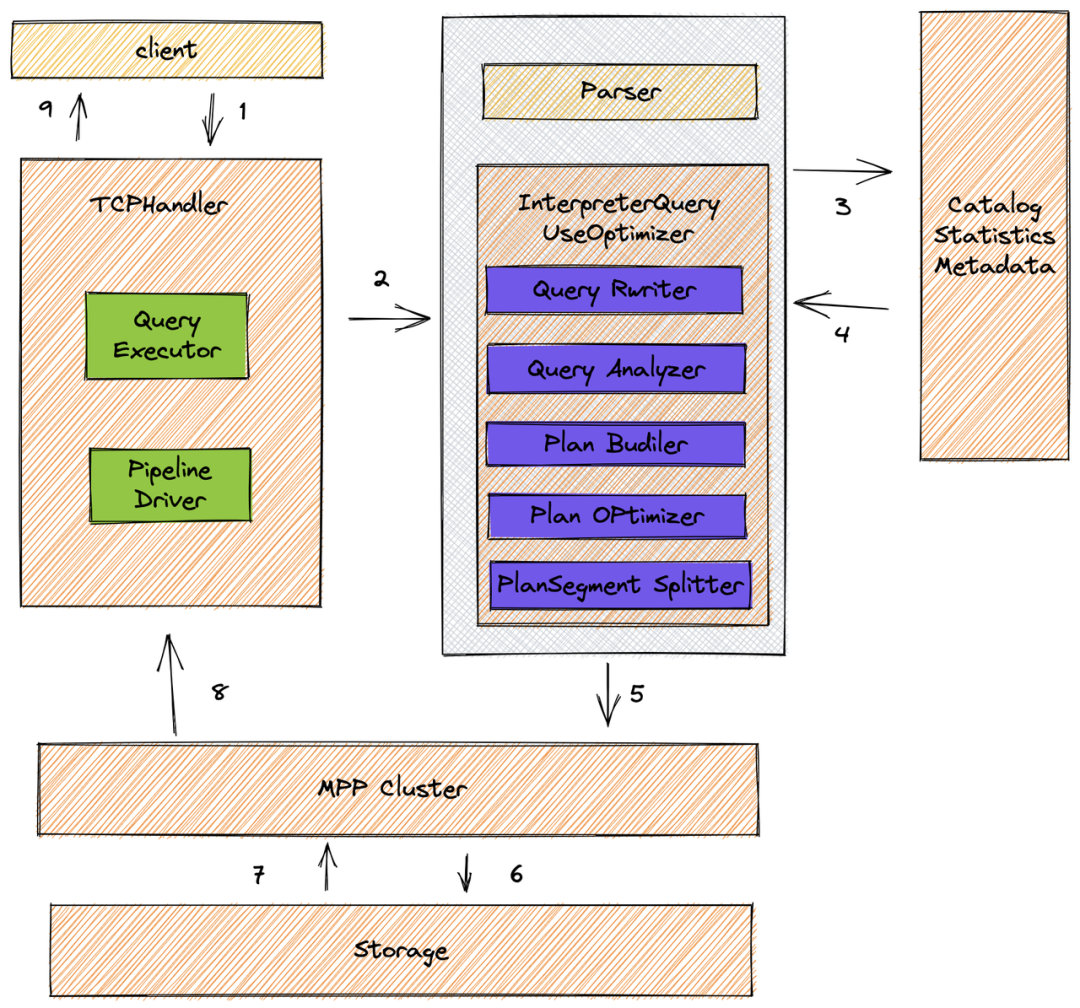
查詢優化的完整流程
上圖描述了整個查詢的執行流程,從 SQL parse 到執行期間所有內容全部進行了重新實現(其中紫色模塊),構建了一套完整的且規范的查詢優化器。
主要功能模塊
Analyzers
Analyzers 目錄包括兩部分功能:
一個是 QueryRewriter,一方面是通過 AST 改寫的方式實現一些語法特性;我們同時支持 Clickhouse SQL 和標準 SQL,所以另一方面是確保在 Clickhouse SQL 模式下 SQL 語義能和原生 Interpreter 執行模式一致。
另一個是 QueryAnalyzer,用于對改寫完的 AST 進行語義的分析和驗證。Analyzer 區分 ANSI SQL 和 Clickhouse SQL 兩種模式。
QueryRewriter 針對 ANSI SQL 的改寫主要有:
With CTE/view 展開;
UDF 展開;
特定函數的改寫,比如將 count(*) 改寫為 count(),將 countDistinct(...) 改寫為 uniqExact(...);
QueryRewriter 針對 Clickhouse SQL 的改寫主要有:
With CTE/view 展開;
UDF 展開;
特定函數的改寫;
JoinToSubquery 展開,對應于 Interpreter 鏈路下的 JoinToSubqueryTransformVisitor;
Qualified name 歸一化,對應于 Interpreter 鏈路下的 TranslateQualifiedNamesVisitor;
Alias 改寫,對應于 Interpreter 鏈路下的 QueryNormalizer;
QueryAnalyzer 查詢語義進行分析和校驗,將 AST 抽象成出結構化的數據結構,為下一步構建 plan 提供數據。在該模塊中標準 SQL 和 Clickhouse SQL 進行了區分,一套代碼同時兼容兩種語義。
QueryPlan
在 Analyze 之后則是利用 Analyze 出的數據結構構建初始的查詢計劃。QueryPlan 是在社區的 QueryPlanStep 基礎上改進而來,一方面增加了序列化/反序列化方法,為了計劃下發執行基于 QueryPlan 并非 AST 或者 SQL 文本。另一方面是對社區中不合理的 Step 進行更改,讓每個 Step 僅僅表達關系代數的語義而非很多執行相關的內容和參數,而這些執行相關的信息則是在每個執行的 server 上構建執行 pipeline 時才真正進行獲得。
Optimizer
構建完執行計劃后則是最為關鍵最后為核心的優化器模塊。PlanOptimizer 類是查詢優化的入口類,首先會基于 PlanPattern 對 SQL的查詢做一次粗粒度的分類,不同復雜度的查詢使用不同的規則集合,提升效率。
優化器不管是 RBO 還是 CBO 本質上都是對查詢做改寫,只是改寫的思路以及改寫框架有不同的取舍。我們實現了三種改寫框架,用于處理不同的場景:
基于 visitor 的改寫框架:可以 Top-Down,也可以 Botton-Up 的 方式對一個 QueryPlan 做改寫,它比較適合于帶有上下文依賴的優化規則,例如 PredicatePushDown,需要把 Predicate 一層層的往下推。
基于 pattern-match 的改寫框架:這種適合簡單、通用的改寫規則,例如對于兩個連續的 Filter 做合并的動作,只要 QueryPlan 里面的 Sub Plan 符合 Filter-Filter 這樣的 pattern,就可以 match 對應的優化規則,進行改寫。
基于 Cascade 的改寫框架:通過遍歷等價計劃,并將所有的等價計劃存儲在一個內存空間中,然后評估每種等價計劃的代價,進而選擇一種最優解。
查詢優化器帶來了什么
在性能方面,原生Clickhouse受限于缺少查詢優化器,對于 TPC-DS測試集的99個SQL用例僅能正常運行很少一部分查詢,即使通過手動改寫 SQL 也僅能成功運行 80%的查詢。在實現了完善的優化器之后可以直接運行全部 TPC-DS 原始 SQL,改進后的 Clickhouse 才這正可以算是可用的 OLAP 數據庫。不僅僅是可以正常執行這些復雜查詢,而且效率也得到了很大的提升,相對在沒優化器的情況下手動改寫的 SQL ,性能提升 6 倍以上。在內部的一些業務場景中性能也有近10倍的提升。
優化器的能力方面:
RBO:支持:列裁剪、分區裁剪、表達式簡化、子查詢解關聯、謂詞下推、冗余算子消除、Outer-JOIN 轉 INNER-JOIN、算子下推存儲、分布式算子拆分等常見的啟發式優化能力。
CBO:基于 Cascade 搜索框架,實現了高效的 Join 枚舉算法,以及基于 Histogram 的代價估算,對 10 表全連接級別規模的 Join Reorder 問題,能夠全量枚舉并尋求最優解,同時針對大于10表規模的 Join Reorder 支持啟發式枚舉并尋求最優解。CBO 支持基于規則擴展搜索空間,除了常見的 Join Reorder 問題以外,還支持 Outer-Join/Join Reorder,Magic Set Placement 等相關優化能力。
分布式計劃優化:面向分布式MPP數據庫,生成分布式查詢計劃,并且和 CBO 結合在一起。相對業界主流實現:分為兩個階段,首先尋求最優的單機版計劃,然后將其分布式化。我們的方案則是將這兩個階段融合在一起,在整個 CBO 尋求最優解的過程中,會結合分布式計劃的訴求,從代價的角度選擇最優的分布式計劃。對于 Join/Aggregate 的還支持 Partition 屬性展開。
高階優化能力:實現了 Dynamic Filter pushdown、單表物化視圖改寫、基于代價的 CTE (公共表達式共享)。
下面我們用TPC-DS標準測試集,來為大家展現一下添加優化器前后的差別:
在沒有優化器時,僅能完成26個SQL的查詢。而添加了優化器后,能夠完整跑完TPC-DS的全部99個SQL,并且在此前能完成的查詢中,性能也得到了極大的提升。
-
存儲
+關注
關注
13文章
4404瀏覽量
86444 -
函數
+關注
關注
3文章
4353瀏覽量
63294 -
數據分析
+關注
關注
2文章
1464瀏覽量
34340
原文標題:“吊打” ClickHouse,火山引擎數倉 SQL 查詢性能 10x 提升!
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ADC參考電壓有多重要?
嵌入式架構有多重要?
單片機中的系統時鐘有多重要?
嵌入式架構有多重要
基于共享執行策略的間隔查詢優化

AppleID是什么 蘋果官方科普有多重要
優化DBLE獨立子查詢教程
一文終結SQL子查詢優化
Cascades查詢優化器基本原理分析





 工商網監
工商網監
評論